はじめに
Keccakとはハッシュ関数の一種であり、SHA3に採用されている。比較的新しいハッシュ関数と言って良いと思います。
また、暗号通貨NEMのプロトコル内でも使用されています。
今回はその仕組みを書く。なお、私は各操作の暗号学的根拠はよく分かっていない。
ハッシュ関数とは
https://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%83%E3%82%B7%E3%83%A5%E9%96%A2%E6%95%B0
KeccakとSHA3の関係
https://qiita.com/mincoshi/items/4b8fd450f13637e6a1f2
Keccak概要
Keccakでは、5×5×w (w は 1,2,4,8,16,32,64 のいずれか) の立方体を扱う。この立方体は一つの要素が1bitを表現している。そのため、w = 64 の時は、容量の合計が 1600bit の立方体を扱う。
この立方体に、メッセージを入れたり、立方体の要素を撹拌したり、要素同士の排他的論理和(XOR)を計算したりなんだりして、ハッシュ値を計算していく。

absorb(吸収)とsqueeze(搾取)
KeccakはStateにメッセージを入れていく作業を**absorb(吸収)と呼ぶ。また、Stateからデータを取り出していく(この取り出したデータがハッシュ値となる)作業をsqueeze(搾取)**と呼ぶ
また、吸収・搾取をする間に、Stateの状態を撹拌したり何だりする作業を**Permutation(並び替え)**と呼ぶ。
メッセージをStateに吸収させる時、またStateからデータを搾取するとき、必要なデータを一度に入れるわけではなく、bitrate (またはblock size) と呼ばれる単位にメッセージを切って吸収させる(またはbtrate単位でデータの搾取を行う)。
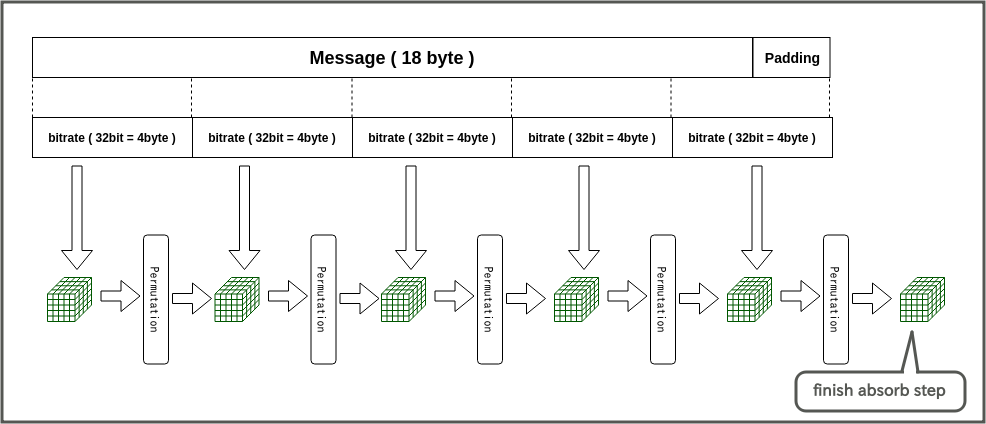
図にもあるが、btrate毎にメッセージを切っていくのは良いが、必ずしも割り切れないときや、そもそもメッセージが空ときがある。このとき、空いている部分をあるルールに従ってパディングする。(メッセージが空の時や、メッセージがbitrateで割り切れた時は、1block丸ごとパディングで作ることになる)
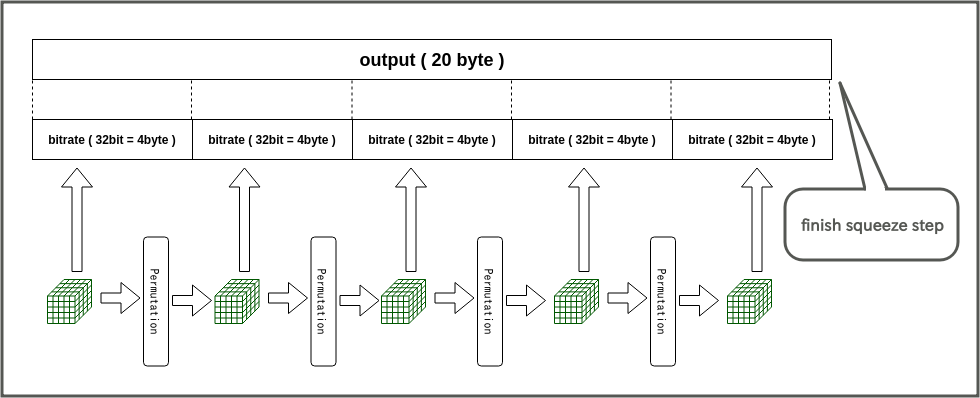
搾取のときも、必要な出力長とbitrateがぴったり合わないときがある(と言うか通常合わない)ので、はみ出した部分は単純に切り落とす。
各要素の名称
立方体をState、Stateの中の各x座標におけるy-z平面をSheet、z軸の配列をLane、などと呼ぶ。
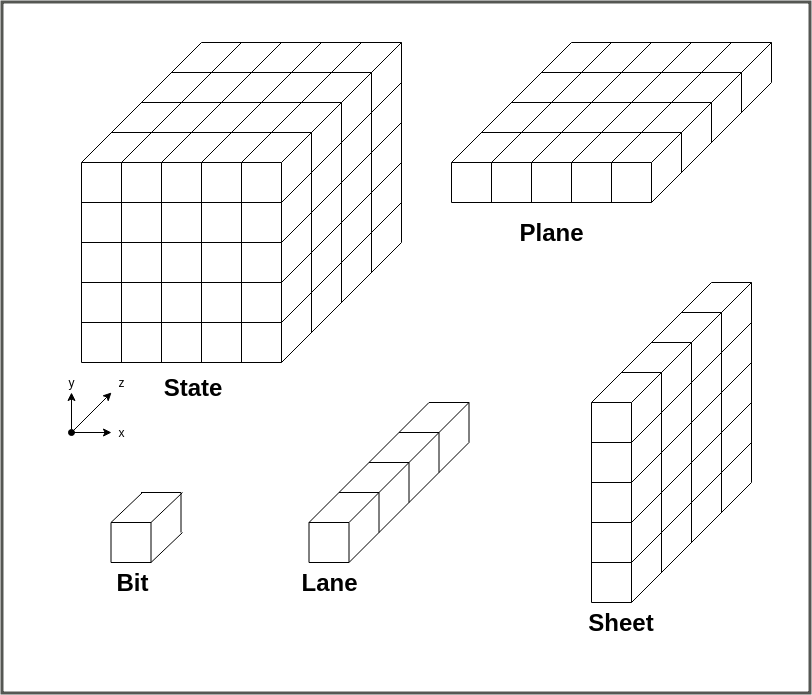
この他にも、y軸の配列をcolumnと呼ぶ。
擬似的なプログラミング言語で表現する
表現すると言っても、KeccakTeamのサイトにわかりやすいものがあるのでそちらをメインに見て欲しい。
https://keccak.team/keccak_specs_summary.html
Pseudo-code description of the permutationsと書かれた部分が、Stateの状態を撹拌する関数の仕組みで、Pseudo-code description of the sponge functionsと書かれた部分が、
- メッセージのパディング
- Stateへのメッセージの差し込みとPermutationによる撹拌
- Stateからメッセージの取り出しとPermutationによる撹拌
を表している。以下、そこにある擬似的なコードをメインにして、補助的な説明を書いていく。
Permutationについて
Permutataionは、Stateの状態を撹拌する関数で、1blockメッセージを挿し込む/読み込む毎に行われる。
Permutationは 5つのステップ によって行われる。θ(シータ),ρ(ロー),π(パイ),Χ(サイ),ι(イオタ)の5つだ。
また、Permutationは上記5つのステップ通して行うことを1ラウンドとし、それを何度も繰り返す。
具体的に何度繰り返すのかと言うと、w (Laneのサイズ)に依存する。
Laneのサイズは1,2,4,8,16,32,64と決められているので、それぞれに対し、12,14,16,18,20,22,24ラウンド繰り返すこととなる。この求め方は、最初に紹介したKccakTeamのサイトのPseudo-code description of the permutationsの真下に書いてある。(n = 12 + 2lというやつ)
θ(シータ)
シータでは、まず最初に全てのcolumnのパリティをとる。
パリティとは、例えば01100110101というビット配列がある時、この配列に1が偶数個あるか奇数個あるかを調べることで、データの誤り検知をする仕組みだ。
ではどうやって01100110101の中に1が偶数個あるか奇数個あるかを調べるのかと言うと、全ての要素のXRO(排他的論理和)を取ることで調べられる。つまり、
0 xor 1 xor 1 xor 0 xor 0 xor 1 xor 1 xor 0 xor 1 xor 0 xor 1
をする。この時、そのビット配列の中に1が偶数個あれば結果は0に、奇数個あれば結果は1になる。
この計算を、State中にある全columnについて行う。
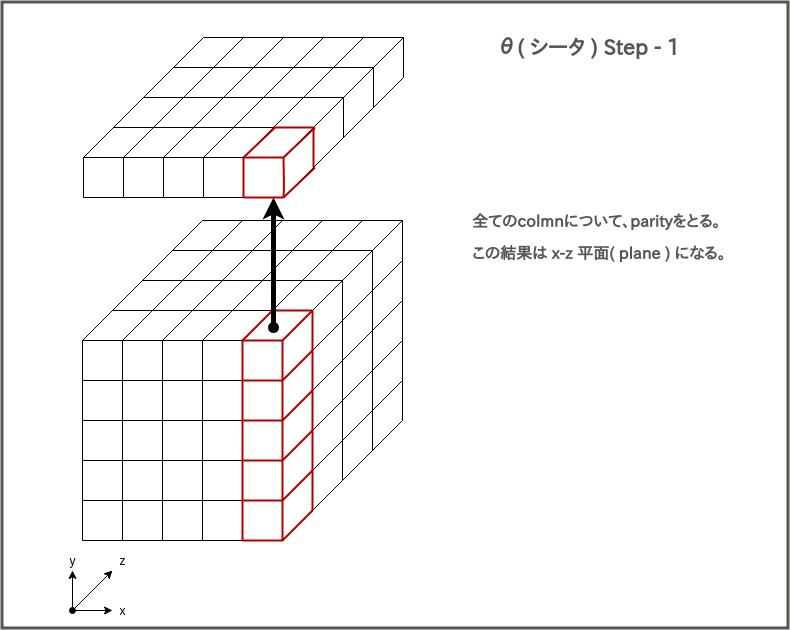
次に、その結果を使って、Stateの全要素について下記図のような計算を行う。
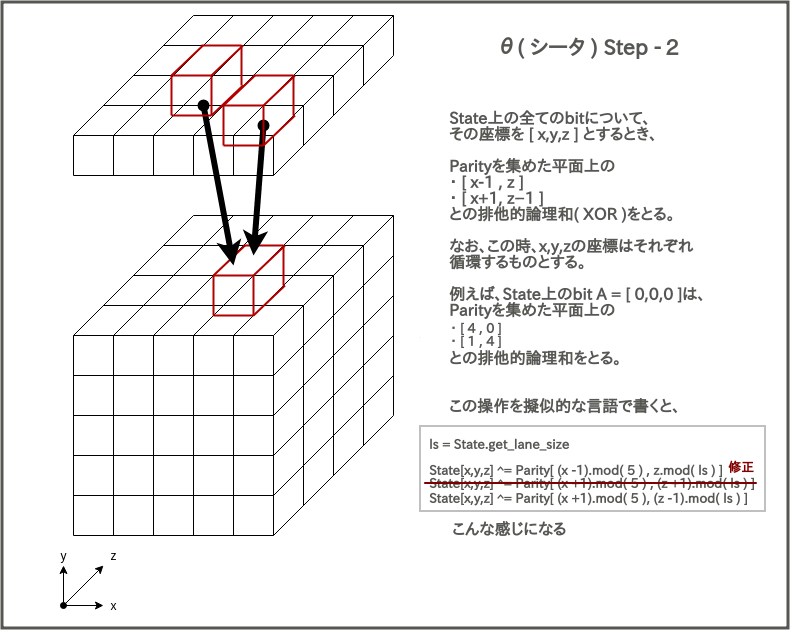
(一部修正しています)
これでシータはおわり。
ρ(ロー)
ローはRotationOffsetと呼ばれる表に従って、Stateの全Laneをローテーションさせる。
π(パイ)
パイは回転行列を使ってStateのLaneを回転させる。
Laneの回転は下記計算式に従ってLaneの差し替えを行うと思えば良い。
元の座標 = [x,y]
先変え先の座標 = [x',y']
[x',y'] = [y,2*x+3*y]
Χ(サイ)
サイでは全てのbitについて、下記計算を行ってその状態を変える
State内のあるbitを B = [x,y,z] とする
(K,Lは一時的な変数)
K = not( B[x+1,y,z] )
L = K and B[x+2,y,z]
B = B[x,y,z] xor L
ι(イオタ)
イオタでは、x=0,y=0のLaneに、Round Contantsと呼ばれるラウンド毎に決められた定数をXORする。Round Constantsは64bitなので、Laneの長さによってははみ出る。はみ出た部分は単純に無視する。
以上、シータからイオタまでを通して行うことで1ラウンドが完了する。これを表現しているのが紹介したサイトの疑似コード、Pseudo-code description of the permutations内でRound[b](A,RC)と表現されている関数部分だ。
また、Round[b](A,RC)関数を指定のラウンド繰り返すことが表現されているのがKeccak-f[b](A)と書かれた関数部分だ。
パディングのルール
メッセージはブロックサイズ(bitrate)ごとに区切られ、最後はパディングで埋められる。パディングは必ず入り、例えばメッセージがブロックサイズで割り切れる場合、パディングによって1ブロック分のデータが最後に作られる。
ではどうやってパディングを行うのか。
この仕組みは単純で、必要なデータのうち、最初と最後のbitを1、間を0で埋めるだけだ。この仕組みはpadding10*1と表現されている。
サンプルを載せておく
# 1byte(8bit)パディングする時
padded = message(bit_array) + 10000001
# 3byte(24bit)パディングする時
padded = message(bit_array) + 100000000000000000000001
しかしここでややこしいのが、SHA3ではメッセージにsuffix(接尾辞)が付くということだ。どういうことかと言うと、例えばSHA3_256では01という2bitの接尾辞がメッセージに付けられ、それに対してパディングが行われる。
KeccakTeamのサイトのStandard instancesに書かれている表のMbitsがそれにあたる。SHAKE128だと、1111という4bitの接尾辞がメッセージに付けられる。
# SHA3_256で3byte(24bit)パディングする時
suffix = 01
padded = message(bit_array) + suffix + 1000000000000000000001
接尾辞を付けたメッセージを新たなメッセージとし、それに対してpadding10*1が行われると考えれば良い。
吸収(absorb)はどのようにして行われるか
ここでは実際に、Stateにブロックサイズ(bitrate)毎に区切ったメッセージをどのように入れるかを書く。
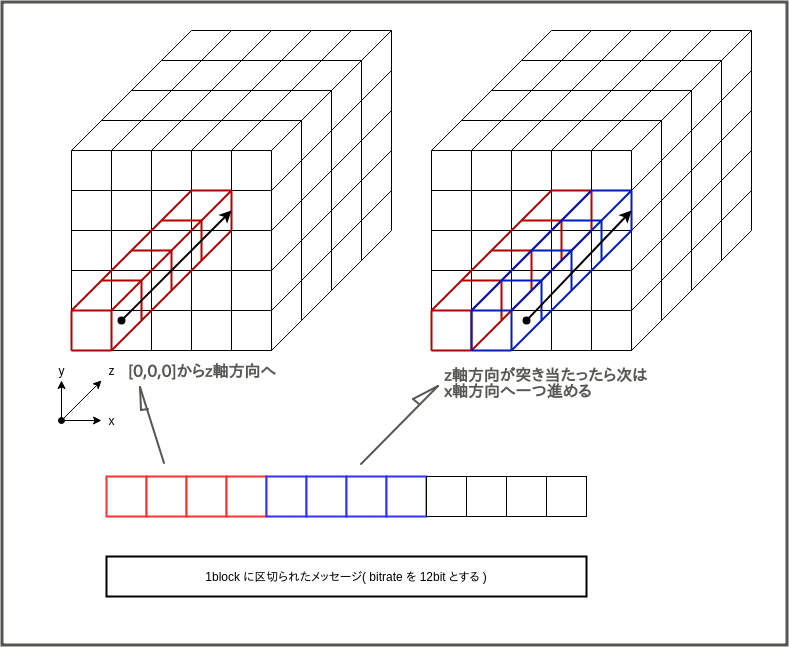
これについては仕組みは簡単で、ブロックごとに区切ったメッセージの各ビットを、Stateの[0,0,0]のbitから順にXORしていく。
まずは[0,0,0]~[0,0,w]のLane、次に[1,0,0]~[1,0,w]、どんどん繰り返し[4,0,w]まで来ると、次は[0,1,0]~[0,1,w]という具合だ。(wはLaneの長さ)
つまり、
- z軸方向に向かってxorしていく
- 突き当りまで行くと一つx座標を進める
- 1,2を繰り返してx座標も突き当り(4)まで行くと、次はy座標を一つ進める
搾取(squeeze)はどのようにして行われるか
搾取は単純に、吸収の時にデータを入れた順番をもって、データを読み込んでいくだけ。とても単純。1ブロック読み込んだら、Permutationで撹拌させて、また同じ位置からデータを読み込む。
必要なデータ長が集まったらそこで終了。集まったデータを繋げたものがハッシュ値となる。
作ってみた
確認のためにrubyで作ってみました。とても非効率でとても遅いです。参考までに。
https://github.com/mijinc0/studying_keccak
SHA_3とKeccak(original)の違いがパラメータ(suffixも含めて)の違いだということがよく分かりました。
参考
わかりやすい
https://www.slideshare.net/KMC_JP/ss-73584867
疑似コードがわかりやすいです
https://keccak.team/keccak_specs_summary.html