はじめに
前回、番地等が1文字(数字)違っているだけだとダメということが分かったので、Fine Tuningでなんとなならないかと考えてみました。
参考
こちらを参考にしています。
ざっくりと説明
これからやろうとしていることは、以下のような流れになります。
- 事前学習モデルを持ってくるよ
- 最後にpooling層を追加するよ(ここが再学習結果になる)
- Triplet Lossで再学習するよ
コード
実際のコードはこちらになります。
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, losses, models
from torch.utils.data import DataLoader
# 事前学習モデルの取得
bert = models.Transformer('sonoisa/sentence-bert-base-ja-mean-tokens-v2')
# pooling層の追加
pooling = models.Pooling(bert.get_word_embedding_dimension())
model = SentenceTransformer(modules=[bert, pooling])
# 学習データの読み込み
# ★★★ 実際は、ここで学習データをdatasets_df(PandasのDataFrame)に読み込みます ★★★
train_dataset = SentencesDataset([InputExample(texts=[row["anchor"], row["positive"], row["negative"]]) for index,row in datasets_df.iterrows()], model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=8)
# Triplet Lossの設定
train_loss = losses.TripletLoss(model=model)
# 学習
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=5,
evaluation_steps=1,
warmup_steps=1,
output_path="./sbert",
)
「datasets_df」に学習データを入れておく予定です。
なお、事前に「sentence-transformers]をインストールしています。
(conda-forgeの方だとうまく動きませんでしたので、pipでインストールしました)
学習データの準備
Triplet Lossで学習するので、3種類の文章の組み合わせを用意します。
- anchor:サンプルとなる文章
- positive:サンプルに近い文章(今回は、同じ番地で表現が違う住所)
- negative:サンプルと遠い文章(今回は、違う番地で表現が同じ住所)
こんなイメージです。
- anchor:東京都港区海岸一丁目2番3号
- positive:東京都港区海岸1-2-3
- negative:東京都港区海岸一丁目1番3号
参考データ
デジタル庁レジストリマスタにある町字マスターをサンプルとします。
でもよく考えたら、町字までは変更が無いので、そこから先だけ学習すればいいような気がします。
ということで、もしうまくいかなかったら町字まで含めることにして、今回は丁目以降だけで学習させていきます。
作成したデータ
結局、「一丁目1番1号」~「十九丁目19番19号」で学習してみることにしました。
(力技でデータを作成しています ^^;)
import numpy as np
import pandas as pd
# '一丁目'みたいに変換
def get_choume(c):
num10 = ["", "", "二", "三", "四", "五", "六", "七", "八", "九"]
num1 = ["", "一", "二", "三", "四", "五", "六", "七", "八", "九"]
juu = ""
if (c//10 >= 1):
juu = "十"
return num10[c//10] + juu + num1[c%10] + "丁目"
# データ作成
list_anchor = []
list_positive = []
list_negative = []
for c in range(1,20):
for b in range(1,20):
for g in range(1,20):
print(str(c) + "-" + str(b) + "-" + str(g))
# 間違い
for inv in range(1,20):
# 丁目違い
if inv != c:
# 一丁目1番1号
list_anchor.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(get_choume(inv) + str(b) + "番" + str(g) + "号")
# 1丁目1番1号
list_anchor.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(str(inv) + "丁目" + str(b) + "番" + str(g) + "号")
# 1-1-1
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_negative.append(str(inv) + "-" + str(b) + "-" + str(g))
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_negative.append(str(inv) + "-" + str(b) + "-" + str(g))
# 番違い
if inv != b:
# 一丁目1番1号
list_anchor.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(get_choume(c) + str(inv) + "番" + str(g) + "号")
# 1丁目1番1号
list_anchor.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(str(c) + "丁目" + str(inv) + "番" + str(g) + "号")
# 1-1-1
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_negative.append(str(c) + "-" + str(inv) + "-" + str(g))
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_negative.append(str(c) + "-" + str(inv) + "-" + str(g))
# 号違い
if inv != g:
# 一丁目1番1号
list_anchor.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(get_choume(c) + str(b) + "番" + str(inv) + "号")
# 1丁目1番1号
list_anchor.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_positive.append(str(c) + "-" + str(b) + "-" + str(g))
list_negative.append(str(c) + "丁目" + str(b) + "番" + str(inv) + "号")
# 1-1-1
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(get_choume(c) + str(b) + "番" + str(g) + "号")
list_negative.append(str(c) + "-" + str(b) + "-" + str(inv))
list_anchor.append(str(c) + "-" + str(b) + "-" + str(g))
list_positive.append(str(c) + "丁目" + str(b) + "番" + str(g) + "号")
list_negative.append(str(c) + "-" + str(b) + "-" + str(inv))
# DataFrameにまとめる
out_data = pd.DataFrame(
data={'anchor': list_anchor, 'positive': list_positive, 'negative': list_negative},
columns=['anchor', 'positive', 'negative']
)
# ファイルに保存
out_data.to_csv("./output.csv")
1,481,544行のデータが出来上がりました。
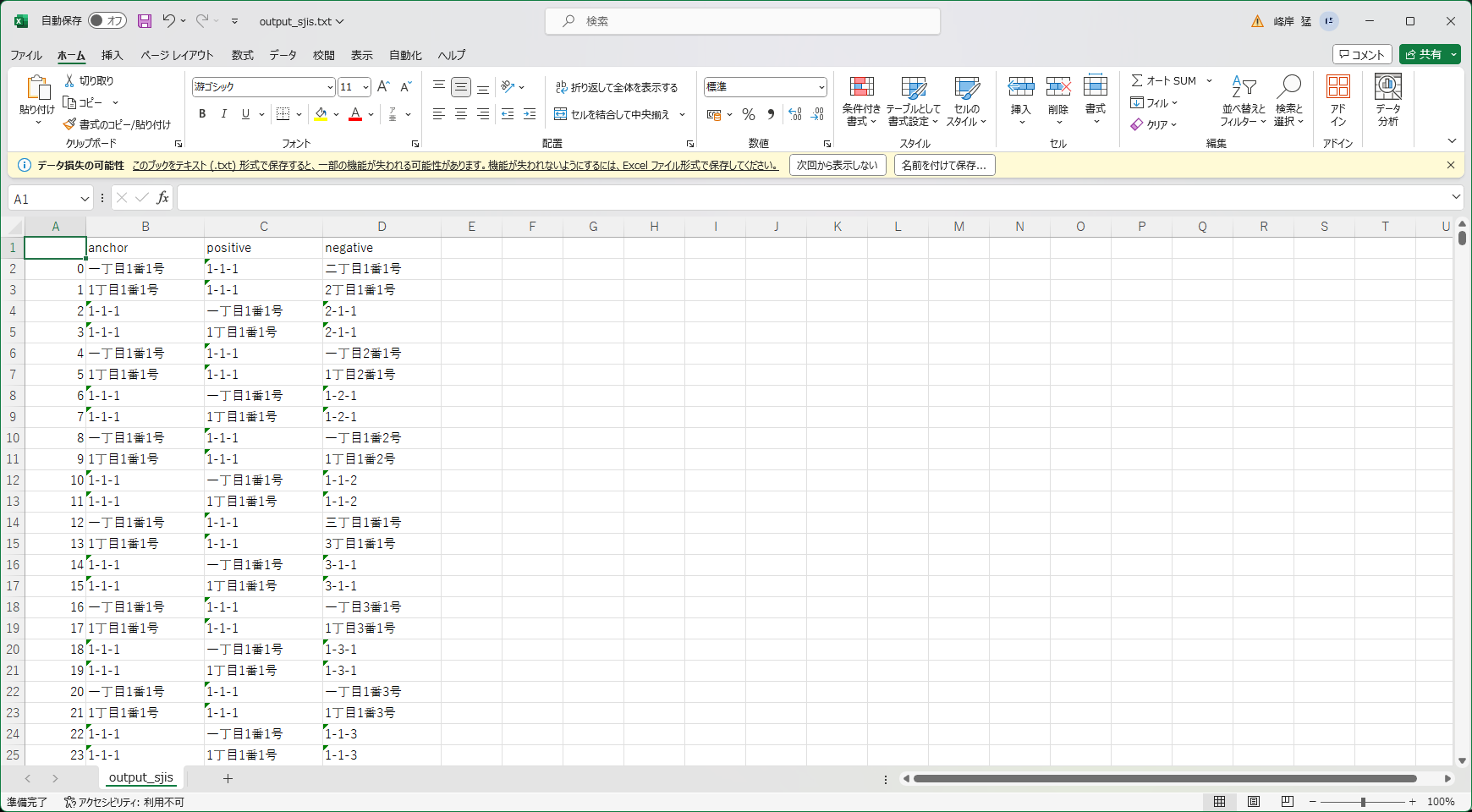
※余談ですが、DataFrameにデータを追加するときは、いったんリストを作ってからDataFrameに変換すると速いです。
(1行ずつconcatすると、遅すぎて死ねます)
学習
作成したデータを読みこんで学習させます。
import pandas as pd
datasets_df = pd.read_csv('./output.csv')
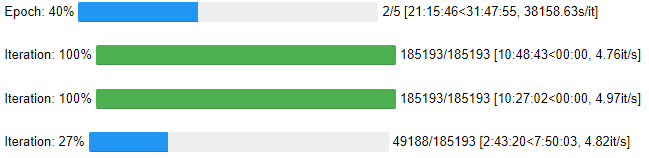
こんな感じで学習が進んでいきます。
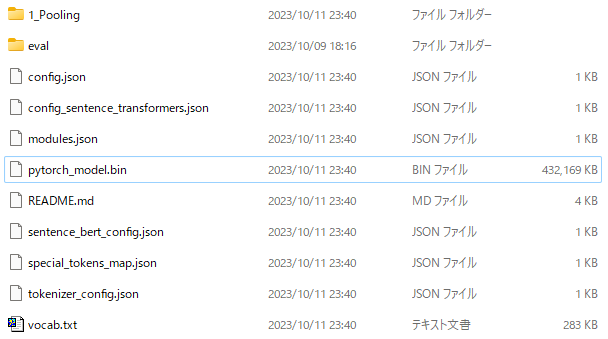
学習が終わると、以下のようなファイルが出来上がります。
試してみる
前回のデータで試してみました。
# モデルのロードはこんな感じ(ディレクトリを指定)
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, losses, models
model = SentenceTransformer('./sbert')
| 東京都港区海岸一丁目2番3号 | ||
|---|---|---|
| 1 | 東京都港区海岸一丁目2番3号 | 0.00000000e+00 |
| 2 | 東京都港区海岸一丁目二番三号 | 5.66171522e-03 |
| 3 | 東京都港区海岸1丁目2番3号 | 7.61460262e-05 |
| 4 | 東京都港区海岸1丁目2番3号 | 7.61460262e-05 |
| 5 | 東京都港区海岸1-2-3 | 3.07086443e-04 |
| 6 | 東京都港区海岸1-2-3 | 3.07086443e-04 |
| 7 | 東京都港区海岸一丁目1番3号 | 1.18531936e-01 |
| 8 | 東京都港区海岸一丁目1番3号 | 1.18531936e-01 |
| 9 | 東京都港区海岸一丁目一番三号 | 1.12835902e-01 |
| 10 | 東京都港区海岸1丁目1番3号 | 1.19411865e-01 |
| 11 | 東京都港区海岸1丁目1番3号 | 1.19411865e-01 |
| 12 | 東京都港区海岸1-1-3 | 1.19002293e-01 |
| 13 | 東京都港区海岸1-1-3 | 1.19002293e-01 |
| 14 | 東京都港区海岸一丁目1番1号 | 2.32376073e-01 |
| 15 | 東京都港区海岸一丁目1番1号 | 2.32376073e-01 |
| 16 | 東京都港区海岸一丁目一番一号 | 2.32260587e-01 |
| 17 | 東京都港区海岸1丁目1番1号 | 2.32439074e-01 |
| 18 | 東京都港区海岸1丁目1番1号 | 2.32439074e-01 |
| 19 | 東京都港区海岸1-1-1 | 2.32677260e-01 |
| 20 | 東京都港区海岸1-1-1 | 2.32677260e-01 |
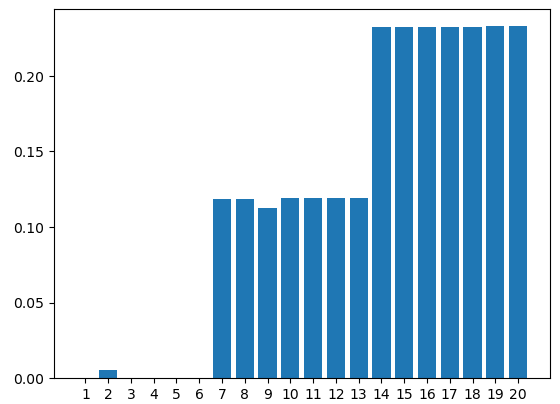
うまくいったようです。
まとめ
とりあえず、全国のデータを読み込まなくてもなんとかいけそうです。
ただ、今は1~19ですので、せめて99まで学習させてたいところです。
(1~19で50時間以上学習に時間がかかっているので、その4倍というと200時間ですか...)