はじめに
ちょっと前に20年物のC言語で作られたシステムのテストを色々改善しようとしてみたので、この時に得たちょっとした知見を書いていこうと思います。
※注意
記事を書くために自分のパソコンで当時を思い出しながら環境を作っているので、実際、実務でやった環境やバージョンとは違います。
また、この記事にはいくつかコードがでてきますが、すべて記事を書くために考えた疑似的な例にすぎません。
単体テスト用のテストコードの作成
20年も動いているシステムだと、もはや誰にも意味はわからんが、既存の挙動を変えてはいけない箇所がいくつもあります。
そういう箇所に手を入れざるを得ないときに、有効な方法として以下のような方法があります。
まず、既存のコードに対するテストコードを記載します。そして全て合格することを確認してから、少しづつ機能を拡張していきます。
これにより、新規機能追加が既存の機能を壊していないことを確認しながら機能追加の作業を進めることが可能になります。
いわゆるテストファーストになりますが、こういう長い歴史をもつ保守的な環境で、XPで言っていたようなことをやると色々と歪みが出ます。
それについてはこの章の最後に記載します。
xUnitの導入
assert等で自力で頑張ってもいいですが、CUnitなどのxUnitのテストフレームワークを使用した方がいいです。
※今回はCUnitしか検証していませんが、最近のモノだと以下のようなC言語用のユニットテストのライブラリがあるようです。
Cutter(2019-09-13にリリースされた1.2.7が最新)
https://cutter.osdn.jp/index.html.ja
UNITY(2017/11にv2.4.3をリリース。コミット履歴は2019/10のものもある)
http://www.throwtheswitch.org/unity
https://github.com/ThrowTheSwitch/Unity
また、CPPUnitなどのC++用のxUnitのフレームワークからもテストが可能ですが、今回は外しています。
何故xUnitのテストフレームワークが必要か
有名どころのテストフレームワークを使用した方が、実現例とかが世の中で出回っていてトラブル時に助かります。
また、有名どころのテストフレームワークを使用するとJenkinsとの連携が楽になります。
たとえばJenkinsのxUnit Pluginは有名どころのxUnitで出力されたXMLを集計する機能を有しており、簡単に自動テストの結果を集計することが可能になっています。
CUnit
CUnitはC言語用のxUnitのフレームワークでgccやvisual cから使用することが可能です。
visual studio2019でビルドする方法
VS2008とか2005の時代のソリューションしかないのでいかんせ古くてワーニングが出まくります。
- CUnit-2.1-3/VC9/CUnit.slnを開く
- CUnit-2.1-3/CUnit/Headers/CUnit.h.inを基にCUnit.hを作成します。違いは以下の通りです。

- libcunit->その他のプロジェクトの順番でビルドしていきます。
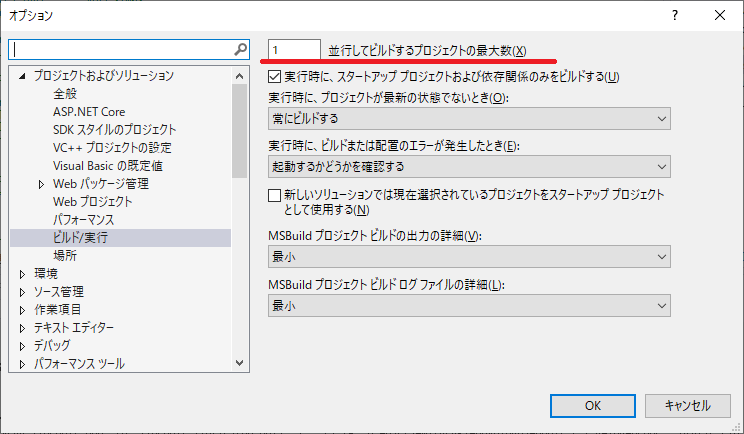
※一度にビルドしてエラーが出る場合は、プロジェクトの依存関係を見直してください。また、プロジェクトの同時ビルド数を1にすると正常にビルドできるようになります。
Visual Stduio2019でプロジェクトの同時ビルド数の確認方法
メニューの「ツール」→「オプション」でオプションダイアログを開き「プロジェクトおよびソリューション」→「ビルド/実行」で該当の画面が表示されます。
makeコマンドでビルドする方法
以下でWindows10 + Ubuntu 18.04の環境下でmakeコマンドを利用してビルドする例を示します。
基本的に以下の記事と同じ方法でビルドできますがバージョンは2.1-3にしています。
CUnitでCプログラムの単体テストをする
https://qiita.com/muniere/items/ff9a984ed7e51eee7112
wget https://jaist.dl.sourceforge.net/project/cunit/CUnit/2.1-3/CUnit-2.1-3.tar.bz2
tar xvf CUnit-2.1-3.tar.bz2
cd CUnit-2.1-3
aclocal
autoconf
automake
./configure
make
make install
トラブルシュート
automakeやautoconfコマンドがない
以下を実行してインストールする。
sudo apt-get install autoconf
configureとか実行すると「configure: error: cannot find install-sh, install.sh, or shtool in "." "./.." "./../.."」というエラーがでる。
下記のコマンドを実行してautoconfからやり直す
autoreconf -i
configure時に「error: Libtool library used but 'LIBTOOL' is undefined」が発生した
以下のコマンドでlibtoolをインストールする。
sudo apt-get install libtool
実行時に「error while loading shared libraries: libcunit.so.1: cannot open shared object file: No such file or directory」が出る場合
環境変数LD_LIBRARY_PATHを設定する。
export LD_LIBRARY_PATH=/usr/local/lib
永続化したい場合は.bashrcにでも記載しておく
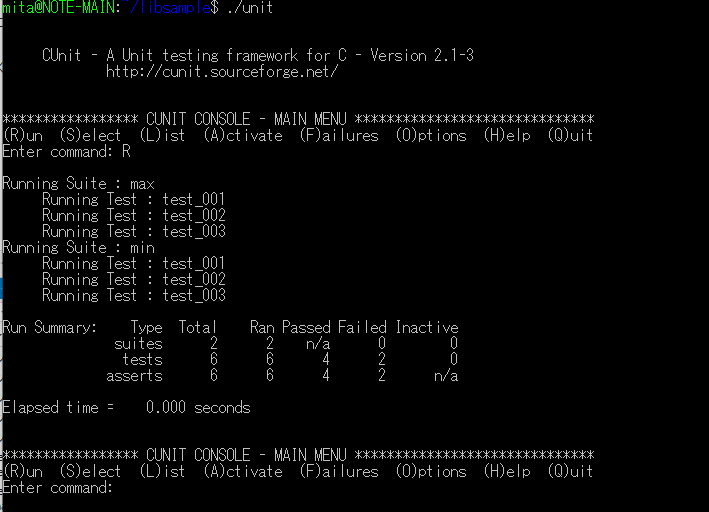
実行例
コンソールで実行する場合は以下のようになります。
# include <CUnit/CUnit.h>
int max(int x, int y) {
if (x>y) {
return x;
} else {
return y;
}
}
int min(int x, int y) {
/** bug **/
if (x>y) {
return x;
} else {
return y;
}
}
void test_max_001(void) {
CU_ASSERT_EQUAL(max(5, 4) , 5);
}
void test_max_002(void) {
CU_ASSERT_EQUAL(max(4, 5) , 5);
}
void test_max_003(void) {
CU_ASSERT_EQUAL(max(5, 5) , 5);
}
void test_min_001(void) {
CU_ASSERT_EQUAL(min(5, 4) , 4);
}
void test_min_002(void) {
CU_ASSERT_EQUAL(min(4, 5) , 4);
}
void test_min_003(void) {
CU_ASSERT_EQUAL(min(5, 5) , 5);
}
int main() {
CU_pSuite max_suite, min_suite;
CU_initialize_registry();
max_suite = CU_add_suite("max", NULL, NULL);
CU_add_test(max_suite, "test_001", test_max_001);
CU_add_test(max_suite, "test_002", test_max_002);
CU_add_test(max_suite, "test_003", test_max_003);
min_suite = CU_add_suite("min", NULL, NULL);
CU_add_test(min_suite, "test_001", test_min_001);
CU_add_test(min_suite, "test_002", test_min_002);
CU_add_test(min_suite, "test_003", test_min_003);
CU_console_run_tests();
CU_cleanup_registry();
return(0);
}
他のASSERT用の関数については下記を参照してください。
http://cunit.sourceforge.net/doc/writing_tests.html
CUnitを実行するソースをコンパイルする際はlibcunit.aにリンクしておいてください。
gcc unit.c -Wall -L/usr/local/lib -lcunit -o unit
コンソールで実行した場合は以下のようになります。
Jenkinsとの連携方法
CUnitの結果をJenkinsに取り込む方法について説明します。
テストコードでXMLを出力するようにする
Jenkinsに渡すXMLファイルを作成するようにコードを変更します。
XMLファイルに出力する場合、CU_console_run_testsの代わりにCU_automated_run_testsとCU_list_tests_to_fileを使用します。
/**略**/
/** コンソール出力
CU_console_run_tests();
*/
/** XML の出力 **/
CU_set_output_filename("./unit");
CU_automated_run_tests();
CU_list_tests_to_file();
CU_cleanup_registry();
/**略**/
上記のファイルを変更してコンパイルして実行するとコンソールに出力する代わりに下記のXMLファイルが作成されます。
- unit-Listing.xml
- unit-Results.xml
CUnitの実行方法の詳細については下記を参照してください。
http://cunit.sourceforge.net/doc/running_tests.html#overview
Jenkinsでテスト結果のXMLを解析するようにする。
プラグインの管理でxUnit Pluginをインストールします。

ジョブの設定でビルド後の処理に「Publish xUnit test result report」を追加してCUnit-2.1を選択します。
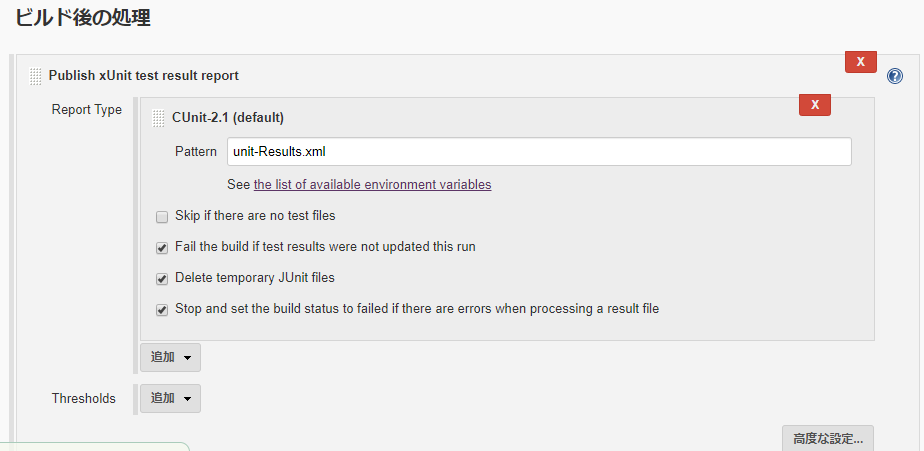
Patternにはunit-Results.xmlを指定してください。
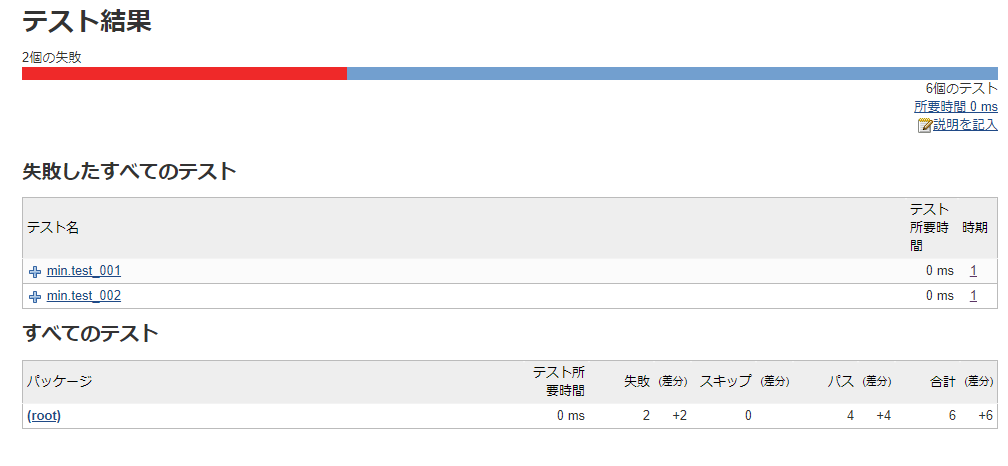
ビルドを実行すると以下のような結果が作成されます。
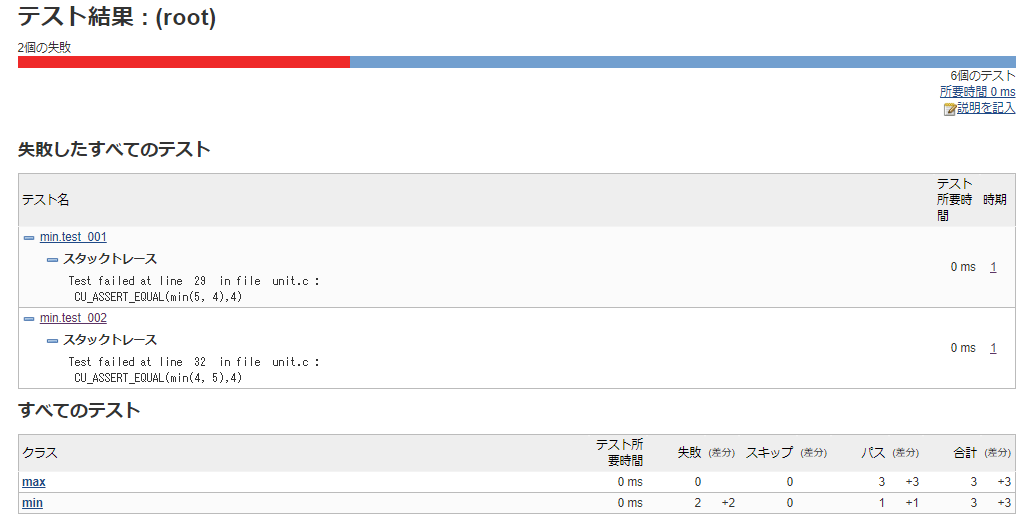
テスト用のスタブの作成
テストを自動化する場合、xUnitのテストフレームワークだけを用意して自動化をしようとすると、導入に失敗するケースが多いです。
単純なユーティリティー関数しかテストできずに廃れていくか、あるいは、依存するライブラリの整合性をとるために複雑なテストコードを記述する羽目になって破綻するかのどちらかです。
たとえば以下のようにライブラリ1に依存するライブラリ2があるとします。
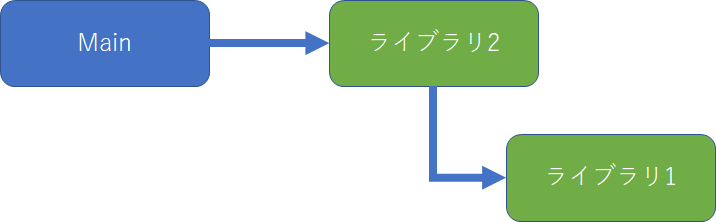
ライブラリ2をテストする場合、ライブラリ1のテスト用のスタブを作成し、ライブラリ2のテストの都合のいいデータを返すようにします。
そうすることで、仮にライブラリ1がネットワークやデータベースに依存していたとしても、実際にはそれらを使用せずにテストに都合のいい状態にすることができます。
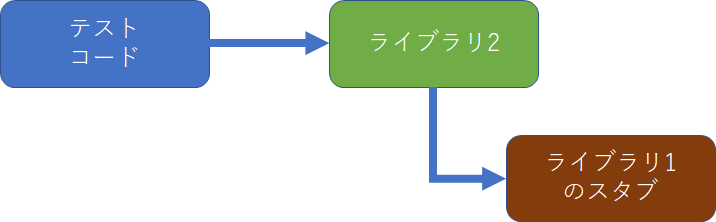
単純なスタブの作成例
単純な例でライブラリ1に依存しているライブラリ2のテストを書く方法について考えてみましょう。
ライブラリ1のサンプル
ライブラリ1は以下のような実装とします。
引数を2つ受け取り、それを加算した結果を返すだけのaddという関数を用意します。
# ifndef STATIC1_H
# define STATIC1_H
extern int add(int x, int y);
# endif
# include "static1.h"
int add(int x, int y) {
return x + y;
}
ライブラリ2のサンプル
ライブラリ2は以下のような実装とします。
ライブラリ2ではproc関数でライブラリ1のadd関数を利用して処理をしています。
# ifndef STATIC2_H
# define STATIC2_H
# include "static1.h"
extern int proc(int x, int y, int z);
# endif
# include "static2.h"
int proc(int x, int y, int z) {
int a = add(x,y);
return add(a, z);
}
ライブラリ1のスタブ
本物のコードの代わりに、スタブを作成します。
このスタブの処理はadd関数が実行されるたびに以下の処理を行います。
・呼び出された回数の記録
・テストコードで事前に登録されたコールバック関数の実行
# ifndef STUB_static1_H
# define STUB_static1_H
# include "static1.h"
typedef int (*pfunc_add_def) ( int x , int y );
typedef struct {
int count_add;
pfunc_add_def pfunc_add;
} stub_data_def_static1;
extern stub_data_def_static1 stub_data_static1;
# endif
# include "stub_static1.h"
stub_data_def_static1 stub_data_static1;
int add ( int x , int y ) {
++stub_data_static1.count_add;
return stub_data_static1.pfunc_add( x , y );
}
テストコードの例
add関数のスタブから実行されるコールバック関数をテストコードに定義して、proc関数を実行する例を以下に示します。
# include <CUnit/CUnit.h>
# include "static2.h"
# include "stub_static1.h"
int test001_stub_add(int x, int y) {
/** add()のスタブ。CUNITでテストするならxとyを **/
if (stub_data_static1.count_add == 1) {
/** 1回目の呼び出し **/
CU_ASSERT_EQUAL(x , 10);
CU_ASSERT_EQUAL(y , 5);
return 15;
}
if (stub_data_static1.count_add == 2) {
CU_ASSERT_EQUAL(x , 15);
CU_ASSERT_EQUAL(y , 4);
return 19;
}
CU_FAIL("addの呼び出し回数不正");
return -1;
}
void test001() {
memset(&stub_data_static1, 0, sizeof(stub_data_static1));
stub_data_static1.pfunc_add = test001_stub_add;
int ret = proc(10, 5,4);
/** 呼び出し回数の確認 **/
CU_ASSERT_EQUAL(stub_data_static1.count_add , 2);
CU_ASSERT_EQUAL(ret , 19);
}
int main() {
CU_pSuite suite;
CU_initialize_registry();
suite = CU_add_suite("stubsample", NULL, NULL);
CU_add_test(suite, "test001", test001);
CU_console_run_tests();
CU_cleanup_registry();
return(0);
}
スタブ用関数が複数回呼び出される場合は、呼び出し回数を元に、スタブが受け取る予定の引数の値をチェックし、スタブが返すべき値を決定します。
スタブの自動作成
前項でスタブを利用した簡単なテストコードの例を紹介しました。
次に問題となるのが、スタブの作成コストです。
手で作成していくことも不可能ではないですが、ライブラリ1の関数が大量にある場合や、更新頻度が多い場合、手で修正していくのは辛いものがあります。
そこで、スタブを自動生成する方法について考えてみましょう。
基本的には単純な変換になります。
そのため、どんなプログラミング言語でもスタブの自動生成できますが、楽をしたいなら、テンプレートライブラリとC言語のパーサーが使えるプログラミング言語がよいでしょう。
Pythonでスタブを自動生成してみる
C言語のパーサーライブラリ
pycparserを使用することでC/C++のソースコードの解析が行えます。
https://github.com/eliben/pycparser
注意事項として、このライブラリはプリプロセッサで処理済みのコードに対してのみしか動作しません。そのため、実際、解析対象とするソースコードは以下のようにプリプロセッサを実行した結果を用いてください。
gcc -E static1.h
今回は以下のようなプリコンパイル済みのヘッダーファイルを解析するものとします。
extern int add(int x, int y);
typedef struct {
int x;
int y;
} in_data_t;
typedef struct {
int add;
int minus;
} out_data_t;
extern void calc(in_data_t* i, out_data_t *o);
extern int max(int data[], int length);
import sys
from pycparser import c_parser, c_ast, parse_file
# https://github.com/eliben/pycparser/blob/master/examples/cdecl.py
def _explain_type(decl):
""" Recursively explains a type decl node
"""
typ = type(decl)
if typ == c_ast.TypeDecl:
quals = ' '.join(decl.quals) + ' ' if decl.quals else ''
return quals + _explain_type(decl.type)
elif typ == c_ast.Typename or typ == c_ast.Decl:
return _explain_type(decl.type)
elif typ == c_ast.IdentifierType:
return ' '.join(decl.names)
elif typ == c_ast.PtrDecl:
quals = ' '.join(decl.quals) + ' ' if decl.quals else ''
return quals + _explain_type(decl.type) + '*'
elif typ == c_ast.ArrayDecl:
arr = 'array'
if decl.dim:
arr = '[%s]' % decl.dim.value
else:
arr = '[]'
return _explain_type(decl.type) + arr
elif typ == c_ast.FuncDecl:
if decl.args:
params = [_explain_type(param) for param in decl.args.params]
args = ', '.join(params)
else:
args = ''
return ('function(%s) returning ' % (args) +
_explain_type(decl.type))
elif typ == c_ast.Struct:
decls = [_explain_decl_node(mem_decl) for mem_decl in decl.decls]
members = ', '.join(decls)
return ('struct%s ' % (' ' + decl.name if decl.name else '') +
('containing {%s}' % members if members else ''))
def show_func_defs(filename):
# Note that cpp is used. Provide a path to your own cpp or
# make sure one exists in PATH.
ast = parse_file(filename, use_cpp=False,
cpp_args=r'-Iutils/fake_libc_include')
if not isinstance(ast, c_ast.FileAST):
return
for ext in ast.ext:
if type(ext.type) == c_ast.FuncDecl:
print(f"function name: {ext.name} -----------------------")
args = ''
print("parameters----------------------------------------")
if ext.type.args:
for arg in ext.type.args:
print(f"{_explain_type(arg)} {arg.name}")
print("return----------------------------------------")
print(_explain_type(ext.type.type))
if __name__ == "__main__":
if len(sys.argv) > 1:
filename = sys.argv[1]
else:
exit(-1)
show_func_defs(filename)
解析処理の簡単な流れとしては、まずparse_fileを実行結果としてFileASTが取得できます。
そこのextプロパティを解析することで、ファイルに定義している関数の情報を取得できます。
上記のプログラムを実行してヘッダファイル中の関数定義を調べた結果が以下のように出力されます。
C:\dev\python3\cparse>python test.py static1.h
function name: add -----------------------
parameters----------------------------------------
int x
int y
return----------------------------------------
int
function name: calc -----------------------
parameters----------------------------------------
in_data_t* i
out_data_t* o
return----------------------------------------
void
function name: max -----------------------
parameters----------------------------------------
int[] data
int length
return----------------------------------------
int
このようにpycparserを使用することでC言語のソースファイルの解析が容易に行えることが確認できました。
テンプレートライブラリ
スタブ用のヘッダファイルとソースファイルを作成する際に、テンプレートライブラリを使用すると作成が楽になります。
Pythonでのテンプレートライブラリについては下記を参考にしてください。
Pythonで久しぶりにHTMLを出力したくなったのでテンプレートについて調べる
https://qiita.com/mima_ita/items/5405109b3b9e2db42332
今回はJinja2を利用しています。
スタブ作成用コード
C言語のパーサーとテンプレートライブラリを使用して、スタブ作成ツールを実装した例が以下のようになります。
import sys
import os
from pycparser import c_parser, c_ast, parse_file
from jinja2 import Template, Environment, FileSystemLoader
stub_header_tpl = """
# ifndef STUB_{{name}}_H
# define STUB_{{name}}_H
# include "{{name}}.h"
{% for func in function_list %}
typedef {{func.return_type}} (*pfunc_{{func.name}}_def) ({% for arg in func.args %}{% if loop.index != 1 %},{% endif %} {{arg.typedef}} {{arg.name}}{{arg.array}} {% endfor %});
{% endfor %}
typedef struct {
{% for func in function_list %}
int count_{{func.name}};
pfunc_{{func.name}}_def pfunc_{{func.name}};
{% endfor %}
} stub_data_def_{{name}};
extern stub_data_def_{{name}} stub_data_{{name}};
# endif
"""
stub_source_tpl = """
# include "stub_{{name}}.h"
stub_data_def_{{name}} stub_data_{{name}};
{% for func in function_list %}
{{func.return_type}} {{func.name}} ({% for arg in func.args %}{% if loop.index != 1 %},{% endif %} {{arg.typedef}} {{arg.name}}{{arg.array}} {% endfor %}) {
++stub_data_{{name}}.count_{{func.name}};
{% if func.return_type != "void" %}
return stub_data_{{name}}.pfunc_{{func.name}}({% for arg in func.args %}{% if loop.index != 1 %},{% endif %} {{arg.name}} {% endfor %});
{% else %}
stub_data_{{name}}.pfunc_{{func.name}}({% for arg in func.args %}{% if loop.index != 1 %},{% endif %} {{arg.name}} {% endfor %});
{% endif %}
}
{% endfor %}
"""
class ParameterData():
def __init__(self, name, typedef):
self.__name = name
self.__typedef = typedef
self.__array = ""
if '[' in typedef:
self.__array = "[" + typedef[typedef.index("[")+1:typedef.rindex("]")] + "]"
self.__typedef = typedef[0: typedef.index("[")]
@property
def name(self):
return self.__name
@property
def typedef(self):
return self.__typedef
@property
def array(self):
return self.__array
class FunctionData:
def __init__(self, name, return_type):
self.__name = name
self.__return_type = return_type
self.__args = []
@property
def name(self):
return self.__name
@property
def return_type(self):
return self.__return_type
@property
def args(self):
return self.__args
# https://github.com/eliben/pycparser/blob/master/examples/cdecl.py
def _explain_type(decl):
""" Recursively explains a type decl node
"""
typ = type(decl)
if typ == c_ast.TypeDecl:
quals = ' '.join(decl.quals) + ' ' if decl.quals else ''
return quals + _explain_type(decl.type)
elif typ == c_ast.Typename or typ == c_ast.Decl:
return _explain_type(decl.type)
elif typ == c_ast.IdentifierType:
return ' '.join(decl.names)
elif typ == c_ast.PtrDecl:
quals = ' '.join(decl.quals) + ' ' if decl.quals else ''
return quals + _explain_type(decl.type) + '*'
elif typ == c_ast.ArrayDecl:
arr = 'array'
if decl.dim:
arr = '[%s]' % decl.dim.value
else:
arr = '[]'
return _explain_type(decl.type) + arr
elif typ == c_ast.FuncDecl:
if decl.args:
params = [_explain_type(param) for param in decl.args.params]
args = ', '.join(params)
else:
args = ''
return ('function(%s) returning ' % (args) +
_explain_type(decl.type))
elif typ == c_ast.Struct:
decls = [_explain_decl_node(mem_decl) for mem_decl in decl.decls]
members = ', '.join(decls)
return ('struct%s ' % (' ' + decl.name if decl.name else '') +
('containing {%s}' % members if members else ''))
def analyze_func(filename):
ast = parse_file(filename, use_cpp=False,
cpp_args=r'-Iutils/fake_libc_include')
if not isinstance(ast, c_ast.FileAST):
return []
function_list = []
for ext in ast.ext:
if type(ext.type) != c_ast.FuncDecl:
continue
func = FunctionData(ext.name, _explain_type(ext.type.type))
if ext.type.args:
for arg in ext.type.args:
param = ParameterData(arg.name, _explain_type(arg))
func.args.append(param)
function_list.append(func)
return function_list
if __name__ == "__main__":
if len(sys.argv) != 3:
print("python create_stub.py プリプロセス実行済みヘッダ 出力フォルダ")
exit(-1)
filename = sys.argv[1]
dst_folder = sys.argv[2]
function_list = analyze_func(filename)
if len(function_list) == 0:
print("関数を見つけることができませんでした")
exit(-1)
data = {
'name' : os.path.splitext(filename)[0],
'function_list' : function_list
}
# スタブのヘッダーファイルの作成
with open(f"{dst_folder}/stub_{data['name']}.h", mode='w', encoding='utf8') as f:
f.write(Template(stub_header_tpl).render(data))
# スタブのソースファイルの作成
with open(f"{dst_folder}/stub_{data['name']}.c", mode='w', encoding='utf8') as f:
f.write(Template(stub_source_tpl).render(data))
このツールを利用して作成したスタブは以下の通りです。
# ifndef STUB_static1_H
# define STUB_static1_H
# include "static1.h"
typedef int (*pfunc_add_def) ( int x , int y );
typedef void (*pfunc_calc_def) ( in_data_t* i , out_data_t* o );
typedef int (*pfunc_max_def) ( int data[] , int length );
typedef struct {
int count_add;
pfunc_add_def pfunc_add;
int count_calc;
pfunc_calc_def pfunc_calc;
int count_max;
pfunc_max_def pfunc_max;
} stub_data_def_static1;
extern stub_data_def_static1 stub_data_static1;
# endif
# include "stub_static1.h"
stub_data_def_static1 stub_data_static1;
int add ( int x , int y ) {
++stub_data_static1.count_add;
return stub_data_static1.pfunc_add( x , y );
}
void calc ( in_data_t* i , out_data_t* o ) {
++stub_data_static1.count_calc;
stub_data_static1.pfunc_calc( i , o );
}
int max ( int data[] , int length ) {
++stub_data_static1.count_max;
return stub_data_static1.pfunc_max( data , length );
}
C言語のパーサーが利用できないとき
Pythonが使えなかったりC言語のパーサーが利用できなかったりする状況もよくあります。
そういう場合は、doxygenを利用します。
Doxygenはソースファイルを解析して関数の情報をXMLに出力することができます。このXMLをもとにスタブ用のファイルを作成することも可能です。CやC++をやっている現場の多くはdoxygenを使用しているケースが多いので、おそらくPython使うよりは導入の障壁が低いと考えられます。※
※なお、私はDoxyge+VBSでスタブを作っていました。
その他スタブやモックの作成方法について
実際には採用しませんでしたが、以下のような方法もあります。
CMock
https://github.com/ThrowTheSwitch/CMock
Rubyを使用してモック用のコードを作成する模様。当該環境でRubyが使えるならありかもしれません。
C言語のテストでスタブ関数を使うためのアイデア
https://qiita.com/HAMADA_Hiroshi/items/e1dd3257573ea466d169
「既存ソースに手を入れずに同一ソース内の関数をスタブにしてユニットテストを実施する方法」をまとめたもので、基本的な考えはマクロを駆使して既存関数を別名に置き換えるということをやっています。
幸い、同一ソース内の関数を呼ぶようなテストを書く必要がなかったので実際には採用していません。
網羅率の計測方法
テストコードを記述した場合、そのテストコードが網羅している割合を計測することで、もれなくテストを実行しているかを判断することが可能になります。
幸いなことにgccにはgcovという網羅率を計測するツールがついています。
10 gcov—a Test Coverage Program
https://gcc.gnu.org/onlinedocs/gcc/Gcov.html
gcov の使い方
https://mametter.hatenablog.com/entry/20090721/p1
カバレッジの計測例
先ほど使用したスタブの例でカバレッジを計測してみます。今回はわざと未到達なルートを作るため、ライブラリ2のstatic2.cを以下のように修正します。
# include "static2.h"
int proc(int x, int y, int z) {
int a = add(x,y);
return add(a, z);
}
int proc2() {
/** 未到達 **/
return 0;
}
その後、カバレッジを計測するために-coverageオプションを付与してコンパイルをします。
gcc -c -Wall -Wextra static2.c -coverage
ar r libstatic2.a static2.o
gcc -c -Wall -Wextra stub_static1.c
ar r libstub_static1.a stub_static1.o
gcc test.c -coverage -Wall -Wextra -L. -lstatic2 -lstub_static1 -L/usr/local/lib -lcunit -o test
上記のコマンドを実行すると以下のファイルが作成されます。
- static2.gcno
- test.gcno
- test
その後、testを実行することでさらに以下のファイルが作成されます。
- static2.gcda
- test.gcda
テスト対象のstatic2.cのカバレッジを調べるには以下のコマンドを実行します。
gcov static2.gcda
このコマンドを実行すると下記のメッセージが表示されます。
File 'static2.c'
Lines executed:60.00% of 5
Creating 'static2.c.gcov'
ここで網羅率が60%であることが確認でき、さらにどこが網羅されていないかを調べるにはstatic2.c.gcovを表示します。
今回の例ではproc2が通っていないことが確認できます。
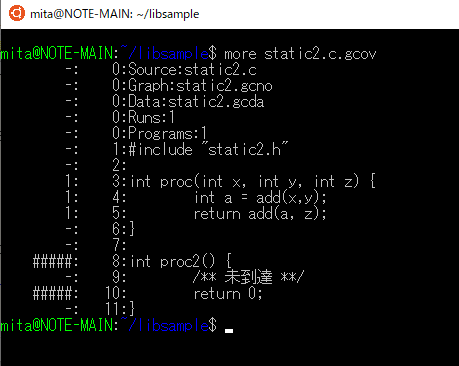
その他自動テストについて
効果について
以下の点で効果的と判断します。
・現状の機能の挙動を変えずに機能を拡張する際のリスクが抑えられる
・テストコードを記載することで、今まで闇の中だった機能を明確にできる。
・テストコードを書くと既存コードの中に眠り続けてきた不具合を検出できる
→直すかどうかは別問題。発生頻度や発生時の影響度と修正コストの兼ね合い。
ただ、幾つの点で課題があるのでそれについては次項で考えていきましょう。
SQLの試験はどうするの?
レガシーな環境だと、ソースコードにSQLを書いていて、実際それをデータベースにつなげて動かさなければテストにならないことがあります。
この場合、開発者毎に使用するDBの領域を区切って単体テストを行うのが望ましいです。
しかしながら、大きな組織だとDBを専門に扱う部門があったりして、安易にデータベースをいじれなかったりします。
またローカル環境にデータベース自体を入れるとした場合、貧弱なPCがネックになったり、仮にそれを突破しても、個人の環境でデータベースの管理を任せた場合、開発者によっては古い環境を使い続けたりするリスクもあったりします。
こういう時は自動テストが終わったらロールバックするという意識の低い方法で対応することができます。
①自動テスト開始
②DBのトランザクションを開始する
③テスト用のデータをDBに格納
④自動テストを行う
⑤自動テストの結果でDBがどう変わったか確認
⑥DBのロールバック
この方法は完璧な案ではありませんが、実現が容易な案です。
大量の組み合わせテスト
構造体の配列で入力値と期待値を書いておいておけば大量のテストが行えます。
よく使う手としてはExcelで入力と出力の一覧を書いておいて、VBAのマクロでC言語の構造体の配列に変換してテストコードに書き込むやり方があります。
保守的なウォーターフォールな環境でテストファーストを行う歪み
保守的なウォーターフォールな環境で採用されている方法だと、実装が終わった後に、単体テストのテスト仕様書やチェックリストを作成して、テストを実施することになります。
しかし、テストファースト的なことをやると、実装完=単体テスト完になるので、ここで歪みが発生してしまいます。
計画が従来の線に乗らない
従来の方式だと実装、単体テスト用チェックリスト作成、単体テストの実施の3つの工程にわけてスケジュールの線を記述します。
そして、高度に管理された完全で完璧な組織だと、それぞれの工程の時間をきっちり計測します。
テストファースト的なことをやると、実装から単体テストがり分けることのできないものになるので、個別の作業時間が計測不能となり、適当に分けて報告することになります。
単体テスト仕様書
従来の方法で作成していた単体テスト仕様書やチェックリストの取り扱いをどうするか決める必要があります。
テストコードのコードレビューをもってOKとし、単体テストの成果物としてはテストコードとするという判断ができればいいのですが、レガシーな環境だと書類が大事です。
この場合、テストコードからテスト仕様書やチェックリストといったものを作成する必要があります。
1つ目の対応策としては、テストコードの内容を手でチェックリストに転記していくという方法です。
問題点は、テストコードとテスト仕様書の同期がとれなくなっていくことです。
また、この方法は自動でテストを実行する利点をなくす非常にまずい対応ですが、時間さえかければ誰でもできるのでよく採用されます。
2つ目の方法は、テストコードのコメントからテスト仕様書を起こす方法です。
テストコードのコメントにテストの内容を記載しておいてDoxygen等で抜き出した結果をチェックリストにまとめます。
この場合、コメントと実際の処理の食い違いが発生するリスクがあります。
3つ目の方法は、テストコード中に指定するテスト名にチェックリストに出力しても違和感のない日本語を書いてしまう方法です。
CU_add_test(max_suite, "max(a,b)を実行してa=5,b=4の場合、aの値が取得されることを確認する", test_max_001);
上記のように記載してテストを実行するとテスト結果のXMLには以下のように出力されます。

あとは、XMLをチェックリストの出力してしまえば完了です。
この方法の問題点は、CU_ASSERT_EQUALなどで行うチェック内容はXMLに出力されないので、チェックリストの粒度が大きくなってしまう点です。
4つ目の方法としては、CU_ASSERT_EQUALなどをラップする関数を作成して、その関数内で、チェックリストに出力しやすい形で検査内容をファイル出力してしまう方法です。
いずれの方法をとるにせよ、書面にこだわられると面倒臭いので注意しましょう。
→書面にこだわる文化のところでは、そういう作業分もちゃんと見積もりに乗せるようにしましょう。
単体テストでの障害票の取り扱い
実装を終了した時点で単体テストが終わっているので、単体テストでの障害を上げるのは不可能になっています。
とはいえ、高度に管理された完全で完璧な組織だと単体テストの障害件数を重視する場合があります。
この場合は、実装中に出た問題を、それっぽいバグとして適当にでっちあげることになります。
本来あるべき論としては説得して新しいルールを作ることですが、文化がちがうので無理だと思います。
テスト件数の桁が変わるので従来の指標が役に立たなくなる
自動テストを導入すると組み合わせ系のテストを機械的に大量に処理できるようになります。
結果、従来の方法で行ったテストの件数より自動で行ったテストの件数が多くなります。(それこそ桁違い)
いままで精々数百のチェックリストの項目数だったものが、普通に千とか万とかになります。
「テストを大量にやってなにが悪いのかね」という話なんですが、高度に管理された完全で完璧な組織だと異常値扱いされるので、粒度を適当に調整して、報告用のそれっぽい件数に調整したりする必要があったりします。
なお、まっとうな対応をするのであるならば、自動テストは別集計として新しい指標を作っていくのが筋でしょう。
結合テスト以降の障害が従来より減るので異常値扱いされる
単体テストを網羅的にやると、結合テストでもなかなか不具合がでなくなります。
これはこれで問題になります。
たとえば、従来、何十件も障害が発生していたところ、不具合件数がほぼでなくなったとしたとしましょう。
数値しか見てない場合、結合テストの観点が間違っているんじゃないだろうかという疑念を抱く人がいてもしょうがないでしょう。
テストコード書きたがらない人が多い
以下でも書きましたが、そういうもんです。あきらめましょう。
意識が高くないVisualStudioを使用した単体テストの自動化
https://qiita.com/mima_ita/items/05ce44c3eb1fd6e9dd46
自動テストの効果を工数や品質で利を説いたり、金額に換算して危機感あおったり、教育用の資料を用意することはできますが、正直、そんな話をいくら積んだところで通じない文化には全く通じません。
ただし、どんな組織においても、志のある人間というのが少数ながらいるモノなので、そういう人間に期待しましょう。
静的解析
前項で自動テストの話をしました。
これは結局、テストコードを書いた範囲を実際に動かしてチェックしているにすぎません。
この項では、実際にテストコードを書いて動かすことなく、怪しげな実装箇所を見つける方法について説明します。
静的解析ツールで怪しい箇所を見つける
静的解析ツールを使用することで怪しげな実装をしている箇所を検出可能です。
お高いツールを使うと効果的な発見をしてくれますが、オープンソースでも十分効果的です。
C言語の場合だとCppCheckを使用することができます。
http://cppcheck.sourceforge.net/
cppcheckはWindowsからGUIで動かすこともできますし、linuxでCUIベースに動かすこともできます。
コマンドラインから使用する方法
Windows10 + Ubuntu 18.04の環境下でcppcheckを使用する方法を説明します。
まず下記のコマンドでインストールします。
sudo apt-get install cppcheck
インストールが完了したら以下のようなコマンドを実行することでcppcheckが実行されます。
$ cppcheck --enable=all .
Checking cov.c ...
1/7 files checked 14% done
Checking main.c ...
2/7 files checked 28% done
Checking static1.c ...
3/7 files checked 42% done
Checking static2.c ...
4/7 files checked 57% done
Checking stub_static1.c ...
5/7 files checked 71% done
Checking test.c ...
6/7 files checked 85% done
Checking unit.c ...
7/7 files checked 100% done
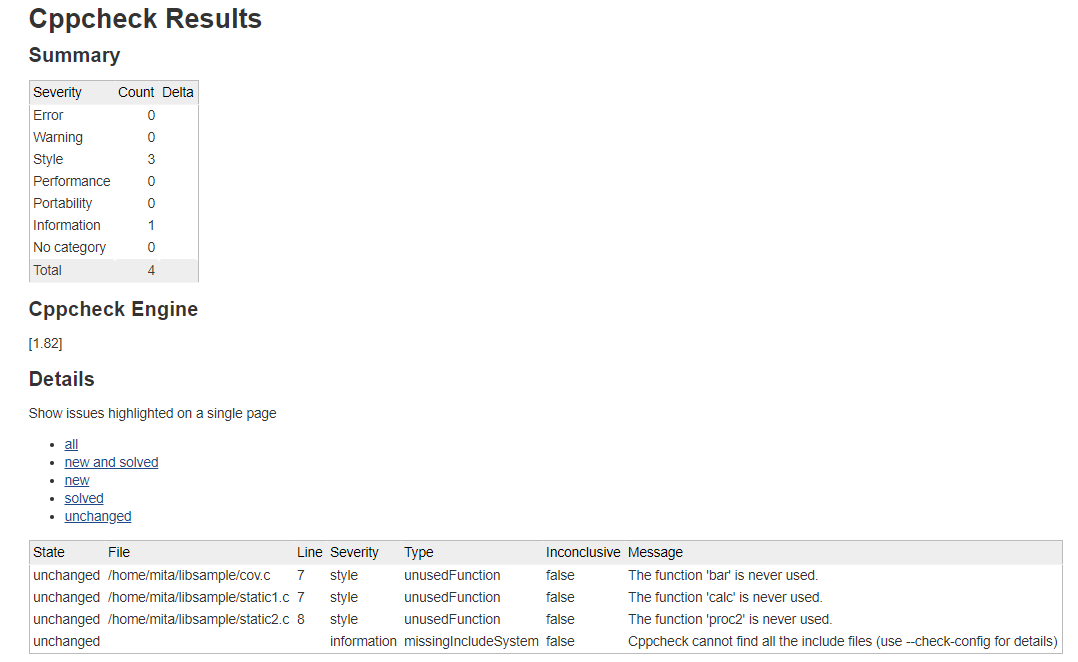
[cov.c:7]: (style) The function 'bar' is never used.
[static1.c:7]: (style) The function 'calc' is never used.
[static2.c:8]: (style) The function 'proc2' is never used.
(information) Cppcheck cannot find all the include files (use --check-config for details)
WindowsのGUIでcppcheckを使用してみる
(1)以下のページからInstallerをダウンロードしてください。
http://cppcheck.sourceforge.net/
(2)インストール後、CppCheckを起動すると以下のような画面が開きます。
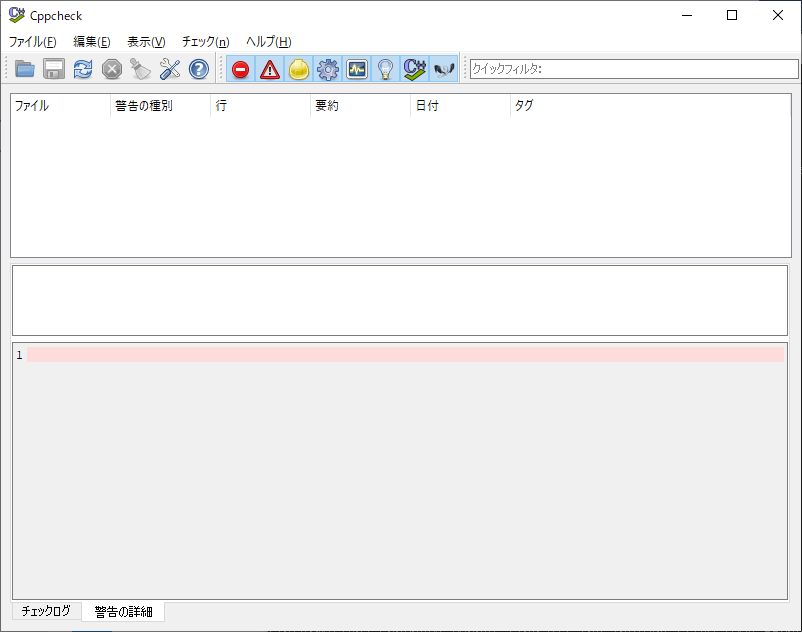
(3)メニューから「ファイル」→「新規プロジェクト」を選択します。
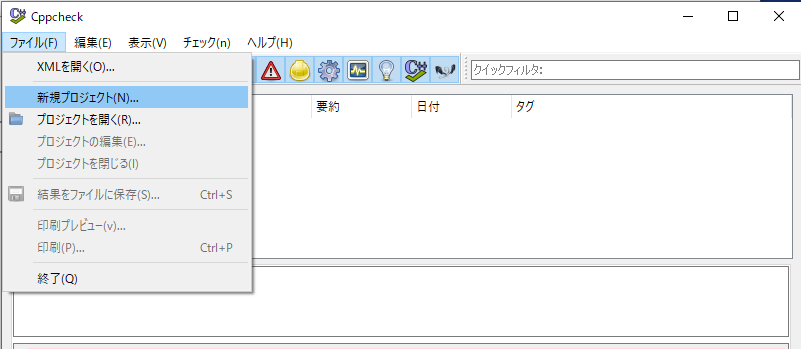
(4)プロジェクトファイルを保存する任意のパスを設定して「保存」を押下します。
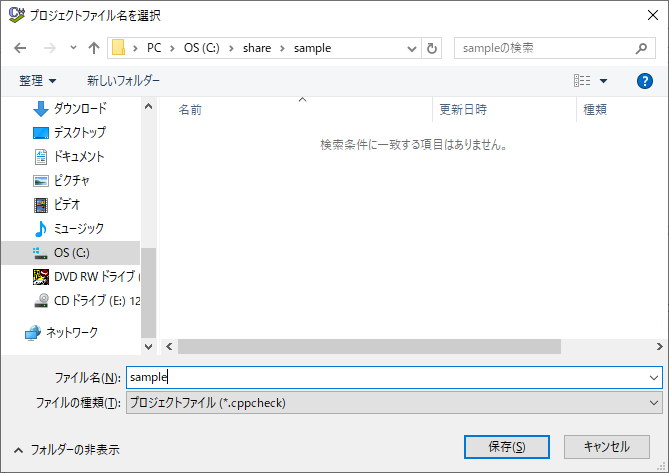
(5)「プロジェクトファイル」ダイアログが開くので「追加」ボタンを押下してC言語のソースファイルがあるパスを追加してください。
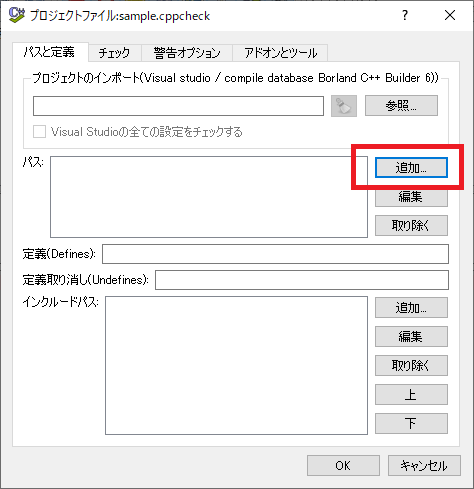
(6)「プロジェクトファイル」ダイアログでOKを押下すると、ビルドディレクトリを作成するか聞かれるので「Yes」を選択します。
(7)指定したディレクトリ以下のCファイルが列挙されます。
(8)列挙されたファイルのツリー構造を展開すると警告の詳細が表示されます。
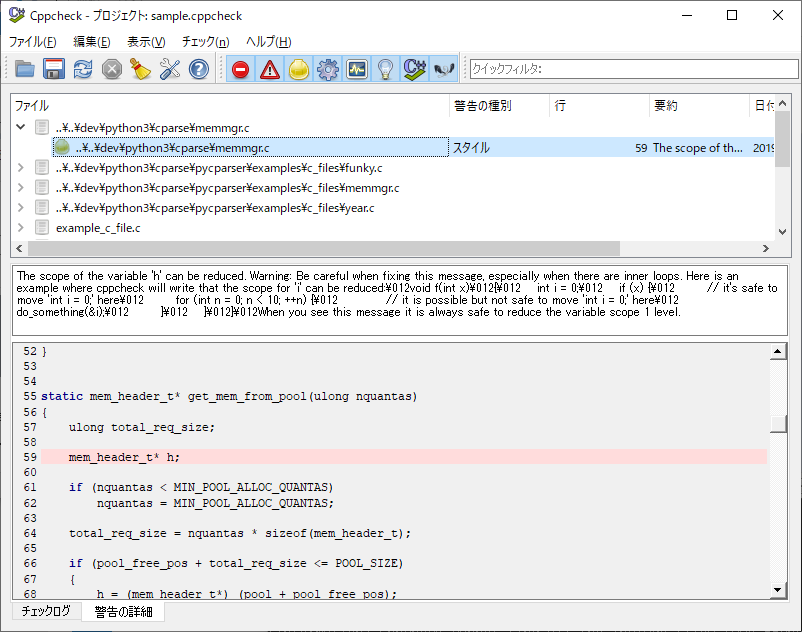
Jenkinsとの連携
JenkinsのCppcheck Plulginを使用することでCppCheckの結果をJenkinsで集計させることが可能です。
https://plugins.jenkins.io/cppcheck
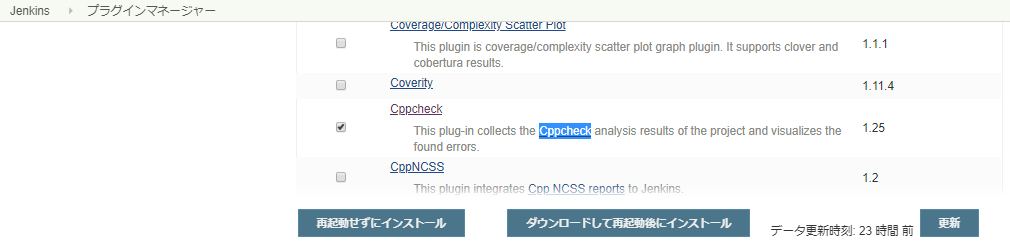
(1)JenkinsのプラグインマネージャーでCppCheckを選択してインストールします。
(2)cppcheckを以下のように実行してxmlで結果を取得します。
cppcheck --enable=all --xml --xml-version=2 ~/libsample/. 2>cppcheck.xml
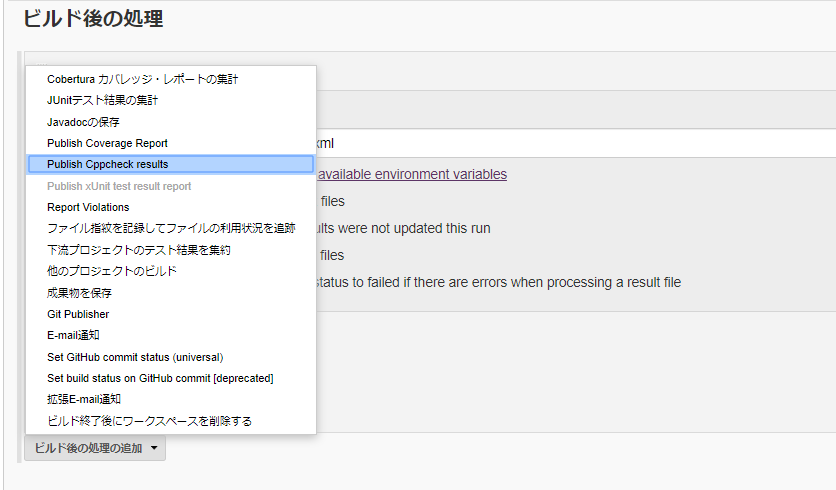
(3)ビルド後の処理にPublsh Cppcheck resultsを追加します。

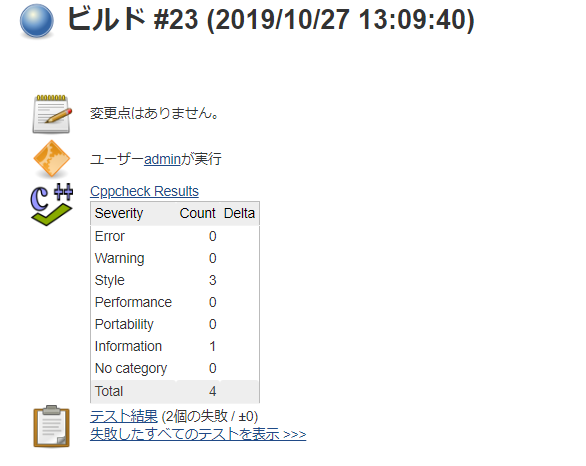
(4)ビルドを実行すると、結果にCppCheckの項目が表示されます。
メトリクスを計測する
ソースコードのステップ数や、循環的複雑度はソースコードの品質を予測するための一つの指標になります。
循環的複雑度(Cyclomatic complexity)
https://ja.wikipedia.org/wiki/%E5%BE%AA%E7%92%B0%E7%9A%84%E8%A4%87%E9%9B%91%E5%BA%A6
循環的複雑度は簡単にいうと、ループや分岐が多いほどこの複雑度は高くなります。
複雑度が高ければ高いほどバグを含む可能性が高くなるので、この指標をもとにテストを重点的に行うべき場所にあたりをつけることができます。
Source Monitor
Source MonitorはC ++、C、C#、VB.NET、Java、Delphi、Visual Basic(VB6)で書かれたソースコードのメトリクスを計測することが可能なフリーソフトです。
(1)下記のページからダウンロードして任意のフォルダに展開してください。
http://www.campwoodsw.com/sourcemonitor.html
(2)展開されたSourceMonitor.exeを実行すると以下のような画面が表示されるので「Start SourceMonitor」を選択してください。
(3)メトリクスを集計するプロジェクトを作成するのでメニューから[File]->[New Project]を選択します。
(4)「Select Language」ダイアログが開くので「C」を選択して「次へ」を押下します。
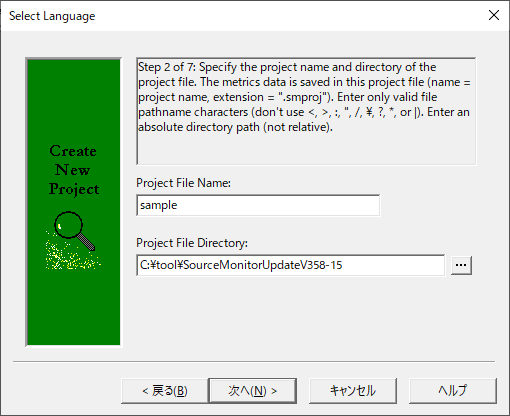
(5)プロジェクトファイルのファイル名と格納するフォルダを指定して「次へ」を押下します。
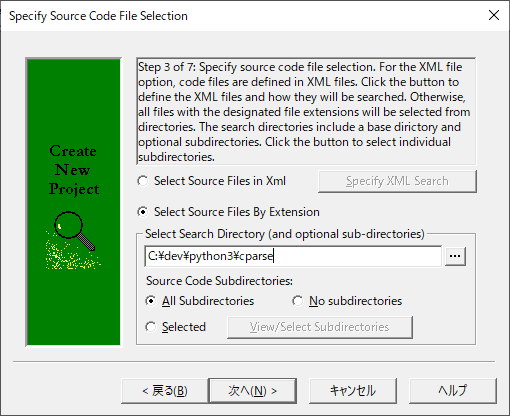
(6)解析対象のソースコードを含むフォルダを指定して「次へ」を押下します。
(7)オプションを選択し「次へ」を押下します。
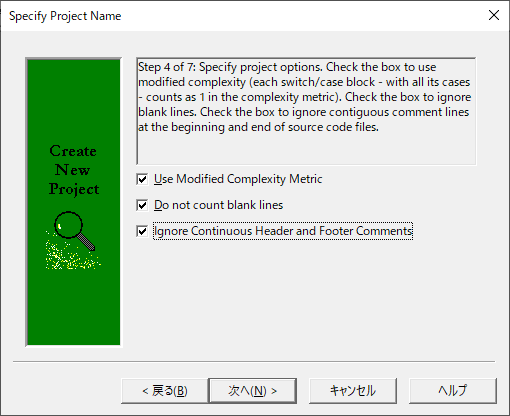
| オプション | 説明 |
|---|---|
| Use Modified Complexity Metrix | デフォルトの複雑度メトリックは、各switchステートメント内のcaseをカウントして計算していますが、チェックをONにすることで各switchブロックは1回だけカウントされるようになり、個々のcaseステートメントはModified Complexityに寄与しなくなります。 |
| Do not count blank line | 行数を数える際に、空行を無視します。 |
| Ignore Continuous Header and Footer Comments | CVSやVisual SourceSafeなどのバージョン管理ユーティリティによって自動的に生成されたファイル履歴などの情報を含む連続したコメント行を無視したい場合にチェックをつけます。 |
(8)「次へ」を押下します。
(9)UTF8のファイルを含むなら、「Allow parsing of UTF-8 files」にチェックを付けて「次へ」を押下します。
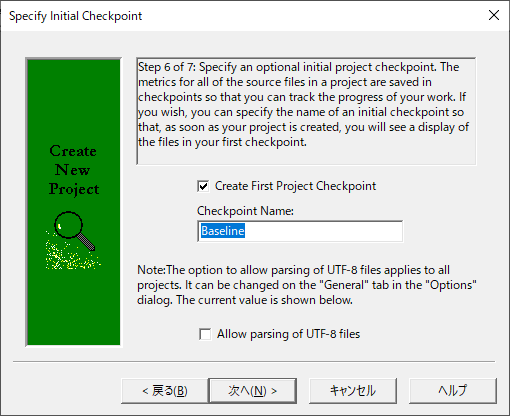
(10)「完了」を押下します。
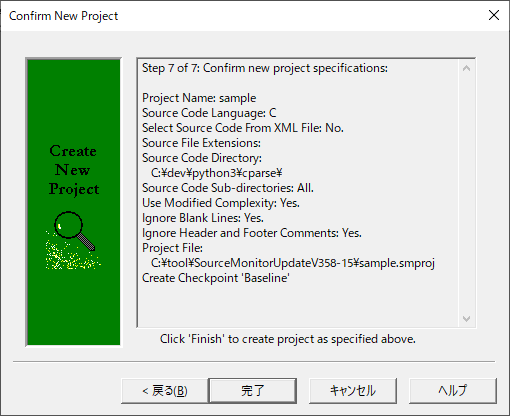
(11)計測対象のファイルの一覧が表示されるので、確認後、OKを押下します。
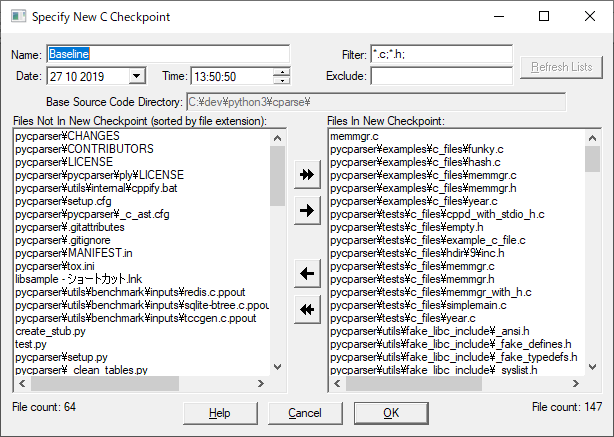
(12)計測結果が表示されます。
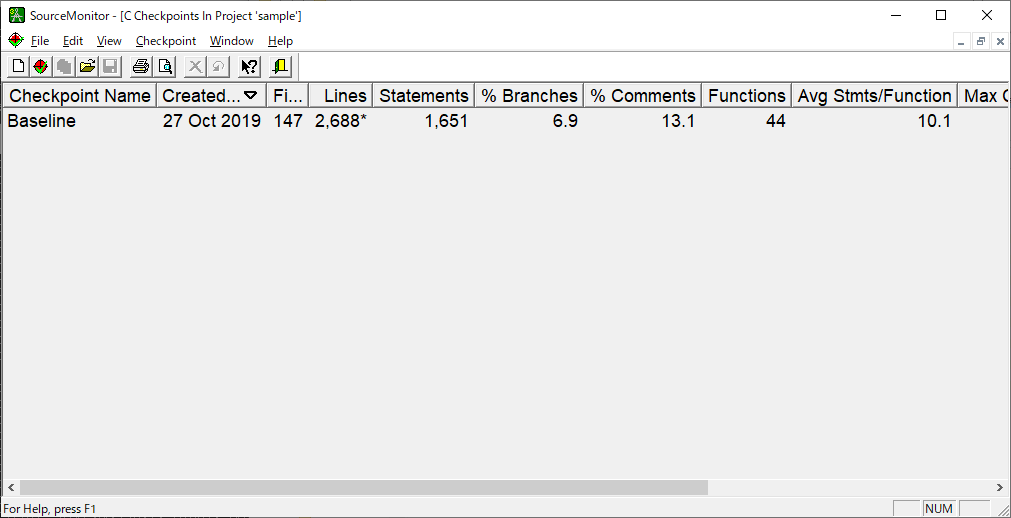
リストをクリックするとファイルの一覧が表示されます。
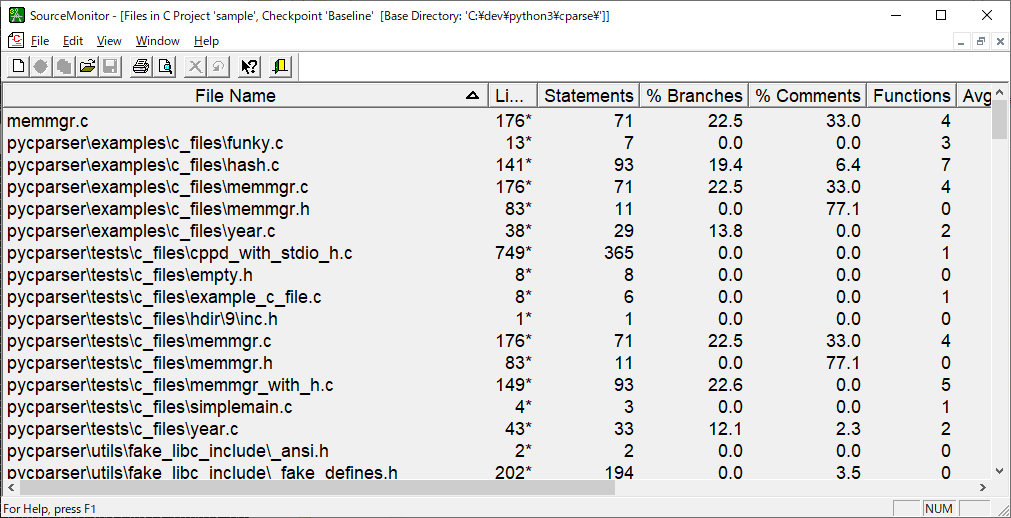
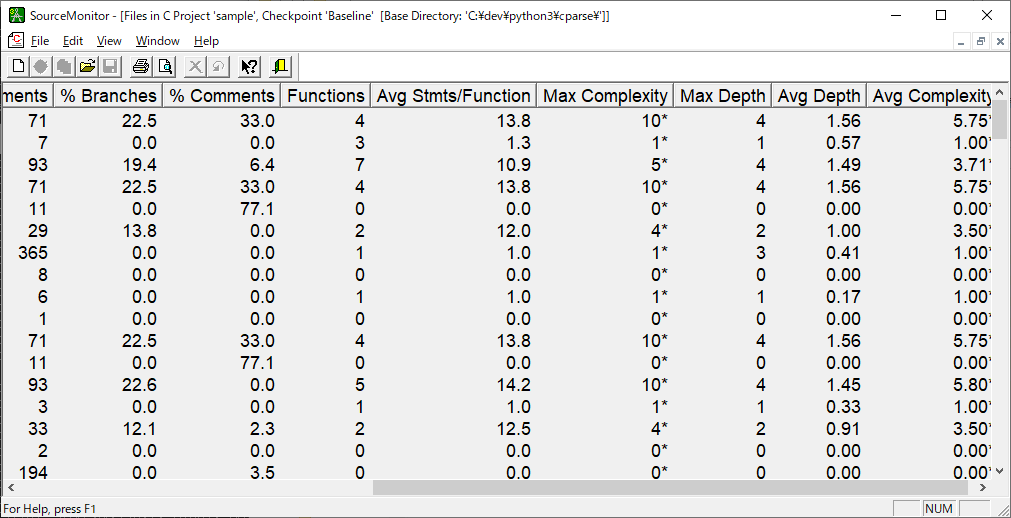
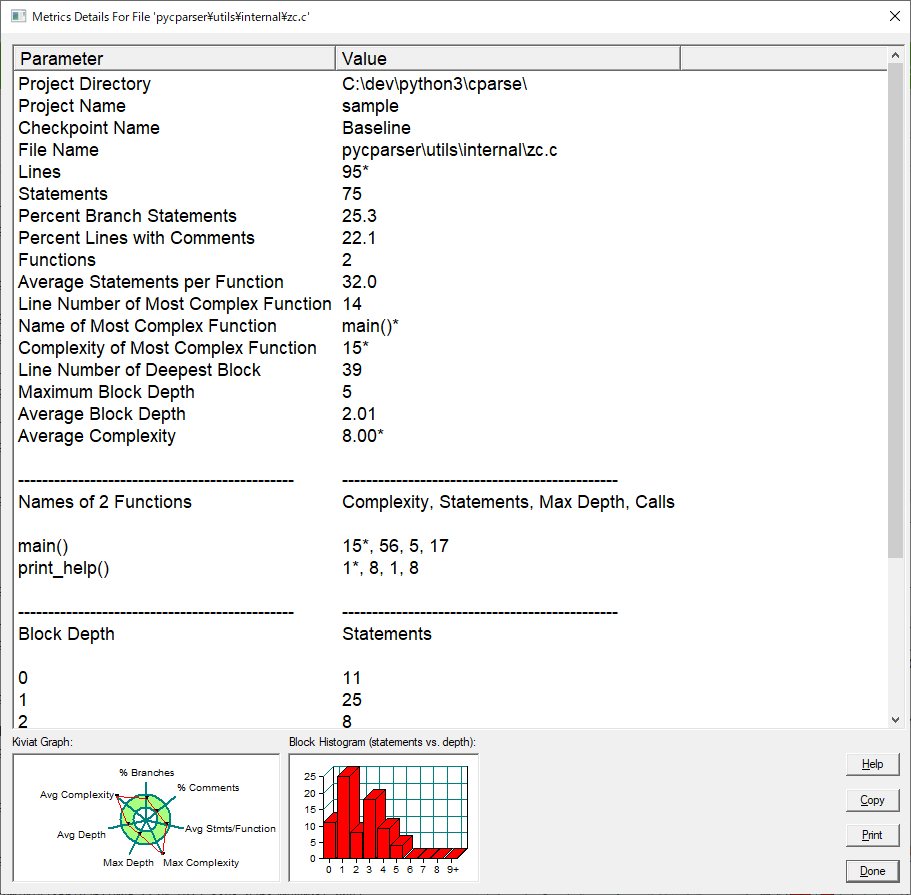
リスト中のファイルのアイテムをクリックすると詳細が表示されます。
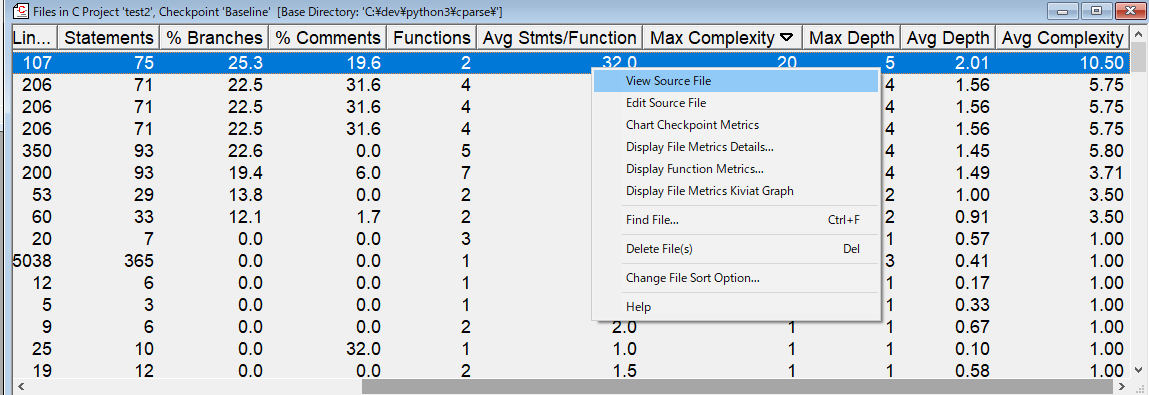
リスト中のファイルのアイテムを右クリックしてコンテキストメニューを表示して「View Source File」を選択することでファイルの内容が確認できます。
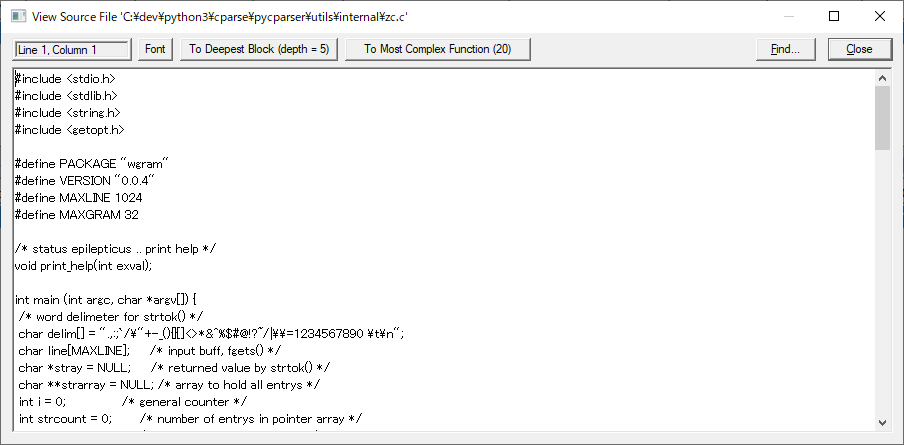
よく利用する数値
| 名前 | 説明 |
|---|---|
| Lines | ソースファイル内の物理行の数。プロジェクト作成に「Do not count blank line」をチェックした場合は空白行を含まない。ざっくりした規模をみるのに使用する |
| Max Complexity | 循環的複雑度。プロジェクト作成時の「Use Modified Complexity Metrix」のチェックの有無によりswitch句のcaseの取り扱いが変わる。この数値が多いほどテストしずらい。 |
| Max Depth | ネストの深さの最大。ネストが深いコードも複雑になる傾向があるので注視する |
| % Comment | コメントの割合。0%とか逆に大きすぎる場合、チェックした方がいい。 |
類似コードを探す
以下で紹介したPMD-CPDを使用することでコピペされたコードを検出することが可能です。
僕にそのコピペを直せというのか
https://qiita.com/mima_ita/items/fe1b3443a363e5d90a21
開発時と違い、類似のコードを探し出して共通化することが目的で使用はしていません。
すでに稼働してしまったシステムは、開発中と違い、コードがコピペされていようが、共通化などのリファクタリングを安易にすることはできません。
こういう状況でコードクローンを検出する目的は、例えば障害対応や機能追加が発生して、あるソースコードを修正する時、他に修正が必要な類似箇所があるかを調べるために使用します。
例えば、障害を出すと当然、「別の箇所は大丈夫?」とか問われることになります。
この際、「コードクローン検出ツールを使用して類似箇所を網羅的に調べて問題ないことを確認しました」とか、それっぽい事を言ってごまかすことができます。
静的解析ツール関係まとめ
実際にコードを動かさずに、コードの評価を行い修正すべき箇所を見つけることができます。
保守的な環境でテストコードを導入するコストは滅茶苦茶かかりますが、静的解析ツールの採用は低コストで行えるので、多くの組織で活用できると思います。
テスト環境まわりの話
テスト時の環境についての話をいくつかさせていただきます。
なお、この章から結合テストの話も出てくるので「C言語で作られたシステム」のタイトル詐欺になりつつあります。
単体テスト環境の分離
別システムが関係したりしている結合テスト時ならばともかく、単体テスト時にも下記のような構成でテストを行う現場があります。
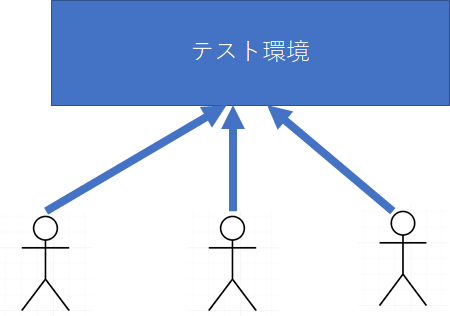
この構成のまずい点は以下の通りです。
・お互いのテストが影響を与えて、本来合格するケースが不合格になったり、その逆のケースがあったりすることが頻発する
・単体テストという不安定な状況のため頻繁にテスト環境を入れ替える必要があり、そのたびに他の開発者の作業が止まる。
つまりテスト容易性が極めて悪くなります。このため、単体テストあたりまでは以下のように開発者毎にテスト環境を用意するのが望ましいです。
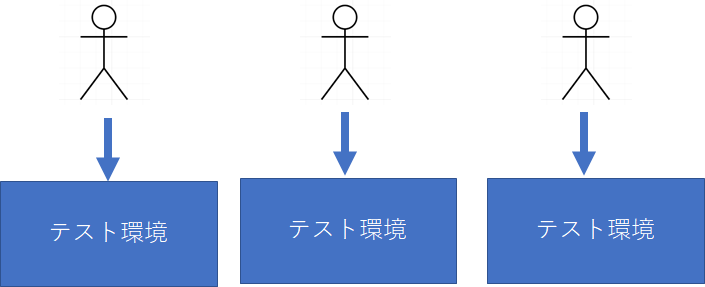
開発者毎にテスト環境をあたえるため、ひと昔前はLinuxで動くプログラムを無理やりWindowsのVisualC++でビルドして動かしたりしてました。
しかしながら、昨今はVMWareやVirtualBoxで仮想環境を構築できるのでそれを利用すべきでしょう。
なお、開発者に与えられたPCのメモリが4GBだったときは、仮想環境で云々はあきらめることになると思います。
テスト環境へのリリースの自動化の話
複数人が触るテスト環境にリリースする際は、なるべく自動で行えるようにしたほうがいいです。
リリース時の影響を最小限におさえるために、テスト環境が止まっている時間を短くしたり、だれも使っていないときにリリースする必要があります。これはテスト環境へのリリース作業を自動化しておくことで対応可能になります。
また、テスト環境へのリリースを記録として残すことで、どの時点で、どのリビジョンの資材が使われていたかを追跡可能になります。
Jenkinsとかの特定のツールにこだわる必要はなく、シェルスクリプトやバッチファイルでいいので自動でできるようにするといいでしょう。
なお、以下の記事のテクニックを使うことでWindowsから資材をWinSCPでアップしたあとにTeraTerm経由でスクリプトを実行して結果をメールで送信するということも可能になると思います。
WinSCPを自動化しても別にかまわんのだろ
https://qiita.com/mima_ita/items/35261ec39c3c587210d8
TeraTermのマクロをためしてみる
https://qiita.com/mima_ita/items/60c30a28ea64972008f2
RedmineをあきらめたオレたちのPowerShellでのOutlookの自動操作
https://qiita.com/mima_ita/items/37ab711a571f29346830
結合テスト時の大量データ作成の自動化
結合テスト時に、大量のデータを作成が必要な場合があります。
この際、結合テストの観点で「使用するデータはシステムで作成できるものとする」とあると、データベースに対してSQLでデータを流し込むという方法ができません。
システムが用意している画面を操作して大量のデータを登録するには、以下の「Windowsの画面操作を自動化しよう」で紹介しているテクニックが使用できます。
自称IT企業があまりにITを使わずに嫌になって野に下った俺が紹介するWindowsの自動化の方法
https://qiita.com/mima_ita/items/453bb6c313e459c44689
ただし、採用するツールや操作対象のアプリケーションの特性上、入力エラー等をすり抜けるケースがあるので、そこは気をつけて採用する必要があります。
結合テストの画面操作を自動化できない?
以下の理由から対象を絞ったほうがいいと思います。
・採用するツールや操作対象のアプリケーションの特性上、自動操作が手動操作とまったく一緒にならないケースがある。
・画面操作の自動化は基本的に安定しない
・画面操作の自動操作は作成コストがかかる。
私がやるなら、スモークテストのための画面操作テストや、大量の繰り返し処理(大量データの作成や負荷試験)に絞って行います。
敗北の記録
理想的だが無駄だった話
世の中には理想的ではあるが、実際問題として導入できない無駄な話がいくつかあります。
ここでは、そういった無駄だった話を紹介したいと思います。
テスト管理ツールの導入の話

テスト工程の管理をするツール、TestLinkについて
https://qiita.com/mima_ita/items/ed56fb1da1e340d397b9
…ってなことを10年来いろんなとこで提案してますが、基本、SIerのような環境では厳しいと思います。
こういうツールに興味がある組織はすでに使っていますし、興味のない組織はテスト管理自体に本当に興味ないので、勝算の薄いツールの導入に色々なコストをかけるくらいなら、やるべきことは他にあると思います。
バグトラッキングシステムの導入の話
バグトラキングシステムを導入することでバグの履歴を管理できたり、だれがどれだけバグを抱えているかの状況判断ができたり、ソースコードとの紐づけなどが管理できるようになります。
残念ながら、ある種の状況では、そういうあるべき論に時間かけるより、「バグ票の書き方」といった基本的な教育に力を使った方がいい状況があるのだと思い知りました。
Wikiによる検索可能なナレッジの蓄積
検索性や履歴の保持を考えた場合、Office文章でナレッジを蓄えるよりWikiを採用した方が望ましいのです。
しかしながら、ある種の環境にいるIT技術者の多くは、文章を書くのにExcelしか使ったことがないケースがあるので、無理な導入はやめましょう。
無駄な話の次善策
上記の理想的な話が全て無駄話になっている現場においては、テスト仕様書、バグ管理票、ナレッジ文章はExcelやWordで記述されて共有フォルダで管理されていることでしょう。
この問題点は2点です。
1つ目は検索性の問題
2つ目は構成管理の問題です。
これらの問題にどう対応すべきか考えましょう。
検索性の問題
Office文章の検索については、いくつかのフリーソフトを使えば行えます。
なんなら、VBSなどで作成することができます。
なお、Officeの検索には時間がかかると思うので、可能であればキャッシュを使っているソフトを採用した方がストレスが溜まらないと思います。
構成管理の問題
共有フォルダに無造作に置かれたファイルは、いつだれが、どんな修正したかが不明になります。
また、誤操作かなにかで稀によく消えたりします。
この対応として共有フォルダでなく構成管理ツールを使用してドキュメントを管理しましょう。
なお、構成管理ツール導入が不可能だった場合は下記の記事を参考にプランBを考えてください。
共有フォルダ教が支配する世界に転生した場合の対応案
https://qiita.com/mima_ita/items/ef3588df4d65cf68f745
さいごに
長い年月を経た保守的な環境でテスト工程を改善してみようとして私が得た知見を紹介しました。
以下の記事でも書きましたが、特に長い年月を経た保守的な環境を改善しようとする場合、とりあえず現状を受け入れたうえで現実的な着地点を探す必要があります。
なお、そもそも「テスト工程を改善しよう」とかいうセリフ自体が
という反応をされてもしょうがないものなので、たまたま受け入れられたら喜べばいい程度のもんだと思います。