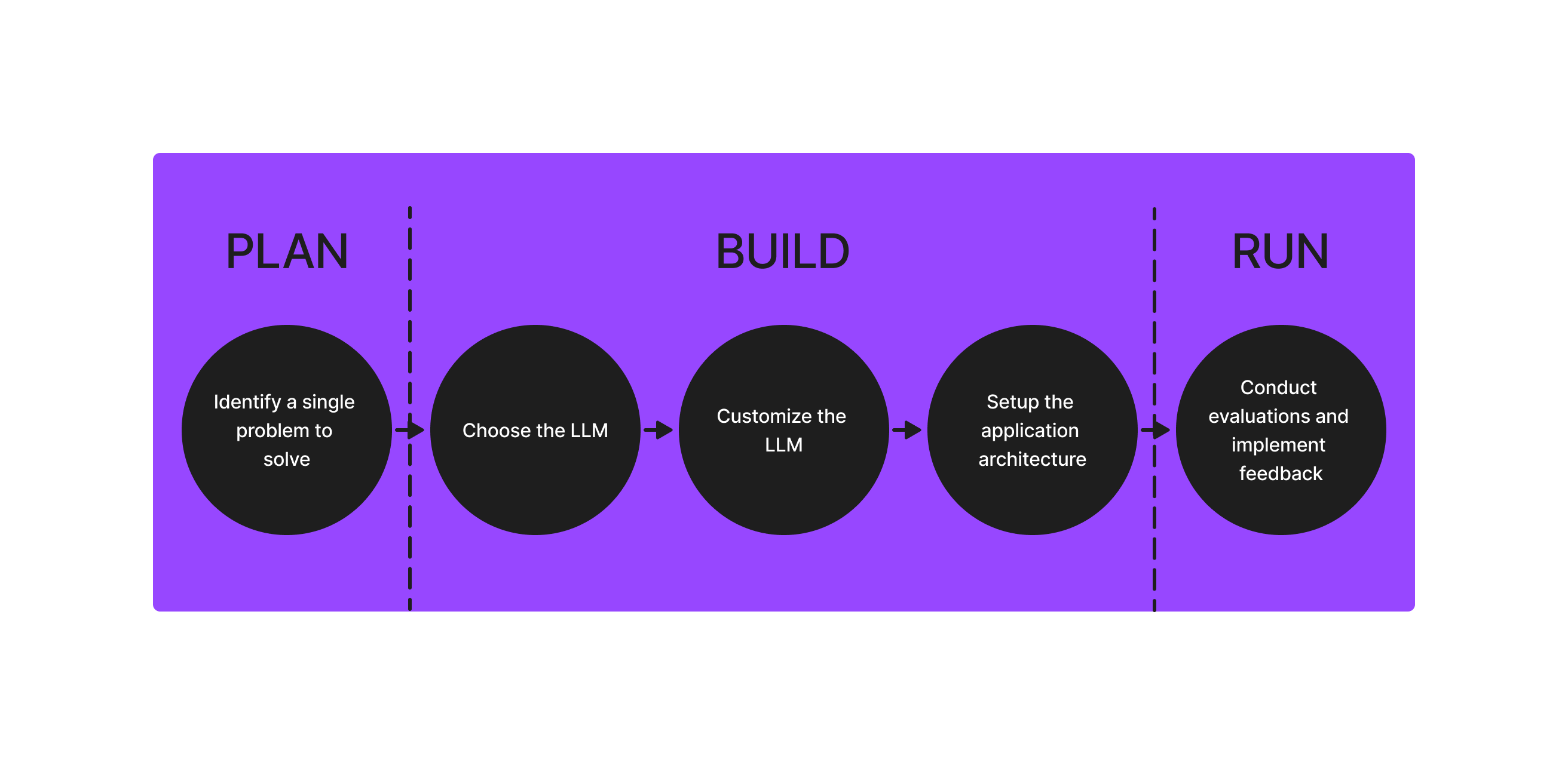
LLM Ops - トレース、評価、分析
このチュートリアルでは、LLM 搭載アプリケーションの構築、観察、評価、分析の方法を学びます。
このチュートリアルは以下のセクションで構成されています。
- LLM 搭載アプリケーションの理解
- トレースを使用したアプリケーションの観察
- LLM Evals を使用したアプリケーションの評価
- UMAP プロジェクションとクラスタリングを使用したアプリケーションの調査とトラブルシューティング
⚠️ このチュートリアルを実行するには、OpenAI キーが必要です。
LLM を使用したアプリケーションの理解
LLM やその他の機械学習モデルを使用してソフトウェアを構築することは、根本的に異なります。一連のコマンドを実行するためにソースコードをバイナリにコンパイルするのではなく、一貫した正確な結果を生成するために、データセット、埋め込み、プロンプト、パラメータの重みをナビゲートする必要があります。LLM の出力は確率論的であるため、毎回同じ決定論的な結果を生成するわけではありません。
LLMアプリケーションの構築には多くの要素が関わりますが、ここではアーキテクチャに焦点を当ててみましょう。以下は、考えられるアーキテクチャの1つを図にしたものです。この図では、アプリケーションがLLMを中心に構築されていることが分かりますが、アプリケーションを機能させるには、他にも多くのコンポーネントが必要であることが分かります。
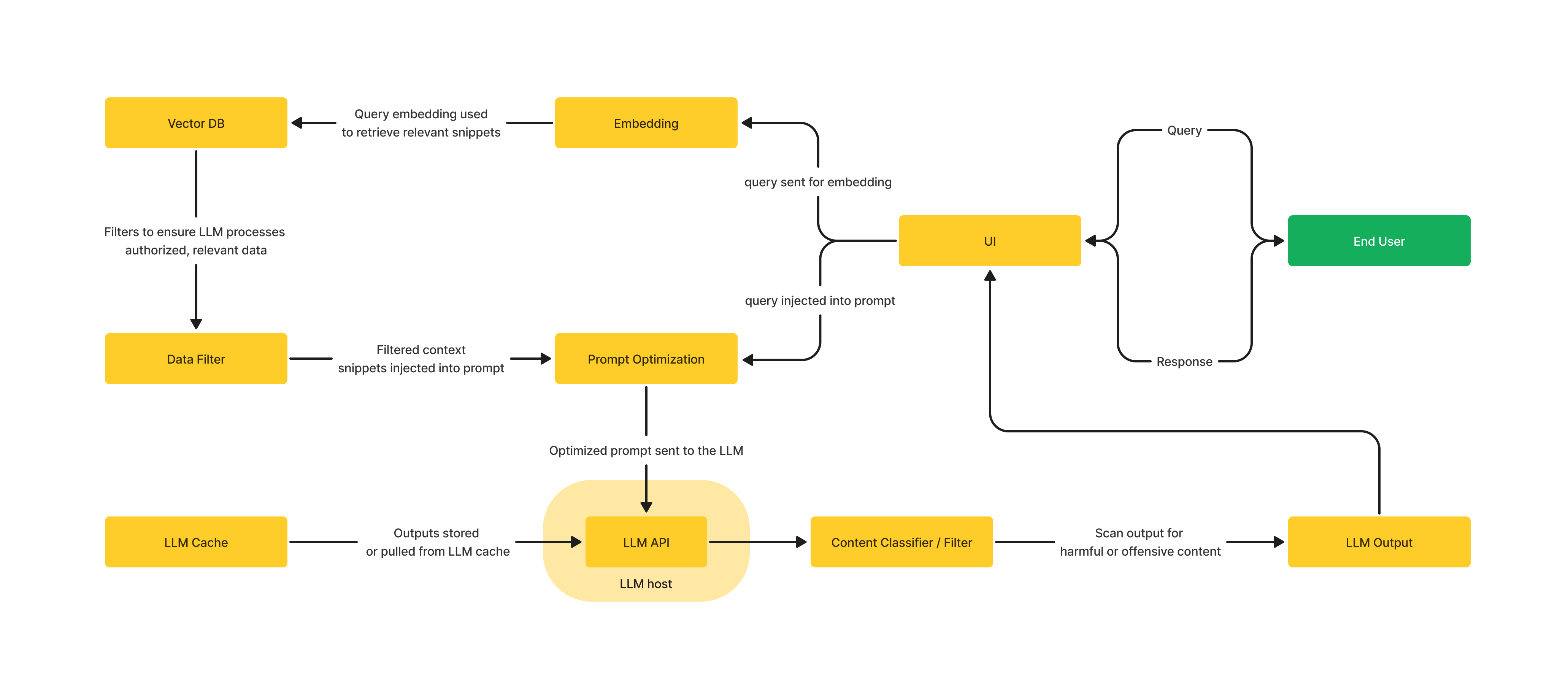
LLMアプリケーションの構築に複雑さが伴うのは、可視性が非常に重要である理由です。Observability(観測可能性)とは、システムの入力と出力を調査することで、その内部状態を把握する能力です。 最高の体験を提供するためには、レスポンス生成プロセスの各ステップを監視、評価、調整する必要があります。 それだけでなく、速度、コスト、精度の最適化を図るために、ある程度のトレードオフが必要になる場合もあります。 LLMアプリケーションの文脈では、LLMトレースなどのテレメトリデータを調査することで、システムの内部状態を把握する必要があります。
トレースを使用してアプリケーションを観察
LLM トレースと Observability により、システムの内部構造を知らなくても、そのシステムに関する質問を投げかけることで、システムを外部から理解することができます。さらに、新しい問題(「未知の未知」)を簡単にトラブルシューティングおよび処理し、「なぜこのようなことが起こるのか?」という疑問に答えることができます。
LLM トレースは、LLM の実行やベクトルストアからの取得、検索エンジンや API などの外部ツールの使用など、LLM およびその周辺のアプリケーションのコンテキストを理解するために使用されるテレメトリデータのカテゴリーとして設計されています。 これにより、アプリケーションが実行する個々のステップの内部動作を理解できるだけでなく、システム全体がどのように実行され、動作しているかを確認することもできます。
トレースは一連のスパンで構成されます。スパンは作業や操作の単位を表します(期間を表すスパンを想像してください)。リクエストが実行する特定の操作を追跡し、その操作が実行された期間に何が起こったかを明らかにします。
LLMトレースは以下のスパンをサポートしています。
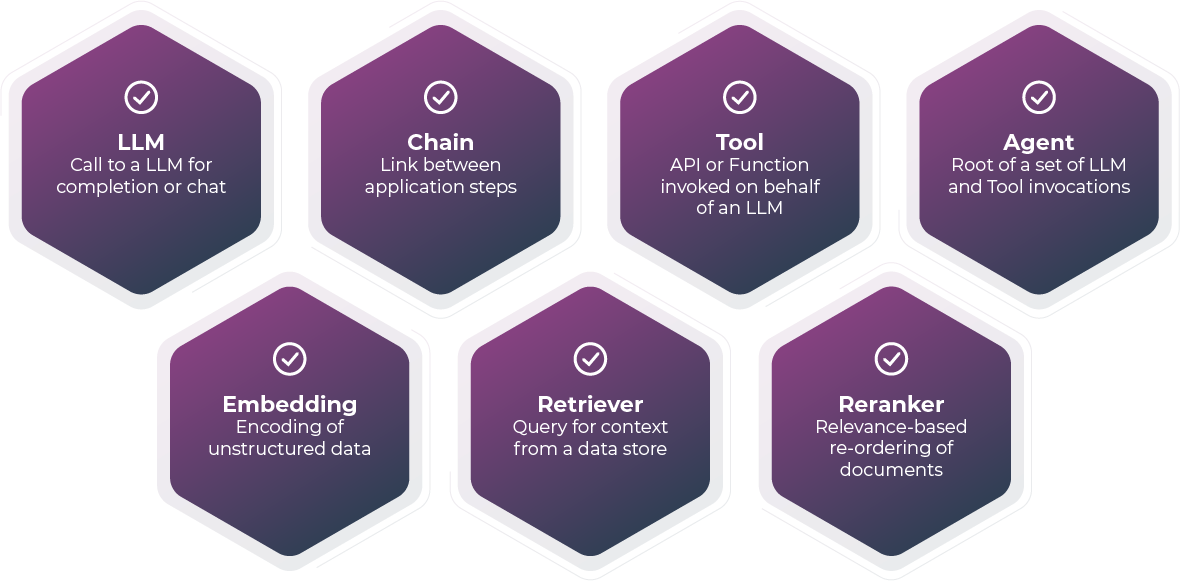
アプリケーションの実行中にその構成要素をキャプチャすることで、Arize Phoenixはアプリケーションの内部動作のより完全な情報を提供することができます。これを説明するために、LLMアプリケーションの例を見て、そのトレースを調べてみましょう。
トレースとスパン
Arize AIに関する質問に答える、LLMを使用した比較的シンプルなアプリケーションを作成してみましょう。この例では、LLMとしてRAGとOpenAI用のLlamaIndexを使用していますが、お好みのLLMを使用できます。アプリケーションの詳細は重要ではありませんが、アーキテクチャは重要です。それでは始めましょう。
!pip install -qq "arize-phoenix[experimental,llama-index]" "openai>=1" gcsfs nest_asyncio
import os
from getpass import getpass
if not (openai_api_key := os.getenv("OPENAI_API_KEY")):
openai_api_key = getpass("🔑 Enter your OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = openai_api_key
import phoenix as px
px.launch_app().view()
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from phoenix.otel import register
tracer_provider = register(endpoint=「http://127.0.0.1:6006/v1/traces」)
LlamaIndexInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)
from gcsfs import GCSFileSystem
from llama_index.core import (
Settings,
StorageContext,
load_index_from_storage,)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
import phoenix as px
file_system = GCSFileSystem(project="public-assets-275721")
index_path = "arize-phoenix-assets/datasets/unstructured/llm/llama-index/arize-docs/index/"
storage_context = StorageContext.from_defaults(
fs=file_system,
persist_dir=index_path,)
Settings.llm = OpenAI(model="gpt-4-turbo-preview")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
index = load_index_from_storage(
storage_context,)
query_engine = index.as_query_engine()
アプリケーションの設定が完了したので、中を見てみましょう。
rom tqdm import tqdm
queries = [
"How can I query for a monitor's status using GraphQL?",
"How do I delete a model?",
"How much does an enterprise license of Arize cost?",
"How do I log a prediction using the python SDK?",
]
for query in tqdm(queries):
response = query_engine.query(query)
print(f"Query: {query}")
print(f"Response: {response}")
アプリケーションを数回実行したので、UIのトレースを見てみましょう
print("The Phoenix UI:", px.active_session().url)
UIでは、インタラクティブなトラブルシューティングが可能です。トレースのソート、フィルタリング、検索が可能です。また、レスポンス生成プロセス中に何が起こったかをよりよく理解するために、各トレースの詳細を表示することもできます。
UIでトレースを表示できることに加え、トレースをクエリして、ノートブックでpandasデータフレームとして使用することもできます。
spans_df[["name", "span_kind", "attributes.input.value", "attributes.retrieval.documents"]].head()
ほんの数行のコードで、アプリケーションの内部動作を可視化することができました。 検索、プロンプト、パラメータの重み付けなどがアプリケーションにどのような影響を与える可能性があるのかをより深く理解できるようになりました。 しかし、この情報から何ができるのでしょうか? LLM 評価を使用してアプリケーションを評価する方法を見てみましょう。
if (
input("The tutorial is about to move on to the evaluation section. Continue [Y/n]?")
.lower()
.startswith("n")
):
assert False, "notebook stopped"
LLM Evals を使用したアプリケーションの評価
評価は、アプリケーションを評価するための主要な基準となります。アプリケーションがデータソースとクエリの範囲に基づいて正確な応答を生成するかどうかを決定します。
個々のクエリとレスポンスを検査することは有益ですが、エッジケースやエラーの件数が増加するにつれ、このアプローチは非現実的になります。 むしろ、一連のメトリクスと自動評価を確立することがより効果的です。 これらのツールは、システム全体のパフォーマンスに関する洞察を提供し、精査が必要な特定の領域を特定することができます。
まず、トレースを実行可能なデータセットに変換してみましょう
from phoenix.session.evaluation import get_qa_with_reference, get_retrieved_documents
retrieved_documents_df = get_retrieved_documents(px.active_session())
queries_df = get_qa_with_reference(px.active_session())
これで、PhoenixのLLM Evalsを使用してこれらのクエリを評価することができます。LLM EvalsはLLMを使用して、さまざまな基準に基づいてアプリケーションの評価を行います。この例では、evalsライブラリを使用して幻覚があるかどうか、Q&Aの正確性(アプリケーションが質問に正しく回答しているかどうか)を確認します。
import nest_asyncio
from phoenix.evals import (
HALLUCINATION_PROMPT_RAILS_MAP,
HALLUCINATION_PROMPT_TEMPLATE,
QA_PROMPT_RAILS_MAP,
QA_PROMPT_TEMPLATE,
OpenAIModel,
llm_classify,
)
nest_asyncio.apply() # Speeds up OpenAI API calls
# Check if the application has any indications of hallucinations
hallucination_eval = llm_classify(
dataframe=queries_df,
model=OpenAIModel(model="gpt-4o", temperature=0.0),
template=HALLUCINATION_PROMPT_TEMPLATE,
rails=list(HALLUCINATION_PROMPT_RAILS_MAP.values()),
provide_explanation=True, # Makes the LLM explain its reasoning
)
hallucination_eval["score"] = (
hallucination_eval.label[~hallucination_eval.label.isna()] == "factual"
).astype(int)
# Check if the application is answering questions correctly
qa_correctness_eval = llm_classify(
dataframe=queries_df,
model=OpenAIModel(model="gpt-4o", temperature=0.0),
template=QA_PROMPT_TEMPLATE,
rails=list(QA_PROMPT_RAILS_MAP.values()),
provide_explanation=True, # Makes the LLM explain its reasoning
concurrency=4,
)
qa_correctness_eval["score"] = (
qa_correctness_eval.label[~qa_correctness_eval.label.isna()] == "correct"
).astype(int)
hallucination_eval.head()
qa_correctness_eval.head()
結果からわかるように、クエリの1つが幻覚としてフラグ付けされました。これらの結果をフェニックスサーバーにログ記録して、UIで幻覚を表示してみましょう。
from phoenix.trace import SpanEvaluations
px.Client().log_evaluations(
SpanEvaluations(eval_name="Hallucination", dataframe=hallucination_eval),
SpanEvaluations(eval_name="QA Correctness", dataframe=qa_correctness_eval),
)
幻覚が記録されたので、それらを UI で見てみましょう。UI で幻覚に対応するトレースが明確にマークされていることがわかるでしょう。これで、それらに対してクエリを実行できます!
print("The Phoenix UI:", px.active_session().url)
特定のクエリが幻覚や不正確な回答を引き起こしていることが判明しました。LLM Evals を使用して、これらの問題が RAG の検索プロセスによって引き起こされているかどうかを特定できるか見てみましょう。LLM を使用して、検索されたチャンクがクエリに関連しているかどうかを評価します。
from phoenix.evals import (
RAG_RELEVANCY_PROMPT_RAILS_MAP,
RAG_RELEVANCY_PROMPT_TEMPLATE,
OpenAIModel,
llm_classify,
)
retrieved_documents_eval = llm_classify(
dataframe=retrieved_documents_df,
model=OpenAIModel(model="gpt-4o", temperature=0.0),
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
rails=list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values()),
provide_explanation=True,
)
retrieved_documents_eval["score"] = (
retrieved_documents_eval.label[~retrieved_documents_eval.label.isna()] == "relevant"
).astype(int)
retrieved_documents_eval.head()
LLMに送信されるプロンプトを汚染している可能性がある、関連性の低いテキストの塊が大量に取得されているようです。これらの評価をフェニックスにログ出力してみましょう。フェニックスが自動的に検索メトリクスを計算してくれます。
from phoenix.trace import DocumentEvaluations
px.Client().log_evaluations(
DocumentEvaluations(eval_name="Relevance", dataframe=retrieved_documents_eval)
)
UIを再度確認すると、Phoenixが検索結果の評価指標(精度、ndcg、ヒット率)を集約していることがわかります。 幻覚や不正解は、検索結果の質の悪さと直接相関していることがわかります!
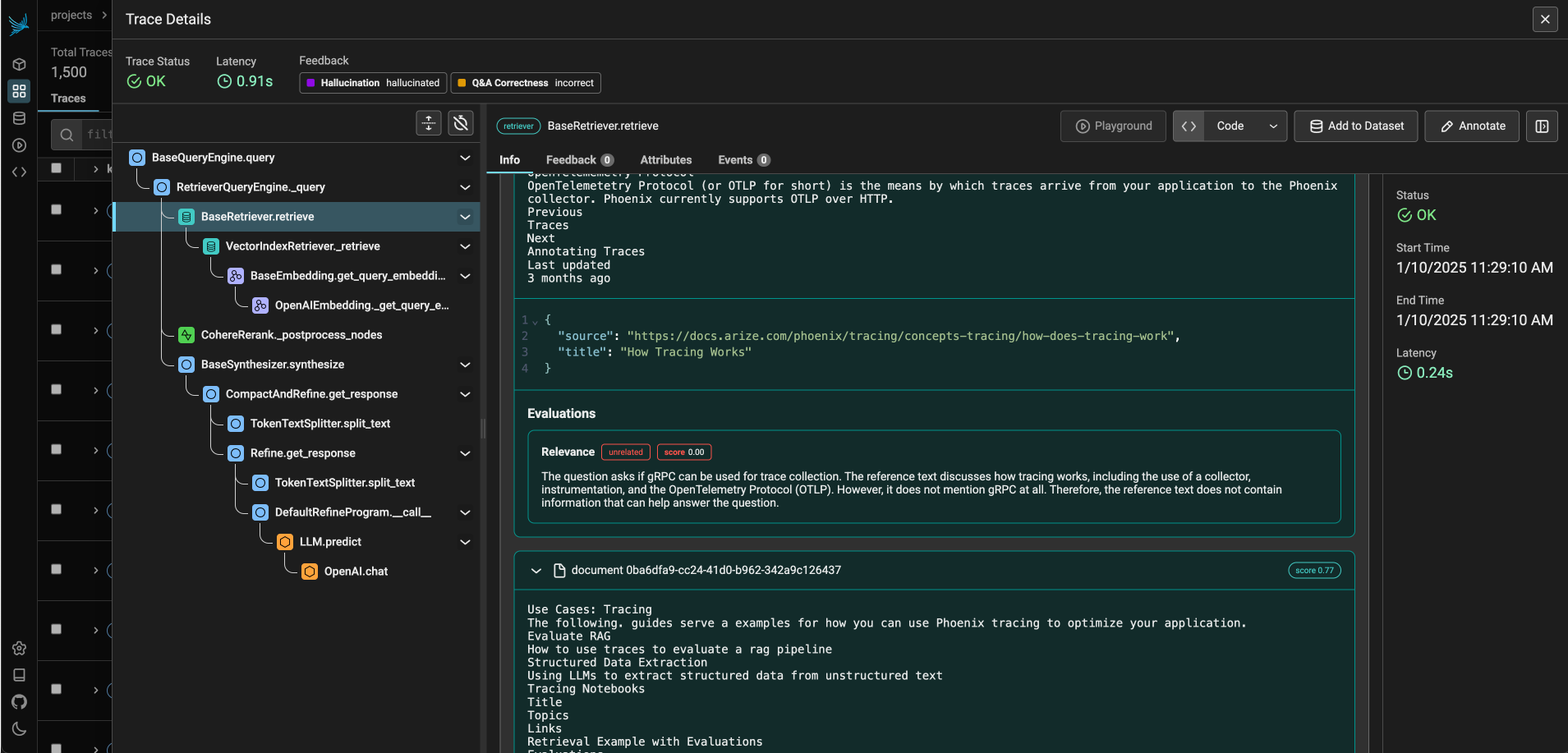
アプリケーションの品質を判断するために使用できる評価メトリクスは他にも多数あります。Phoenixはトレースだけでなく、個々のスパン(レトリバーなど)の評価や、ドキュメントチャンクの検索分析もサポートしています。評価メトリクスは、特定のユースケースに合わせてカスタマイズすることもできます。詳細は、Phoenixのドキュメントを参照してください。
if (
input("The tutorial is about to move on to the analysis section. Continue [Y/n]?")
.lower()
.startswith("n")
):
assert False, "notebook stopped"
px.close_app() # Close the Phoenix UI
UMAP プロジェクションとクラスタリングを使用したアプリケーションの調査とトラブルシューティング
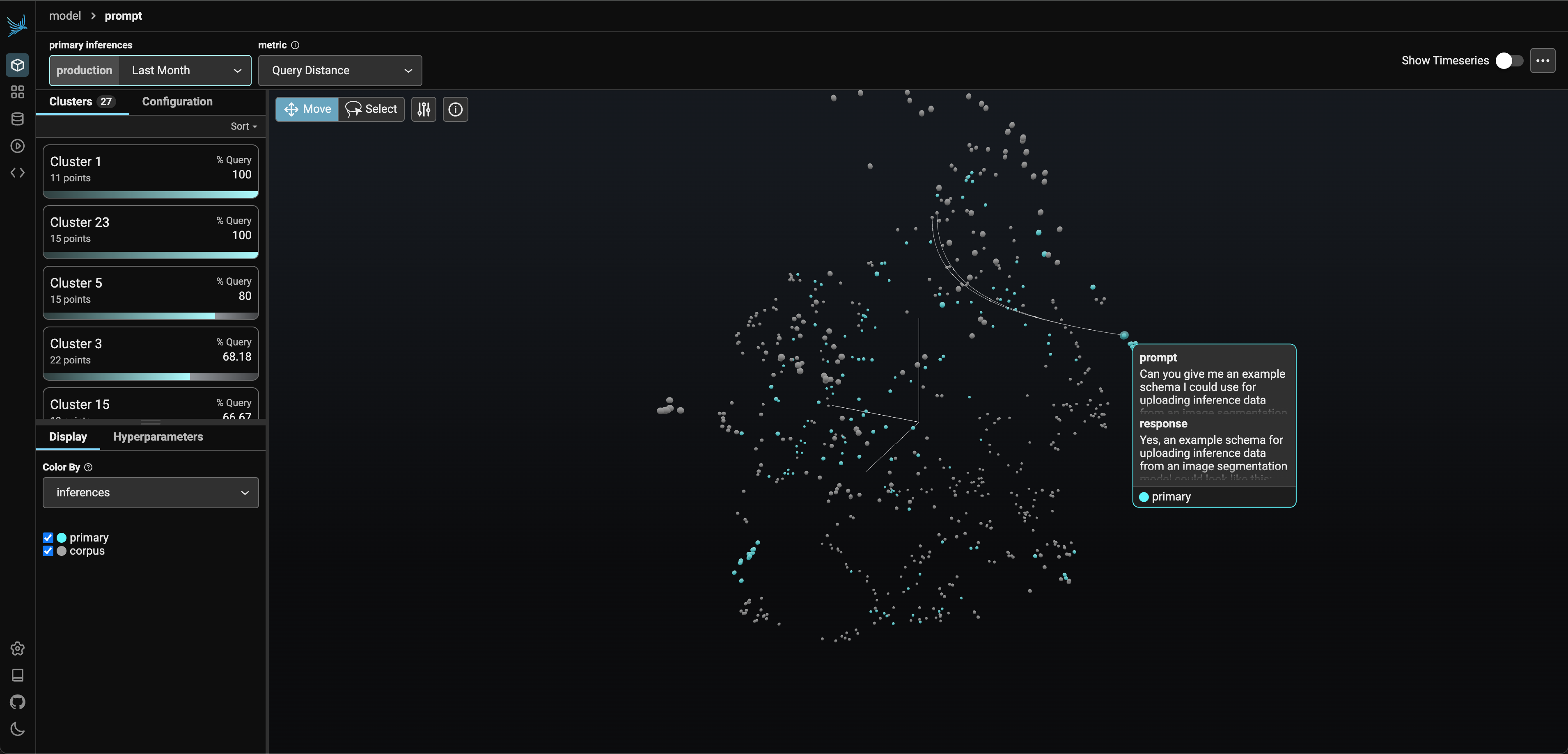
これまで、アプリケーションのトレース方法と評価方法について説明してきました。しかし、アプリケーションをより高いレベルで理解する必要がある場合はどうでしょうか。アプリケーションが特定のトピックに対してパフォーマンスが悪いのか、あるいはアプリケーションを改善するために使用できるデータ内のパターンがあるのかを理解する必要がある場合はどうでしょうか。このような場合に役立つのが、UMAP プロジェクションとクラスタリングです。UMAPとクラスタリングにより、アプリケーションのクエリ埋め込みを3D空間で表示することができます。これにより、データ内のパターンを確認し、さまざまなクラスタ(意味グループ)におけるアプリケーションのパフォーマンスを把握することができます。
アプリケーションを4つのクエリに対してのみ実行したため、データ内のパターンを確認することはできません。より大規模なクエリデータセットを取り込み、アプリケーションを再度実行してみましょう。
import pandas as pd
# Pull in queries from the LLM
query_df = pd.read_parquet(
"http://storage.googleapis.com/arize-phoenix-assets/datasets/unstructured/llm/llama-index/arize-docs/query_data_complete3.parquet",
)
query_ds = px.Inferences.from_open_inference(query_df)
query_ds.dataframe.head()
ナレッジベースのエンベッディングも取得してみましょう。これにより、アプリケーションがドキュメントのチャンクをどのように取得しているかを確認することができます。
def storage_context_to_dataframe(storage_context: StorageContext) -> pd.DataFrame:
"""Converts the storage context to a pandas dataframe.
Args:
storage_context (StorageContext): Storage context containing the index
data.
Returns:
pd.DataFrame: The dataframe containing the index data.
"""
document_ids = []
document_texts = []
document_embeddings = []
docstore = storage_context.docstore
vector_store = storage_context.vector_store
for node_id, node in docstore.docs.items():
document_ids.append(node.hash) # use node hash as the document ID
document_texts.append(node.text)
document_embeddings.append(np.array(vector_store.get(node_id)))
return pd.DataFrame(
{
"document_id": document_ids,
"text": document_texts,
"text_vector": document_embeddings,
}
)
database_df = storage_context_to_dataframe(storage_context)
database_df = database_df.drop_duplicates(subset=["text"])
database_df.head()
それでは、この2つのデータセットを使ってPhoenixを起動してみましょう。
# get a random sample of 500 documents (including retrieved documents)
# this will be handled by by the application in a coming release
num_sampled_point = 500
retrieved_document_ids = set(
[
doc_id
for doc_ids in query_df[":feature.[str].retrieved_document_ids:prompt"].to_list()
for doc_id in doc_ids
]
)
retrieved_document_mask = database_df["document_id"].isin(retrieved_document_ids)
num_retrieved_documents = len(retrieved_document_ids)
num_additional_samples = num_sampled_point - num_retrieved_documents
unretrieved_document_mask = ~retrieved_document_mask
sampled_unretrieved_document_ids = set(
database_df[unretrieved_document_mask]["document_id"]
.sample(n=num_additional_samples, random_state=0)
.to_list()
)
sampled_unretrieved_document_mask = database_df["document_id"].isin(
sampled_unretrieved_document_ids
)
sampled_document_mask = retrieved_document_mask | sampled_unretrieved_document_mask
sampled_database_df = database_df[sampled_document_mask]
database_schema = px.Schema(
prediction_id_column_name="document_id",
prompt_column_names=px.EmbeddingColumnNames(
vector_column_name="text_vector",
raw_data_column_name="text",
),
)
database_ds = px.Inferences(
dataframe=sampled_database_df,
schema=database_schema,
name="database",
)
(session := px.launch_app(primary=query_ds, corpus=database_ds, run_in_thread=False)).View()
Phoenixの埋め込み投影機能を使用すると、クエリの埋め込みを3D空間で表示することができます。ご覧になっているのは、各点がクエリを表す点群です。埋め込みが低次元空間に投影されると、UMAPは埋め込みがエンコードする意味的な距離を維持します。つまり、より近くに位置する点はより類似しているということです。これにより、データ内のパターンを確認し、さまざまなクラスタでアプリケーションがどのように動作しているかを理解することができます。クラスタをクリックすると、ナレッジベースから大幅に離れたクエリのクラスタが表示されます。これは、ナレッジベースがユーザーの質問に答えるのに十分な情報を含まないことを意味します(この場合、ドキュメントのチャンクには価格に関する情報が含まれていません。このクラスタを見つけることができますか?)。
Phoenixの埋め込みビューは、色付けや評価によるクラスターの測定値もサポートしています。つまり、ユーザーフィードバックの悪い部分や幻覚を見ている部分を見つけるのに使用できるということです。Phoenixの埋め込みビューは、テキスト、画像、動画の埋め込みをサポートしているため、ほとんどの形式の非構造化データを分析することができます。
最後に、Phoenixはクエリとドキュメントの断片の間の関連性を描画することができます。これにより、各クエリでどのドキュメントの断片が取得されているかを確認し、それらの意味的な距離を視覚化することができます。
結論
Phoenixは、LLMを搭載したアプリケーションを構築するための強力なパートナーです。開発プロセスのあらゆる段階で、アプリケーションの観察、評価、調査を行うことができます。詳細については、Phoenixのドキュメントを参照してください。