あるプロダクトでMySQLを使っていて、Joinを含んだクエリが遅くなっていたので、何か役に立つのではないかと思い
以前目にして気になっていたMySQL8.0.18で実装されたHash Joinを調べたり動かしたりしました。(動かしたのは8.0.20)
Hash Joinとは
テーブル結合するためのアルゴリズムの一つです。
メモリ上でハッシュテーブルを作成して、片方のテーブルを結合条件となるカラムをハッシュテーブルのキーとなるようにハッシュテーブル入れていき、
そして、もう片方のテーブルを上からみていくハッシュテーブルの値と組み合わせて結合表を作っていくアルゴリズムらしいです。
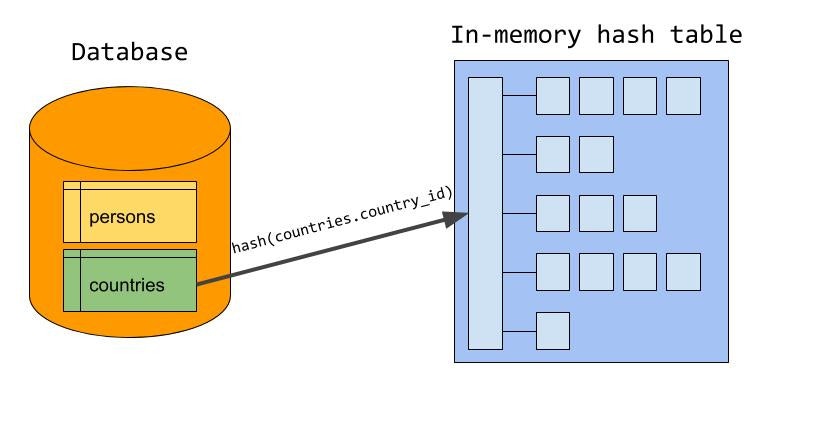
PostgreSQLなどでは以前から実装されていたみたいですが、
MySQLは最近出た模様です。
特徴
(2020/12/09現在)
- 結合条件となるカラムにindexが貼られていない時のみ、Hash Joinが動作する。
- MySQL8.0.20 より前は Inner Joinの等結合の時のみ動作したようですが、今はInner Joinの等結合以外にも対応しているそうです。
https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html - はじめに、片方のテーブルでハッシュテーブルを作成するので、一番最初のレコードができるまではNLJと比べると遅い
- メモリ上にハッシュテーブルを作成するので、メモリ上に乗り切らない場合はディスクに漏れ出し、パフォーマス劣化する。
試してみる
Inner Joinを試してみる。
最初はHash Join
mysql> SELECT version();
+-----------+
| version() |
+-----------+
| 8.0.22 |
+-----------+
mysql> CREATE TABLE t1 (c1 INT, c2 INT);
mysql> CREATE TABLE t2 (c1 INT, c2 INT);
// ダミーデータの注入
mysql> SELECT COUNT(*) FROM t1;
+----------+
| count(*) |
+----------+
| 200000 |
+----------+
mysql> select COUNT(*) FROM t2;
+----------+
| count(*) |
+----------+
| 50000 |
+----------+
mysql> EXPLAIN ANALYZE SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;
+---------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (t1.c1 = t2.c1) (cost=981411409.09 rows=981406159) (actual time=826.891..4981.045 rows=100019 loops=1)
-> Table scan on t1 (cost=0.05 rows=200193) (actual time=0.027..1761.334 rows=200000 loops=1)
-> Hash
-> Table scan on t2 (cost=4942.55 rows=49023) (actual time=0.051..440.221 rows=50000 loops=1)
|
+---------------------------------------------------------------------------------------------------------------------+
1 row in set (5.73 sec)
mysql> SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;
+-------+-------+-------+-------+
| c1 | c2 | c1 | c2 |
+-------+-------+-------+-------+
| 18479 | 69765 | 18479 | 10111 |
....
| 31040 | 15880 | 31040 | 50169 |
| 31040 | 15880 | 31040 | 6474 |
+-------+-------+-------+-------+
100019 rows in set (0.21 sec)
indexを作成して、NLJで試してみる。
mysql> alter table t1 add index (c1);
Query OK, 0 rows affected (0.90 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;
+---------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------+
| -> Nested loop inner join (cost=44301.81 rows=112455) (actual time=0.212..5926.671 rows=100019 loops=1)
-> Filter: (t2.c1 is not null) (cost=4942.55 rows=49023) (actual time=0.079..1150.526 rows=50000 loops=1)
-> Table scan on t2 (cost=4942.55 rows=49023) (actual time=0.040..447.369 rows=50000 loops=1)
-> Index lookup on t1 using c1 (c1=t2.c1) (cost=0.57 rows=2) (actual time=0.025..0.046 rows=2 loops=50000)
|
+---------------------------------------------------------------------------------------------------------------------+
1 row in set (6.67 sec)
mysql> SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;
+-------+-------+-------+-------+
| c1 | c2 | c1 | c2 |
+-------+-------+-------+-------+
| 18479 | 69765 | 18479 | 10111 |
....
| 68326 | 78847 | 68326 | 22370 |
| 68326 | 11900 | 68326 | 22370 |
+-------+-------+-------+-------+
100019 rows in set (0.28 sec)
という感じで、誤差の範囲くらいですが、わずかにHash Joinの方がindexの貼られているNLJより速く動き
十分に高速なことが確認できました。
- メモリ上のみのアクセスになる
- indexだとO(log n)でフェッチしてるところが、ハッシュテーブルなのでO(1)でアクセスできる
とかが速い原因なのかなとか推測してました。(ただ確証は全くないです)
気なってるところ
今後実際使っていくことを考えると、まだまだ調べ足りていないところがあるので、以下は追々調べて行かないとな〜と思っています。
- ディスクに漏れるとどれくらいパフォーマンス劣化するのか
- メモリ上に乗り切るデータの計算方法
- Hash Joinがきく箇所は、手放しでindex貼らなくて済むようになるのか(多分そんなことない)
- ORMとの兼ね合い
- もっと結合を増やしたらどうなる
などなど
感想
正直調べれば調べるほど、自分の知らないところが出てきてHash Joinをさらっと舐めるだけの記事になっちゃいました。
自分自身、開発でHash Joinをメリデメをきちんと整理して実装したりするにはまだもっと調べないといけないことがいっぱいありますが、
MySQL8.0.20からはInner Joinの等結合以外にも使えるようになったので、いい感じに利用していればと思います。
参考にしたドキュメント
https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html
https://mysqlserverteam.com/hash-join-in-mysql-8/