ETL処理の中でデータをDB(Table)へ出力することはよくあるかと思いますので、PDIでの設定方法をまとめました。
使用するのはテーブル出力ステップです。
テーブルからデータを抽出する際はこちらの記事をご参照ください。
出力先のTableを確認する
以下のようなTableを作成しておきます。
今回はPostgreSQL上に、etlというDBを構築し、そこにsampleというテーブルを作成しています。
etl=# \d sample
テーブル"public.sample"
列 | タイプ | 照合順序 | Null 値を許容 | デフォルト
-----+--------------+----------+---------------+------------
key | character(3) | | |
var | integer | | |
中身は空っぽです。
etl=# select * from sample;
key | var
-----+-----
(0 行)
テーブル出力までのETL上の処理を作成する
Tableへ出力するためのテストデータを作成し、Tableへ出力するところまでの流れを作成します。
テストデータをETL上で作成するにはデータグリッドを使用しますが、このあたりの設定方法は、こちらをご参照ください。
ここでは、上記参照ページで作成した処理にテーブル出力処理を追加する形にしたいと思いますので、以下のようにテーブル出力ステップを配置して、データグリッドステップとつなげます。
【補足】
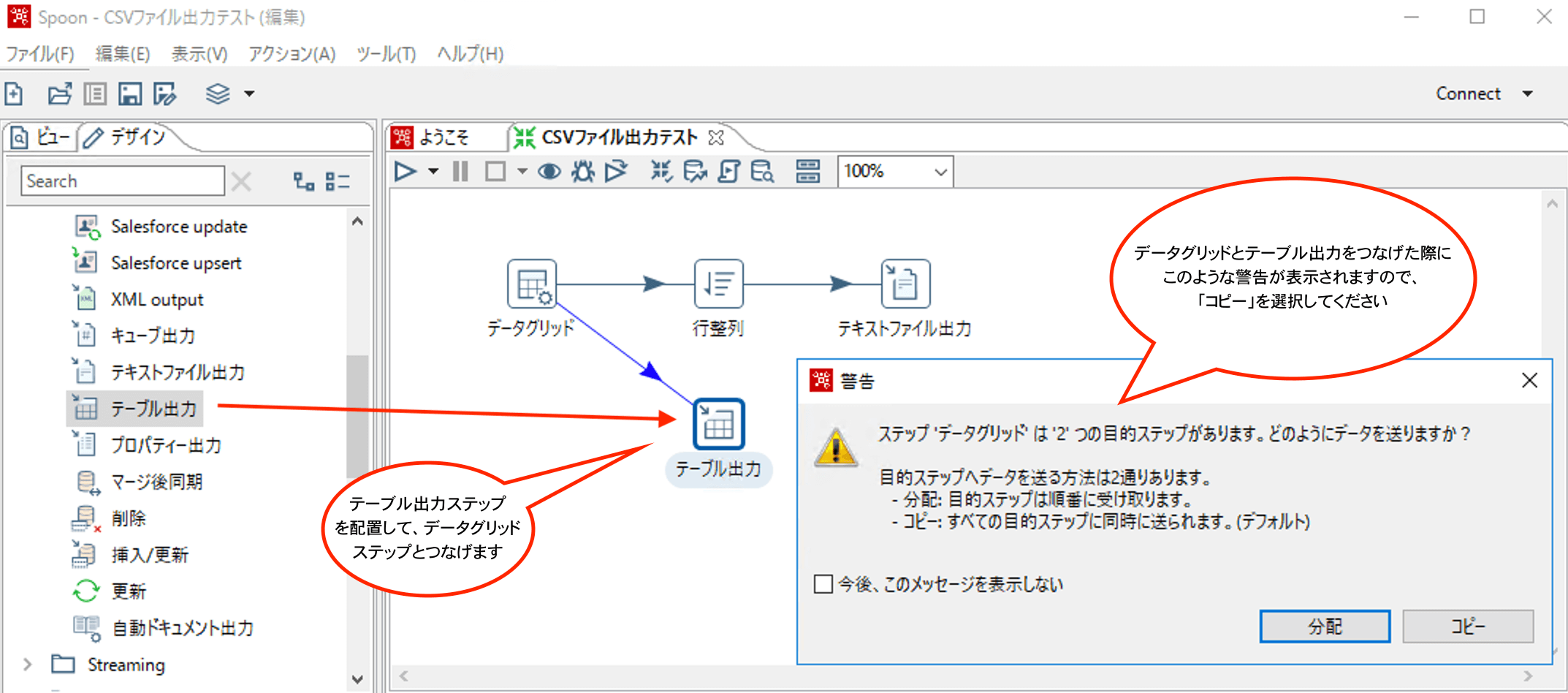
ステップ間をホップでつないだ際に、上のような警告が表示されることがあります。
これは、一つのステップから複数のホップが設定されている場合に発生します。
この警告が何を伝えているのかというと、「出力先が複数あるけどデータの渡し方はどうしますか?」ということになります。
つまり、上の例でいうと、データグリッドステップで作成している3行のデータを行整列とテーブル出力へどのように渡していくか?ということです。
分配は、後続のステップへ順番に渡すことになりますので、まず行整列に1行渡して、次にテーブル出力に1行渡して、次はまた行整列に渡す、、のような動作となります。
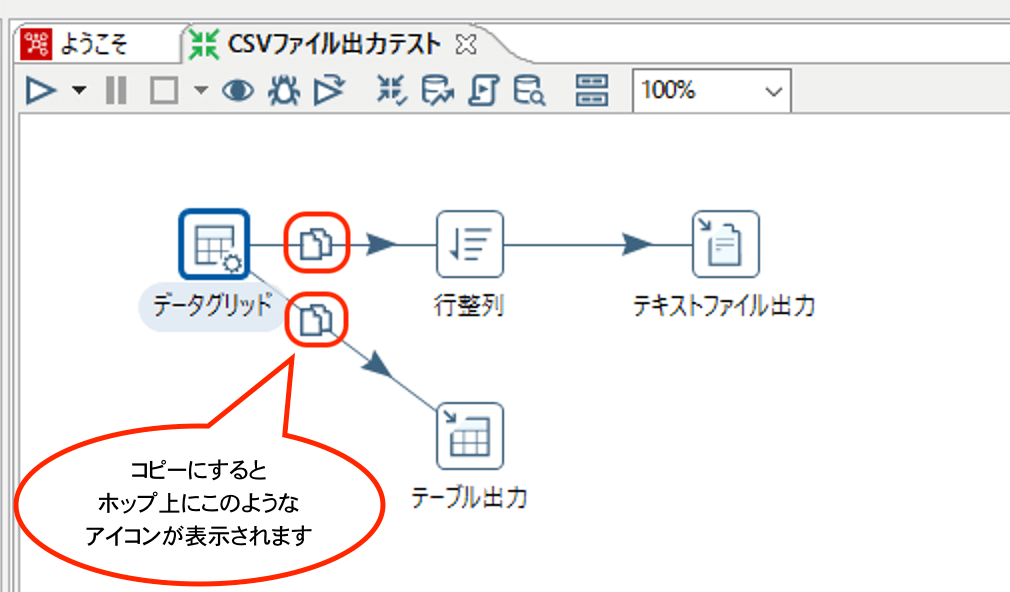
コピーは、後続のステップへ同じデータをすべてわたすことになるので、データグリッドステップで作成している3行のデータは、行整列とテーブル出力のどちらにも渡されることになります。
基本的に、分配を使用することはほぼないので、コピーを使用することになるかと思います。
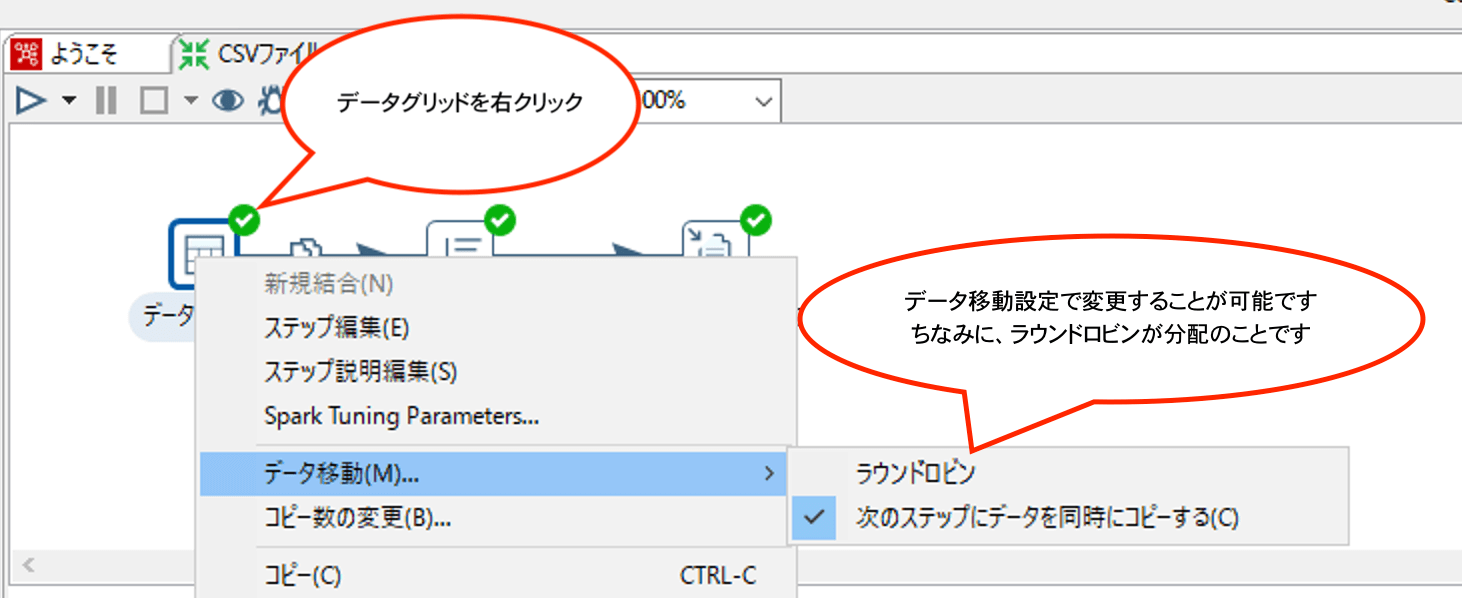
なお、配分とコピーの設定は、元ステップのアイコンを右クリックして出てくるメニュー内のデータ移動設定で変更が可能です。
テーブル出力の設定を行う
テーブル出力ステップの配置まで終わりましたので、テーブル出力ステップのアイコンをダブルクリックして設定画面を表示し、設定を行っていきます。
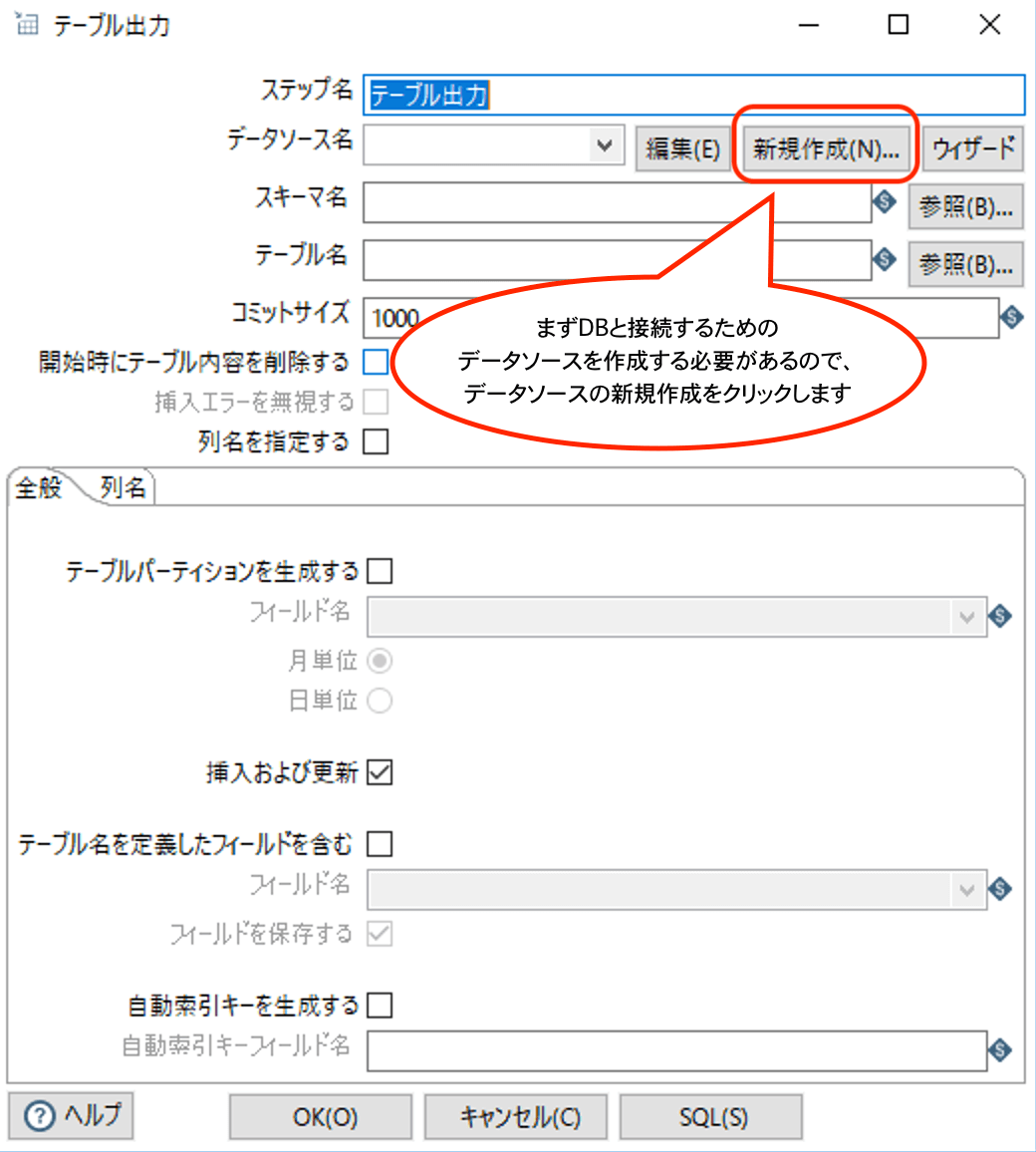
上のようにテーブル出力の設定画面が表示されたら、まずはDBと接続するためのデータソースの設定を行う必要があるので、新規作成ボタンを押下して、データソースを作成します。
なお、ここで作成するデータソースは同じTransformation内で共有されているので、テーブル出力ステップを新規に配置すると、先程作成したデータソースが選択できるようになっています。
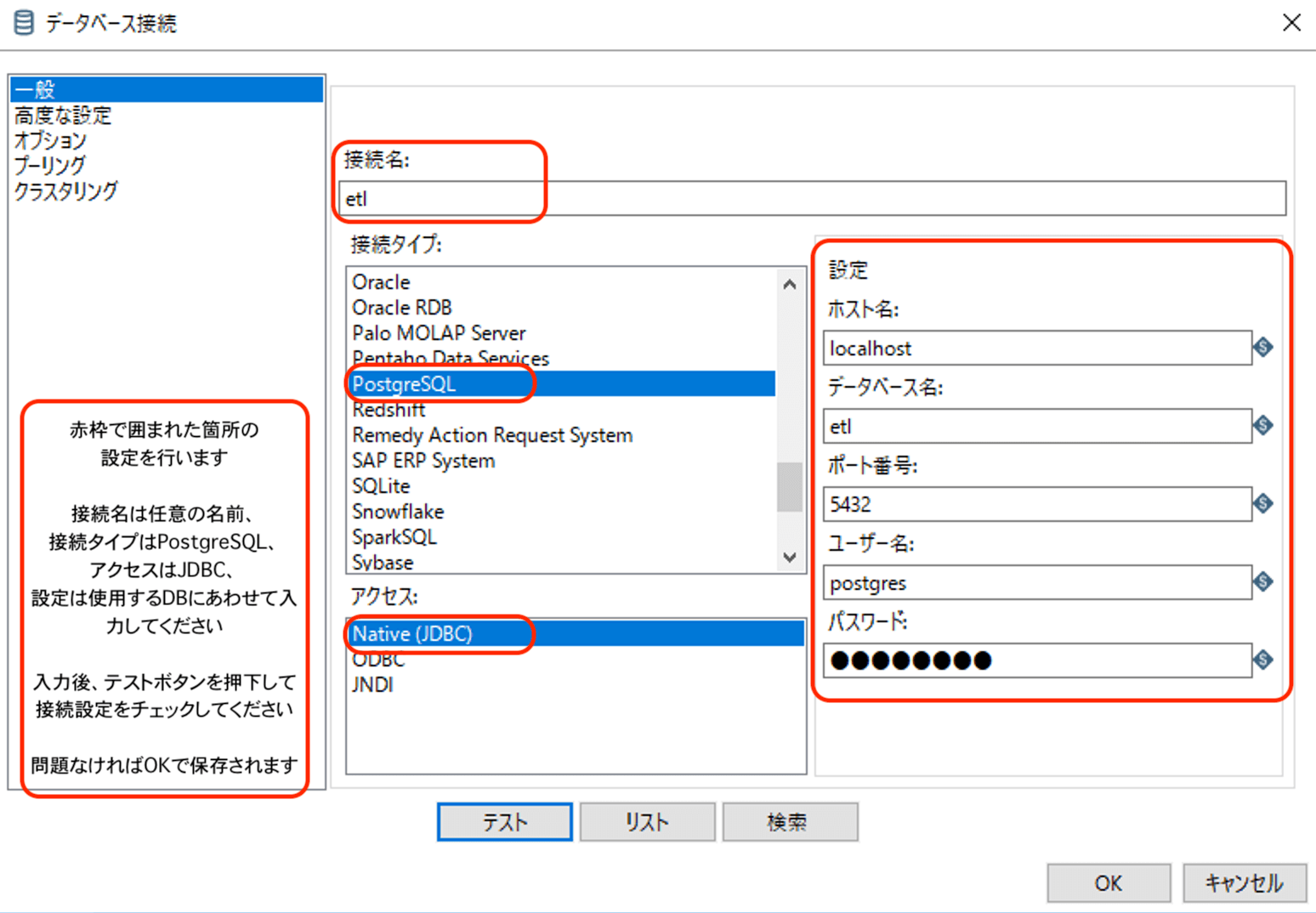
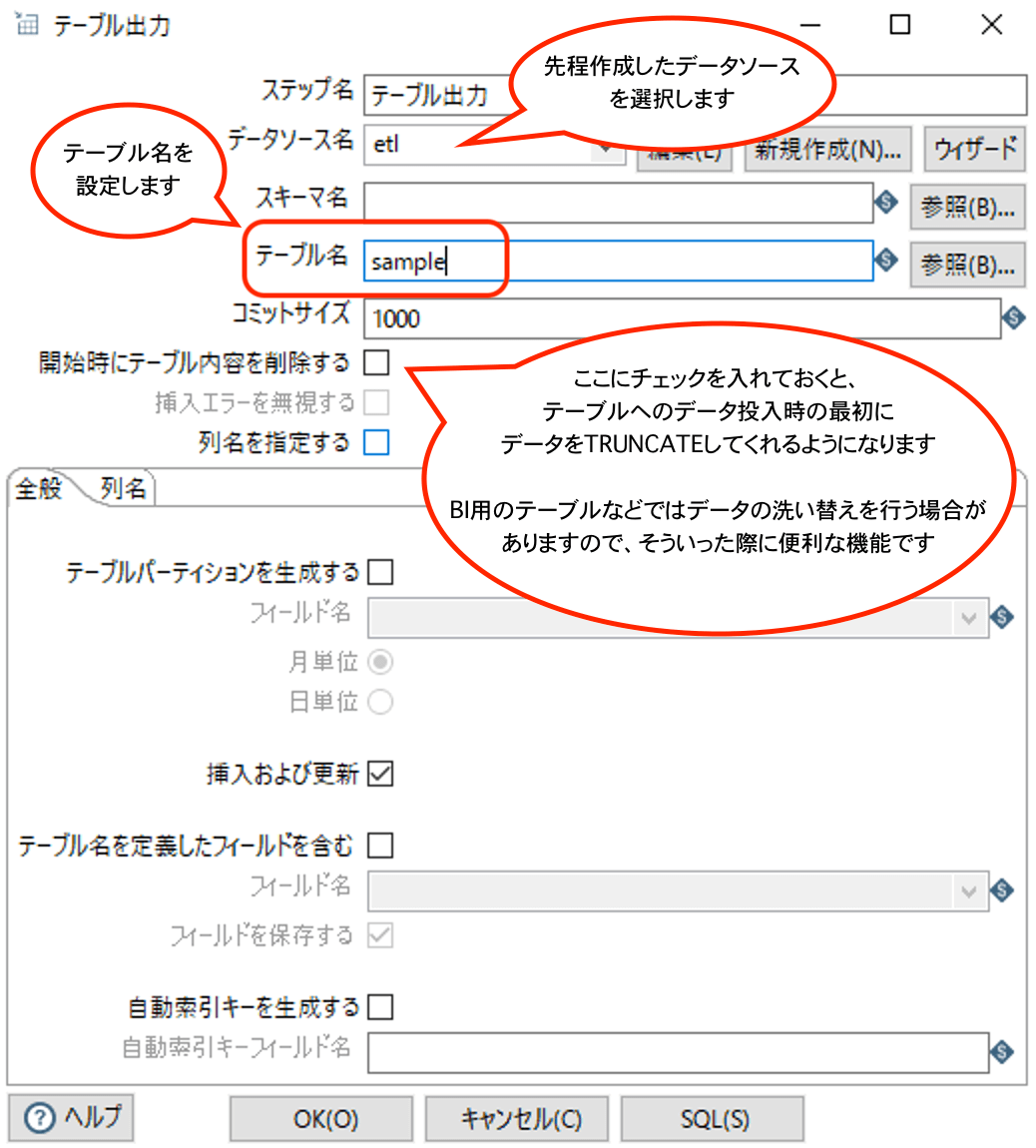
データソースを保存してテーブル出力の設定画面に戻ってきたら、テーブル名を設定して、OKボタンを押下して完了です。
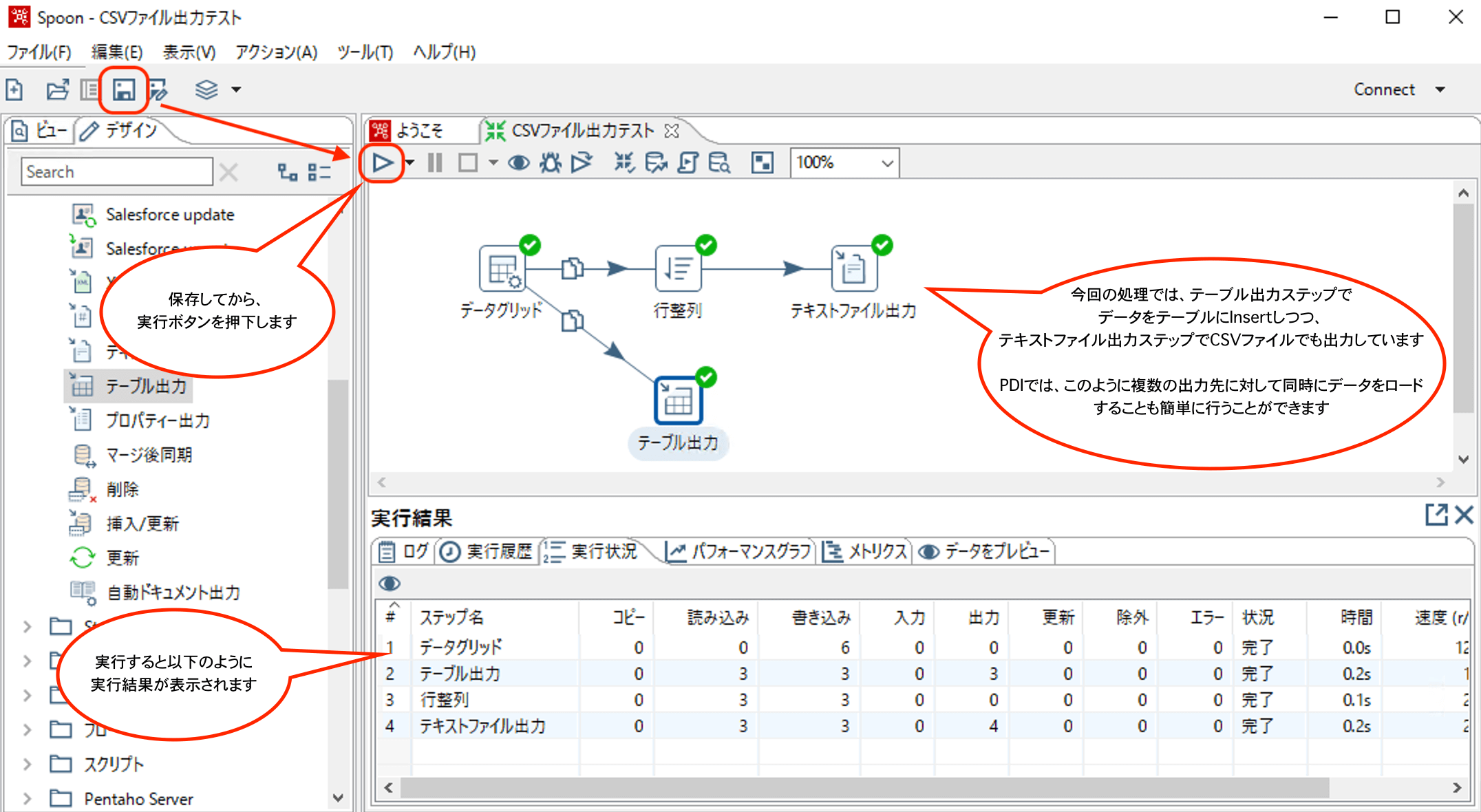
実行と確認
実行ボタンを押下してETL処理を実行します。
以下のようにエラーなく実行できていればOKです。
sampleテーブルにデータが投入されていることが確認できます。
etl=# select * from sample;
key | var
-----+------
aaa | 100
bbb | 10
ccc | 1000
(3 行)
列名を指定してテーブルにデータを出力する
上記の例では、テーブル出力のInputデータと出力先のテーブルのカラムが同じ名前で、且つ、同じ数であったので比較的簡単な設定でOKでした。
つまり、Inputデータ側がkeyとvar、テーブル側もkeyとvarだったので、PDI側が勝手に紐付けてInsertしてくれていました。
しかし、実際の運用を考えた場合、Input側ではデータ加工を行った際にさまざまなデータが追加されており、これらのデータはテーブルへのInsertを行う必要がない場合もあると思います。
その場合は「列名を指定してテーブルにデータを出力する」という設定が必要になります。
例えば、以下のように定数を追加してInput側の列とTable側の列をずれた状態にしてみます。
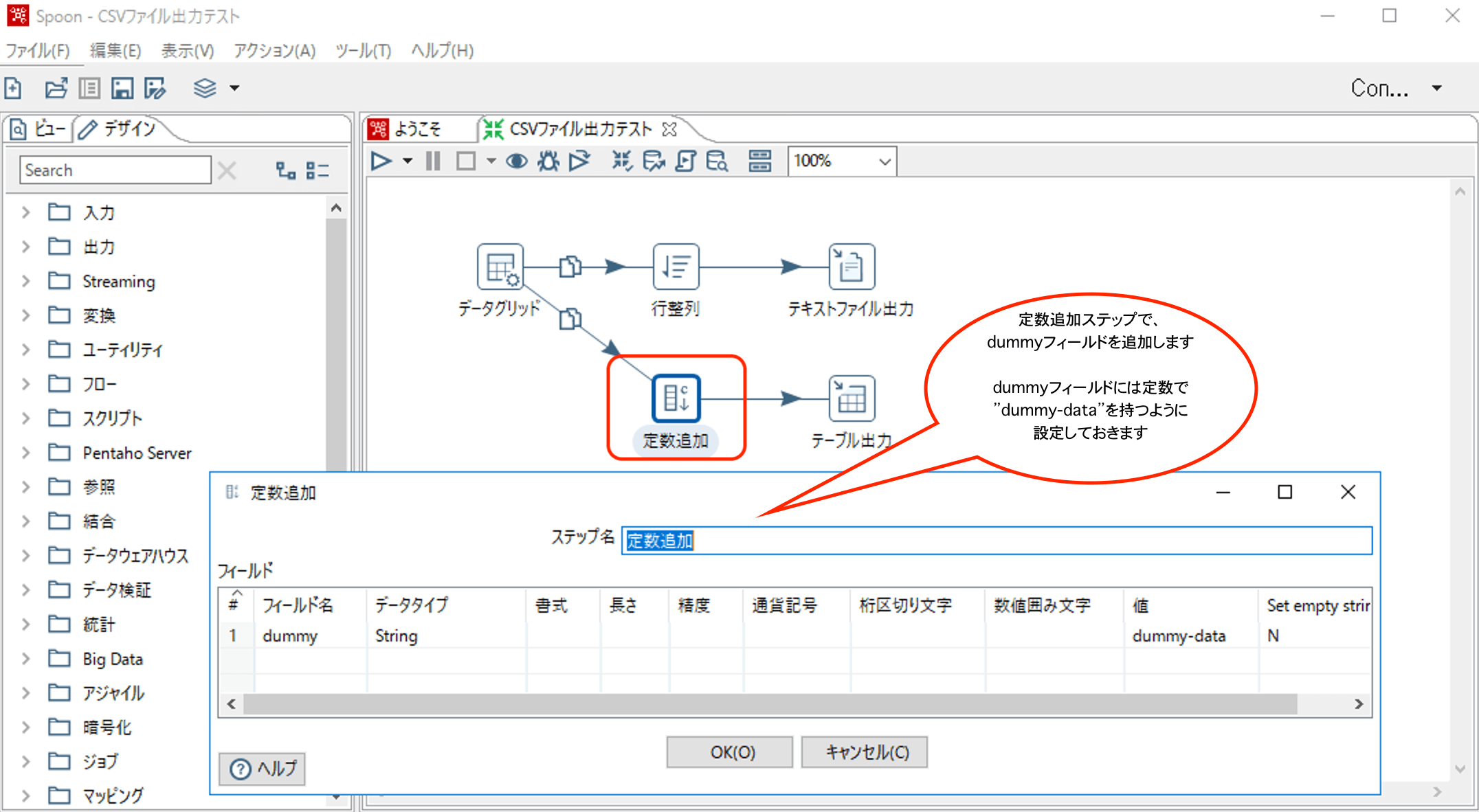
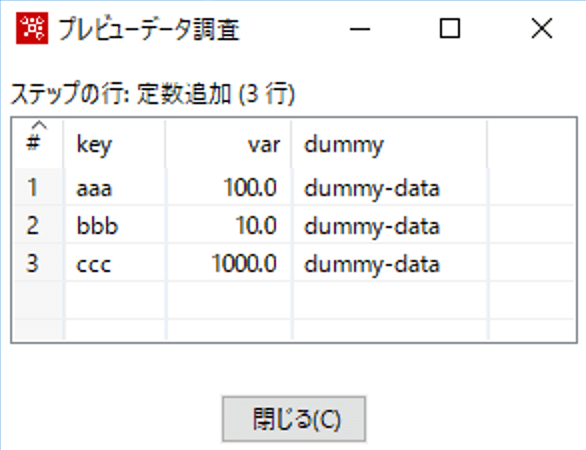
定数追加ステップでプレビューすると以下のようになりますので、Input側はkey,var,dummyの3列、Output側は変わらずsampletテーブルのkey,varの2列となり、ミスマッチがおこります。
この状態のまま、実行すると以下のようにエラーとなります。
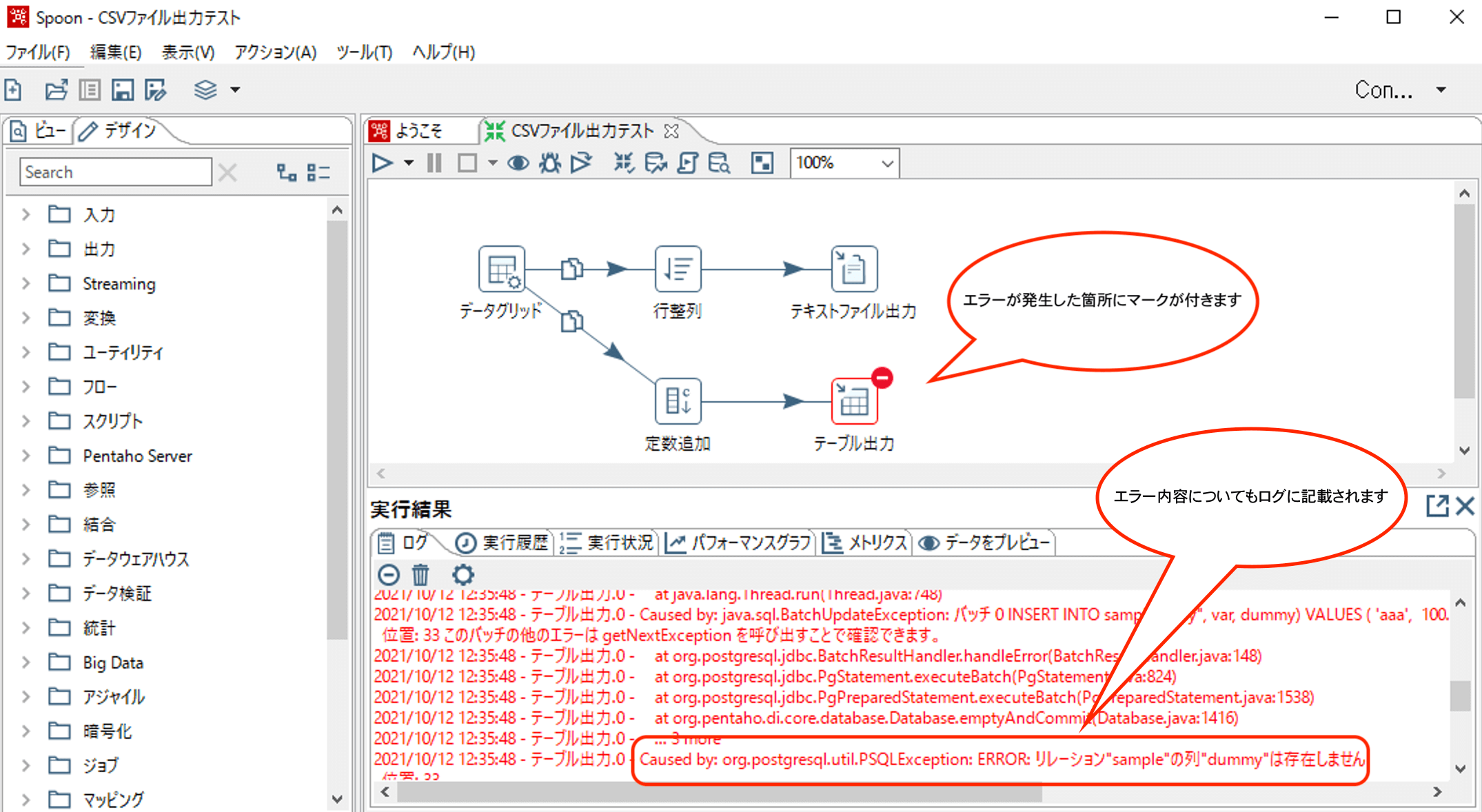
このエラーを回避するために、列名を指定する設定を行います。
テーブル出力ステップをダブルクリックして、設定画面を表示し、以下のように設定を行います。
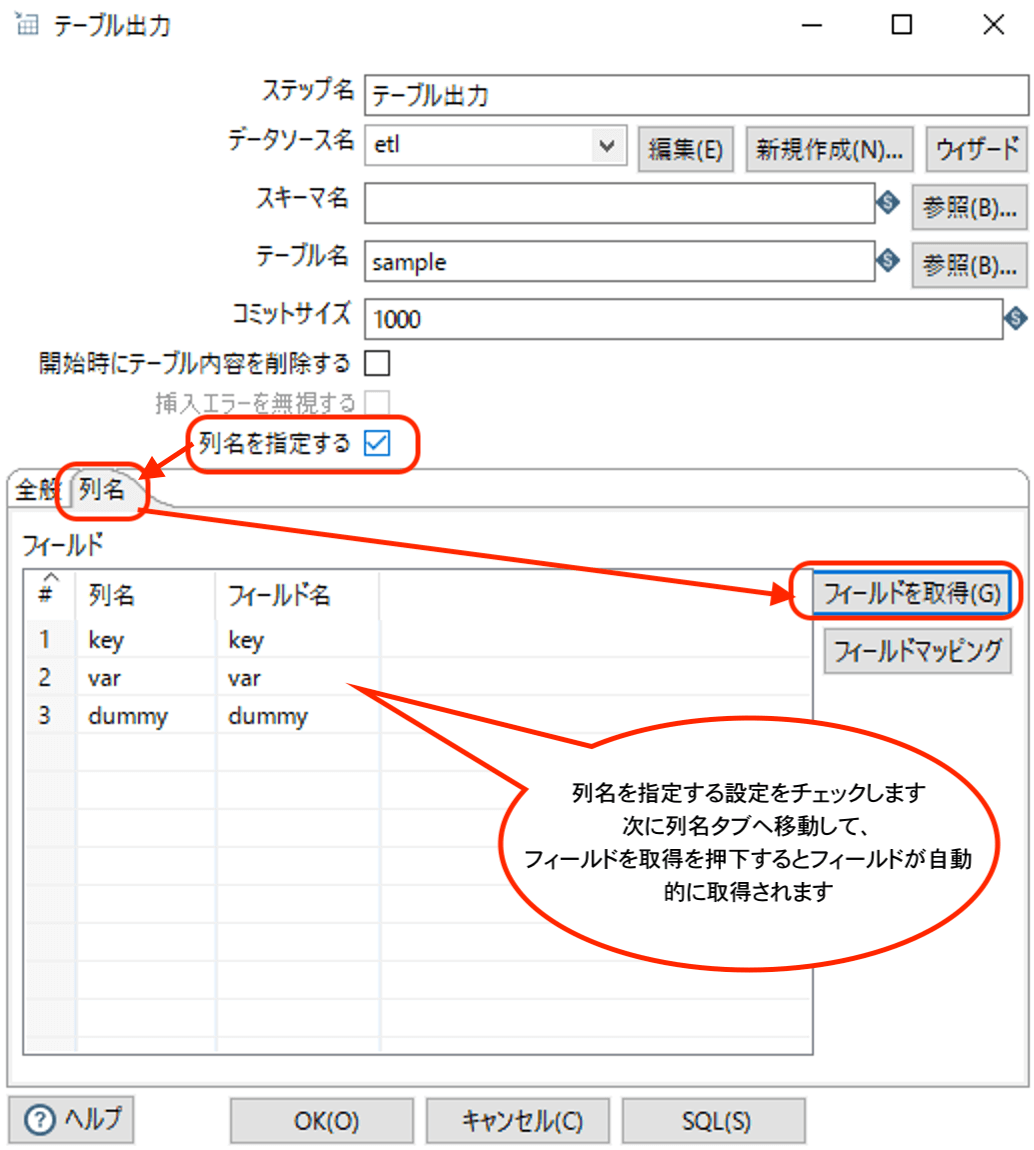
続いて、dummy列の設定は必要なので削除します。
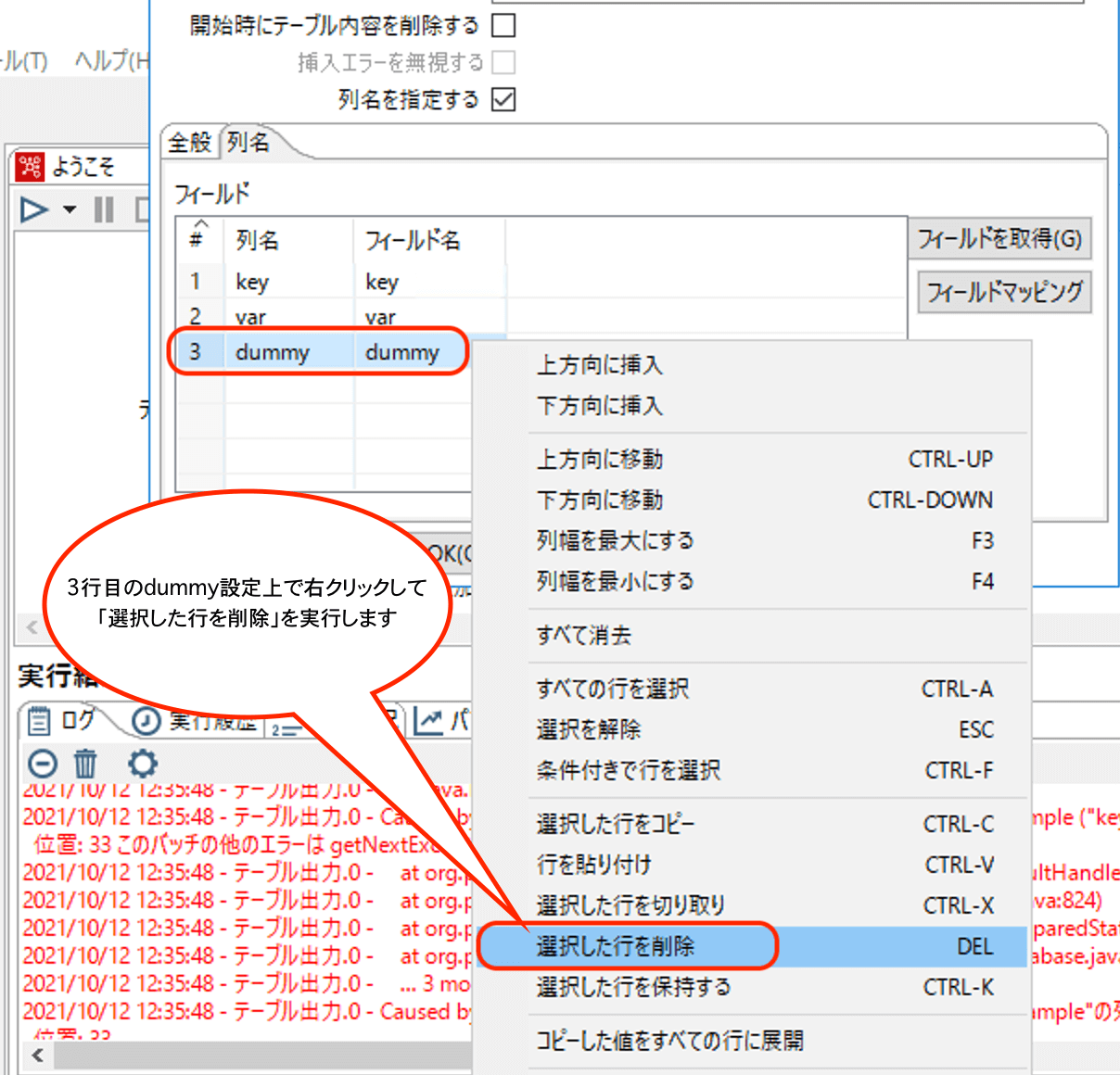
結果として以下のようになります。
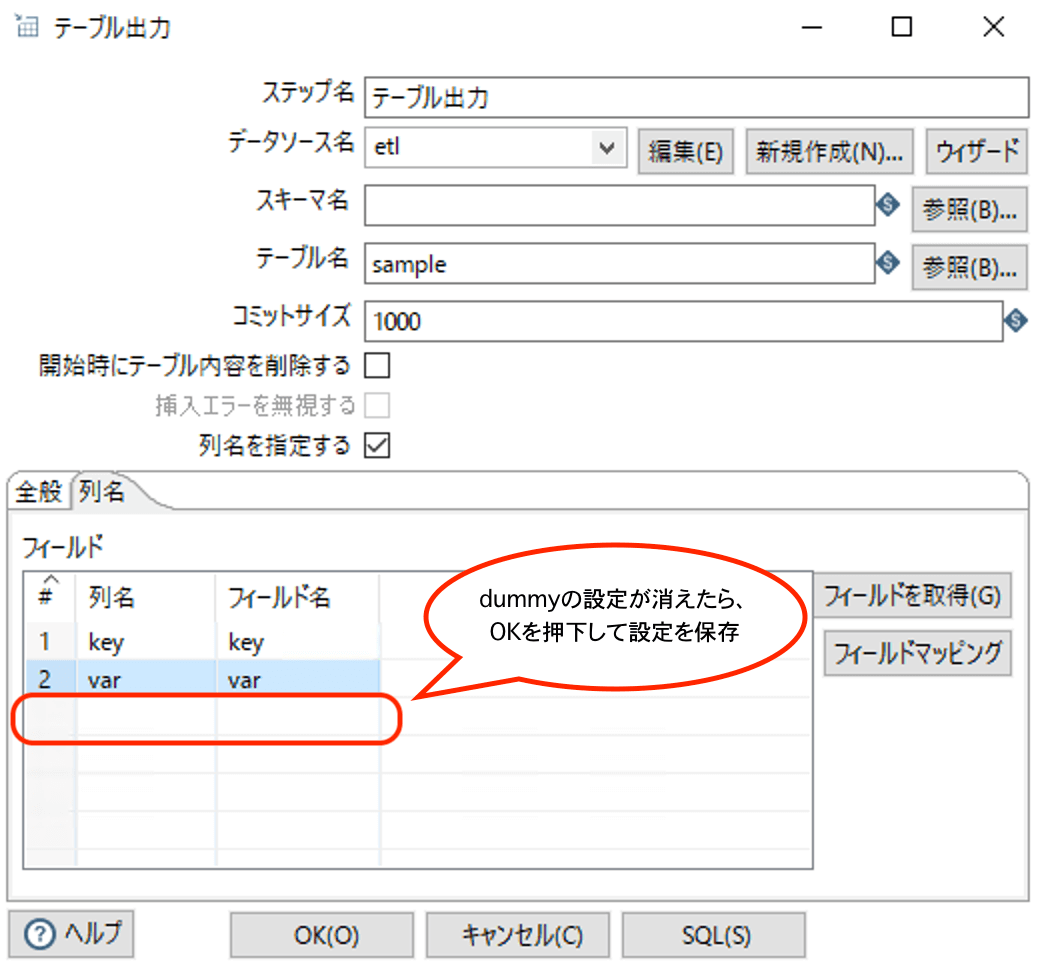
この状態でOKで設定を保存、Transformation自体も保存してから、実行を行います。
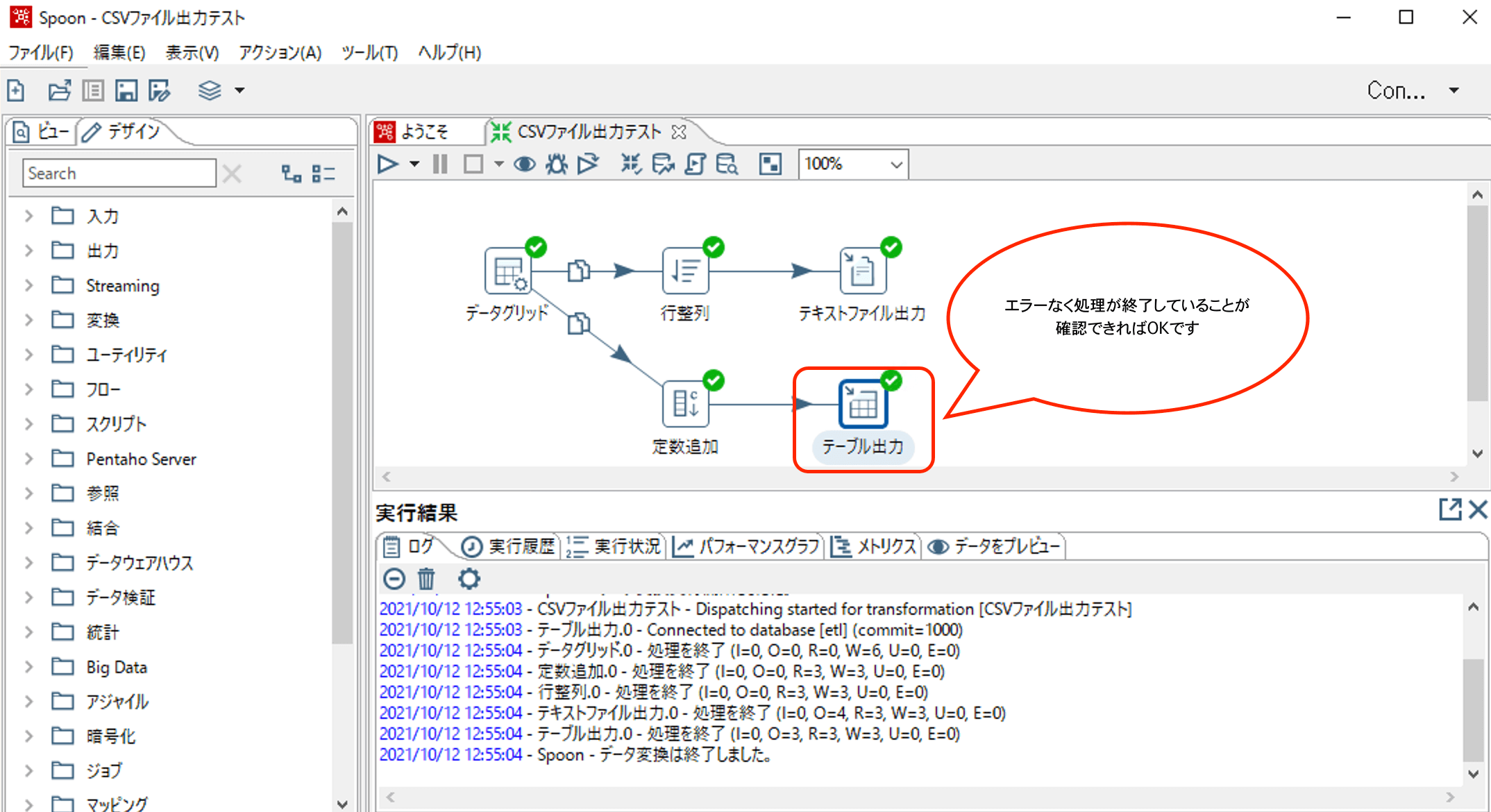
エラーが出なければOKです!