CP932の環境依存文字(機種依存文字)を、JIS X 0208(JIS基本漢字)の異字体・俗字に置き換えるソフトを C# で作ったので記事にする。
予備知識
本稿では、次の知識があるものとして話を進める。
- 文字符号化方式(エンコーディング)と符号化文字集合(キャラクタセット)の違いを知っている。
-
JIS X 0208は符号化文字集合のひとつであり、その文字符号化方式にはShift_JIS、EUC-JP、ISO-2022-JPなどがあること。 -
Unicodeは符号化文字集合のひとつであり、その文字符号化方式にはUTF-8、UTF-16などがあること。 -
CP932は、Shift_JISの符号化文字集合をマイクロソフト社が独自に拡張したものであること。
一般に「文字コード」と言われれば文字符号化方式を指すが、厳密には異なる。
もし新人SEがUnicodeとUTF-8の違いを質問してきたら、それは「文字コード」が文字符号化方式と符号化文字集合で構成されていることを理解していないということなので、丁寧に説明してあげよう。
なお、CP932については、
https://qiita.com/kasei-san/items/cfb993786153231e5413
の記事が詳しいので、そちらを参照して欲しい。
開発のきっかけ
今のeLTAX(地方税の電子申告システム)では、JIS X 0208で定義されていない環境依存文字、半角カナ、JIS第3水準漢字、JIS第4水準漢字を扱えないので、これらを似たような文字に置き換えてしまおうというのが開発の発端。
ちなみに総務省発表によると、扱える文字の不足問題は2019年9月に改善される予定とのことで今後に期待するとしよう。
現在は e-Tax(国税の電子申告システム)と同水準に改善され、この問題は解消している。
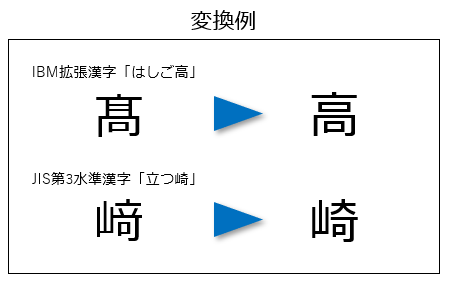
なお、e-Tax(国税の電子申告システム)では、JIS X 0221をUTF-8で符号化した文字コードを扱えるため上図に示した文字では問題は発生しない。ただし、「𠮷」(土の下に口。某牛丼チェーンでも使われている文字)のようなサロゲートペアの文字はやはり扱えない。
そもそも異字体・俗字とは何か
異字体・俗字に明確な定義づけがあるわけではない。
同じ意味の漢字ではあるものの、字体が少し異なっているものとし、ここでは、旧字体や古字も異字体に含まれると定義する。
ソフトの性質上、人名と地名で使われる漢字に集中するわけだが、まずは該当文字を洗い出し、文字単位で変換辞書を作成するところから始めた。
CP932で拡張された文字が対象なので、JIS X 0208に存在する文字は除外する。
変換される漢字の例
JIS X 0208に存在しないので変換する。
-
髙橋 一生
 高橋 一生
高橋 一生 -
濵﨑 あゆみ 浜崎 あゆみ
- 綾瀨 はるか 綾瀬 はるか
-
德永 英明 徳永 英明
変換されない漢字の例
旧字体ではあるがJIS X 0208にも存在する漢字なので変換しない。
-
齊藤 由貴 斉藤 由貴
- 森山 未來 森山 未来
-
眞木 よう子 真木 よう子
-
櫻井 翔 桜井 翔
-
氣志團 気志団
-
國學院大學 国学院大学
中国の人名など
日本国内で流通していない漢字、中国の一部の人名用漢字については、ピンイン、中国語読みのカナ表記、日本語読みのカナ表記のいずれかに変換できるようにした。
日本に伝えられた漢字の読み方(音読み)には、呉音(主に百済人によって伝えられた中国南方系の読み方)、漢音(奈良~平安時代に伝えられた中国北方系の読み方)、唐音(主に鎌倉時代に伝えられた江南浙江地方の読み方)があるが、中国の人名を日本語で読む場合は漢音が多いので、ソフトでは漢音に統一した。
変換できない文字
苗字の棈松(アベマツ)の「棈」、地名の荢千場(ウホシバ)の「荢」、苗字と地名の双方に使われている橳島(ヌデシマ)の「橳」などは、JIS X 0208の中に適当な文字が見つからなかった。「橳」の俗字として「椦」を確認できたものの、典拠が不明な幽霊文字なので採用しなかった。
また、岩手県には霻霳(ホウリョウ)という、JIS X 0208にない文字だけで構成された地名があり「豊隆」と書き換えた文献も確認しているが、ソフトは単語単位ではなく文字単位で見るので「豊隆」には変換されない。
変換が必要なのに変換できなかった文字、つまり辞書に無い文字は、ユーザーの判断に委ねることにした。
ソースコード
C# のソースコードを一部だが抜粋する。
文字チェック関数
CP932で拡張された文字なら 0 以外を返す。
EncodingにShift_JISを指定しているが、これは .NET Framework に該当するコードページが無いからで、要はCP932と同じである。
.NET で CP932とShift_JISを区別する関数としても使えるだろう。
Encoding sjis = Encoding.GetEncoding("Shift_JIS", EncoderFallback.ExceptionFallback, DecoderFallback.ReplacementFallback);
private int getBadChar(char c) {
byte[] bytes = sjis.GetBytes(c.ToString());
if (bytes.Length == 1) return 0; // 半角なら
if (BitConverter.IsLittleEndian) Array.Reverse(bytes); // 上位バイトと下位バイトを入れ替える
int code = BitConverter.ToUInt16(bytes, 0);
// 文字コードチェック(チェック範囲は下位1バイトが 0x40~0x7e、0x80~0xfc にあるもの)
if ((code >= 0x81ad && code <= 0x81b7) || (code >= 0x81c0 && code <= 0x81c7) || (code >= 0x81cf && code <= 0x81d9) ||
(code >= 0x81e9 && code <= 0x81ef) || (code >= 0x81f8 && code <= 0x81fb) || (code >= 0x81fd && code <= 0x824e) ||
(code >= 0x8259 && code <= 0x825f) || (code >= 0x827a && code <= 0x8280) || (code >= 0x829b && code <= 0x829e)) {
return code; // 記号、桁、ラテン
}
if ((code >= 0x82f2 && code <= 0x82ff) || (code >= 0x8397 && code <= 0x839e)) {
return code; // ひらがな、カタカナ
}
if ((code >= 0x83b7 && code <= 0x83be) || (code >= 0x83d7 && code <= 0x83df) || (code >= 0x8461 && code <= 0x846f) ||
(code >= 0x8492 && code <= 0x849e) || (code >= 0x84bf && code <= 0x889e)) {
return code; // ギリシャ文字、キリル文字、特殊文字
}
if ((code >= 0x9873 && code <= 0x989e) || (code >= 0xeaa5)) {
return code; // 漢字
}
return 0;
}
文字変換関数
上述の文字チェック関数で 0 以外を返した文字は、文字変換関数に渡す。
これでJIS X 0208で表現できる文字列となる。定義が無ければ null を返す。
private string replaceChar(char badChar) {
switch (badChar) {
case '髙': return "高";
case '﨑': return "崎";
case '濵': return "浜";
case '賴': return "頼";
case '瀨': return "瀬";
case '德': return "徳";
case '蓜': return "配";
case '昻': return "昂";
case '桒': return "桑";
case '栁': return "柳";
case '犾': return "犹";
case '琪': return "棋";
case '裵': return "裴";
case '魲': return "鱸";
case '羽': return "羽";
case '焏': return "丞";
case '祥': return "祥";
case '曻': return "昇";
case '敎': return "教";
case '澈': return "徹";
case '曺': return "曹";
case '黑': return "黒";
case '塚': return "塚";
case '閒': return "間";
case '彅': return "薙";
case '匤': return "匡";
case '冝': return "宜";
case '埇': return "甬";
case '鮏': return "鮭";
case '伹': return "但";
case '杦': return "杉";
case '罇': return "樽";
case '柀': return "披";
case '﨤': return "返";
case '寬': return "寛";
case '神': return "神";
case '福': return "福";
case '礼': return "礼";
case '贒': return "賢";
case '逸': return "逸";
case '隆': return "隆";
case '靑': return "青";
case '飯': return "飯";
case '飼': return "飼";
case '緖': return "緒";
case '埈': return "峻";
case '①': return "(1)";
case '②': return "(2)";
case '③': return "(3)";
case '④': return "(4)";
case '⑤': return "(5)";
case '⑥': return "(6)";
case '⑦': return "(7)";
case '⑧': return "(8)";
case '⑨': return "(9)";
case '⑩': return "(10)";
case '⑪': return "(11)";
case '⑫': return "(12)";
case '⑬': return "(13)";
case '⑭': return "(14)";
case '⑮': return "(15)";
case '⑯': return "(16)";
case '⑰': return "(17)";
case '⑱': return "(18)";
case '⑲': return "(19)";
case '⑳': return "(20)";
case 'Ⅰ': return " I ";
case 'Ⅱ': return " II ";
case 'Ⅲ': return " III ";
case 'Ⅳ': return " IV ";
case 'Ⅴ': return " V ";
case 'Ⅵ': return " VI ";
case 'Ⅶ': return " VII ";
case 'Ⅷ': return " VIII ";
case 'Ⅸ': return " IX ";
case 'Ⅹ': return " X ";
case '㎜': return "mm";
case '㎝': return "cm";
case '㎞': return "km";
case '㎎': return "mg";
case '㎏': return "kg";
case '㏄': return "cc";
case '㎡': return "m2";
case '㍻': return "平成";
case '㋿': return "令和";
case '〝': return "“";
case '〟': return "”";
case '№': return "No.";
case '㏍': return "K.K.";
case '℡': return "Tel";
case '㈱': return "(株)";
case '㈲': return "(有)";
case '㈹': return "(代)";
case '㍾': return "明治";
case '㍽': return "大正";
case '㍼': return "昭和";
}
return null;
}
なお、完成したソフトの方は、オンラインソフトウェア流通サイト Vector で無償配布させていただいた。
興味のある人は使ってみて欲しい。
https://www.vector.co.jp/soft/winnt/business/se518540.html
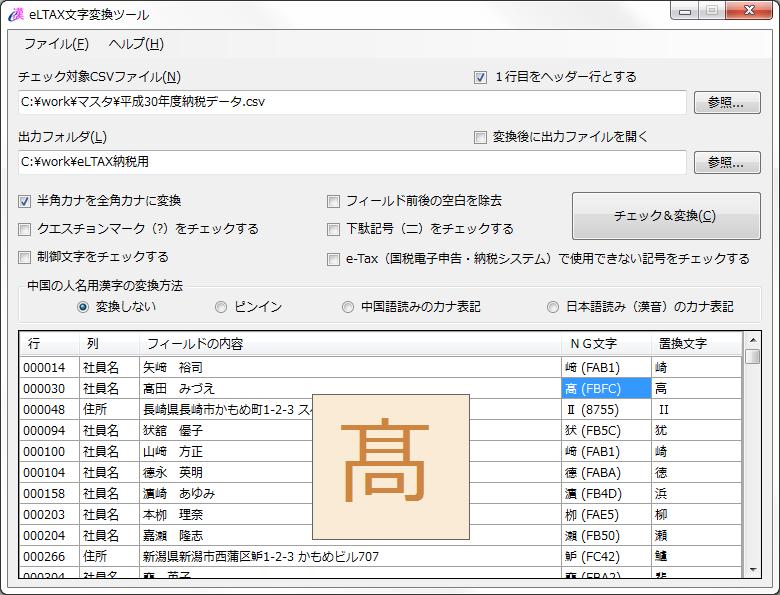
※人名・住所は架空のもの。
参考URL
- ユニコードコンソーシアム JIS X 0208 (1990) to Unicode
http://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/JIS0208.TXT