本記事は DMMグループ Advent Calendar 2019 の10日目の記事です。
こんにちは、DMM.comの情報システム部で社内向けのサービスを開発しているmimicknです。
現在はUIにNext.js、APIにはTypeScriptで書いたGraphQL、DBにはneo4jといった構成で従業員管理システムを構築しています。
その中で今回はneo4jに焦点を当てて記事を書きたいと思います。
グラフの構成
今回差分を取るグラフですが下記構成の従業員データベースを例に書いていきたいと思います。
ノード
Employee
| プロパティ名 | 型 | 備考 |
|---|---|---|
| name | String | 従業員の名前 |
| code | String | 社員コード |
| create_date | String | 作成日 |
Affiliation
| プロパティ名 | 型 | 備考 |
|---|---|---|
| name | String | 所属の名前 |
| code | String | 所属コード |
| create_date | String | 作成日 |
Company
| プロパティ名 | 型 | 備考 |
|---|---|---|
| name | String | 会社の名前 |
リレーション
BELONG
| プロパティ名 | 型 | 備考 |
|---|---|---|
| position_name | String | 役職の名前 |
| is_another | Boolean | 兼務フラグ |
| create_date | String | 作成日 |
COMPANY
| プロパティ名 | 型 | 備考 |
|---|---|---|
| create_date | String | 作成日 |
差分を取るグラフ
上記のテーブル定義を元に、今回は以下のグラフ同士の差分をとってみたいと思います。
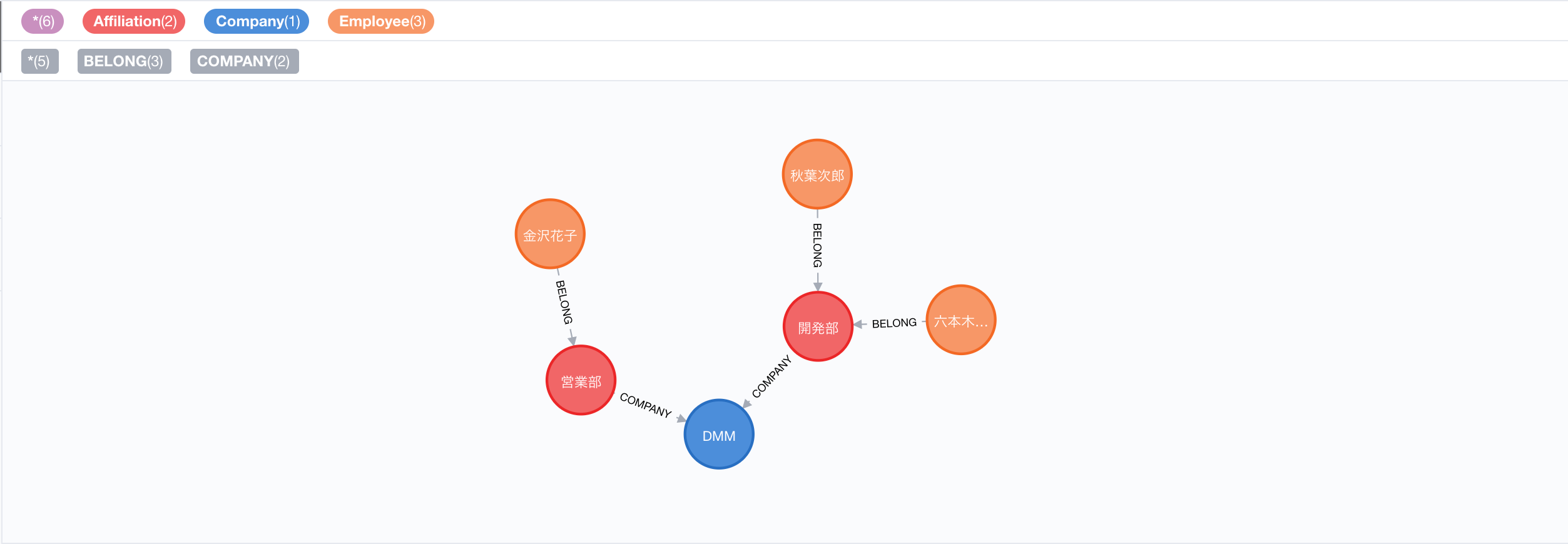
グラフA
グラフB
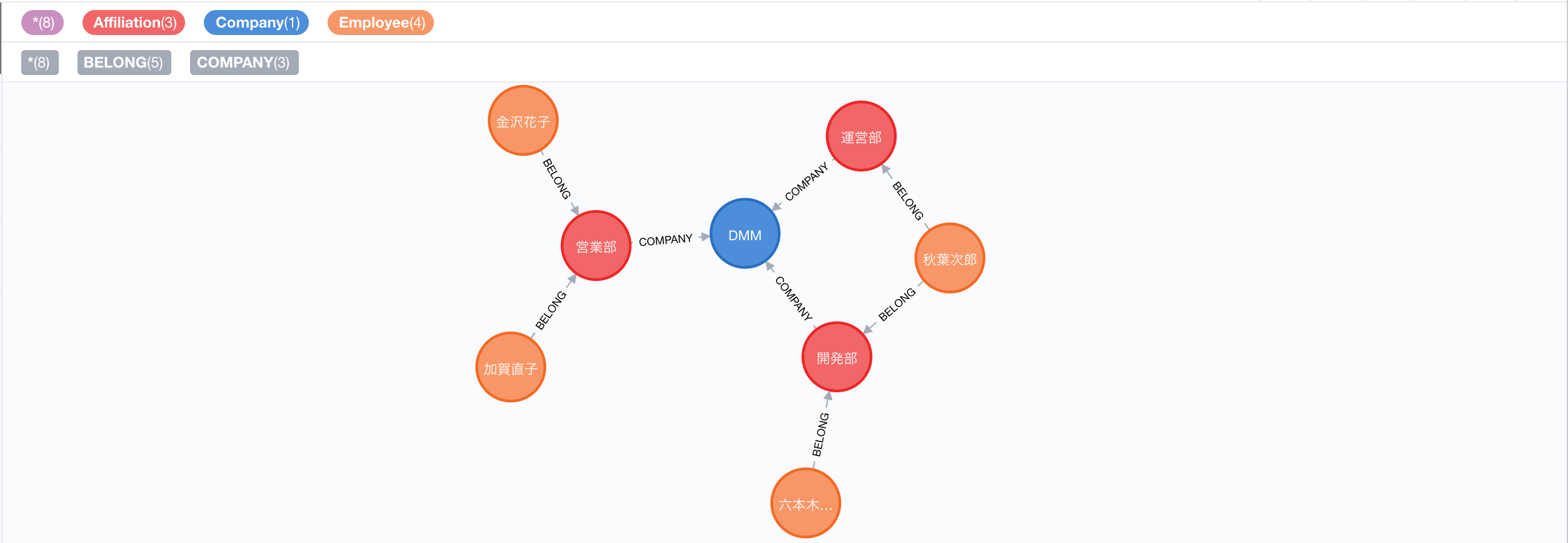
グラフAは2019-11-01時点の従業員データ、グラフBは2019-12-01時点の従業員データとしています。
グラフAとグラフBの差分としては以下になります。
- グラフBでは営業部に加賀さんが増えている
- 秋葉さんはグラフAでは開発部にのみ所属しているが、グラフBでは運営部も兼務している
となります。
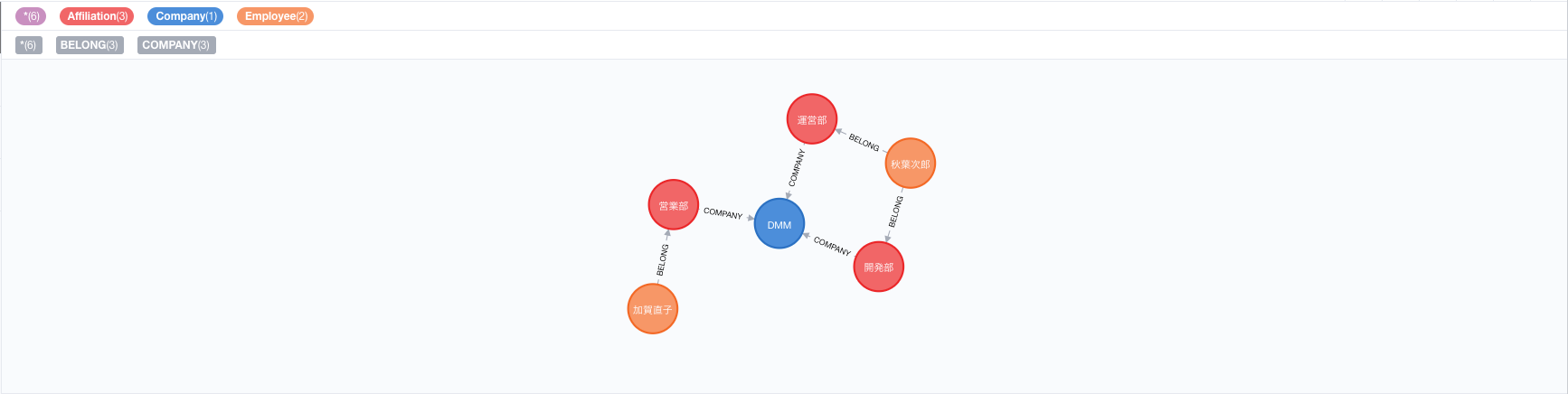
上記より両グラフの差分を取った期待値のグラフは以下とします。
両グラフの差分を取ったときの期待値
差分取るCypher本体
早速ですが、以下がグラフA/グラフBの差分を取るCypherとなります。
MATCH (employee:Employee)
WHERE date(employee.create_date) <= date("2019-11-01")
WITH employee
MATCH (affiliation:Affiliation)
WHERE date(affiliation.create_date) <= date("2019-11-01")
WITH employee, affiliation
MATCH (employee:Employee)-[belong:BELONG]->(affiliation:Affiliation)-[:COMPANY]->(company:Company)
WITH employee, collect(affiliation) AS affiliations,collect(belong) AS belongs, company
WITH collect({ employee: employee, affiliations: affiliations, belongs: belongs, company: company}) AS recordsA
WITH recordsA
MATCH (employee:Employee)
WHERE date(employee.create_date) <= date("2019-12-01")
WITH employee, recordsA
MATCH (affiliation:Affiliation)
WHERE date(affiliation.create_date) <= date("2019-12-01")
WITH employee, affiliation, recordsA
MATCH (employee:Employee)-[belong:BELONG]->(affiliation:Affiliation)-[:COMPANY]->(company:Company)
WITH employee, collect(affiliation) AS affiliations,collect(belong) AS belongs, company, recordsA
WITH collect({ employee: employee, affiliations: affiliations, belongs: belongs, company: company}) AS recordsB, recordsA
RETURN [record IN recordsA WHERE NOT record IN recordsB] AS onlyA, [record IN recordsB WHERE NOT record IN recordsA] AS onlyB
…とまぁいきなりこんな長いもの見せられても何をしているのかわからないと思うので細かく見ていきましょう。
MATCH (employee:Employee)
WHERE date(employee.create_date) <= date("2019-11-01")
WITH employee
MATCH (affiliation:Affiliation)
WHERE date(affiliation.create_date) <= date("2019-11-01")
WITH employee, affiliation
この部分では特定の日付(上の例だと2019-11-01)のSnapshotとしてEmployeeとAffiliationを取得しています。
MATCH (employee:Employee)-[belong:BELONG]->(affiliation:Affiliation)-[:COMPANY]->(company:Company)
WITH employee, collect(affiliation) AS affiliations, collect(belong) AS belongs, company
次にMATCHで各リレーション(BELONGとCOMPANY)と、Companyノードを取得しています。
またその後のWITHでサブクエリに渡す変数を記述しているのですが、
兼務がある関係上一人の従業員が複数所属を持つ場合があるのでcollect関数を使用して
affiliationとbelongをまとめています。
WITH collect({ employee: employee, affiliations: affiliations, belongs: belongs, company: company}) AS recordsA
前半の最後ですが、ここでは今まで取得した値を一つのオブジェクトとして扱うようにマッピングし、また結果のすべてのレコードをリストにしrecordsAとしています。
なぜこのような処理をしているのかですが、今回差分を取る処理でリストで処理をする必要があったためこのようにリスト形式にして結果をまとめています。
MATCH (employee:Employee)
WHERE date(employee.create_date) <= date("2019-12-01")
WITH employee, recordsA
MATCH (affiliation:Affiliation)
WHERE date(affiliation.create_date) <= date("2019-12-01")
WITH employee, affiliation, recordsA
MATCH (employee:Employee)-[belong:BELONG]->(affiliation:Affiliation)-[:COMPANY]->(company:Company)
WITH employee, collect(affiliation) AS affiliations,collect(belong) AS belongs, company, recordsA
WITH collect({ employee: employee, affiliations: affiliations, belongs: belongs, company: company}) AS recordsB, recordsA
後半のRETURNの直前までですが前半とほぼ同じで、違うところは指定している日付と前半の結果をまとめたrecordsAをWITHで持ってきているところです。
さて、ここまででrecordsAとrecordsBをといった形で各グラフの結果を取得することができました。
RETURN [record IN recordsA WHERE NOT record IN recordsB] AS onlyA, [record IN recordsB WHERE NOT record IN recordsA] AS onlyB
最後にそれぞれの結果の差分を取るところです。
ここで出てきた[]構文ですが、List comprehensionと呼ばれ既存のリストに基づいてリストを作るための構文になります。
ここではまずリストrecordsAの要素を一つずつ取り出し、recordsBに含まれていないものだけ返すといった処理をしています。この処理によってrecordsAだけに存在する要素が取り出せます。
次にrecordsBに対しても同様の処理をすることでrecordsBにだけ存在する要素が取得できます。
これによってグラフAだけの結果とグラフBだけの結果が取得でき、グラフ同士の差分を取ることができました!
おわりに
最初はCypherでやるやり方がまったく分からずTypeScriptでゴニョゴニョする方向にしようかと思ってましたが、粘った結果なんとかCypherでグラフ同士の差分を取ることができました…。この方法がどなたかのお役に立てば幸いです。
また今回のこのやり方は一例でしかなく、もっとスマートなやり方もある気がします。
もっと良い書き方を知ってるよ!って方がいればどんどんコメントいただければと思います。
DMMグループ Advent Calendar 2019 明日はkleus_balutさんです。よろしくお願いします!