■■■Oracle Cloudのウェビナーシリーズは?→こちら■■■
地理空間情報 x 時間軸 でデータを何か見てみたいなあ...と思っていたのですが、Oracle Spatial Studio 20.1に「Time Slider」機能が追加されていたので、試してみました。
やりたいこと
航空機の飛行データ(緯度・経度、高度、時刻、便名など)が記録されたjsonファイルの内容を、Oracle Autonomous DatabaseにUploadし、Oracle Spatial Studioで可視化します。
注:jsonファイルの内容は、あくまで個人の1箇所のアンテナで受信したデータ。(全ての航空機の飛行データ、というわけでは無いです。記事のタイトルが大きくてすみません![]() )
)
あと、国土地理院が公開する Shapefile(行政区域の情報)を使って、Oracle Autonomous Database上で簡単な地理空間情報検索を実行します。以前「ドラクエウォークのおみやげを集めるのに最寄り駅を調べたい」で行ったような内容です。
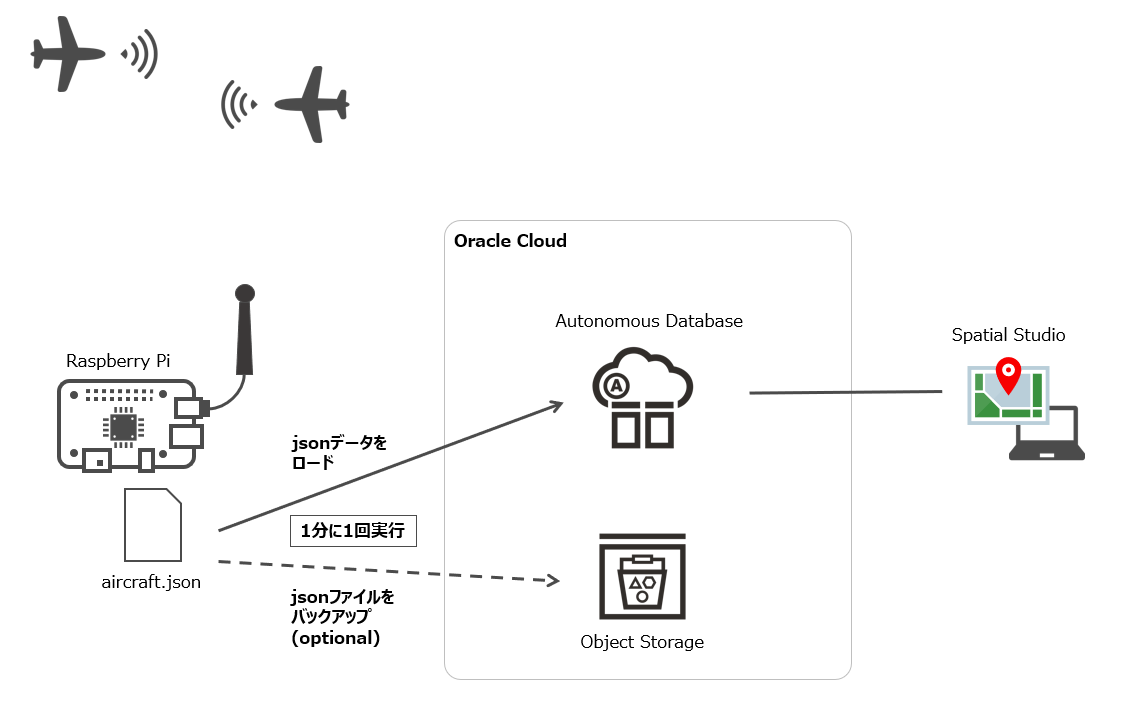
今回利用するOracle Cloud の(or 関連する)サービス
- Oracle Autonomous Database
- Oracle SQL Developer Web
- SODA for REST (NOSQL形式のAPIセット、Oracle REST Data Services (ORDS) の REST API)
- Oracle Spatial Studio
- Oracle Object Storage ※optional
Oracle Autonomous Database と Oracle Object Storage は、Oracle Cloud上のサービスです。
Oracle Spatial Studio は、JavaのWebアプリで、WebLogicやTomcatにEARファイルを展開する方法と、Webアプリとしてlocalhostで起動して実行する方法の大きく2種類があります。今回は後者を利用。手元のWindows PC上で実行しています。
使用したバージョンはそれぞれ、Oracle Autonomous Database (19c), Oracle Spatial Studio (20.1) です。
データの準備
使用する jsonファイルは、dump1090 というソフトウェアにより Raspberry Pi上に保存された aircraft.json です。
毎秒(30秒に1回かも..)、更新されるファイルですが、今回は1分に1回、このaircraft.jsonの内容をOracle Cloud 環境にUploadします。(これを約3日間実行)
dump1090 には、可視化ができる簡易Webアプリも付属するので、わざわざ別環境に上げる意味、、という点はありますが、データを集約したいことや、SQLでいろいろ処理できたほうが(個人的には)扱いやすいので、そうすることにします。
jsonファイルの内容をAutonomous Databaseにアップロードする
jsonファイルの中身を、1分に1回、Autonomous Databaseに登録していきます。こんなデータです。
{ "now" : 1607743862.8,
"messages" : 123456,
"aircraft" : [
{"hex":"86d1eb","squawk":"3403","flight":"APJ551 ","lat":35.822552,"lon":139.621095,"nucp":7,"seen_pos":2.9,"altitude":29725,"vert_rate":1088,"track":260,"speed":319,"messages":214,"seen":0.1,"rssi":-33.1},
{"hex":"850e14","squawk":"3413","flight":"JAL293 ","altitude":23375,"vert_rate":2624,"track":263,"speed":308,"messages":125,"seen":5.2,"rssi":-33.9},
{"hex":"847c18","squawk":"3327","flight":"JJP203 ","altitude":30000,"vert_rate":0,"track":252,"speed":309,"messages":610,"seen":120.4,"rssi":-34.1},
{"hex":"86cea3","squawk":"3373","flight":"SNJ13 ","lat":35.447433,"lon":139.188309,"nucp":7,"seen_pos":11.7,"altitude":28125,"vert_rate":2304,"track":263,"speed":294,"messages":203,"seen":1.3,"rssi":-33.4}
]
}
各変数の意味はこのあたりが参考になりますが、今回主に使用するのは以下です。値(キー)がない場合は省略されます。
| 変数 | 意味 |
|---|---|
| now | このファイルの生成時刻、Unix時間(エポック秒) |
| aircraft | JSON Objectの配列、1オブジェクトが1航空機を示す |
| flight | 便名 |
| altitude | 高度(単位:フィート) |
| lat | 緯度 |
| lon | 経度 |
| seen | nowの何秒前にメッセージを受信したか |
aircraft.json の内容を Autonomous DatabaseにUploadするには、SODA for REST (NOSQL形式のAPIセット、Oracle REST Data Services (ORDS) の REST API) を使用して、はじめに以下を実行します。
## コレクション:aircraft を作成
$ curl -X POST -u '<DB username>:<DB password>' "https://<ORDSのRESTのエンドポイント>/hogehoge/soda/latest/aircraft"
これにより、Autonomous Database側では、スキーマに aircraft という名前の新しいコレクションが作成されます。(実体は1つのテーブル(AIRCRAFT表)が作成されます。)
SQL> desc aircraft
Name Null? Type
------------- -------- -------------
ID NOT NULL VARCHAR2(255)
CREATED_ON NOT NULL TIMESTAMP(6)
LAST_MODIFIED NOT NULL TIMESTAMP(6)
VERSION NOT NULL VARCHAR2(255)
JSON_DOCUMENT BLOB
JSONファイルの内容を投入するには、以下のように実行します。aircraft表の JSON_DOCUMENT列に格納されます。
$ curl -X POST -u '<DB username>:<DB password>' -H "Content-Type: application/json" --data @/PATH_TO_jsonfile/aircraft.json "https://<ORDSのRESTのエンドポイント>/hogehoge/soda/latest/aircraft"
SODA for REST (NOSQL形式のAPIセット、Oracle REST Data Services (ORDS) の REST API) に関する補足
Autonomous Databaseは、今回新規作成した 19c を使用しました。
SODA周りは、「Autonomous Databaseに自動でデータをロードするよう、リファレンスアーキテクチャーに習ってやってみた」の「Autonomous Database(ADB)を作成」を参照。
-
Autonomous Databaseのコンソール > 開発 > 「RESTfulサービスとSODA」にある、「URLのコピー」を押下してRESTのエンドポイントURLをコピー。
→ 上記のURL に代入。 -
adminとは別のユーザで実行する場合(<DB username>に一般ユーザを入れる場合)は、hogehogeのところに任意の文字列(自分が設定したもの)が入るので、それを代入する。(admin以外のDBユーザがSQL Developer Webが実行できるよう設定する時に、ORDS_ADMIN.ENABLE_SCHEMA を実行しますが、そのときにURLに入れる文字列を指定。)
私の環境では、admin以外のユーザで実行しており、aircraftに登録するには以下のURLです。stgwebが、ORDS_ADMIN.ENABLE_SCHEMA実行時に指定した任意の文字列です。
https://xxx.adb.<リージョン>.oraclecloudapps.com/ords/stgweb/soda/latest/aircraft
定期実行するよう登録
上記内容を、ベタですが、1分毎に cron で実行するよう登録しました。
ついでに、aircraft.jsonファイルそのものを、バックアップの意味で Object StorageにUploadしています(この先の分析では使用しません)。
$ crontab -e
*/1 * * * * /home/pi/work/flight/upload.sh
#!/bin/sh
d=`date -u "+%Y%m%dT%H%M%S"`
# To Autonomous Database
curl -X POST -u '<DB username>:<DB password>' -H "Content-Type: application/json" --data @/PATH_TO_jsonfile/aircraft.json "https://<ORDSのRESTのエンドポイント>/hogehoge/soda/latest/aircraft"
# To Object Storage
curl -X PUT --data-binary @/PATH_TO_jsonfile/aircraft.json https://objectstorage.xxx.oraclecloud.com/p/xxx/n/xxx/b/<バケット名>/o/aircraft.json.$d.log
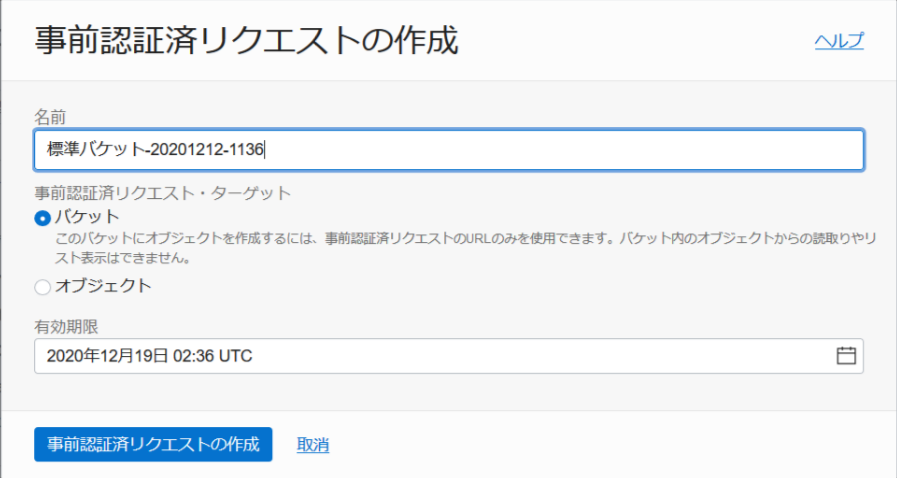
Object Storageのエンドポイントは、簡単のため事前認証済みリクエストを使いました(バケットを指定、有効期限が必須)。
Object Storageのバケットに、事前認証済みリクエストを作成
「作成」押下後、1度だけ表示されるURLをエンドポイントとして利用する。
Object Storageのバケットに、ファイルが1分おきにUploadされていく様子
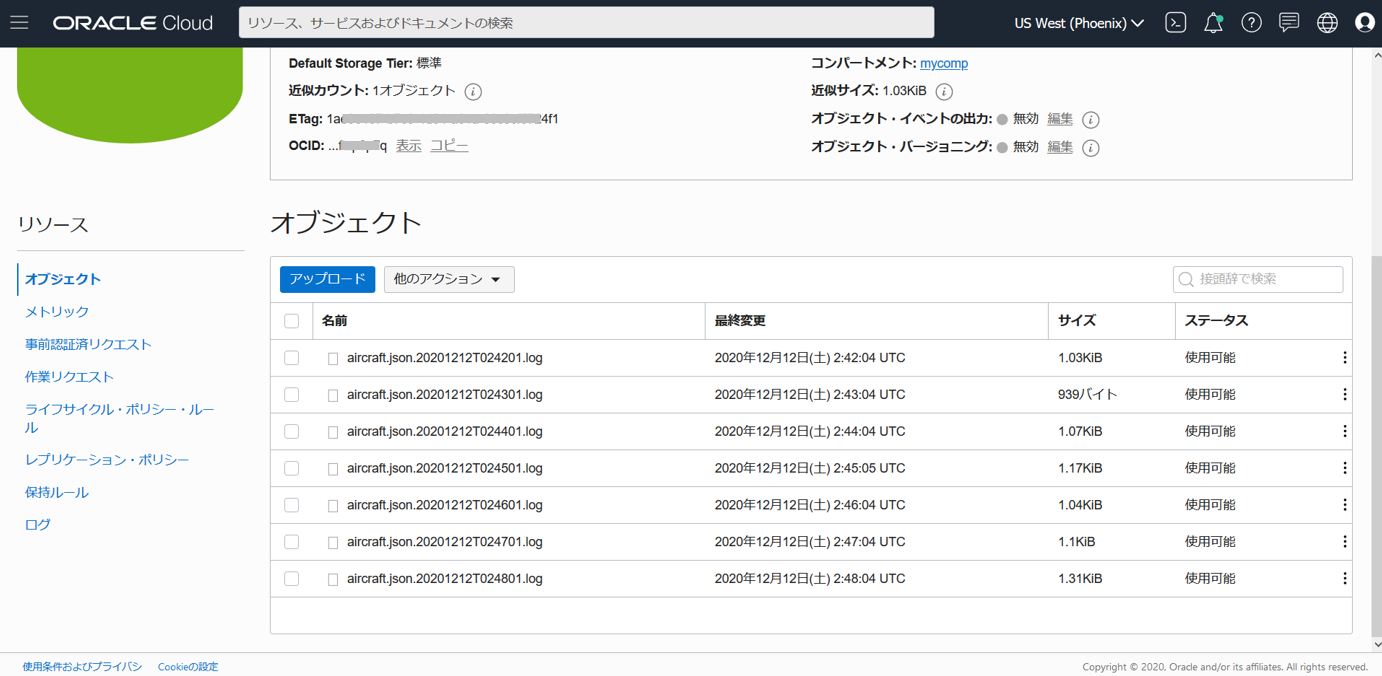
今回は直接Autonomous DatabaseにJSONデータを投入したので、ここから先はそのデータを使っていきます。
データ投入の方法は、例えば他にも、一旦Object StorageにJSONファイルを置き、それをAutonomous Databaseから外部表として読みながら前処理するようなやり方も取れます。もちろん、Databaseではない場所で前処理することも考えられます。
データを分析しやすいように加工する
ここまでの処理で、AIRCRAFT表には、1レコードでJSON_DOCUMENT列に複数の航空機の情報が入っています。
これを加工し、今回の可視化用にAIRCRAFT_SP表を作成します。
-- JSON_TABLE()を利用し、JSON配列オブジェクトを分解し、
-- 1レコードに1つの航空機情報となるようVIEWを作成
create or replace view
aircraft_v
as
select
a.json_document.now as now,
to_date('1970/01/01 00:00:00','YYYY/MM/DD HH24:MI:SS') + (a.json_document.now/(24*60*60)) as now2,
to_date('1970/01/01 00:00:00','YYYY/MM/DD HH24:MI:SS') + ((a.json_document.now-seen)/(24*60*60)) as datetime,
jt.hex,
trim(jt.flight) as flight,
jt.lat,
jt.lon,
jt.altitude,
jt.seen
from aircraft a,
json_table(a.json_document, '$.aircraft[*]'
columns (
hex varchar2(10) path '$.hex',
flight varchar2(20) path '$.flight',
lat number path '$.lat',
lon number path '$.lon',
altitude number path '$.altitude',
seen number path '$.seen')) jt
;
-- aircraft_v から aircraft_sp表を作成。
-- 1. PK相当の列(not null かつ Unique)が後でSpatial Studioのところで必要になるので
-- row_number()を使って作成
-- 2. datetime列はUTCなので、JSTの datetime_jst列を追加
-- 3. lat列・lon列が null のデータは除去
create table aircraft_sp as
select
row_number() over (order by now) as id,
datetime,
datetime + 9/24 as datetime_jst,
hex,
flight,
lat,
lon,
altitude
from aircraft_v
where lat is not null and lon is not null;
Spatial Studio を準備
ダウンロード
https://www.oracle.com/database/technologies/spatial-studio/oracle-spatial-studio-downloads.html
今回は「Oracle Spatial Studio - Quick Start」を使用しました。
インストール
https://www.oracle.com/database/technologies/spatial-studio/get-started.html
起動
展開したフォルダの start.bat を実行し、(同じフォルダのreadmeにログインユーザ名とパスワード記載有り)、https://localhost:4040/spatialstudio にアクセス
Spatial Studio が使うリポジトリの作成
初回起動時は、リポジトリの作成を求められます。ウィザードに従ってリポジトリとして使用するDatabaseを指定します。
今回の投稿は「Always FreeのAutonomous Database」で完結したかったのですが、リポジトリ作成時に、セッションを多く張るようで、ここで ORA-00018 maximum number of sessions exceeded 発生。Always FreeのAutonomous Databaseでは、最大セッション数は20という制限があります。(一方で、有償のAutonomous Databaseは low接続で OCPU当たり 300セッション)
リポジトリは有償環境に作成することにしました。
Spatial Studio で、データを可視化する
リポジトリの作成に成功すると、次の画面になりました。
- Step 1:接続(connection)を作成
- Step 2:データセットを作成
- Step 3:プロジェクトを作成
言われたとおりにやってみます。
接続を作成
リポジトリ作成と似たような画面が出るので、接続先のDBを指定する。
JSONデータをロードした Autonomous Databaseを指定し(要Walletファイル)、接続する データベースユーザを指定します。
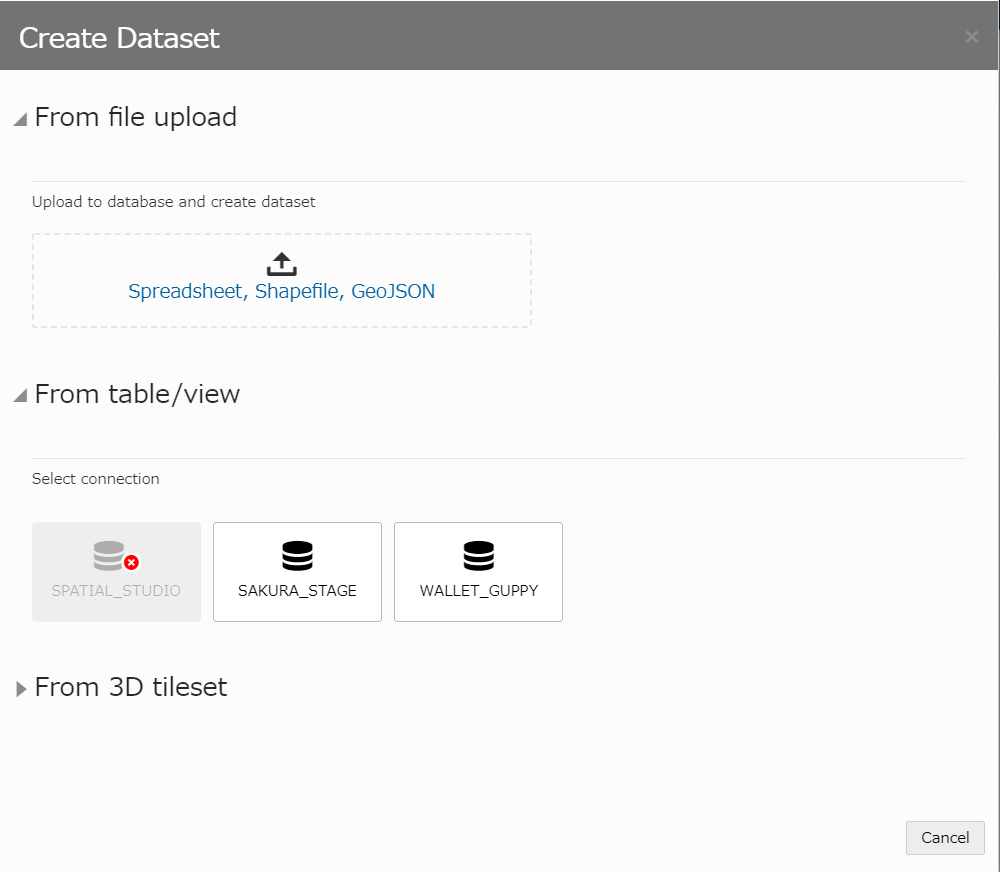
データセットを作成
1つ目のデータセット:AIRCRAFT_SP表
From table/view から、接続先DBを選択し、AIRCRAFT_SP表を選択。
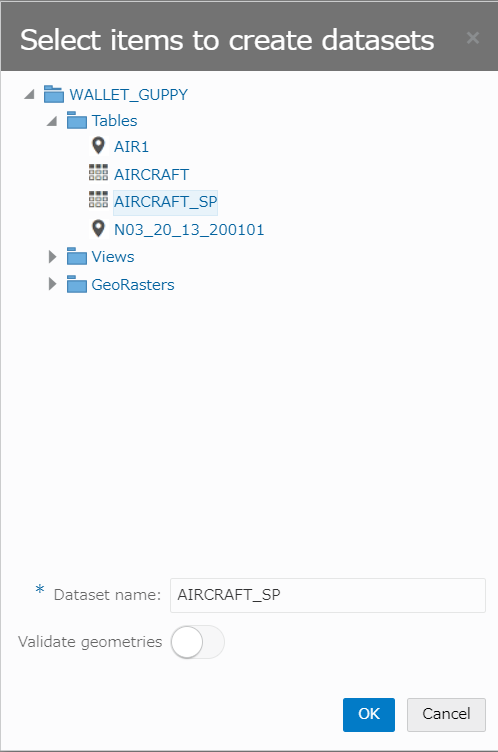
OKを押下し、作成します。
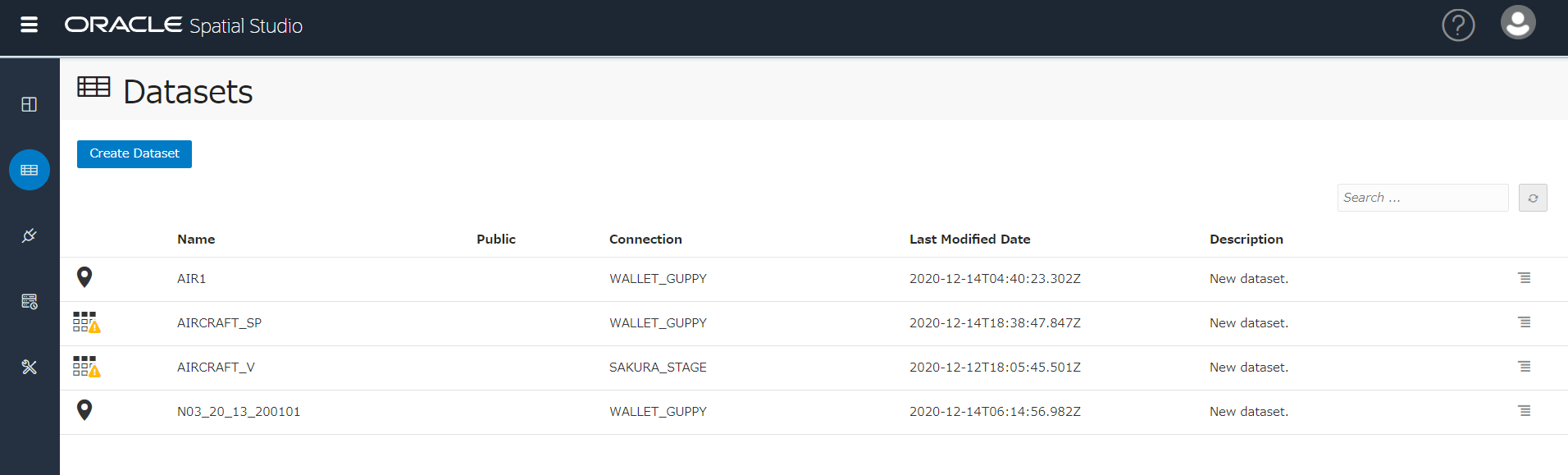
作成は成功しましたが、データセット名AIRCRAFT_SPの左側のアイコンに ! が付いており、クリックします。

PKに相当する列が必要なのと、マッピングや空間分析には準備が必要とのことで、まずは上から。
Go to Dataset Columns をクリック。
表示された「Dataset Properties」で、ID列のトグルスイッチ「Use As Key」を下図のようにONにし、「Validate key」ボタンを押下します。
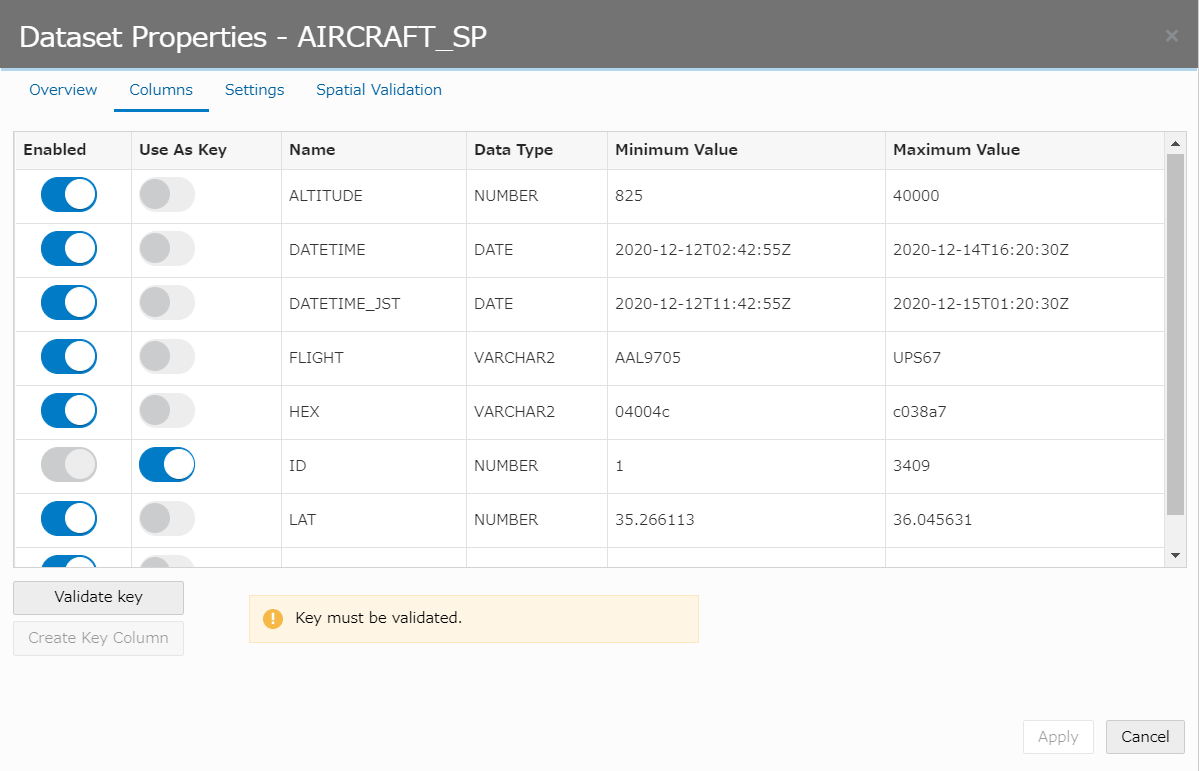
Validateが成功したら、右下の「Apply」を押下します。
もう片方のIssue対処のため、再度、!がついてるアイコンをクリックし、Create Latitude/Longitude Indexをクリックします。
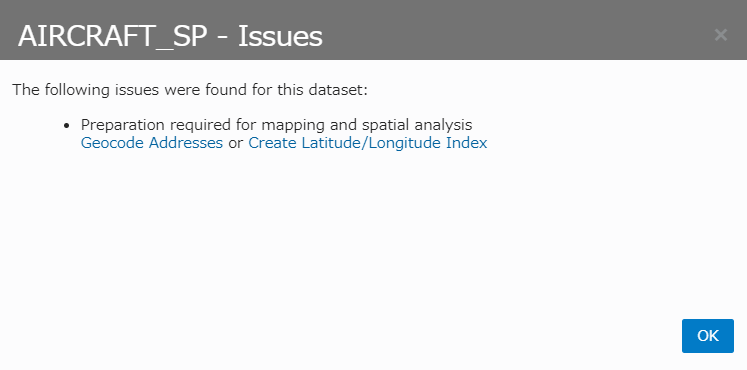
Latitude(緯度に相当する列)、Longitude(経度に相当する列)を、それぞれ指定し、「OK」を押下。
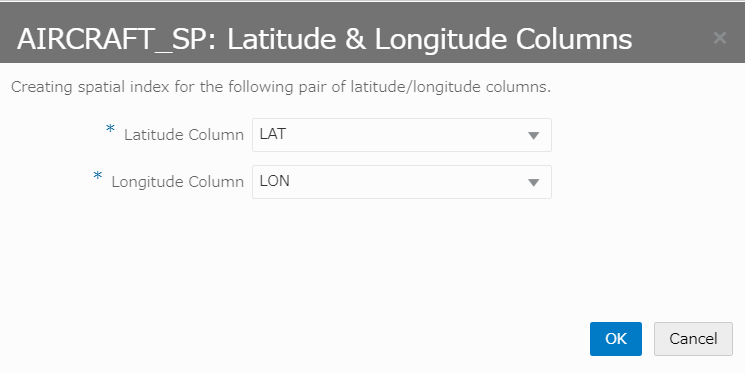
Index作成が完了すると、AIRCRAFT_SP の !が消え、ピンアイコンに変わります。
2つ目のデータセット:東京都のシェープファイルから
※今回利用したシェープファイルは、出典:「国土地理院「数値地図(国土基本情報)」の「国土数値情報 行政区域データ」です。
東京都の市区町村の形状を示すデータ(シェープファイル)をダウンロードして、展開しておきます。
https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-N03-v2_4.html から、東京都の、最新版を選択(N03-190101_13_GML.zip)。
zip内の、ファイル4つ(*.dbf, *.prj, *.shp, *.shx)を、下図の「From file upload」の枠内にドラッグ。
Upload to connection で、シェープファイルのアップロード先を指定し(AIRCRAFT表と同じ接続を指定する)、他はデフォルトのままで「Submit」を押下します。
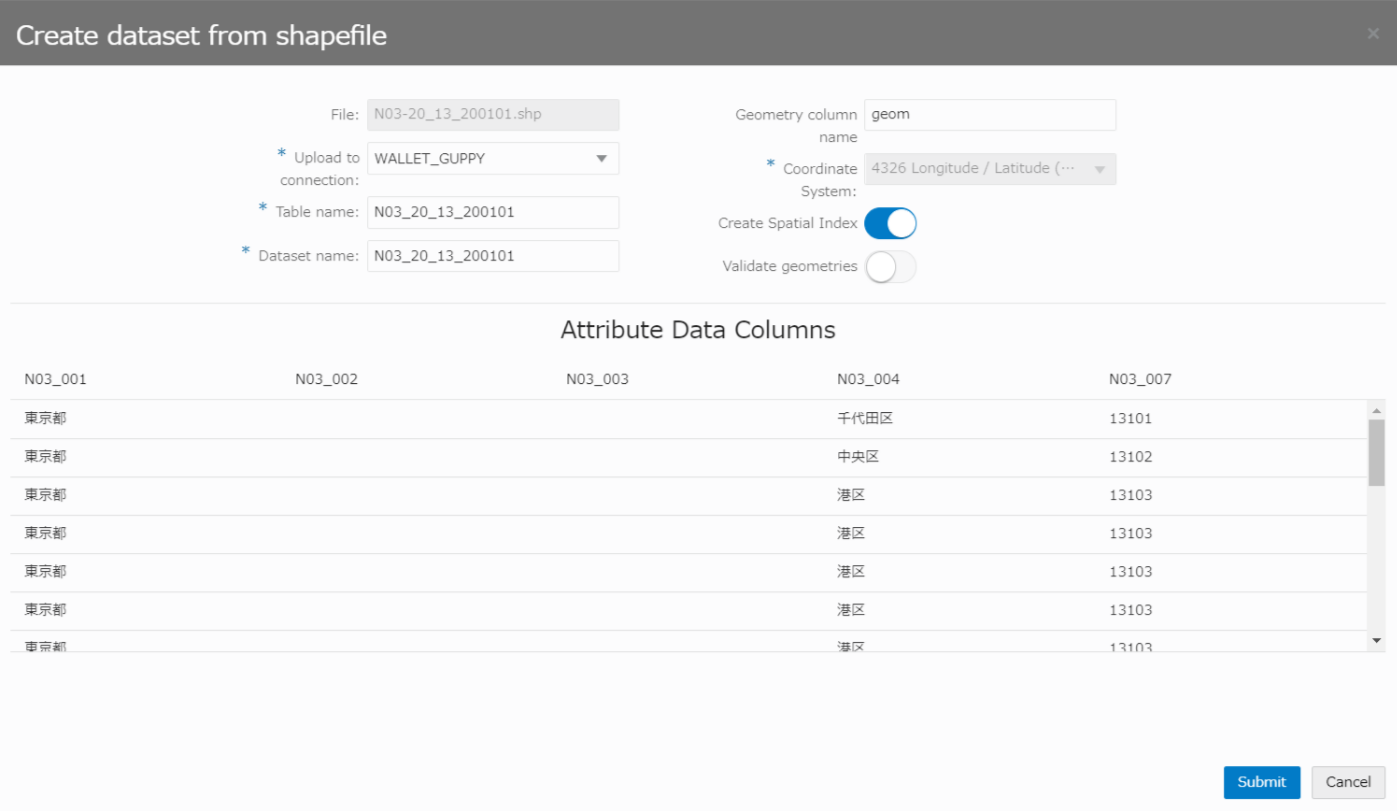
Database上に「N03_12_13_200101表」が作成され、シェープファイルの内容がアップロードされます。
シェープファイルについては前回の投稿「ドラクエウォークのおみやげを集めるのに最寄り駅を調べたい」でも使用しましたが、Shapefile(シェープファイル)とは、Esri社が提唱する、GISデータのフォーマットの1つです。
https://www.esrij.com/gis-guide/esri-dataformat/shapefile/
図形情報と属性情報を持った地図データファイルが集まったファイルで、例えばこの後使う「市区町村の形状データ」では、市町村の形を示す情報や、その市町村の名前などが格納されています。*.shp, *.dbf など、決まった拡張子を持つ複数のファイルからなります。
プロジェクトを作成し、可視化する
プロジェクトを作成(左側の一番上のアイコン)を押下したところです。
地図をドラッグ・拡大縮小して、東京近郊が表示されるようにして、
+ > Add Dataset
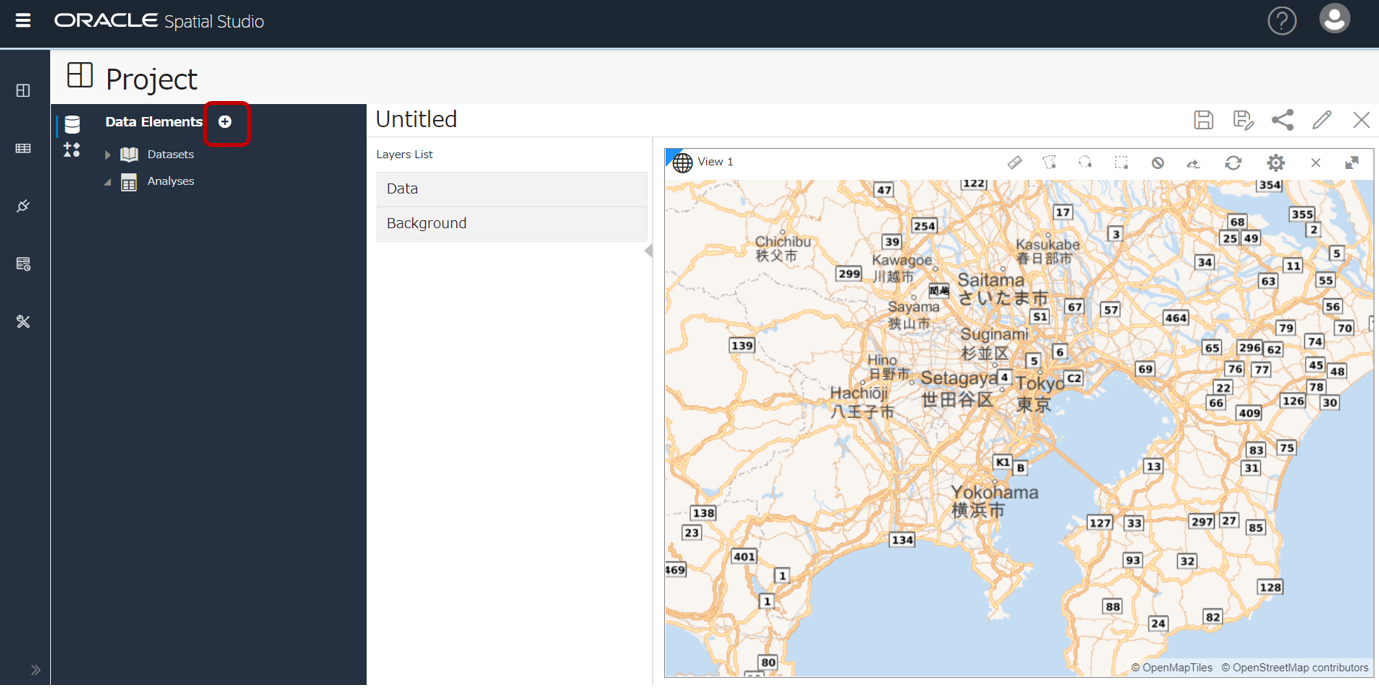
AIRCRAFT_SPと、N03_12_13_200101(=東京都のシェープファイルが格納されたデータセット)を選択し、「OK」
追加されたデータセットの▼を開いて列を表示し、緑の列を地図上にドラッグ(AIRCRAFT_SPのLAT/LON列、N03_12_13_200101のGEOM列)
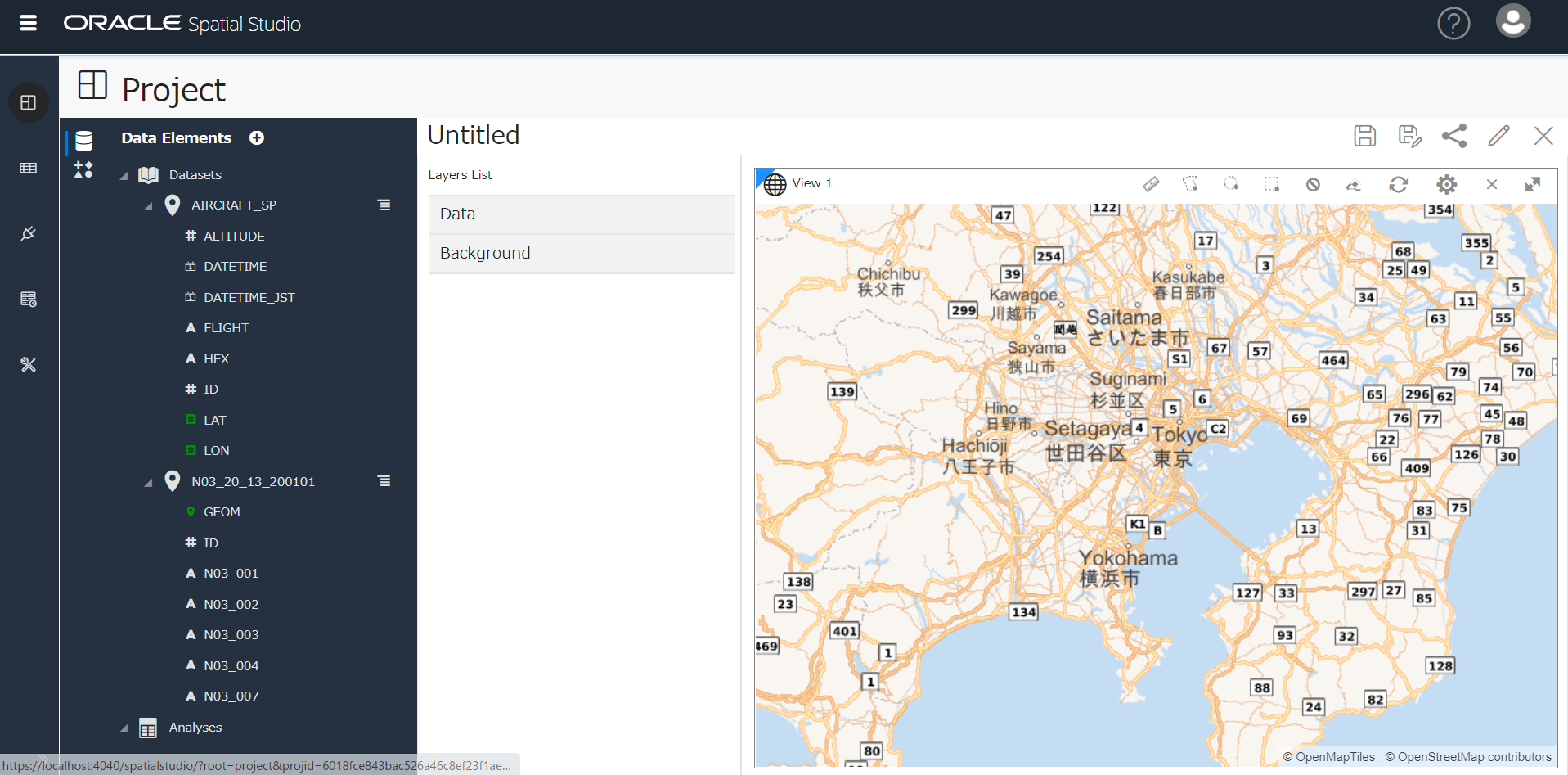
航空機の位置情報がプロットされました(赤)。
東京都の市区町村の形状も表示されました(青い線)。
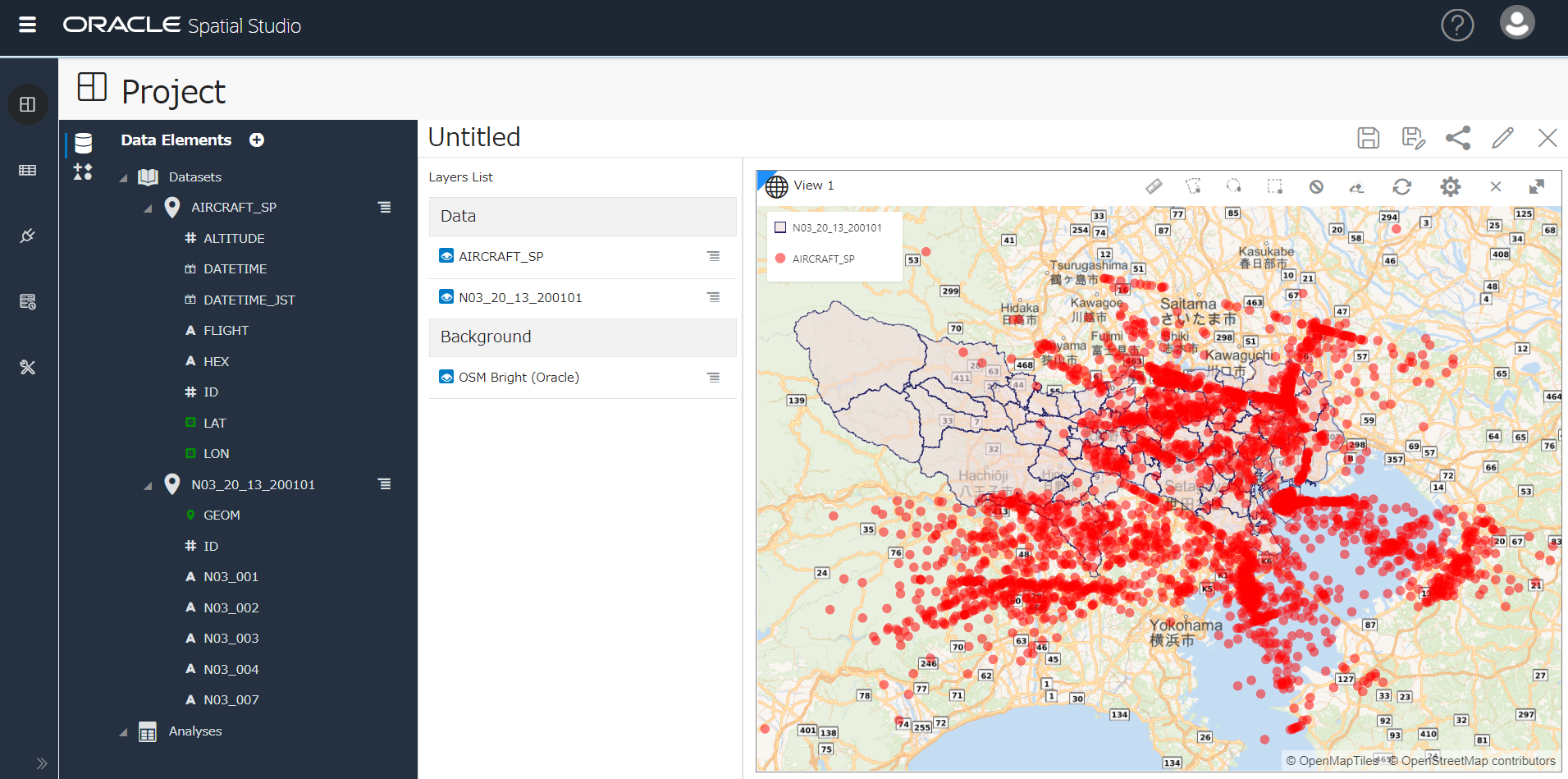
Time Slider を表示し、時間ごとの推移を見る
Time Slider in Oracle Spatial Studio 20.1 の通りに実施。
地図右上の歯車アイコンをクリック

Show time slider を ON に
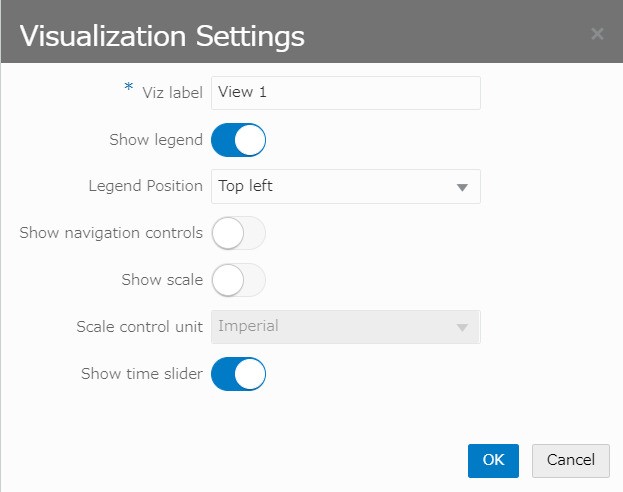
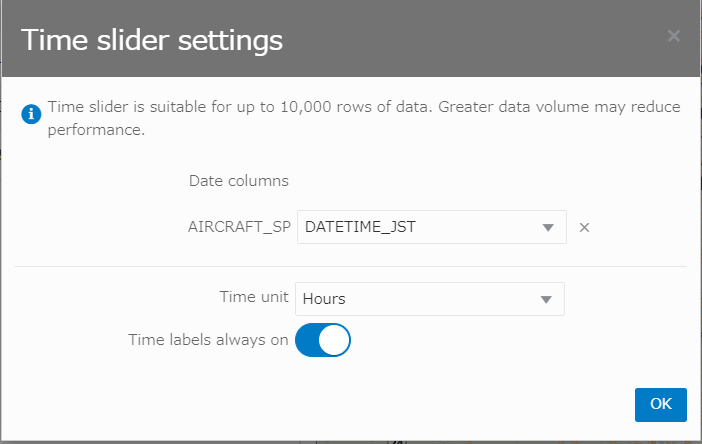
地図上にTime Sliderが表示されました。Time Slider 横の 歯車アイコンをクリック。
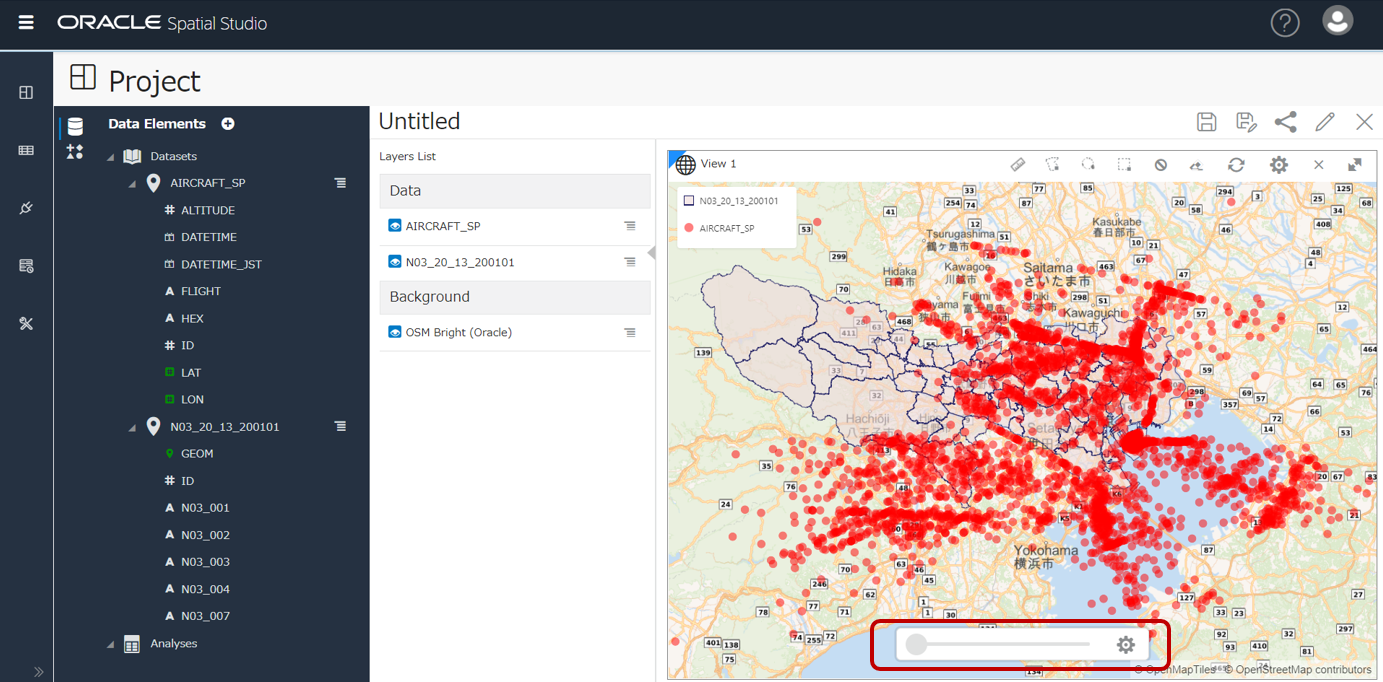
Time Sliderに使用する、AIRCRAFT_SP表の列を指定します。プルダウンで、DATE型の列が選択可能。
(プルダウンが出ないときは一度N03_12_13_200101のレイヤーを削除するとよいかも)
Time Unitは**HOURS(1時間)**を選択しました。他に 秒、日、.. 年、などの選択肢があります。
Time Sliderの利用はデータ量は10000件以内が推奨の旨、記載があります。
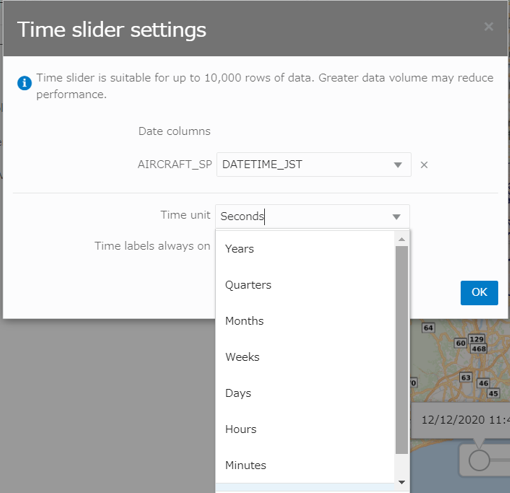
Time Unitは、他に 秒、日、.. 年、などの選択肢がありました。
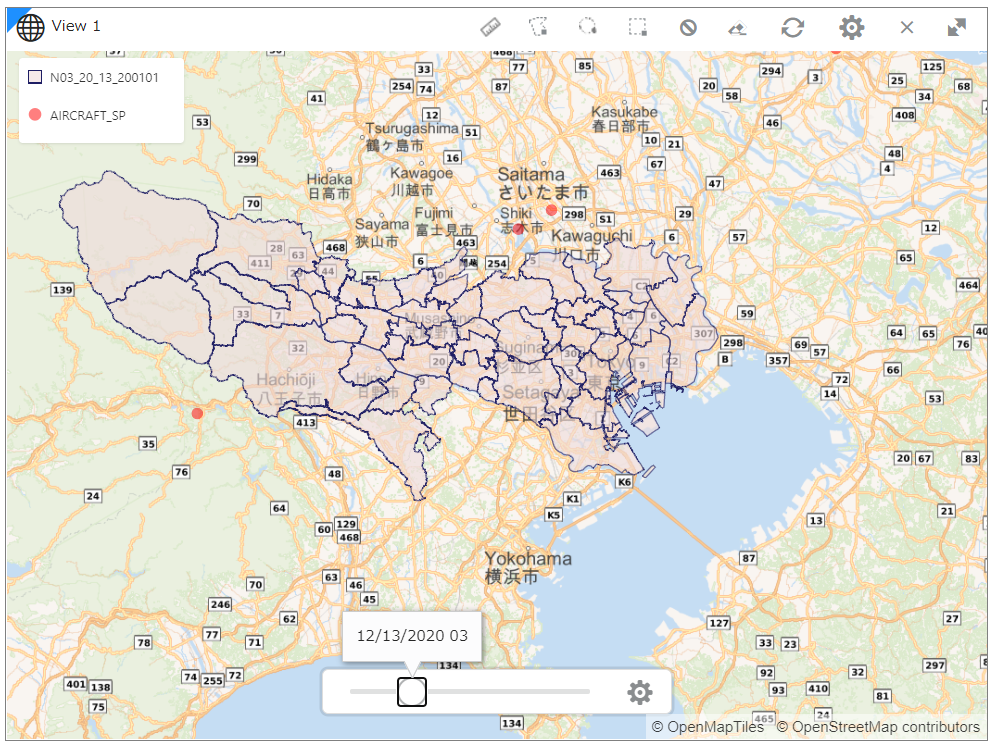
Time Sliderをグリグリ動かしてみます。昼と夜でだいぶ違いがありそうです。
夜間(12月13日、03:00)
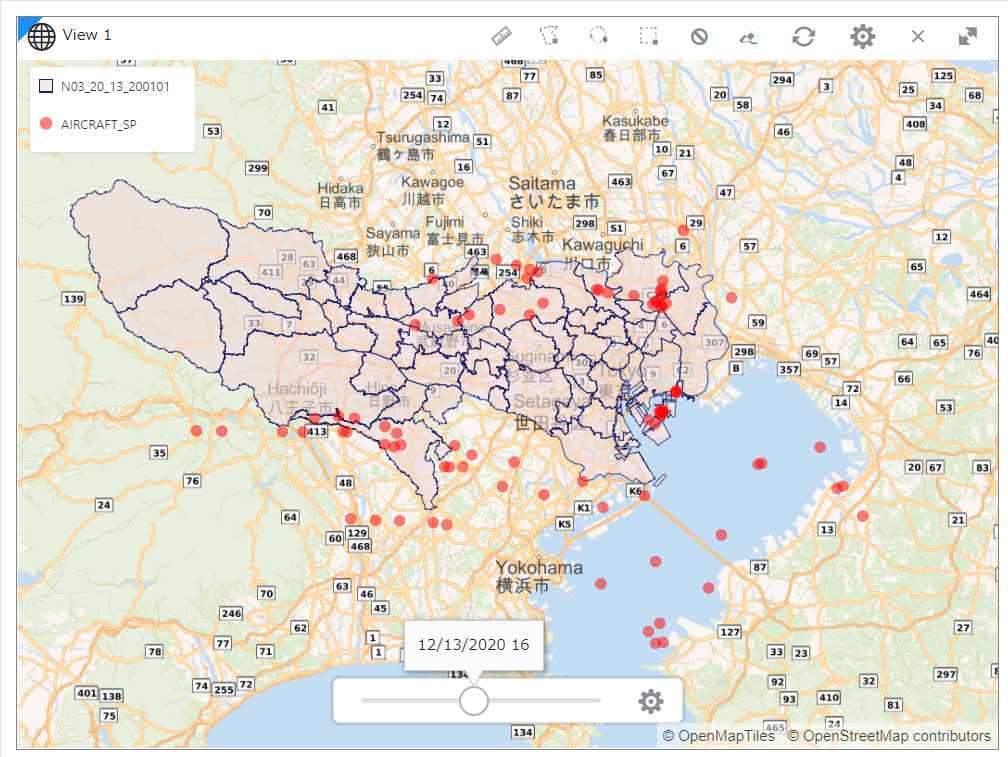
昼間(12月13日、16:00)
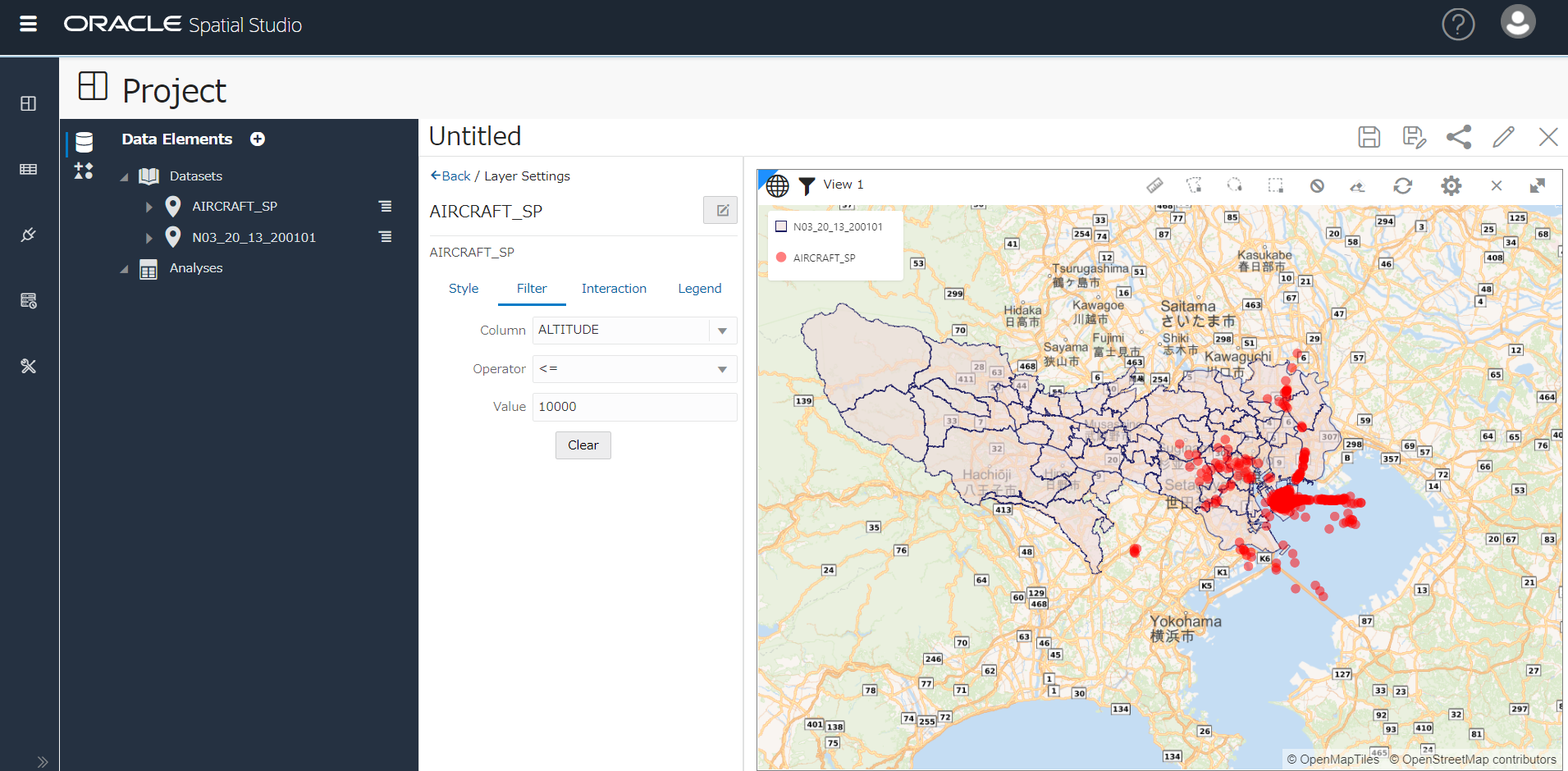
データをフィルタする(高度で絞る)
レイヤーのデータセット右側のメニューから
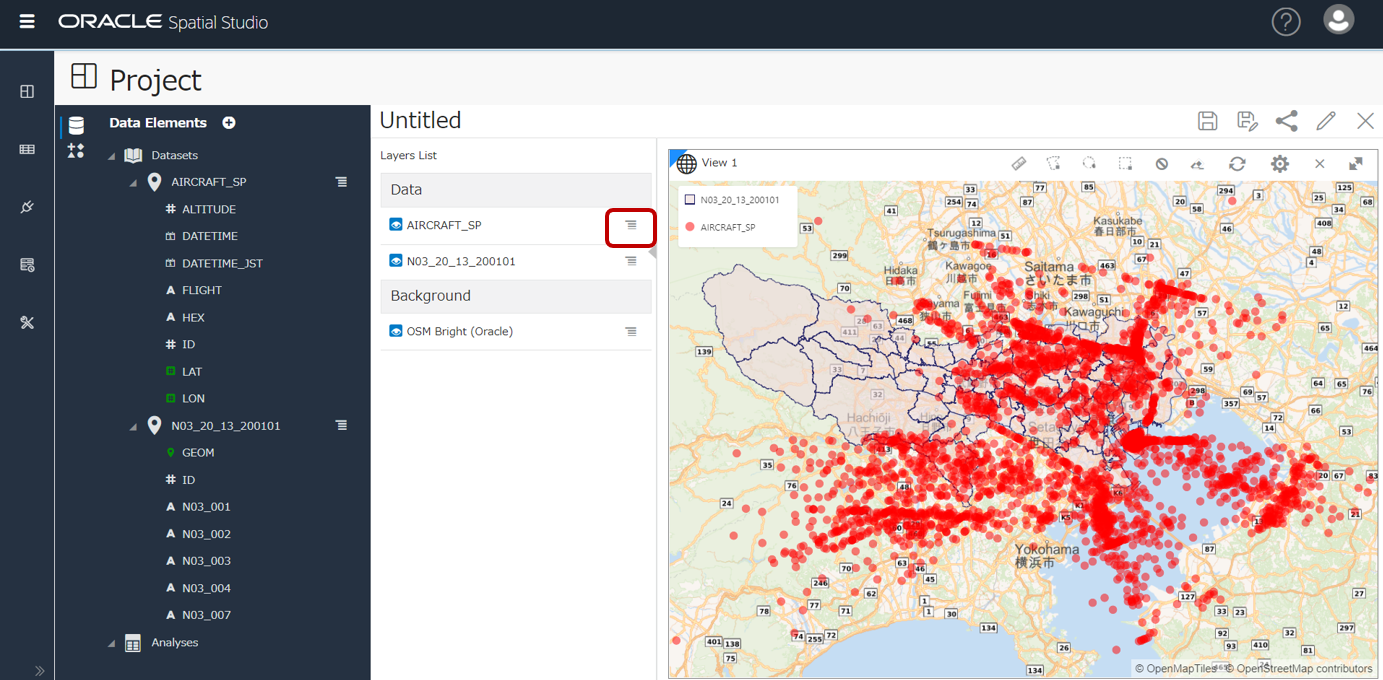
Filterタブで、列を指定して絞り込み可能。下図では 上空 10,000フィート以下のデータのみに絞ってみました。
Autonomous Database上でSQLで簡単な地理空間情報検索を行う
ここからは、SQL Developer Webを使って、SQLで問い合わせを行います。
SDO_ANYINTERACT()など、使用した空間演算子の説明は、前回投稿「ドラクエウォークのおみやげを集めるのに最寄り駅を調べたい」を参照ください。
※ あくまで、今回使用したデータの範囲内での集計結果です。
①どの街の上空に何件の飛行機が観測できたか?
select n03_004, count(1) from
(
SELECT a.flight, a.datetime_jst, a.lat, a.lon, a.altitude, n.n03_001, n.n03_003, n.n03_004
FROM aircraft_sp a, N03_20_13_200101 n
WHERE SDO_ANYINTERACT(n.geom, SDO_GEOMETRY(2001, 4326, SDO_POINT_TYPE(a.lon, a.lat, NULL), NULL, NULL)) = 'TRUE'
)
group by n03_004
order by count(1) desc;
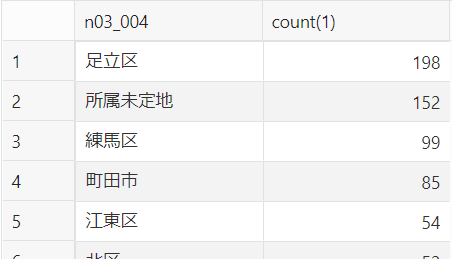
東京都には「所属未定地」という場所があることを初めて知りました。(検索すると、お台場のあるあたりでしょうか?)
②東京上空を通過していく(高度30,000フィート以上)航空機は?
先のSQLにWHERE~ でフィルター条件を追加しました。
select n03_004, count(1) from
(
SELECT a.flight, a.datetime_jst, a.lat, a.lon, a.altitude, n.n03_001, n.n03_003, n.n03_004
FROM aircraft_sp a, N03_20_13_200101 n
WHERE SDO_ANYINTERACT(n.geom, SDO_GEOMETRY(2001, 4326, SDO_POINT_TYPE(a.lon, a.lat, NULL), NULL, NULL)) = 'TRUE'
)
where altitude >= 30000
group by n03_004
order by count(1) desc;
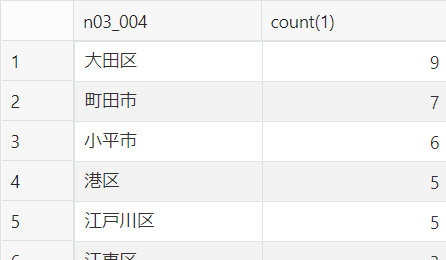
③東京上空の低い高度で飛ぶ航空機(高度10,000フィート以下)と、その高度平均は?
先のSQLと同じ要領で、かつ、区ごとの高度平均を算出しました。
select n03_004, avg(altitude), count(1) from
(
SELECT a.flight, a.datetime_jst, a.lat, a.lon, a.altitude, n.n03_001, n.n03_003, n.n03_004
FROM aircraft_sp a, N03_20_13_200101 n
WHERE SDO_ANYINTERACT(n.geom, SDO_GEOMETRY(2001, 4326, SDO_POINT_TYPE(a.lon, a.lat, NULL), NULL, NULL)) = 'TRUE'
)
where altitude <= 10000
group by n03_004
order by avg(altitude) desc;
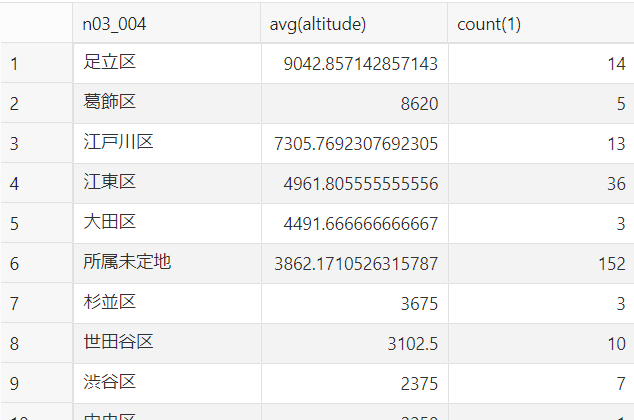
10000フィート以下に絞ったデータを、区ごとに高度を平均し、高度の高い順に並べるSQLです。
スクショは途中で切れていますが10位以下も続いていています。ざっくりですが、東京上空を反時計回りに高度を下げながら羽田空港へ着陸する、羽田新ルートの道筋がうっすら見えているような結果になっているように思います ![]()
まとめ
あくまで個人で収集できた範囲のデータのみを利用して、かつ、データの位置補正などは何も行っていませんが、以下を実施しました。
- Oracle Spatial Studio で可視化し、20.1の新機能 Time Sliderを使ってデータの時間推移を確認
- 東京都の市区町村形状を示すシェープファイルと組み合わせて、簡単な地理空間情報検索をSQLで実行
本投稿は、Oracle Cloud Infrastructure Advent Calendar 2020, Day 15 として書きました。OCIのAdvent Calendarその2もあります。よろしければぜひご参照&投稿を![]()
![]()