これは琉大アドベントカレンダー2020の12/8の記事です。
こんばんは。OBの人工無脳N/A3です。今回は声質変換について遊んでみたので、それを記事にしてみました。昨日の琉大アドベントカレンダーはYoshiaki Sanoさんによる「ニューラルネットワークの仕組みと実装の解説」でしたが、そんなニューラルネットの応用先の一つである音声変換に関して、「こんな便利なライブラリがあるよ」と紹介するのが、本記事の目的です。今回はニューラルネット使っていないけどね。
前書き
コロナ始まって家に篭ることも増えてきたし、何か新しいことでも始めるかと考えていた矢先、友人が動画配信や投稿とかに手を出し始めていたので、「それなら、私はボイスチェンジャー作ってバ美肉ならぬ、バ美声でも始めるか〜」と手を出しました。
1. 声質変換とは?
簡単に言うと、入力した音声を全く別の音声へ変換する技術を差します。例えば、男性の音声から女性化したり、反対に、女性の音声を男性化したりすることに使えます。
1.1 音声の特徴
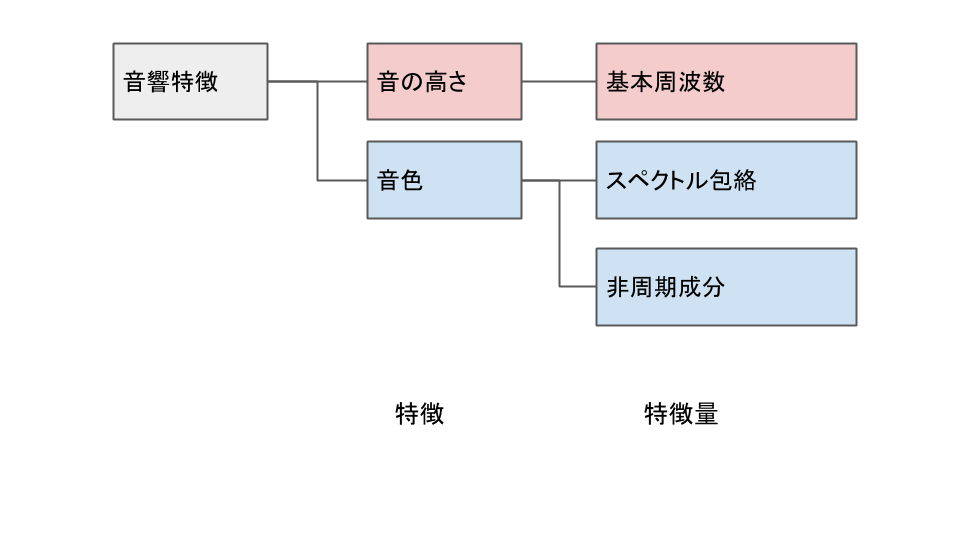
音声には、音の高さ、音色といった音響的な特徴と、音素列や単語といった言語的な特徴があります。 声質変換では言語特徴は変換せず、音響特徴のみを変換します。
そのため、声質変換では、この音の高さ、音色といった音響特徴を抽出して数値化する必要があります。ここで、周期的なインパルス列をフィルタリングすることで音声を生成するモデルを考えます(ソース・フィルタモデル)。 こうすると、音の高さはインパルス列の間隔、音色はフィルタ特性とみなせます。 このとき、音声は、インパルス列とフィルタ特性(つまりスペクトル包絡)の畳み込みで合成できます。 インパルス列の間隔の逆数を基本周波数またはf0と呼びます。
1.2 音響特徴量の抽出と合成
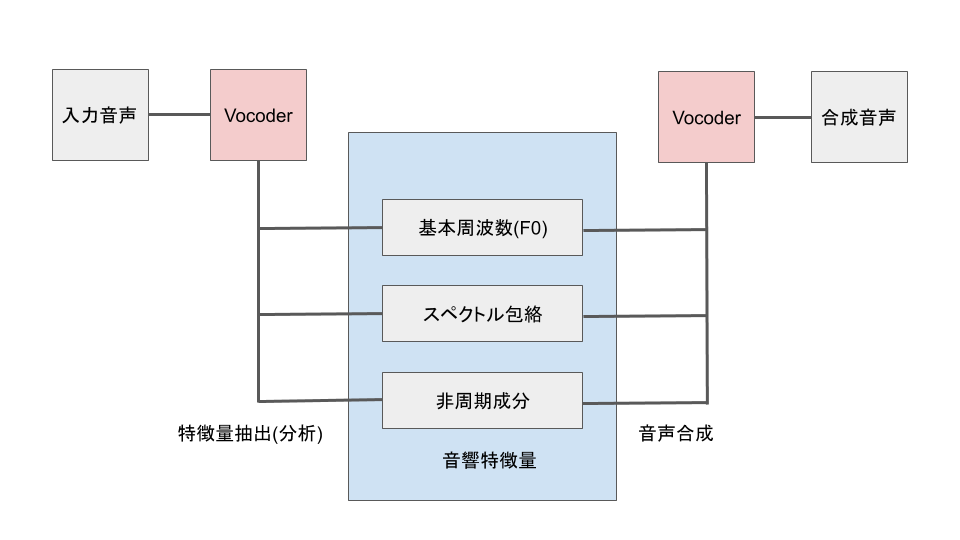
音声から音響特徴量を抽出する場合は、Vocoderを用います。 また、Vocoderは逆に抽出した音響特徴量から音声を合成することも可能です。
1.3 声質変換
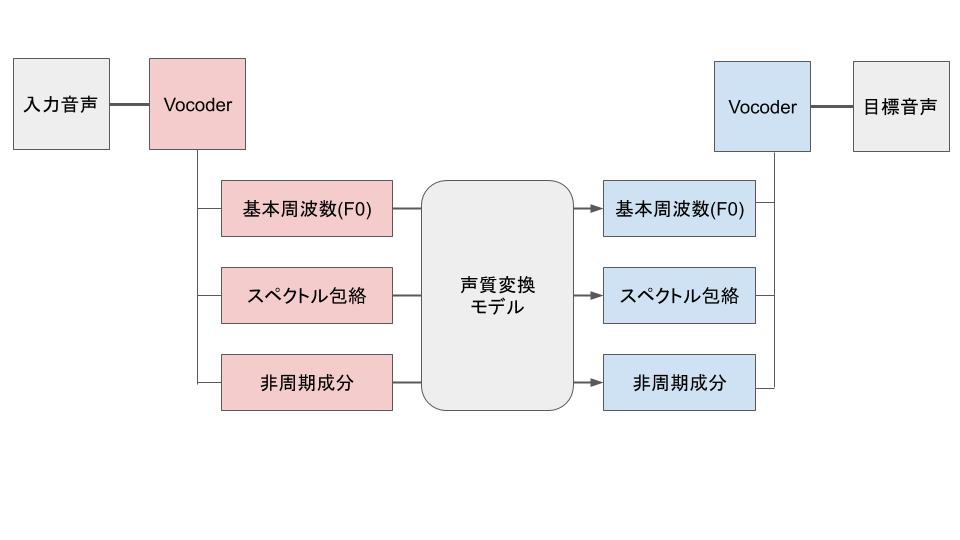
音響特徴量の変換関数を推定し、入力音声に適用することで声質変換が可能です。今回のモデルは、非周期成分は変換せずそのまま利用し、基本周波数とスペクトル包絡だけを変換します。
1.4 声質変換の種類
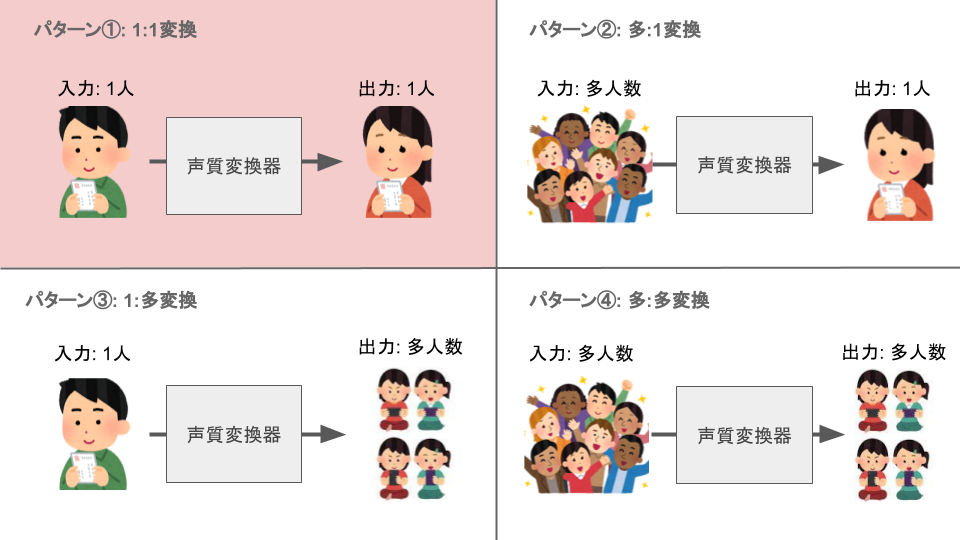
主に4種類のカテゴリがあり、入力音声の話者数と目標音声の話者数の組み合わせパターンで決まります。今回は、1人ぼっちの男性がとある女の子へバ美声したいので、パターン①の1:1変換を想定した声質変換となります。
2. nnmnkwiiとは?
r9y9氏が開発・整備しているPython向けの音声系の機械学習ライブラリです。
音声変換やテキスト2スピーチ(文章から音声を生成すること)を実行するのに必要なデータセットの準備、下処理、モデルの学習、学習後のデータ生成関連のライブラリを包括して提供しています。
詳細は、公式のドキュメントを参照してみるといいかもしれません。
個人的に魅力なポイント
・ データの取扱関連がPyTorch-like(つまり、pythonic)なため、コードがスッキリしてて、読みやすい。
・ 自作データセットにも対応でき、データローダーの自作も可能。
・ 著名な音声コーパスに対応しており、各種モデルの性能調査も容易。
・ DTW、0フレーム除去等の音声データに関する下処理が豊富、かつ、サンプルも豊富
3. インストール
pipでインストールできます。ですが、公式でも記載されていますが、利用には幾つか別のライブラリも必須とのことで、このタイミングでまとめてインストールしちゃうといいかもしれません。
pip install nnmnkwii
pip install pysptk pyworld librosa tqdm
Tips: python 3.7の場合
bandmatというライブラリのインストールエラーが発生します。その場合は下記にしたがって、直接インストールする必要があります。ちなみに私の環境はubuntu18.0.4 & python 3.8.1でしたが、下記の対応でなんとかなりました。
git clone git://github.com/MattShannon/bandmat.git
sudo apt-get install cython3 python3-numpy python3-scipy
cd bandmat
sudo pip install -r requirements.txt
python setup.py build_ext --inplace
python setup.py install
4 データセットの用意
公式のチュートリアルでは英語音声における声質変換を載せています。ですが、私としてはあくまでバ美声がしたいので、日本語音声データセットであるJVSコーパスを利用して日本語音声でモデルを学習させます。このサイトからダウンロード可能です。
5. 音声変換モデルの学習
チュートリアルを参考にしながら、JVSコーパスverに書き換えてみました。今回の音声変換モデルでは、F0(基本周波数)を線形変換。音声特徴量をGMMで変換。非周期性は変換なしとなっています。書き換えたプログラムはこちら。
6. 音声変換結果
学習に利用していないテストデータの変換結果がこちらです。
それぞれ、src○.wavが元音声である男性による読み上げ、tgt○.wavが目標音声である女性の読み上げ、w_MLPG○.wavが元音声の変換結果となっています。聞き比べると、流石に目標の女性の声にはほど遠いかもしれませんが、女性っぽい声への変換はできているんじゃないかと思います。
7. 最後に
動機は不純ですが、声質変換に関して便利なライブラリを見つけたので紹介してみました。「研究で音声変換やってみたい!!」や「自作の音声変換アプリ作ってみたい。」など興味のある方は色々と触ってみるといいかもしれません。私も早くボイスチェンジャーアプリ作らなきゃ・・・
次の琉大アドベントカレンダーは、Unimarimos76による「セキュキャン ネクスト参加記」とのことです。琉大の中でも色々と有名?なUnimarimos76くんの体験記とのことなので、今から私も楽しみです。
参考文献
- 統計的声質変換を行うための知識と手法: 最初の掴み
- nnmnkwii (nanamin kawaii) documentation: 公式ドキュメント
- GMM-based voice conversion (en): 本件の元ネタ
- Toda, A. W. Black, and K. Tokuda, “Voice conversion based on maximum likelihood estimation of spectral parameter trajectory,” IEEETrans. Audio, Speech, Lang. Process, vol. 15, no. 8, pp. 2222–2235, Nov. 2007.: 元ネタのアルゴリズムが書かれている論文
- SunPro会誌 2016: 戸田先生の論文を理解するための入門書。無料
- ベイズ推定とグラフィカルモデル:コンピュータビジョン基礎1:混合ガウス分布, EMアルゴリズム関連。会員登録必要、無料
- 統計的声質変換クッソムズすぎワロタ(チュートリアル編): Julia版のライブラリも紹介している。
- JVSコーパス: 今回のデータセットの配布先。声優コーパスでの問題点を改良したデータセット。日本語音素バランス文としてはこちらのほうがより大規模かつ高品質。