SHA-1 とは
SHA-1 は、任意の長さのデータから固定長 (20バイト) のデータ (ハッシュ) を計算するアルゴリズムである。
同じ SHA-1 ハッシュ値を持つ異なるデータの組が発見されており (SHAttered)、署名などの暗号用途には使用してはいけないことになっている。
一方、暗号的な強度が重要でない場面においてデータから識別子を得るには有効であり、Git などで活用されている。
さらに、二要素認証用のワンタイムパスワードを得るために広く用いられている TOTP (Time-Based One-Time Password Algorithm) の計算でも、内部で SHA-1 が用いられている。
SHA-1 の求め方
SHA-1 の求め方は、RFC 3174 で定義されている。
SHA-1 の計算では、数値とバイト列の変換にビッグエンディアンが用いられる。
これは、数値の上位の桁ほど前のバイトに格納する表現方法である。
例えば、数値 0x12345678 は、バイト列 0x12 0x34 0x56 0x78 で表現できる。
入力データ
SHA-1 を求めるための入力としては、長さ $0$ バイト以上 $2^{61}-1$ バイト以下の任意のバイト列を用いることができる。
SHA-1 の本来の入力は、長さ $2^{64}$ ビット未満のビット列である。
しかし、この記事では入力として計算機で広く用いられるバイト列を扱う。
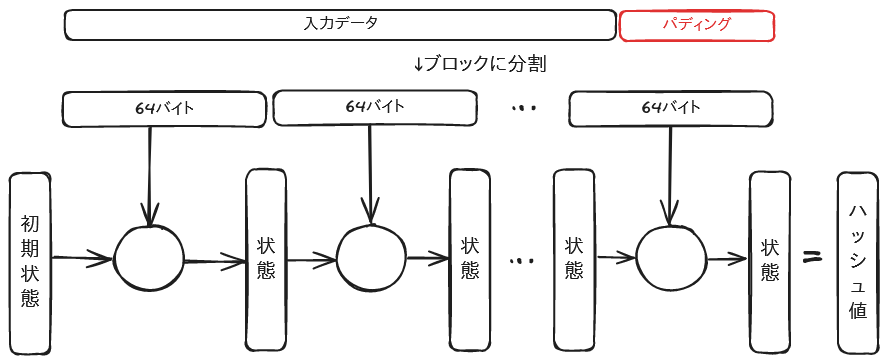
パディングとブロックへの分割
入力のバイト列は、64 バイトのブロックごとに処理される。
入力を前から順に 64 バイトずつとり、順番に処理 (状態の更新) をしていく。
最後のブロックの処理が完了した後の状態が、そのままハッシュ値となる。
入力のバイト列の終端の後、必ず以下のデータ (パディング) を順に加える。
- 値
0x80のバイト 1 個 - 値
0x00のバイト 0 個以上 - 入力のビット数 (バイト数の8倍) 8 バイト、ビッグエンディアン
2番目の値 0x00 のバイトは、全体の長さが 64 バイトの倍数になる最小の数を加える。
3番目の入力のビット数には、ここで追加するパディングの長さは含めない。
入力のバイト列にパディングを加えたデータの長さは 64 バイトの倍数となり、全てのデータをブロックとして処理する。
入力のバイト数を 64 で割った余りが 56 以上の場合、値 0x80 のバイトと入力のビット数を加えようとするとブロックの残りの部分 (8 バイト以下) に収まらない。
このような場合は、パディングが最後の 2 個のブロックにまたがる。
状態と初期状態
SHA-1 の計算で用いる状態は、5 個の 32 ビット符号なし整数 H0, H1, H2, H3, H4 で表される。
初期状態は、以下の値である。
H0 = 0x67452301
H1 = 0xEFCDAB89
H2 = 0x98BADCFE
H3 = 0x10325476
H4 = 0xC3D2E1F0
ブロックの処理 (状態の更新)
補助関数と定数の準備
まず、ブロックの処理に用いる補助関数と定数を定義する。
左ローテート S_n(x)
32 ビットの符号なし整数 x を左に n ビットローテートした値を、S_n(x) とする。
すなわち、
S_n(x) = (x << n) | (x >> (32-n))
である。(シフト演算は論理シフト (空いた部分は常に 0 で埋める) を用いる)
ラウンド用関数 f_t(B,C,D) と定数 K(t)
何ラウンド目かを表す整数 t の値によって、関数 f_t(B,C,D) と定数 K(t) を以下のように定める。
t |
f_t(B,C,D) |
K(t) |
|---|---|---|
| 0 ~ 19 | (B & C) | ((~B) & D) |
0x5A827999 |
| 20 ~ 39 | B ^ C ^ D |
0x6ED9EBA1 |
| 40 ~ 59 | (B & C) | (B & D) | (C & D) |
0x8F1BBCDC |
| 60 ~ 79 | B ^ C ^ D |
0xCA62C1D6 |
ただし、演算子 &、|、^、~ はそれぞれビットごとの AND 演算、OR 演算、XOR 演算、NOT 演算を表す。
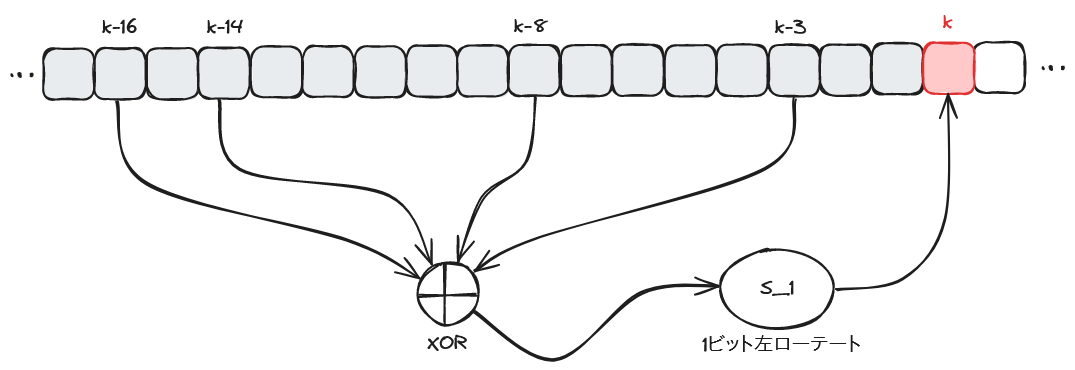
ブロックから整数の配列に変換する
64 バイトのブロック (バイト列) から、次のようにして 32 ビット符号なし整数の配列 W(0), W(1), ... , W(79) を求める。
- バイト列から 4 バイトずつ順に取り出し、ビッグエンディアンで
W(0), W(1), ... , W(15)とする -
k = 16, ... , 79について、W(k)を以下の式で順に計算する (これまでに計算したW(x)の値を用いる)
W(k) = S_1(W(k-3) ^ W(k-8) ^ W(k-14) ^ W(k-16))
整数の配列を用いて状態を更新する
まず、状態 H0, H1, H2, H3, H4 をそれぞれ変数 A, B, C, D, E にコピーする。
A = H0
B = H1
C = H2
D = H3
E = H4
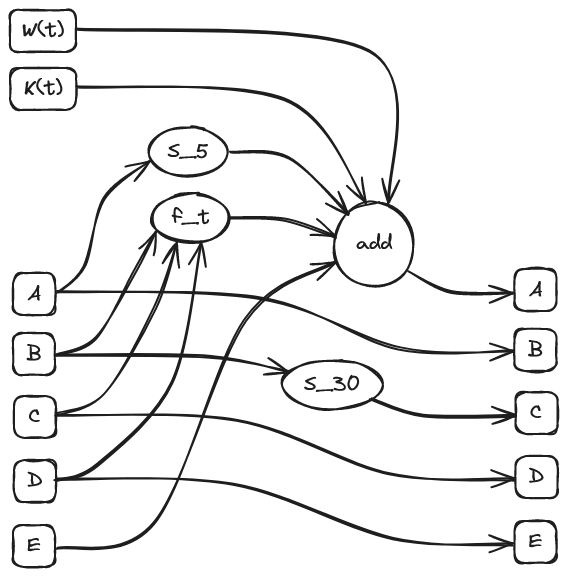
次に、t = 0, 1, ... , 79 について、それぞれ以下の処理を行って変数 A, B, C, D, E を更新する。
TEMP = S_5(A) + f_t(B,C,D) + E + W(t) + K(t)
E = D
D = C
C = S_30(B)
B = A
A = TEMP
すなわち、1 回の処理では以下のように値が動き、B, C, D, E については A, B, C, D 由来の値が 1 個ずつずれて入ることがわかる。
最後に、t = 79 までの処理を終えた後の変数 A, B, C, D, E の値を、それぞれ状態 H0, H1, H2, H3, H4 に加算する。
H0 = H0 + A
H1 = H1 + B
H2 = H2 + C
H3 = H3 + D
H4 = H4 + E
ここで、この処理 (t = 0, 1, ... , 79 の処理を含む) における加算 + は通常の 32 ビット符号なし整数の足し算を表す。
あふれた桁は捨てる。(すなわち、$\mod 2^{32}$ での足し算を行う)
最終状態からハッシュ値への変換
全てのブロックの処理を完了した後の状態 H0, H1, H2, H3, H4 を、この順番で 4 バイトのビッグエンディアンで表現し、連結する。
得られた 20 バイトのデータが、求める SHA-1 ハッシュ値である。
実装例
ブロックを受け取って状態の更新処理を行うプログラムの例 (C言語) を以下に示す。
#include <stdio.h>
#include <inttypes.h>
uint32_t read_uint32(const void* ptr) {
const uint8_t* uptr = ptr;
return ((uint32_t)uptr[0] << 24) | ((uint32_t)uptr[1] << 16) | ((uint32_t)uptr[2] << 8) | uptr[3];
}
uint32_t rotate(uint32_t x, int n) {
return (x << n) | (x >> (32 - n));
}
void update_sha1_status(uint32_t H[5], const void* block) {
uint32_t W[80], A, B, C, D, E;
int i;
/* ブロックから整数の配列に変換する */
for (i = 0; i < 16; i++) {
W[i] = read_uint32((const uint8_t*)block + 4 * i);
}
for (i = 16; i < 80; i++) {
W[i] = rotate(W[i - 16] ^ W[i - 14] ^ W[i - 8] ^ W[i - 3], 1);
}
/* 整数の配列を用いて状態を更新する */
A = H[0]; B = H[1]; C = H[2]; D = H[3]; E = H[4];
for (i = 0; i < 20; i++) {
uint32_t TEMP = rotate(A, 5) + ((B & C) | ((~B) & D)) + E + W[i] + UINT32_C(0x5A827999);
E = D; D = C; C = rotate(B, 30); B = A; A = TEMP;
}
for (i = 20; i < 40; i++) {
uint32_t TEMP = rotate(A, 5) + (B ^ C ^ D) + E + W[i] + UINT32_C(0x6ED9EBA1);
E = D; D = C; C = rotate(B, 30); B = A; A = TEMP;
}
for (i = 40; i < 60; i++) {
uint32_t TEMP = rotate(A, 5) + ((B & C) | (B & D) | (C & D)) + E + W[i] + UINT32_C(0x8F1BBCDC);
E = D; D = C; C = rotate(B, 30); B = A; A = TEMP;
}
for (i = 60; i < 80; i++) {
uint32_t TEMP = rotate(A, 5) + (B ^ C ^ D) + E + W[i] + UINT32_C(0xCA62C1D6);
E = D; D = C; C = rotate(B, 30); B = A; A = TEMP;
}
H[0] += A; H[1] += B; H[2] += C; H[3] += D; H[4] += E;
}
int main(void) {
char block[64] =
"Lorem ipsum dolor sit amet ipsum pariatur." /* 42 バイト */
"\x80"
"\0\0\0\0\0\0\0\0\0\0\0\0\0"
"\0\0\0\0\0\0\x01\x50";
uint32_t H[5] = {
UINT32_C(0x67452301), UINT32_C(0xEFCDAB89), UINT32_C(0x98BADCFE),
UINT32_C(0x10325476), UINT32_C(0xC3D2E1F0)
};
update_sha1_status(H, block);
/*
Lorem ipsum dolor sit amet ipsum pariatur. の SHA-1 ハッシュ値の
3526D1A93C0E6C9A1567217365B8171817619DF3 が出力される
*/
printf("%08" PRIX32 "%08" PRIX32 "%08" PRIX32 "%08" PRIX32 "%08" PRIX32 "\n",
H[0], H[1], H[2], H[3], H[4]);
return 0;
}
x86 の SHA-1 用拡張命令
最近の x86 CPU には、Intel SHA extensions という SHA 系のハッシュ値を求めるのに便利な命令が存在する。
SHA-1 用の命令は、以下の 4 種類が存在する。
| 命令 | 役割 |
|---|---|
| SHA1MSG1 | 状態更新用の配列を求める処理の一部を行う |
| SHA1MSG2 | 状態更新用の配列を求める処理の一部を行う |
| SHA1NEXTE | 4 ラウンド後の変数 E を求める |
| SHA1RNDS4 | 4 ラウンド後の変数 A, B, C, D を求める |
各命令の詳細は、以下のページでも確認できる。
この記事では、64 ビット環境 (x86_64) 用のコードを扱う。
各命令のオペランドと動作
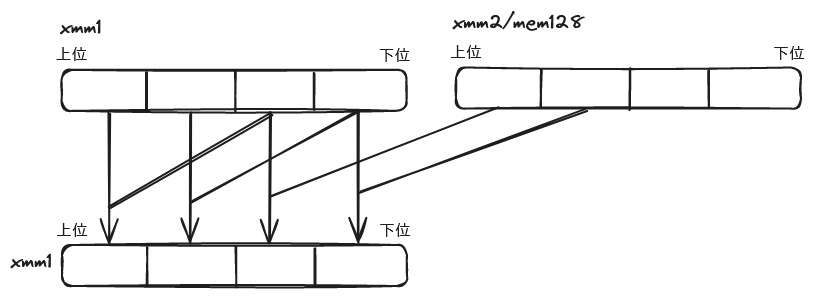
SHA1MSG1
sha1msg1 xmm1, xmm2/m128
第 1 オペランド (デスティネーション) と第 2 オペランド (ソース) の対応する値の XOR を計算し、デスティネーションに格納する。
これは、「ブロックから整数の配列に変換する」処理中の演算 W(k-14) ^ W(k-16) に相当する。
SHA1MSG2
sha1msg2 xmm1, xmm2/m128
第 1 オペランド (デスティネーション) と第 2 オペランド (ソース) の対応する値の XOR を計算し、さらに 1 ビット左ローテートしてデスティネーションに格納する。
これは、「ブロックから整数の配列に変換する」処理中の W(k-3) を XOR して S_1 を適用する処理に相当する。
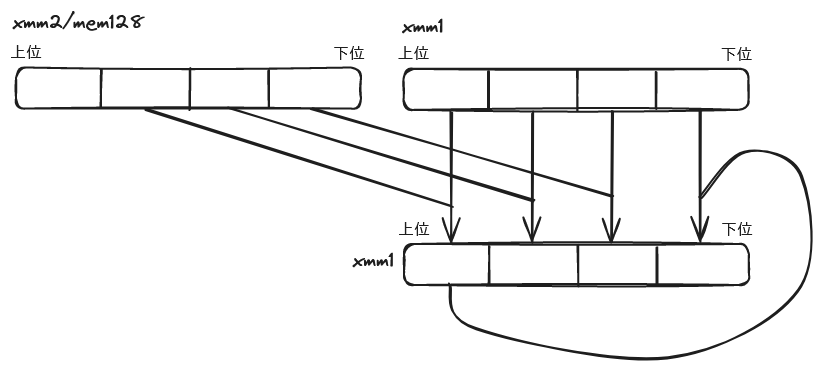
SHA1NEXTE
sha1next2 xmm1, xmm2/m128
第 1 オペランド (デスティネーション) の上位 32 ビットを SHA-1 の計算で用いる変数 A として用い、4 ラウンド後の変数 E を計算する。
前述の通り変数 B, C, D, E については 1 回の処理で変数 A, B, C, D 由来の値が 1 個ずつずれて入るので、4 ラウンド後の変数 E の値は現在の変数 A の値のみから求めることができる。
求めた変数 E を第 2 オペランド (ソース) の上位 32 ビットに加算し、結果をデスティネーションに格納する。
上位 32 ビット以外は、ソースの値がそのままデスティネーションに格納される。
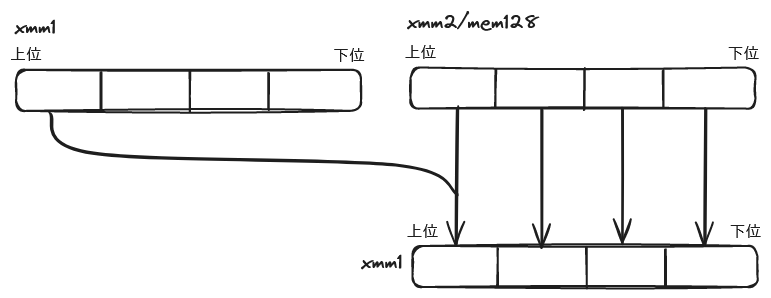
SHA1RNDS4
sha1rnds4 xmm1, xmm2/m128, imm8
第 1 オペランド (デスティネーション) に格納されている変数 A, B, C, D を、4 ラウンド後の値に更新する。
この更新において、配列の値 W(t), W(t+1), W(t+2), W(t+3) を第 2 オペランド (ソース) から取得する。
なお、第 2 オペランドの上位 32 ビットには、あらかじめ変数 E の値を加算しておく必要がある。
第 3 オペランドの即値で、用いる関数 f_t(B,C,D) および定数 K(t) を指定する。
これは以下のように対応する。
| 即値 | t |
|---|---|
| 0 | 0 ~ 19 |
| 1 | 20 ~ 39 |
| 2 | 40 ~ 59 |
| 3 | 60 ~ 79 |
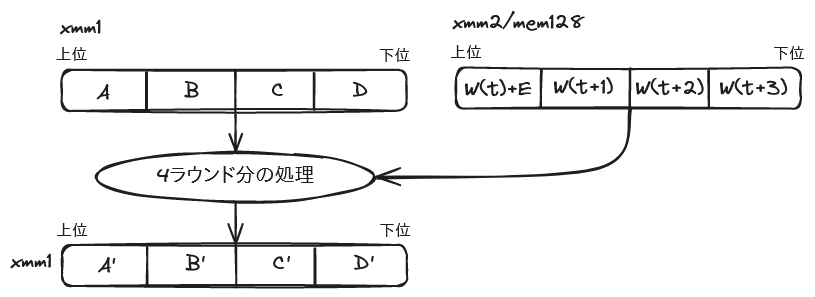
各命令を活用した SHA-1 の求め方
拡張命令の存在を確認する
プログラムを実行中の CPU で Intel SHA extensions の命令が利用できるか否かは、CPUID 命令 を EAX=7, ECX=0 で実行し、結果の EBX レジスタの 29 ビット目が 1 であるかどうかで判定できる。
#include <stdio.h>
/* Intel SHA extensions が利用可能なら 1、利用不可能なら 0 を返す */
int is_sha_extension_available(void) {
int ret;
/* EAX=7 に対応しているかをチェックする */
__asm__ __volatile__(
"xor %%eax, %%eax\n\t"
"cpuid\n\t"
: "=a"(ret) : : "%ebx", "%ecx", "%edx");
if (ret < 7) return 0;
/* sha フラグをチェックする */
__asm__ __volatile__(
"mov $7, %%eax\n\t"
"xor %%ecx, %%ecx\n\t"
"cpuid\n\t"
: "=b"(ret) : : "%eax", "%ecx", "%edx");
return (ret >> 29) & 1;
}
int main(void) {
printf("%d\n", is_sha_extension_available());
return 0;
}
また、この記事では Intel SHA extensions の命令に加え、以下の命令も使用する。
| 命令の種類 | 命令 |
|---|---|
| SSE2 | MOVDQU など |
| SSSE3 | PSHUFB |
| SSE4.1 | PEXTRD |
これらの命令が利用可能かは、CPUID 命令を EAX=1 で実行し、以下のビットが 1 であるかどうかで判定できる。
| 命令の種類 | 結果のレジスタ | 結果のビット |
|---|---|---|
| SSE2 | EDX |
26 |
| SSSE3 | ECX |
9 |
| SSE4.1 | ECX |
19 |
これらの判定処理を追加すると、以下のようになる。
#include <stdio.h>
/* 用いる拡張命令が利用可能なら 1、利用不可能なら 0 を返す */
int is_extensions_available(void) {
int ret, ret2;
/* EAX=7 に対応しているかをチェックする */
__asm__ __volatile__(
"xor %%eax, %%eax\n\t"
"cpuid\n\t"
: "=a"(ret) : : "%ebx", "%ecx", "%edx");
if (ret < 7) return 0;
/* 各種 SSE をチェックする */
__asm__ __volatile__(
"mov $1, %%eax\n\t"
"cpuid\n\t"
: "=d"(ret), "=c"(ret2) : : "%eax", "%ebx");
if (!((ret >> 26) & 1)) return 0; /* sse2 */
if (!((ret2 >> 9) & 1)) return 0; /* ssse3 */
if (!((ret2 >> 19) & 1)) return 0; /* sse4.1 */
/* sha フラグをチェックする */
__asm__ __volatile__(
"mov $7, %%eax\n\t"
"xor %%ecx, %%ecx\n\t"
"cpuid\n\t"
: "=b"(ret) : : "%eax", "%ecx", "%edx");
return (ret >> 29) & 1;
}
int main(void) {
printf("%d\n", is_extensions_available());
return 0;
}
ブロックから整数の配列に変換する (値の取得)
まず、64 バイトのブロック (バイト列) から配列の値 W(0) ~ W(15) を取得したい。
それぞれの配列の値は 32 ビットのビッグエンディアンである。
また、小さい添字の要素ほど xmm レジスタの上位に格納しておくと、拡張命令を用いた操作がうまくいく。
x86 系の CPU はリトルエンディアンで値を扱うので、MOVDQU などの単純なロードだけでは、このような値の取得を行うことはできない。
MOVDQU 命令を用いてバイト列を xmm レジスタにロードすると、「リトルエンディアンで、小さい添字の要素ほど xmm レジスタの下位に格納されている」状態になる。
このバイト列を PSHUFB 命令を用いて反転させることで、「ビッグエンディアンで、小さい添字の要素ほど xmm レジスタの上位に格納されている」状態を作ることができる。
以下のようにすることで、PSHUFB 命令を用いてバイト列の反転を行うことができる。
bits 64
section .text
global reverse_test
reverse_test:
movdqu xmm0, [rdi]
pshufb xmm0, [reverse_arg]
movdqu [rdi], xmm0
ret
section .rodata
align 16
reverse_arg:
db 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0
PSHUFB 命令のオペランドとしてメモリを用いる場合は、16 バイト単位にアライメントされていなければならない。
このような形で .rodata セクションにデータを配置すると、一部の再配置形式に対応できず、GCC を用いたリンク時に -static オプションをつけることが要求される。
バイトの順序を表すデータをスタック上に動的に用意することで、命令数は増えるがこれを回避できる。
bits 64
section .text
global reverse_test
reverse_test:
mov rax, 0x0001020304050607
push rax
mov rax, 0x08090a0b0c0d0e0f
push rax
movdqu xmm1, [rsp]
movdqu xmm0, [rdi]
pshufb xmm0, xmm1
movdqu [rdi], xmm0
add rsp, 16
ret
スタックを経由せず、MOVQ 命令と PUNPCKLQDQ 命令でバイトの順序を表すデータを構築してもよい。
PUNPCKLQDQ 命令は、ソースの下位 64 ビットをデスティネーションの上位 64 ビットに設定する命令である。
bits 64
section .text
global reverse_test
reverse_test:
mov rax, 0x0001020304050607
movq xmm2, rax
mov rax, 0x08090a0b0c0d0e0f
movq xmm1, rax
punpcklqdq xmm1, xmm2
movdqu xmm0, [rdi]
pshufb xmm0, xmm1
movdqu [rdi], xmm0
ret
以下のプログラムを用いて、これらのサンプルの動作を確認できる。
#include <stdio.h>
void reverse_test(void* p);
int main(void) {
char a[17] = "hello_world_meow";
puts(a);
reverse_test(a);
puts(a);
return 0;
}
アセンブリ言語のソースコードは、NASM を用いて
nasm -f elf64 source.asm
のようにしてアセンブルを行う。(-f オプションで出力形式を設定する)
以下の出力が得られるはずである。
hello_world_meow
woem_dlrow_olleh
ブロックから整数の配列に変換する (値の拡張)
W(0) ~ W(15) の値をメモリから取得したら、次にこれらの値から W(16) ~ W(79) の値を計算したい。
これらの値の計算を、4 ワード (ここでは 32 ビット符号なし整数を「ワード」という) ずつまとめて行う。
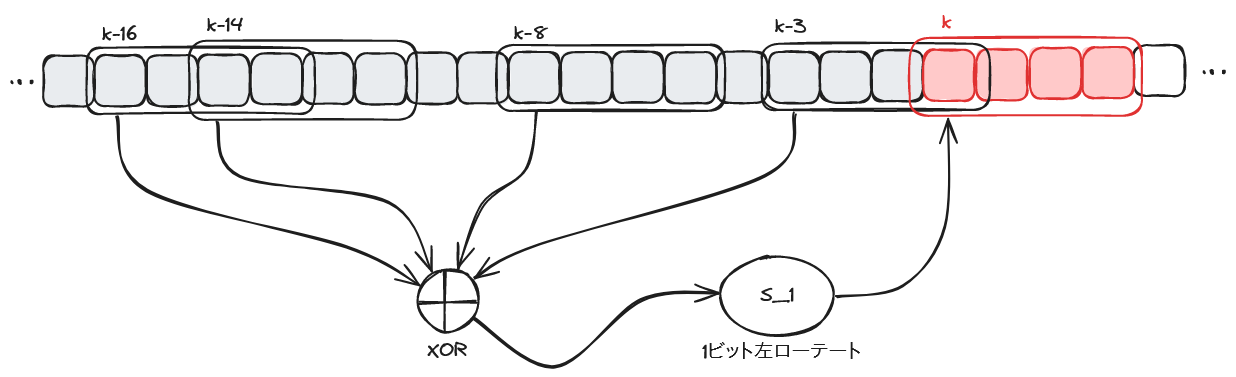
計算は、以下の手順で行うことができる。
-
W(k-16)からの 4 ワードとW(k-14)からの 4 ワードの XOR を計算する - この結果と、
W(k-8)からの 4 ワードの XOR を計算する - この結果と、
W(k-3)からの 4 ワードの XOR を 1 ビット左ローテートした値を計算する
これらの計算は、それぞれ以下の命令で行うことができる。
- SHA1MSG1 命令
-
PXOR 命令 (
xmmレジスタ同士、またはxmmレジスタとメモリの XOR 演算を行う) - SHA1MSG2 命令
例として、各ワードが以下のレジスタに格納されている、もしくは格納するとする。
| ワード | レジスタ |
|---|---|
W(k-16) ~ W(k-13)
|
xmm0 |
W(k-12) ~ W(k-9)
|
xmm1 |
W(k-8) ~ W(k-5)
|
xmm2 |
W(k-4) ~ W(k-1)
|
xmm3 |
W(k) ~ W(k+3)
|
xmm4 |
このとき、W(k) ~ W(k+3) を求める処理は以下のようになる。
movdqa xmm4, xmm0
sha1msg1 xmm4, xmm1
pxor xmm4, xmm2
sha1msg2 xmm4, xmm3
この例では W(k-16) ~ W(k-13) の値 xmm0 を xmm4 にコピーしてから計算を行ったが、この値が不要であればコピーを行わず xmm0 に上書きする形で計算を行ってもよい。
更新するために状態を取得する
拡張命令を用いて状態の更新を行うには、変数 A, B, C, D をこの順に xmm レジスタの上位から格納することが要求される。
これは、このような順番で格納すると定めてしまえば、MOVDQU 命令などで素直にロードできる。
しかし、今回の実装例では、変数 A, B, C, D (に対応する状態 H0, H1, H2, H3) はこの順番でメモリに格納されており、このまま MOVDQU 命令を用いると変数 A が xmm レジスタの下位に格納されてしまう。
このとき、PSHUFD 命令を用いると、xmm レジスタ内のワードを並べ替え、変数 A を上位に移動することができる。
; xmm0 に格納されているワードを逆順に並べ替える
pshufd xmm0, xmm0, 0x1b
変数 E (状態 H4) は、xmm レジスタの上位 32 ビットに格納したい。
これは、MOVD 命令 で xmm レジスタの下位 32 ビットに格納 (それ以外のビットはゼロクリアされる) した後、同様に PSHUFD 命令でワードを並べ替えることで実現できる。
変数の更新を行う
SHA1RNDS4 命令を用いると、上位から順に変数 A, B, C, D が格納された xmm レジスタを、4 ラウンド先に更新できる。
このとき、ソースとして配列の値を上位から順に格納し、さらに上位 32 ビットに変数 E の値を加算した xmm レジスタを用いる。
この「上位 32 ビットに変数 E の値を加算」という操作には、SHA1NEXTE 命令を用いることができる。
SHA1NEXTE 命令は、デスティネーションとして変数 A を含む xmm レジスタ、ソースとして加算を行う元の xmm レジスタ (またはメモリ) をとり、加算結果をデスティネーションに格納する。
よって、まず変数 A を含む xmm レジスタをコピーし、そこに SHA1NEXTE 命令を用いて加算を行うのがよいだろう。
最初に取得した変数 E (状態 H4) は、PADDD 命令を用いて加算できる。
更新操作の最初の部分は、以下のようにできる。
; それぞれ上位から
; xmm0 : A, B, C, D
; xmm1 : E, 0, 0, 0
; xmm2 : W(0), W(1), W(2), W(3)
; xmm3 : W(4), W(5), W(6), W(7)
; xmm4 : W(8), W(9), W(10), W(11)
; が格納されているとする
; 配列の最初の部分に最初の E の値を加算する
movdqa xmm5, xmm2
paddd xmm5, xmm1
; 配列をコピーし、最初の 4 ラウンドの計算を実行後の E の値を加算する
movdqa xmm6, xmm0
sha1nexte xmm6, xmm3
; 変数 A, B, C, D を 4 ラウンド進める
sha1rnds4 xmm0, xmm5, 0
; 配列をコピーし、次の 4 ラウンドの計算を実行後の E の値を加算する
movdqa xmm5, xmm0
sha1nexte xmm5, xmm4
; 変数 A, B, C, D を 4 ラウンド進める
sha1rnds4 xmm0, xmm6, 0
最後のラウンドでは、配列をコピーして変数 E の値を加算するかわりに、ゼロクリアした xmm レジスタに加算することで、最終的な変数 E の値を取得できる。
xmm レジスタのゼロクリアは、PXOR 命令 で同じレジスタの XOR を計算することで行うことができる。
状態の更新を行う
t = 0, ... , 79 の処理を行った後の変数 A, B, C, D がある xmm レジスタの上位から順に格納され、変数 E が別の xmm レジスタの上位 32 ビットに格納されているとする。
これらの値を状態 H0, H1, H2, H3, H4 に加算し、状態の更新を行いたい。
変数 A, B, C, D の状態 H0, H1, H2, H3 への加算は、PADDD 命令で行うことができる。
状態の順番が変数の順番と合わない場合は、事前に (xmm レジスタ内の) 変数を PSHUFD 命令で並べ替えればよい。
変数 E は、値を PEXTRD 命令 で通常のレジスタに取り出し、通常の ADD 命令 で加算すればよい。
実装例
前述のC言語での実装の関数
void update_sha1_status(uint32_t H[5], const void* block)
を置き換える実装の例を以下に示す。
この実装では、xmm0, xmm1, xmm2, xmm3 をリングバッファのように用い、配列の値を生成・格納していく。
さらに、今回変数 A, B, C, D を更新するために用いる「配列の値に E を加算したデータ」を保持したまま次の更新に用いる「配列の値に E を加算したデータ」を計算・格納するため、xmm5 および xmm6 を交互に用いている。
最後の更新では、次の配列の値の生成は行わず、かわりに E を加算する対象をゼロにして E の値が単独で得られるようにする。
bits 64
section .text
; xmm0, xmm1, xmm2, xmm3 : 配列 W(x)
; xmm4 : 変数 A, B, C, D
; xmm5, xmm6 : 配列の値に変数 E を足した結果
; generate_next_words 一番古い/更新対象, 2番目に古い, 3番目に古い, 4番目に古い
%macro generate_next_words 4
sha1msg1 %1, %2
pxor %1, %3
sha1msg2 %1, %4
%endmacro
; advance_round 次に足す(入力), 前に足した(入力), 次に足した(出力), 演算の種類
%macro advance_round 4
movdqa %3, xmm4
sha1nexte %3, %1
sha1rnds4 xmm4, %2, %4
%endmacro
global update_sha1_status
update_sha1_status:
%ifidn __?OUTPUT_FORMAT?__, win64
; Windows 環境なので、xmm6 を保存する
sub rsp, 16
movdqu [rsp], xmm6
%else
; 第 1 引数を rcx に、第 2 引数を rdx に格納する
mov rcx, rdi
mov rdx, rsi
%endif
; ブロックをロードする
movdqu xmm0, [rdx]
movdqu xmm1, [rdx + 16]
movdqu xmm2, [rdx + 32]
movdqu xmm3, [rdx + 48]
mov rax, 0x0001020304050607
movq xmm5, rax
mov rax, 0x08090a0b0c0d0e0f
movq xmm4, rax
punpcklqdq xmm4, xmm5
pshufb xmm0, xmm4
pshufb xmm1, xmm4
pshufb xmm2, xmm4
pshufb xmm3, xmm4
; 状態をロードする
movdqu xmm4, [rcx]
movd xmm5, [rcx + 16]
pshufd xmm4, xmm4, 0x1b
pshufd xmm5, xmm5, 0x1b
; 最初の E を配列に加算する
paddd xmm5, xmm0
; t = 0, 1, 2, 3
advance_round xmm1, xmm5, xmm6, 0
generate_next_words xmm0, xmm1, xmm2, xmm3
; t = 4, 5, 6, 7
advance_round xmm2, xmm6, xmm5, 0
generate_next_words xmm1, xmm2, xmm3, xmm0
; t = 8, 9, 10, 11
advance_round xmm3, xmm5, xmm6, 0
generate_next_words xmm2, xmm3, xmm0, xmm1
; t = 12, 13, 14, 15
advance_round xmm0, xmm6, xmm5, 0
generate_next_words xmm3, xmm0, xmm1, xmm2
; t = 16, 17, 18, 19
advance_round xmm1, xmm5, xmm6, 0
generate_next_words xmm0, xmm1, xmm2, xmm3
; t = 20, 21, 22, 23
advance_round xmm2, xmm6, xmm5, 1
generate_next_words xmm1, xmm2, xmm3, xmm0
; t = 24, 25, 26, 27
advance_round xmm3, xmm5, xmm6, 1
generate_next_words xmm2, xmm3, xmm0, xmm1
; t = 28, 29, 30, 31
advance_round xmm0, xmm6, xmm5, 1
generate_next_words xmm3, xmm0, xmm1, xmm2
; t = 32, 33, 34, 35
advance_round xmm1, xmm5, xmm6, 1
generate_next_words xmm0, xmm1, xmm2, xmm3
; t = 36, 37, 38, 39
advance_round xmm2, xmm6, xmm5, 1
generate_next_words xmm1, xmm2, xmm3, xmm0
; t = 40, 41, 42, 43
advance_round xmm3, xmm5, xmm6, 2
generate_next_words xmm2, xmm3, xmm0, xmm1
; t = 44, 45, 46, 47
advance_round xmm0, xmm6, xmm5, 2
generate_next_words xmm3, xmm0, xmm1, xmm2
; t = 48, 49, 50, 51
advance_round xmm1, xmm5, xmm6, 2
generate_next_words xmm0, xmm1, xmm2, xmm3
; t = 52, 53, 54, 55
advance_round xmm2, xmm6, xmm5, 2
generate_next_words xmm1, xmm2, xmm3, xmm0
; t = 56, 57, 58, 59
advance_round xmm3, xmm5, xmm6, 2
generate_next_words xmm2, xmm3, xmm0, xmm1
; t = 60, 61, 62, 63
advance_round xmm0, xmm6, xmm5, 3
generate_next_words xmm3, xmm0, xmm1, xmm2
; t = 64, 65, 66, 67
advance_round xmm1, xmm5, xmm6, 3
generate_next_words xmm0, xmm1, xmm2, xmm3
; t = 68, 69, 70, 71
advance_round xmm2, xmm6, xmm5, 3
generate_next_words xmm1, xmm2, xmm3, xmm0
; t = 72, 73, 74, 75
advance_round xmm3, xmm5, xmm6, 3
generate_next_words xmm2, xmm3, xmm0, xmm1
; t = 76, 77, 78, 79
pxor xmm0, xmm0
advance_round xmm0, xmm6, xmm5, 3
; 状態を更新する
pshufd xmm4, xmm4, 0x1b
paddd xmm4, [rcx]
movdqu [rcx], xmm4
pextrd eax, xmm5, 3
add [rcx + 16], eax
%ifidn __?OUTPUT_FORMAT?__, win64
; Windows 環境なので、xmm6 を復元する
movdqu xmm6, [rsp]
add rsp, 16
%endif
ret
Windows では、第 1 引数は rcx に、第 2 引数は rdx に格納し、xmm6 レジスタ (以降の xmm レジスタ) は保存する必要がある。
(x64 ABI conventions | Microsoft Learn)
Linux では、第 1 引数は rdi、第 2 引数は rsi に格納し、xmm6 レジスタ (を含む xmm レジスタ) を保存する必要はない。
(Notes on x86-64 programming)
おわりに
x86 の SHA-1 を計算する用の拡張命令群は、一見すると処理内容が複雑で使い方がわかりにくいが、しっかり考えてみると他の命令を少し挟むだけで効率よく SHA-1 が計算できるようにできていることがわかった。