背景
その1の続きです。その1はここです。
Tesseractの原理のあれこれその1 〜Page Layout Analysis〜
一応どんな流れだったかをもう一度説明します。
Tesseractの内部処理は「Page Layout Analysis」と「テキスト判定の2つに分けられます。
概要は以下の通りで、
1、Page Layout Analysis
入力された画像に対し、垂直線と文字以外の画像(図とか写真)の排除および段組や行、単語の領域の特定を行う。
2、テキスト判定
Page Layout Analysisで特定した単語の領域の画像に対して、LSTMベースのニューラルネットワークモデルにより文字を予測する。
となっています。また処理の流れとしては、出力は領域と文字がセットで出力されるので以下図のようなイメージです。
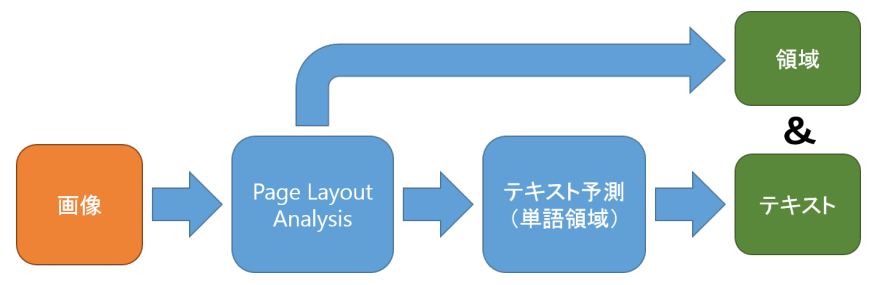
そして今回は2、テキスト予測についてまとめていきます。
はじめに ~資料探し~
まず、サブタイトルを回収しておきましょう。VGSLとは、Variable-size Graph Specification Languageの略で、単語画像からテキストを予測させるためのニューラルネットワークモデルの一種です。このVGSLはCNNとLSTMの2つから構成されており、画像から単語を一気に予測できるのが特徴。つまり、
画像⇒文字(CNN)
⇒文脈⇒単語(LSTM)
ではなく、
画像⇒単語(VGSL)
という処理の流れになっていて、CNNから文字を起こす作業と文脈からの推測が複合されたモデルがVGSLとなっています。また、VGSLに関するWiki①を読んでみると、以下の利点があるみたいですね。
・さまざまなサイズの画像を入力できる。
・画像、連続文字、カテゴリを出力できる。(確か画像出力はまだ対応していないはず)
・畳み込みとLSTMが主な処理要素
・固定サイズの画像もOK!
まあ特に「さまざまなサイズの画像を入力できる」、これが利点として大きい気がします(VGSLの名前はここから来ているのかな)。どうしてこれが可能かは、VGSLの原理を理解すればわかる事です。
それでは本題に入るのですが、その情報が参考文献①と②を参考にしてます。なるべく番号振って説明したいと思います。
参考文献
①VGSL Specs - rapid prototyping of mixed conv/LSTM networks for images
②6. Modernization Efforts
※2020年2月25日時点での調査で、Wikiは不定期的に更新されているので注意してください。
VGSL
さて本題です。VGSLはCNNとLSTMを組み合わせたモデルと述べましたが、決まった形のモデルをVGSLと呼んでる感じではないと思います。CNNとLSTMを含んでいたらVGSLって感覚ですかね。
という事で、おそらくeng.traineddataのVGSLモデルを説明したであろう参考文献②の以下のスライドを元に説明していこうかと思います。
処理の概要はこの画像↓
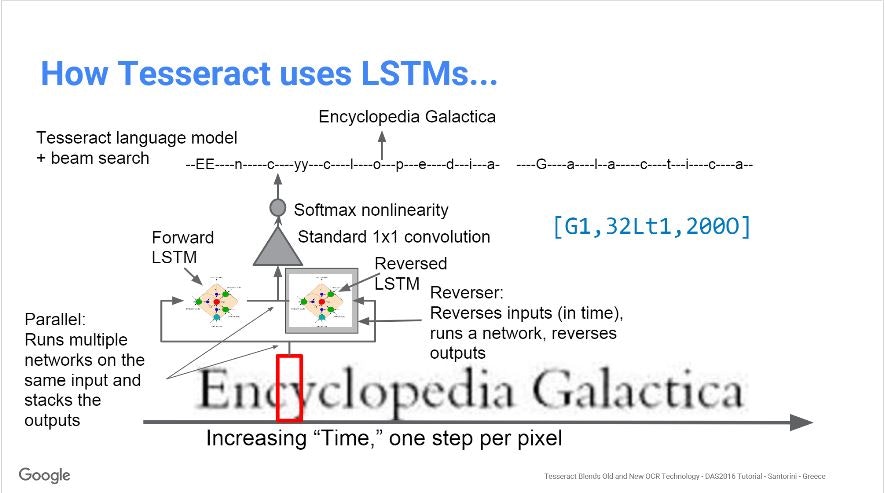
モデルの詳細はこの画像↓
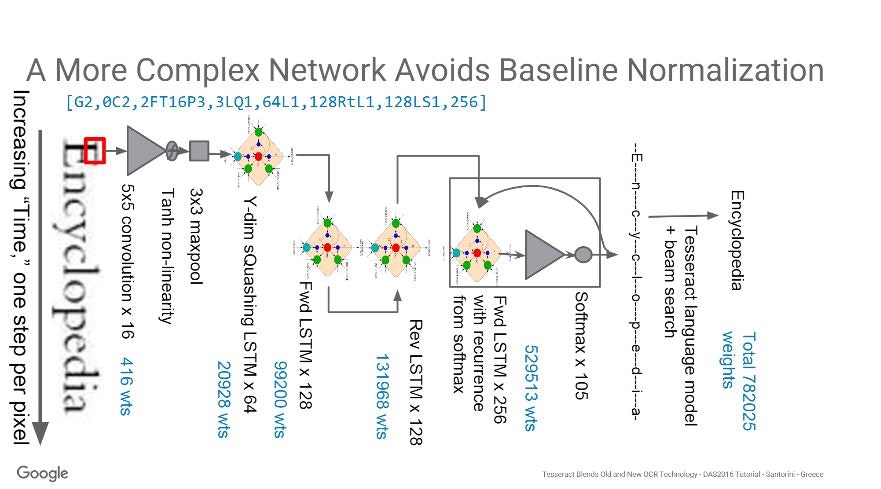
まあ、、、よく分かんないですよね。
調べたところ、最初のCNNとY-dim sQuashing LSTMまで・それ以降のLSTMで特徴量の扱い方が違ってくるのでこういったモデルの概形のみではなかなか伝わらない感じでした。
それでは、大まかに2つに分けてモデルの説明をしていきます。
特徴量抽出その1 ~CNNとLSTMによる画像特徴の抽出~
まず5×5が16層あるCNNと活性関数、3×3のMax Poolingにより、そのエリア(5×5の画素値)の特徴量を抽出します(出力は1つの値)。これがオレンジの特徴量です。そして、縦方向に対して画像の底までそれらの特徴量を抽出します。すると縦方向の特徴量がいくつか得られるので、その特徴量に対してLSTMで予測をかけます。これが緑の特徴量です。
すると、縦方向のCNNによるいくつかの特徴量がLSTMにより5×(縦幅)を代表する特徴量が得られます。
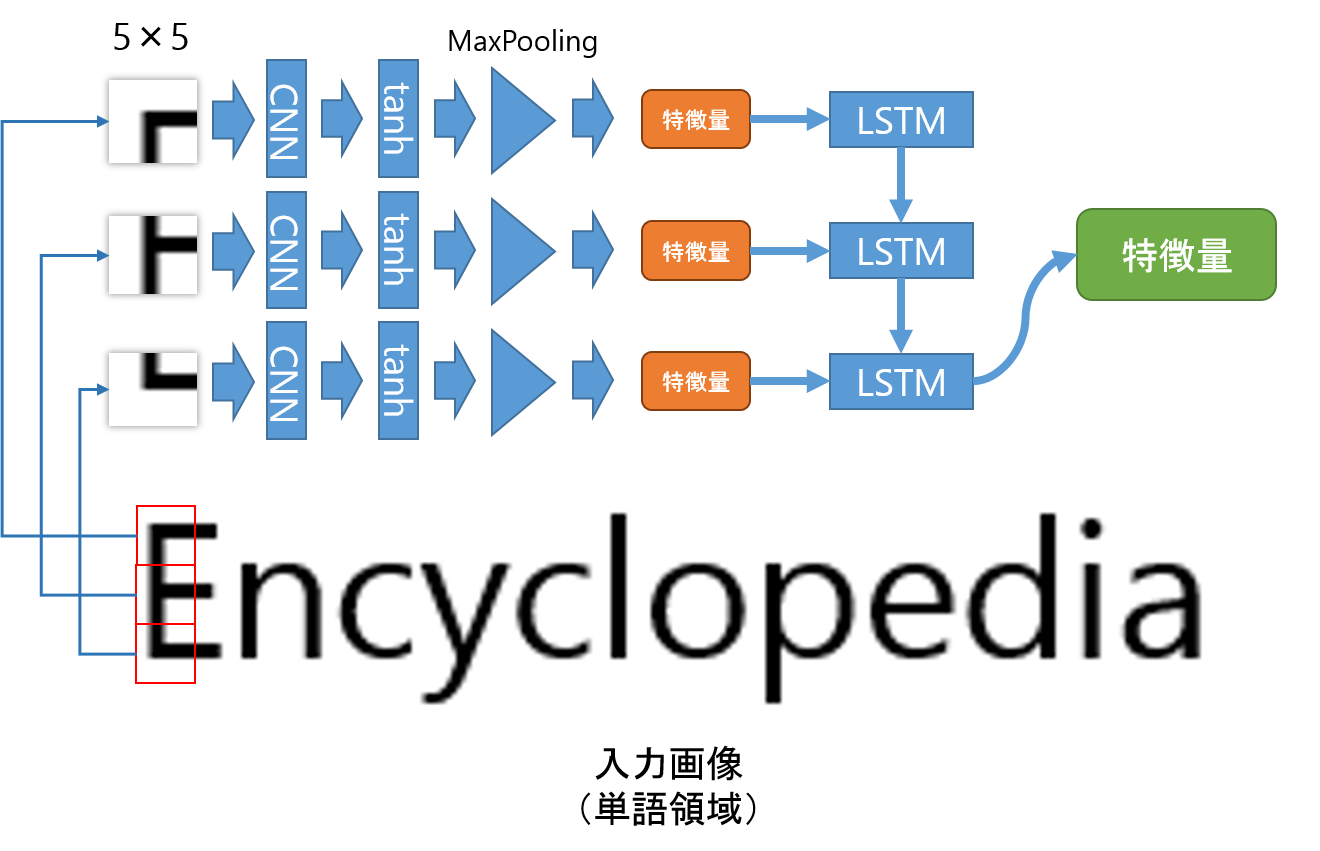
これまでの処理で5×(縦幅)の特徴量を得る事ができましたね。つぎに、この特徴量を横方向に対してすべて抽出します。
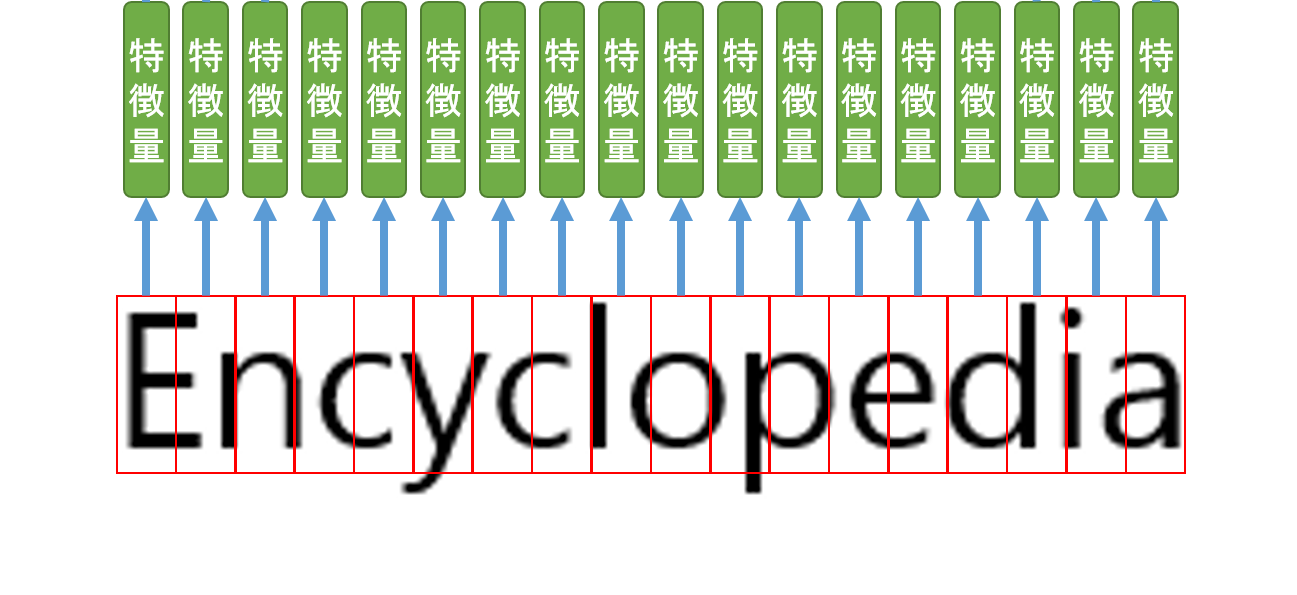
この時点では、これらの緑の特徴量から文字予測までしません。あえて言うなら、「CNNとLSTMをうまく使って、可変な画像に対して画像特徴量を抽出した」という事になるのですかね。
つぎはこの緑の特徴量を用いて予測を行っていきます。
特徴量抽出その2 ~Fwd & Rev LSTMによる文脈的特徴の抽出~
その1で抽出できた特徴量は、まだ隣同士独立した関係ですね。しかし実際には文脈的?というか単語の文字の並びにはある程度規則性がありますよね。(母音であるkは連続する確率は少ない、とか)それらの情報も含めて予測させる為に、その1で抽出された特徴量たちをFwd LSTMとRev LSTMで更新してやるのです。
ここで、FWd LSTMとRev LSTMってなんぞや??ってことなんですけど、LSTMに関する知識が乏しい私が調べた限りよくわかりませんでした。なので、参考資料②から推測しただけなのですが、
LSTMが途中で吐き出す特徴量を出力とするモデル
のことだと考えました。例えば、以下図のようにFwd LSTMはその1で得られた特徴量を左から右方向へ予測をかけていくLSTMと考えます。この際、途中で出力される特徴量(黄色の特徴量)を次のLSTMに処理させる情報とします。
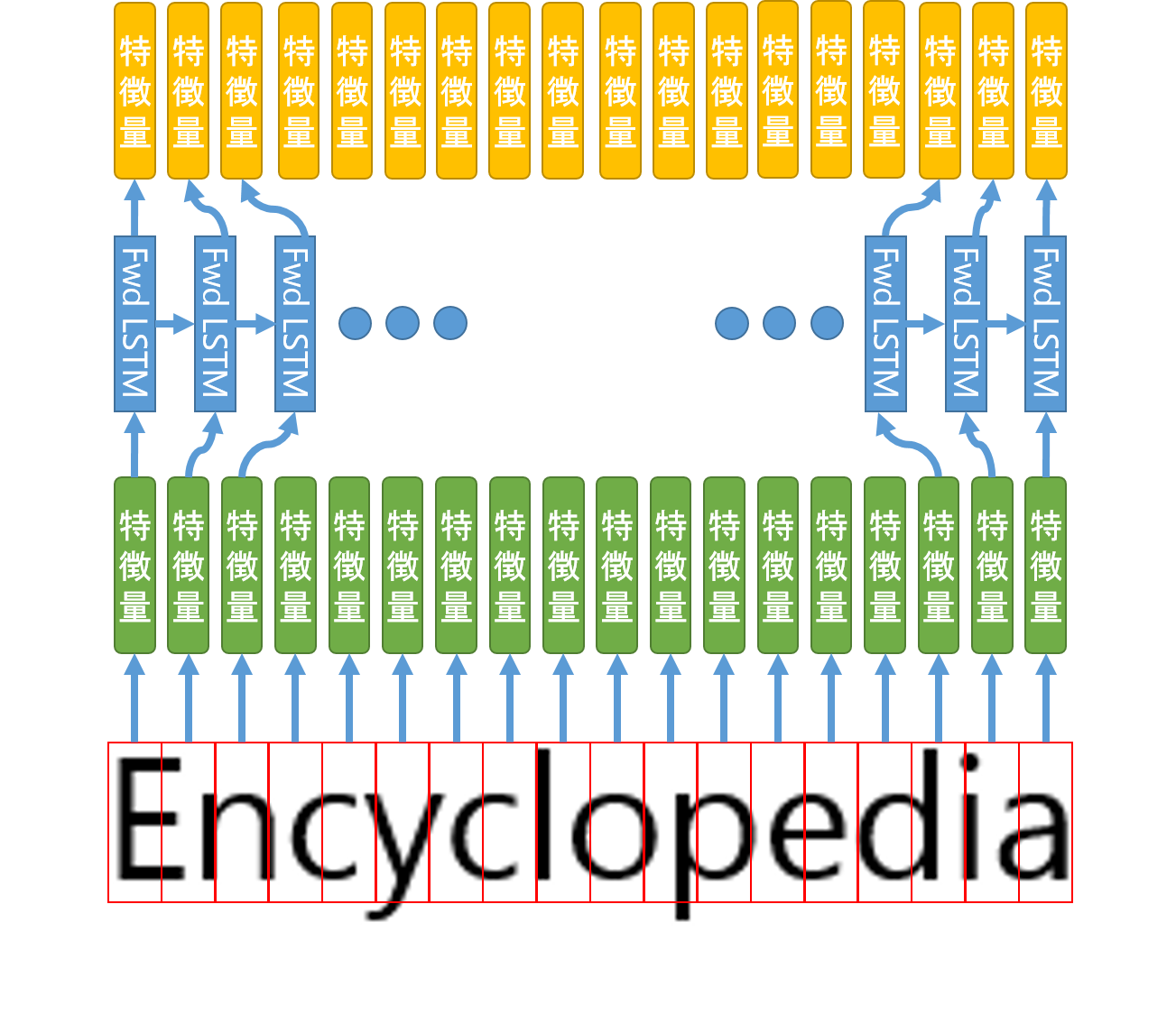
(するとRev LSTMは、右から左に特徴量を予測するモデルとなります)
ということで、モデルの詳細をみると
①Fwd LSTM
②Rev LSTM
③Fwd LSTM
の順番で特徴量を更新しています。そして以下図のように、活性化関数Softmaxで特徴量を処理して文字を予測するのです。
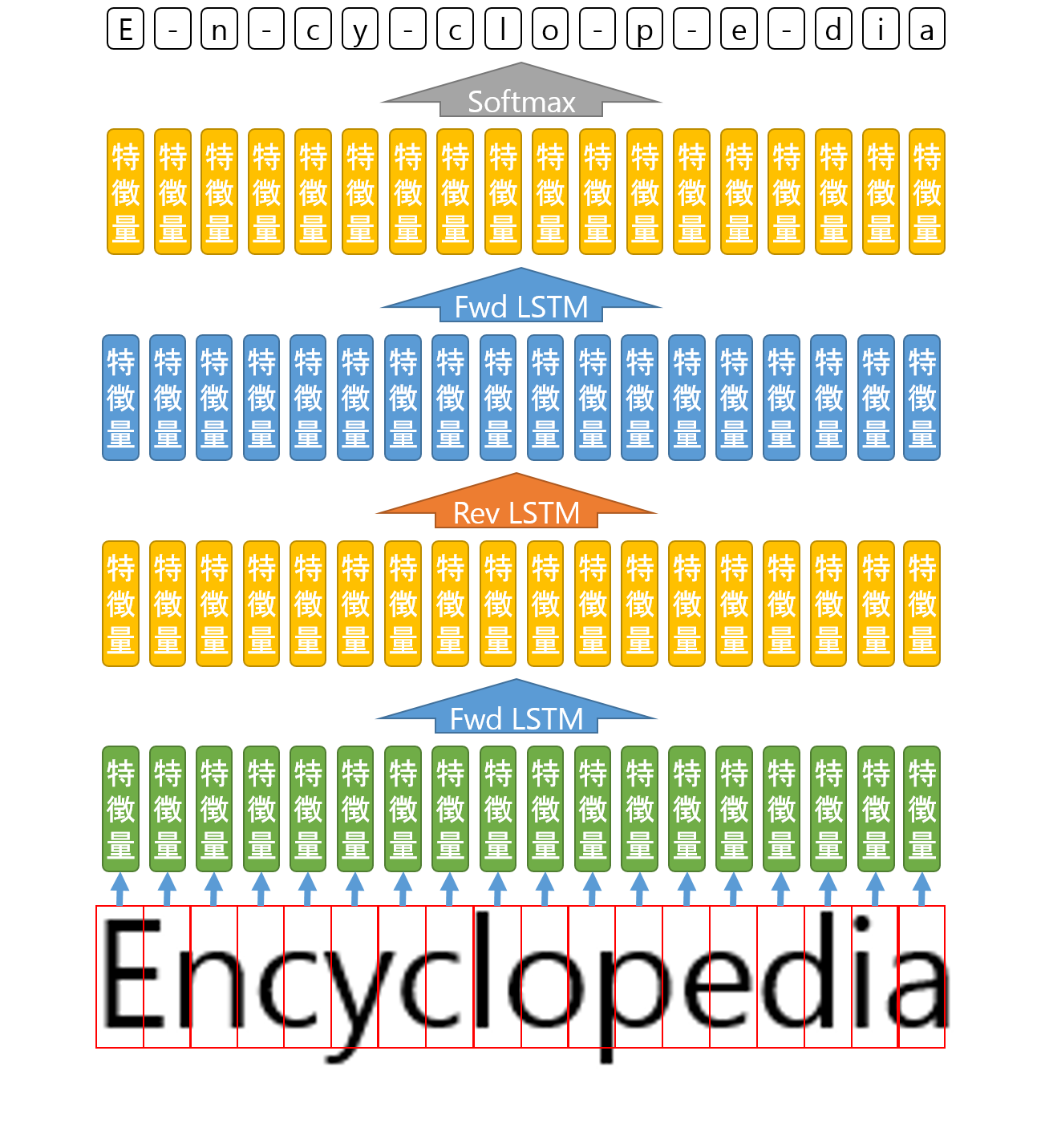
さいごに
いかがだったでしょうか?これがTesseractで使われているVGSLというモデルの詳細です。やはり最大の利点は入力画像のサイズが可変なことと直接文脈的情報も予測できることの2点だと思います。
今回はあえて検証はしませんが、後々モデルの組み立て方についても記事を書きたいと思います。Tesseractをもっと知りたい誰かのためになれば!との思いで書きましたが、憶測が含まれているのでご指摘があれば気軽にコメントお願いします。
それじゃ!