はじめに
PDFを機械翻訳する方法は色々ありますが、レイアウトを維持して翻訳をするという意味ではDocTranslatorが使いやすいです。
しかしながら、サイズの制限があるらしく、PDF32000_2008.pdfなどは翻訳に失敗してしまいます。
今回はレイアウトを崩さずに翻訳する方法を考えてみます。
なお、結論からいうと、今回説明する方法は面倒くさいので、別の方法でいいなら別の方法をお勧めします。
PDFに注釈として訳を埋め込む
DocTranslatorのように本文にレイアウトを崩さずに訳を埋め込めるならば、いいのですが、色々うまくいかなと予測できるので、注釈として訳を埋め込むことにします。
たとえば、PDF32000_2008.pdfを翻訳した場合の結果は以下の通りになります。
http://needtec.sakura.ne.jp/doc/tmp/output.pdf
※Adobe Acrobat Readerで閲覧してください。ブラウザ経由だと注釈が文字化けします。
Adobe Acrobat Readerで閲覧すると以下のように表示されます。
![]()
概要
この翻訳の仕組みは以下の通りです。
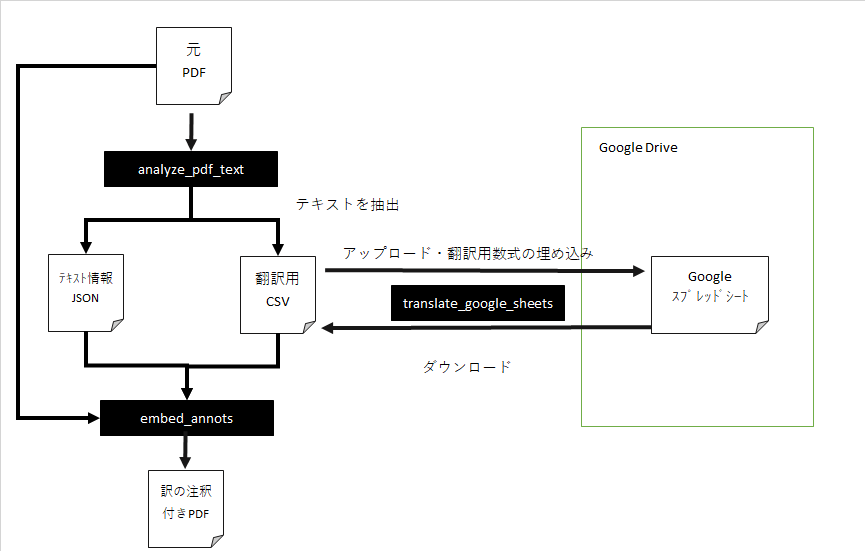
元のPDFから翻訳用のテキストを抽出したCSVと、テキストの位置などの情報を格納したJSONを抽出します。
その後、CSVをGoogleDriveにアップロードして、Googleスプレッドシートで開きます。
GoogleスプレッドシートのGOOGLETRANSLATE数式を利用して翻訳元のテキストを翻訳します。
あとは、Googleスプレッドシートで編集したCSVをダウンロードして、そのCSVとテキストの位置などを格納したJSONを元にPDFに訳を記述した注釈をつけていきます。
使用方法
事前準備
1.Python 3.7.5を用意します。
2.ライブラリをインストールします。
- tqdm 4.45.0
- PyMuPDF 1.16.18
- google-api-python-client 1.8.2
- google-auth-httplib2 0.0.3
- google-auth-oauthlib 0.4.1
3.Google Drive APIとGoogle Sheets APIを使用できる準備をします。
以下のクイックスタートを実行すれば、準備はできると思います。
Google Drive API- Python Quickstart
https://developers.google.com/drive/api/v3/quickstart/python
Google Sheets API- Python Quickstart
https://developers.google.com/sheets/api/quickstart/python
このクイックスタート中に認証情報が格納されたJSONが作成されるので、それを利用します。
4. 以下から必要なスクリプトをダウンロードします。
https://github.com/mima3/pdf_translate
翻訳方法
1.翻訳したいPDFをローカルPCにダウンロードします。
2. 下記のコマンドを使用して翻訳対象のPDFから、そのテキスト情報と位置を記録したJSONと、テキストの一覧を記録したCSVを作成します。
python ./analyze_pdf_text.py PDF32000_2008.pdf
以下のファイルが作成されます。
- PDF32000_2008.pdf.json
- PDF32000_2008.pdf.csv
3. PDF32000_2008.pdf.csvの2列目に訳を入力します。
今回はGoogleスプレッドシートにアップロードしてGOOGLETRANSLATE数式で翻訳を行います。
これを自動化したスクリプトは以下のようになります。
python ./translate_google_sheets.py PDF32000_2008.pdf.csv client_secret.json
4. 下記のコマンドを実行して訳を注釈として埋め込みます
python ./embed_annots.py PDF32000_2008.pdf.json output.pdf
使っているライブラリの説明
PDFのテキスト情報はどうやって取得しているのか?
PyMuPDFを利用しています。
Page.getTextメソッドを利用することで、テキストブロックの位置と、その内容を取得できます。
サンプルコード
import fitz
doc = fitz.open('PDF32000_2008.pdf')
print(doc[5].getText('blocks'))
出力例
[(36.779998779296875, 39.29692077636719, 130.1901397705078, 52.363121032714844, 'PDF 32000-1:2008', 0, 0), 略]
なお、getTextの第一引数の値を「words」にすることで単語単位で取得することも可能です。
出力例
[(36.779998779296875, 39.29692077636719, 58.759761810302734, 52.363121032714844, 'PDF', 0, 0, 0),略]
「json」や「dict」を与えるとより詳細なフォントや色などの情報が取得できます。
{
"width":595.0,
"height":842.0,
"blocks":[
{
"type":0,
"bbox":[
36.779998779296875,
39.29692077636719,
130.1901397705078,
52.363121032714844
],
"lines":[
{
"wmode":0,
"dir":[
1.0,
0.0
],
"bbox":[
36.779998779296875,
39.29692077636719,
130.1901397705078,
52.363121032714844
],
"spans":[
{
"size":10.979999542236328,
"flags":20,
"font":"DDPEIM+Helvetica-Bold",
"color":0,
"text":"PDF 32000-1:2008",
"bbox":[
36.779998779296875,
39.29692077636719,
130.1901397705078,
52.363121032714844
]
}
]
}
]
},
略
注釈の埋め込みはどうやっているのか?
Page.addTextAnnotを使用します。
今回追加したような単純なもの以外を試したい場合は、以下のコードが参考になると思います。
CSVのアップロード
Google DriveにCSVをアップロードしてGoogleスプレッドシートとして編集後、ダウンロードするにアップロードだけのサンプルコードを載せています。
service_drive = build('drive', 'v3', credentials=creds)
# CSVをGoogleスプレッドシートで編集できるようにUploadします.
# https://developers.google.com/drive/api/v3/manage-uploads#python
file_metadata = {
'name': 'Test',
'mimeType': 'application/vnd.google-apps.spreadsheet'
}
media = MediaFileUpload('test.csv',
mimetype='text/csv',
resumable=True)
file = service_drive.files().create(body=file_metadata,
media_body=media,
fields='id').execute()
print('File ID: %s' % file.get('id'))
createのbodyパラメータのmimeTypeに「application/vnd.google-apps.spreadsheet」を指定することでGoogleスプレッドシートとしてCSVを追加することになります。
Googleスプレッドシートとして編集
Google DriveにCSVをアップロードしてGoogleスプレッドシートとして編集後、ダウンロードするにGoogle DriveにアップロードしたCSVをGoogle Sheets APIで編集するだけのサンプルコードを載せています。
小さいサイズのCSVの場合はこれだけでいいのですが、大量の行を更新する場合、GOOGLETRANSLATE数式が完了しきらない場合があります。この場合、セルには翻訳後の文字ではなく「Loading...」または「読み込んでいます...」と表示されます。
これはAPI経由でなく、画面でGoogleスプレッドシートを編集している場合も発生する問題です。
今回は旨い回避策が見つからなかったので10秒おきに「Loading...」または「読み込んでいます...」が存在しないことを確認しています。
https://github.com/mima3/pdf_translate/blob/master/translate_google_sheets.py#L45
なお、今回は愚直にupdateメソッドでセルを更新していますが、batchUpdateとかを使った方がよさそうです。
Googleスプレッドシートのダウンロード
Google DriveにCSVをアップロードしてGoogleスプレッドシートとして編集後、ダウンロードするにダウンロードのサンプルを載せています。
# download
request = service_drive.files().export_media(fileId=file_id, mimeType='text/csv')
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
print ("Download %d%%." % int(status.progress() * 100))
with open('download.csv', 'wb') as f:
f.write(fh.getvalue())
GoogleDriveからダウンロードするにはget_mediaとexport_mediaの2種類の方法があります。
https://developers.google.com/drive/api/v3/manage-downloads
今回は一回、Googleスプレッドに変換したものをCSVとしてダウンロードするのでexport_mediaを使用します。
まとめ
とりあえず、こんな感じで700ページくらいあるPDFを翻訳できました。
ただし、このやり方は面倒くさい上に、時間がかかるので別の方法が可能なら別の方法を検討した方がいいと思います。
少なくとも別の翻訳APIを使用できる環境なら、一旦アップロードして数式埋め込んでダウンロードしなおすという面倒なことをしなくていいと思います。