PDIでよく使うなと思う変換機能(ステップ)をまとめて紹介していきます。
なお、定数追加を含む文字列加工機能は色々あるので、それは別途紹介するとして、今回はそれ以外の機能に絞りました。
1. 選択/名前変更
Inputデータのフィールド名変更や型変更、不必要なフィールドの除去、フィールド順序の変更などを行うことができます。
様々なデータ加工を行い、無駄にフィールド(列)が多くなってしまった際の整理によく使用されます。
感覚的にはTransformationを作ると必ずひとつは使うと思います。
少々コストの高い処理なので使いすぎると処理が重くなるよと、Pentahoの中の人に以前聞いたことがありますので多用にはご注意ください。
後述するグループ化ステップでも不要なフィールドの削除はできるので、処理の中でグループ化(合計とか)を行う場合などは、そちらでフィールド整理してしまっても良いかもしれません。
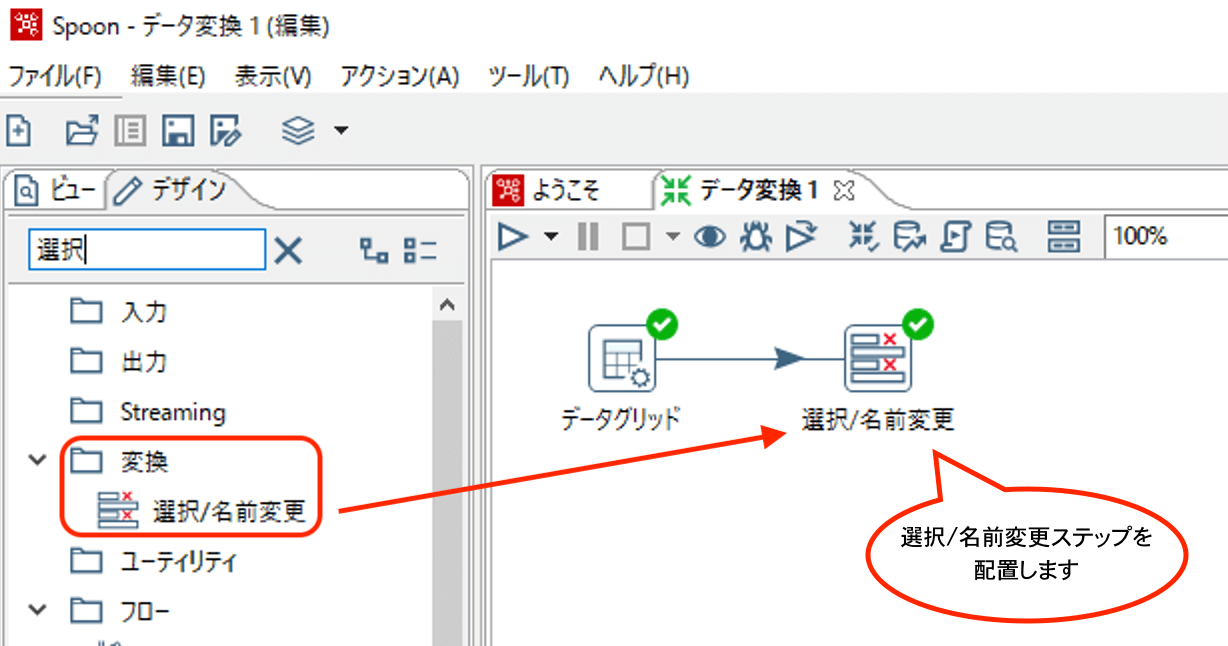
以下のように「選択/名前変更」ステップを配置します。元データはデータグリッドステップを使用しています。
各設定を行ったあと、選択/名前変更ステップ上で右クリックして、プレビューを行うことで結果を確認することができます。
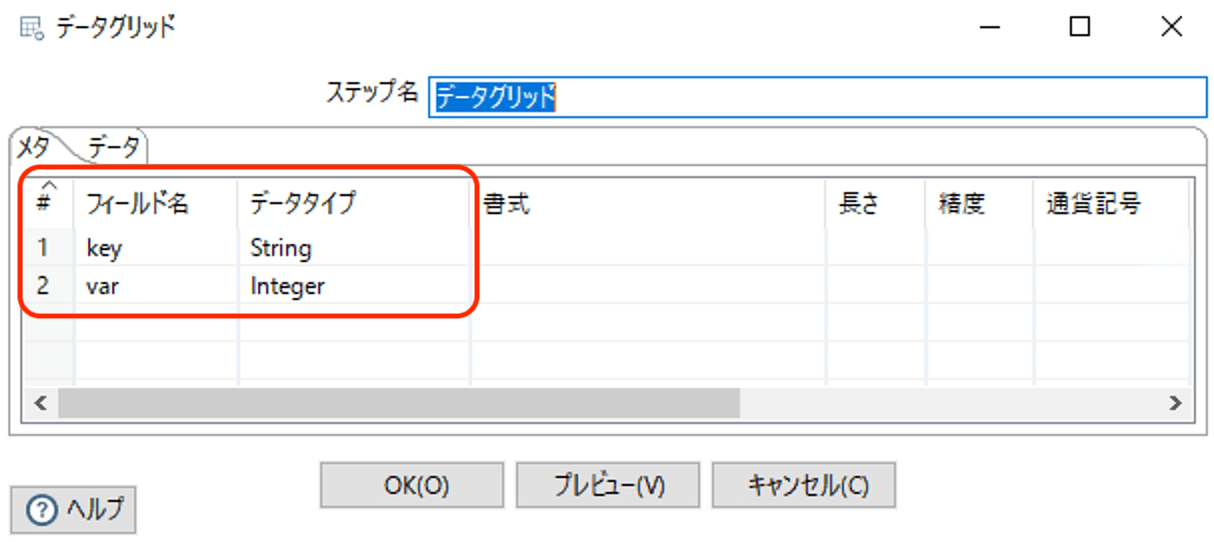
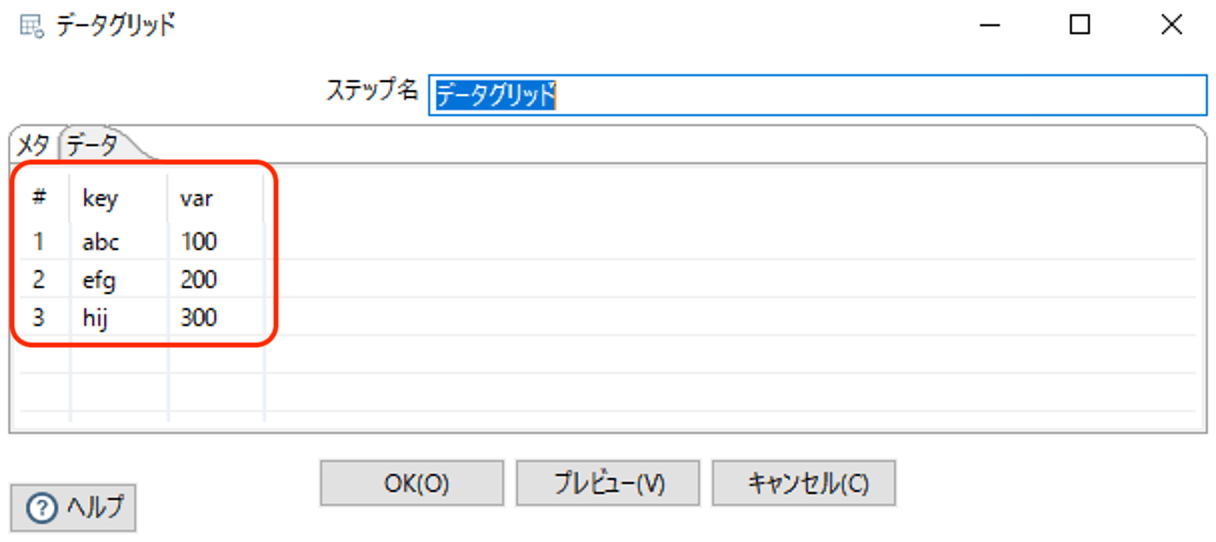
データグリッドは、以下のような構造とデータになっています。
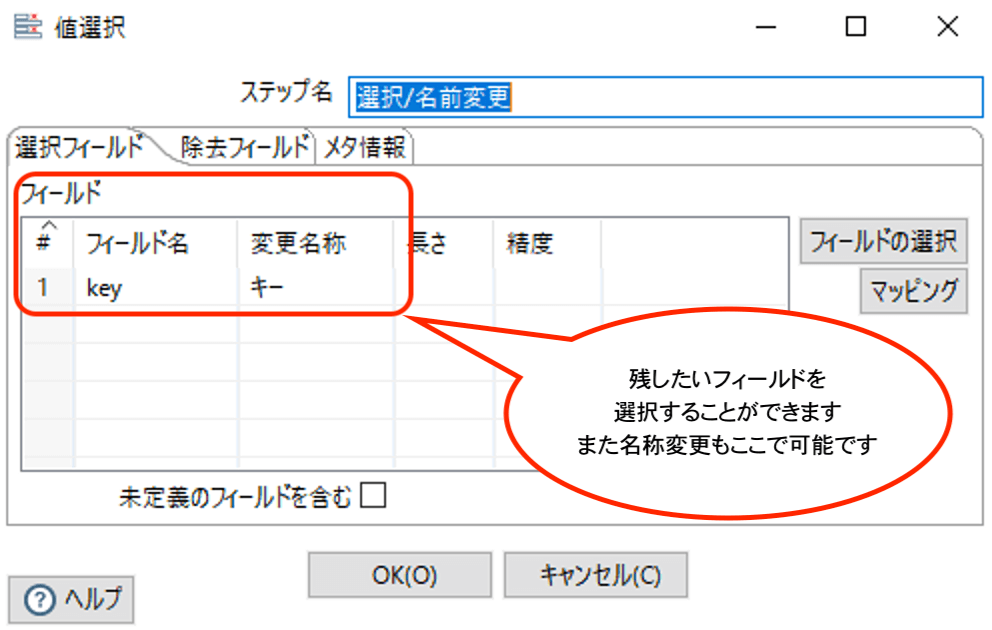
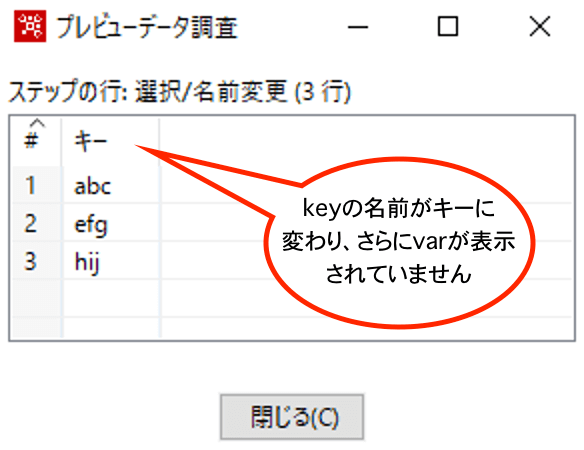
【フィールドの除去とフィールド名の変更】
以下、結果です。
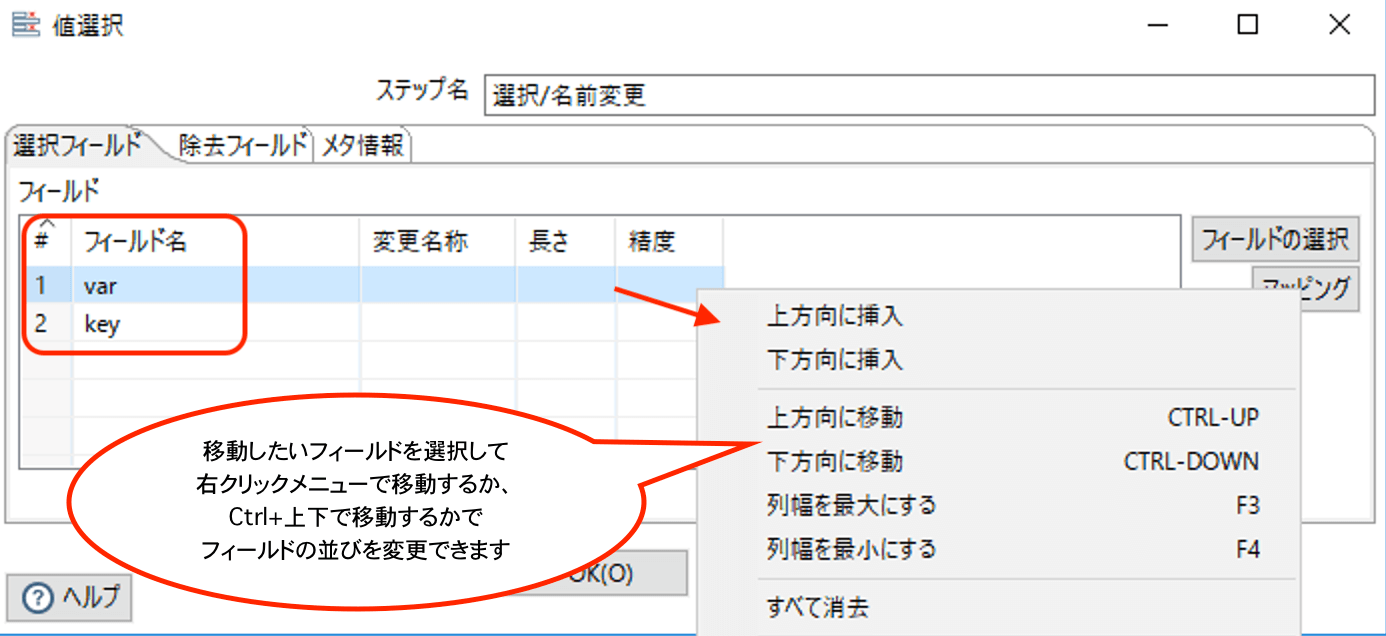
【フィールド順序の変更】
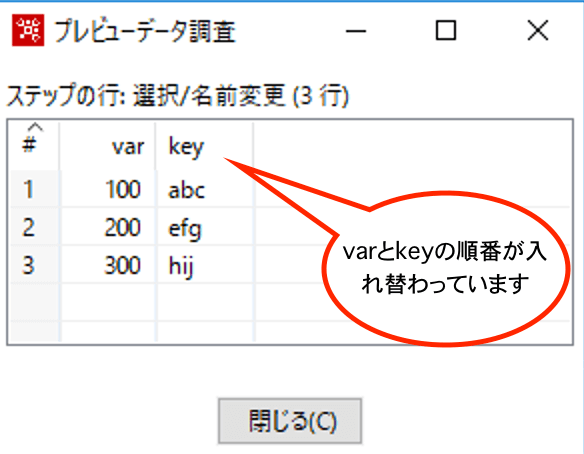
以下、結果です。
【除去フィールド】
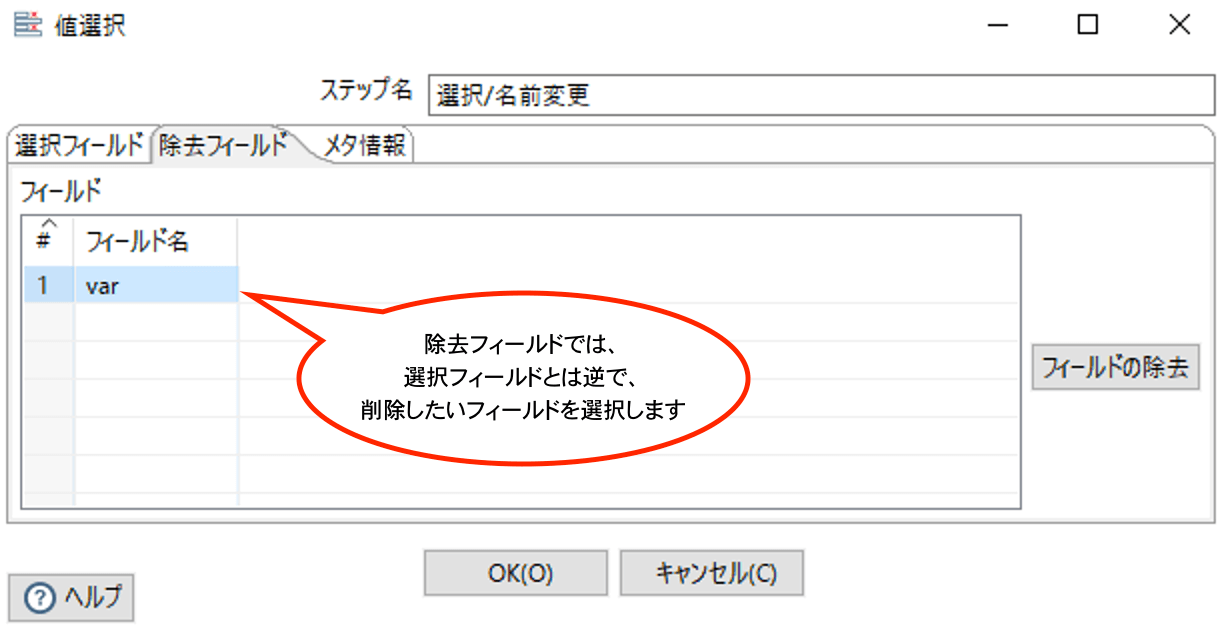
選択フィールドと変わらないので結果は割愛します。
ちなみに選択フィールドで選択しているものを、除去フィールドで選択すると、結果的には削除されます。
【型変換】
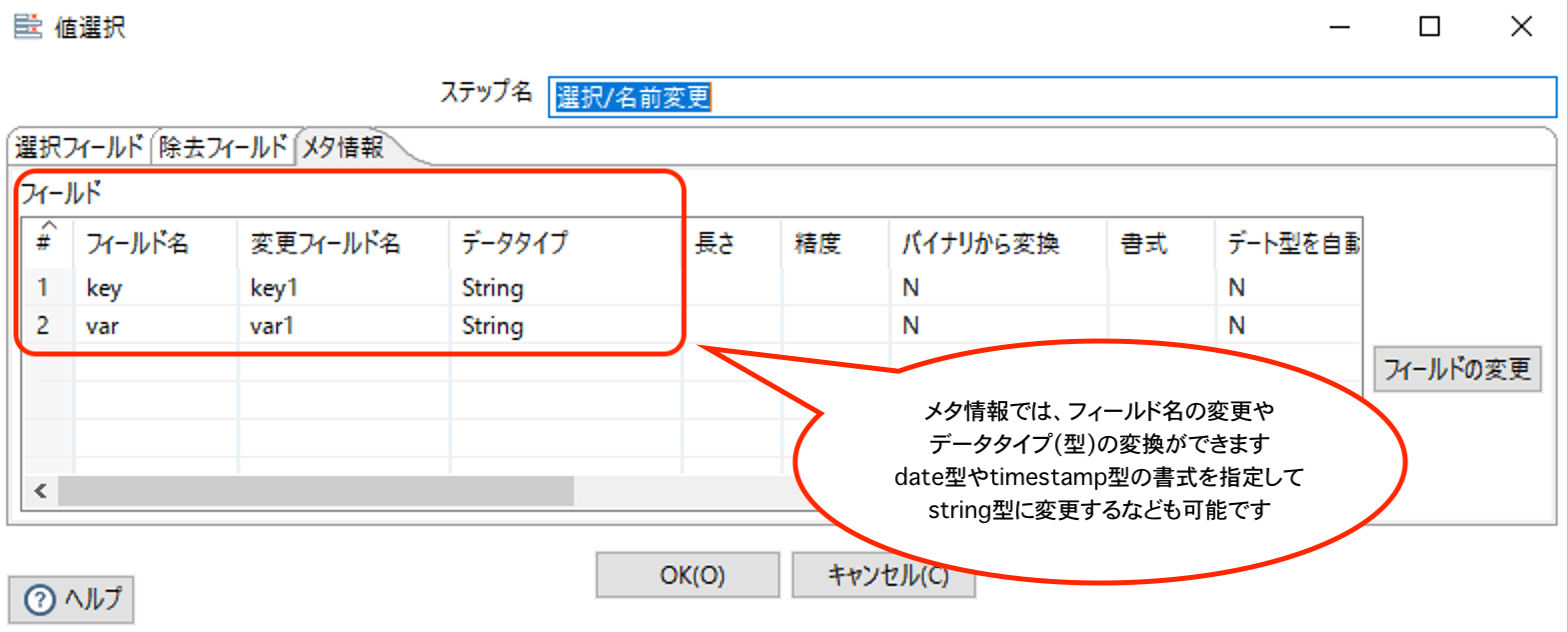
こちらも結果は割愛します。
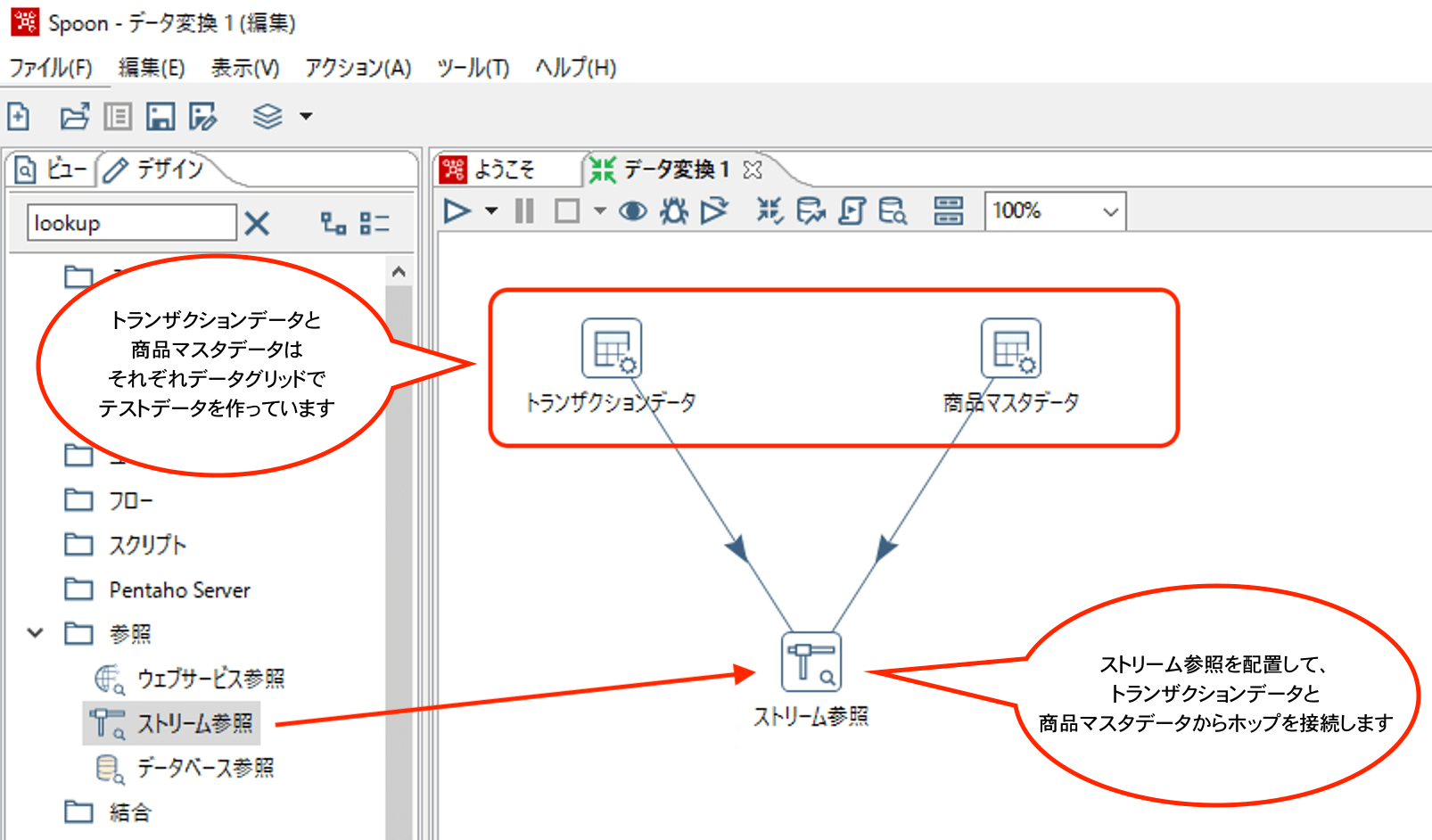
2. ストリーム参照
データをキーにして別のデータとマッチング、必要なデータを取得する際に使用します。
基本的には結合処理と同じですが、Left Outerでマスタ情報を取得する処理ができるものと考えればよいかと思います。
具体的には、売上伝票等のトランザクションデータに商品マスタの商品名を追加するなどの場合に使用ができます。
(トランザクションデータは商品コードを持ち、商品マスタは商品コードと商品名やカラーなどを持っている想定です)
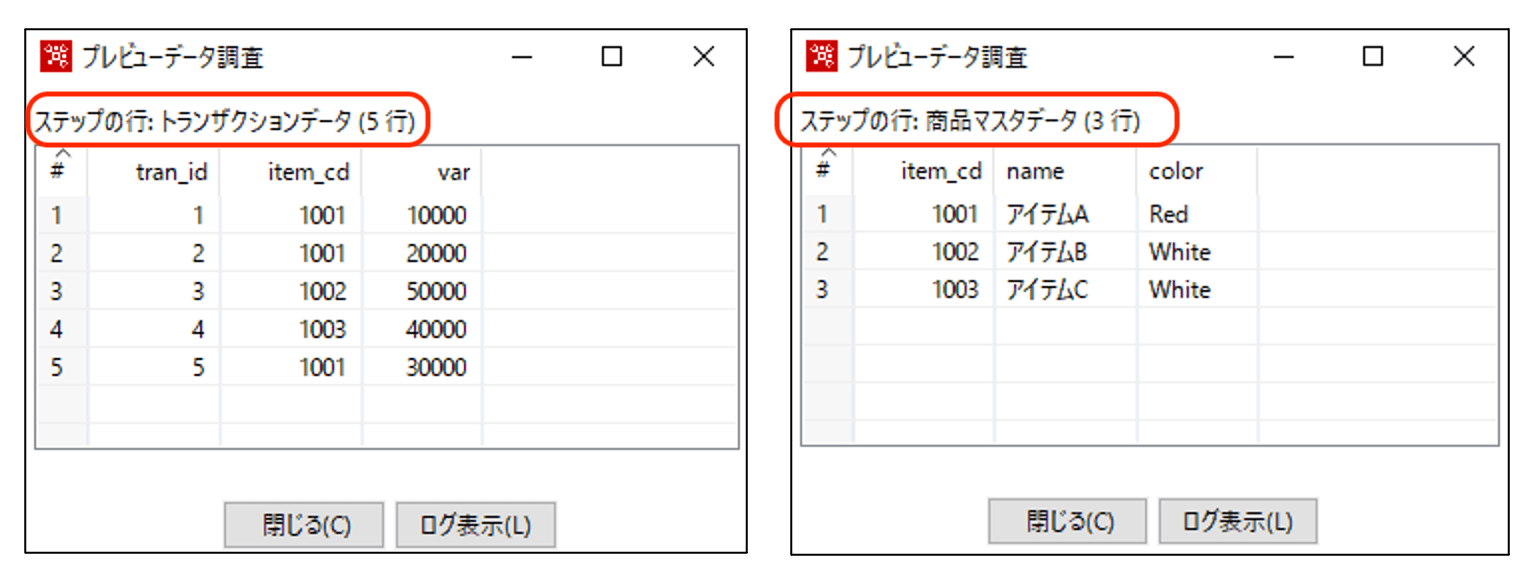
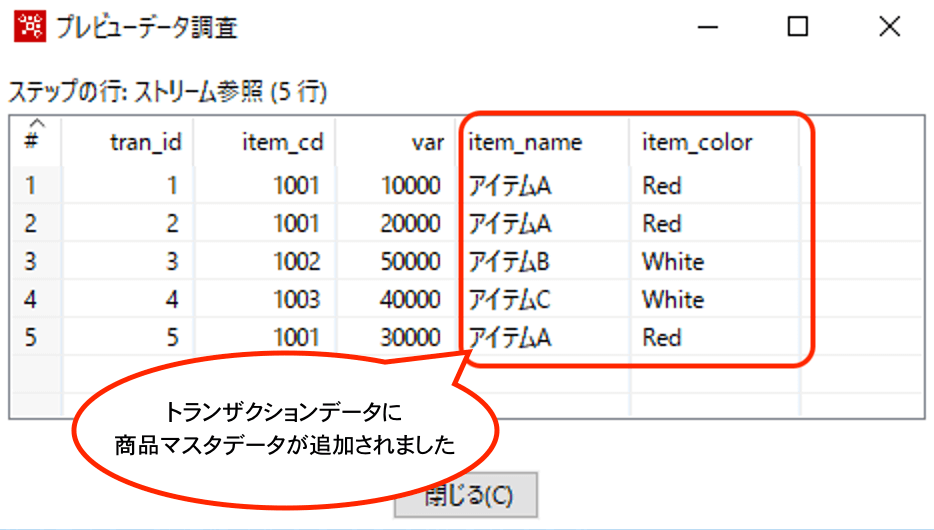
トランザクションデータと商品マスタデータの中身は以下のような感じです。
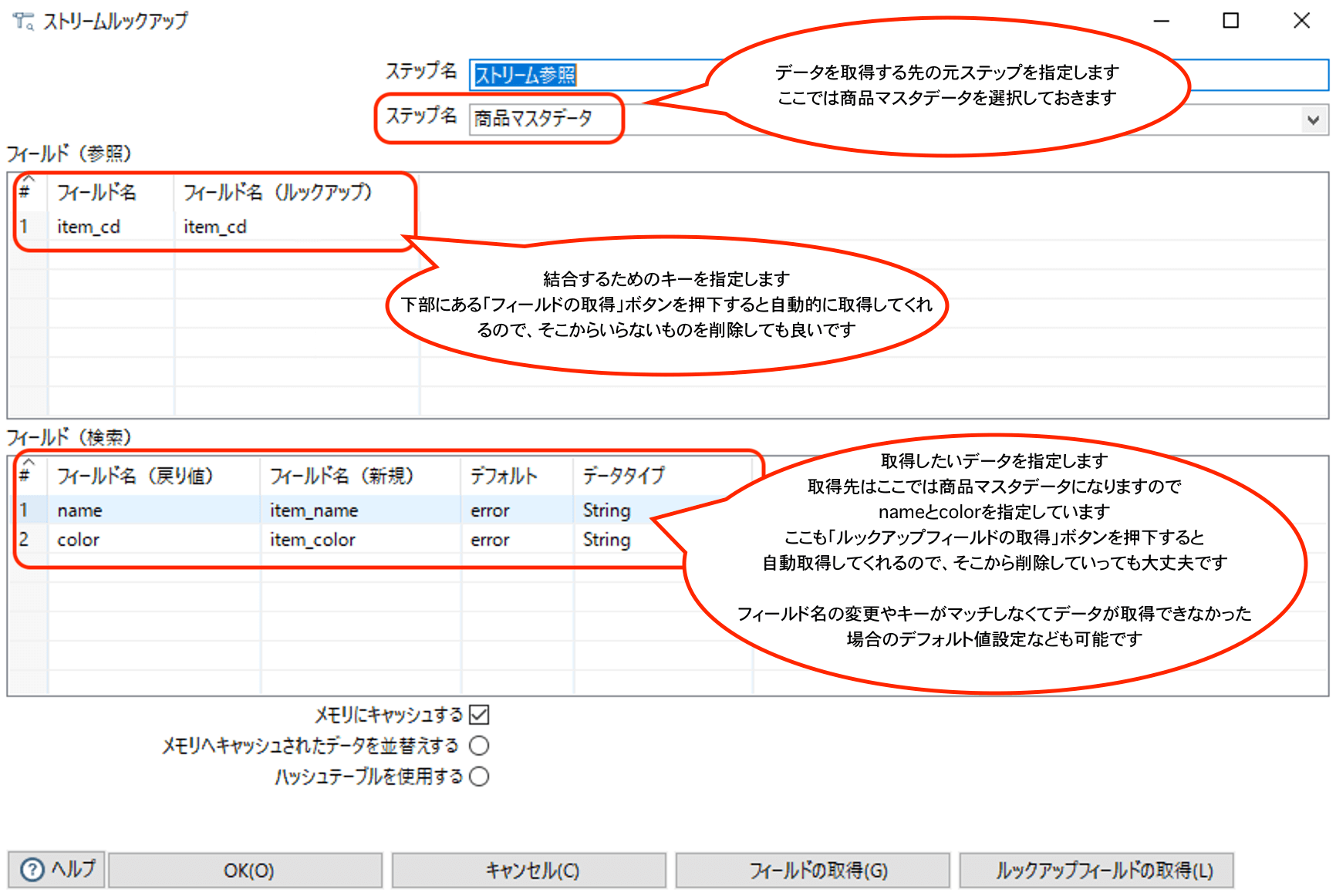
以下のように設定を行います。
参照する側のデータ(ここでは商品マスタデータ)を指定して、トランザクションデータにあるitem_cdをキーに参照側データのnameとcolorを取得するというイメージです。
以下、結果です。
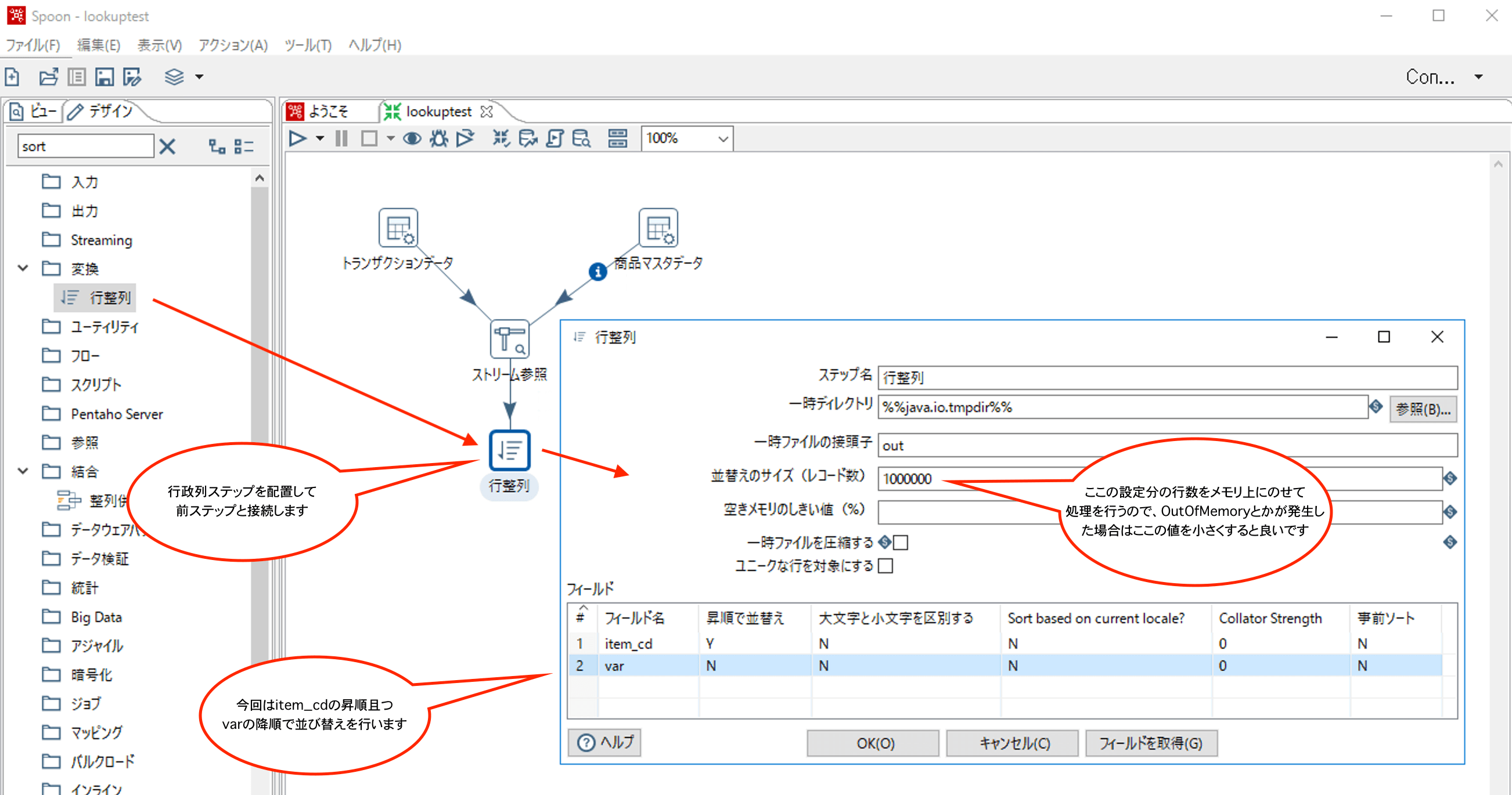
3. 行整列
行整列ではソートを行うことができます。複数キーでの並び替えも可能です。
ストリーム参照で使用したTransformationに行整列ステップをつなげて説明していきます。
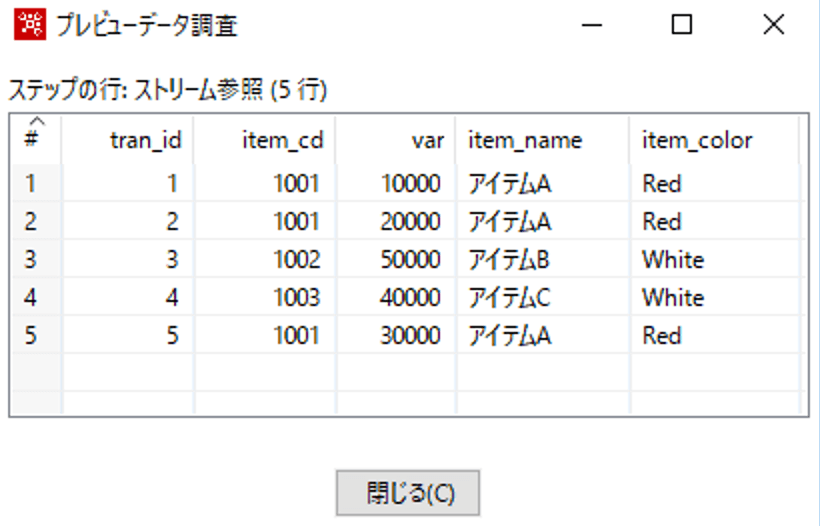
ソート前のデータは以下のようになっております。
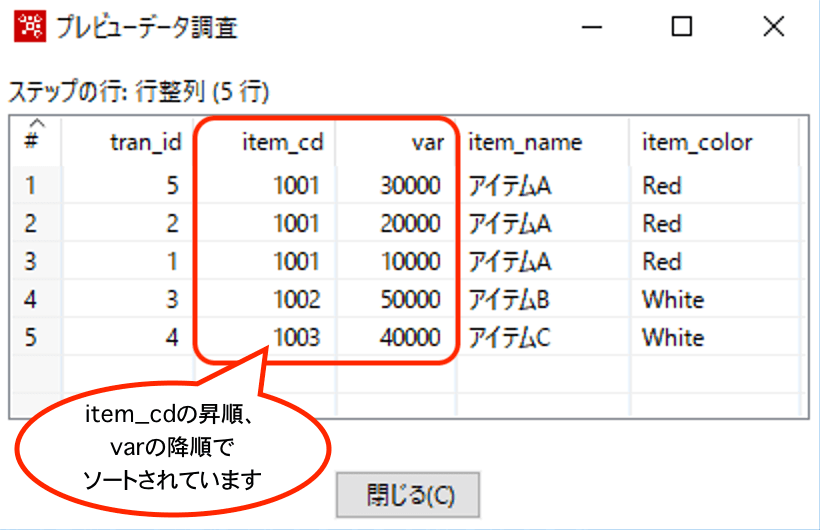
ソート後の結果は以下のとおりです。
4. グループ化
グループ化は、キーを指定して、そのキーごとのデータの合計や平均値の計算、MaxやMin値の取得、先頭や最後の値の取得などを行う際に使用します。
注意点としては、グループ化を行う前に事前にソートをしておく必要があることでしょうか。ソートせずに実行すると正しい結果が取得できません。
これも行整列で紹介したTransfromationの後ろにグループ化ステップをつなげて説明していきます。
まず、元データは以下のとおりです。
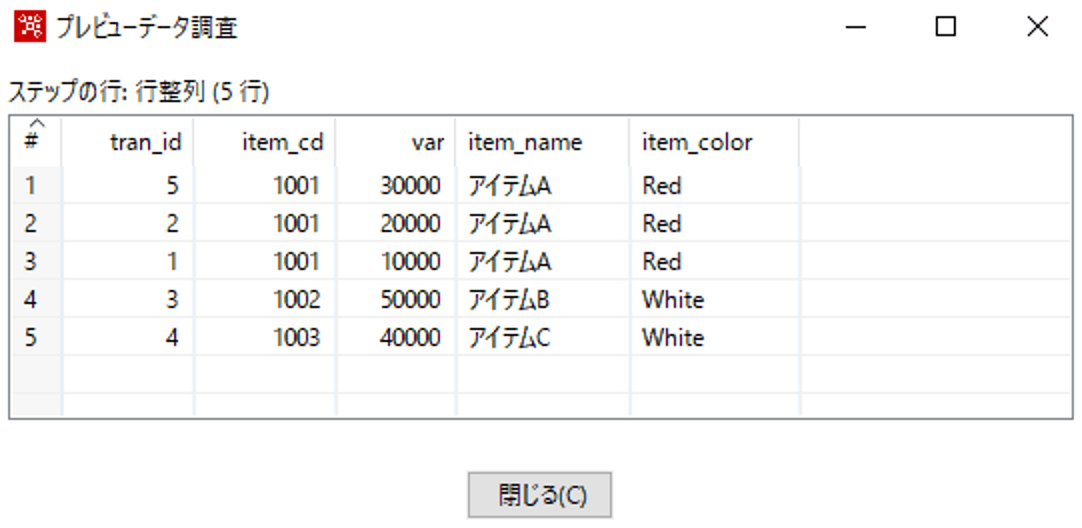
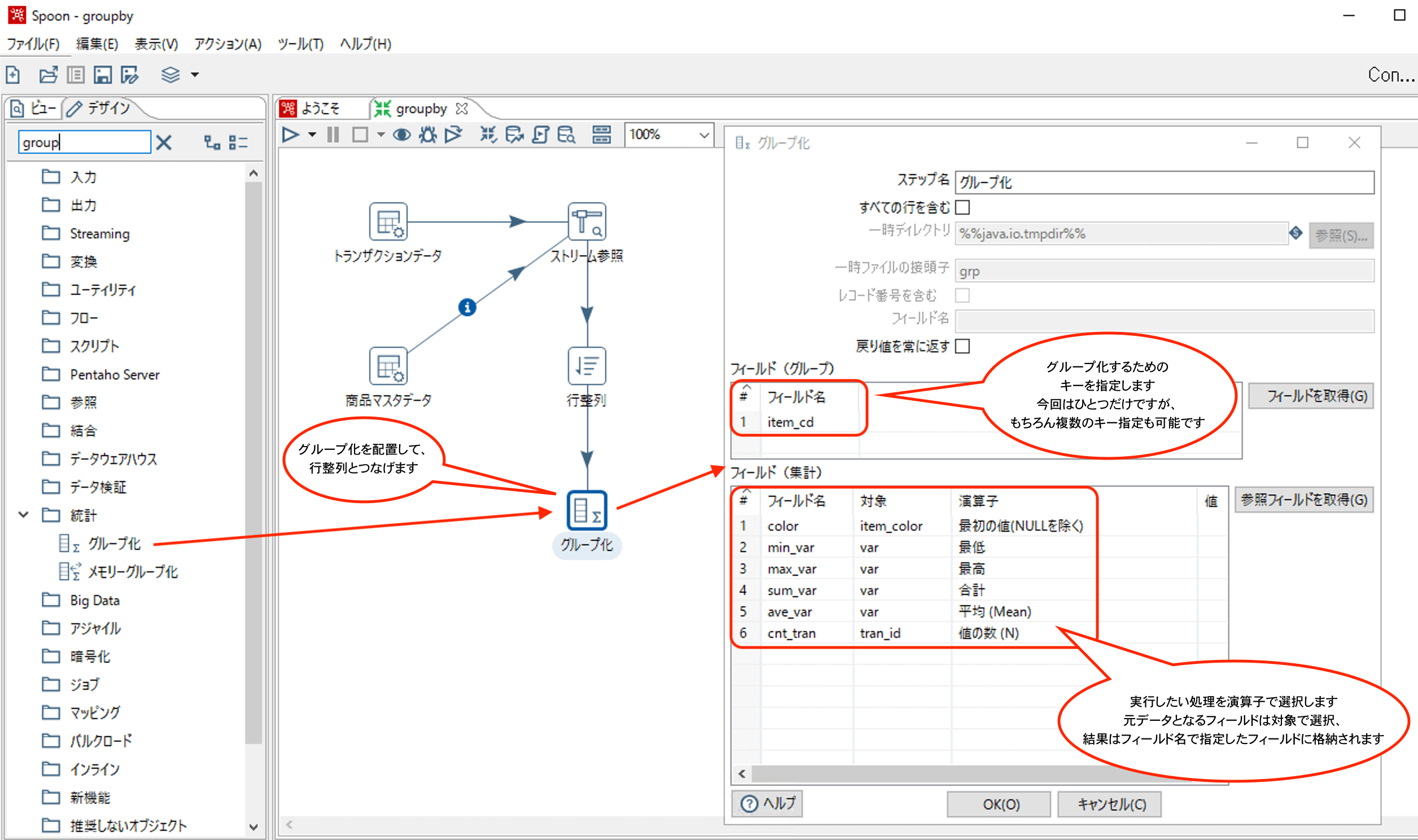
グループ化ステップの設定は以下のとおりです。
OKで保存する際に、以下のようなメッセージが表示されます。
日本語的に何を言っているかよくわからないメッセージですが、これは事前にソートしてないと結果が正しくならないことがありますよ、ということを伝えようとしているものです。あまり深く考えずに了解しておきましょう。

結果は以下のとおりです。
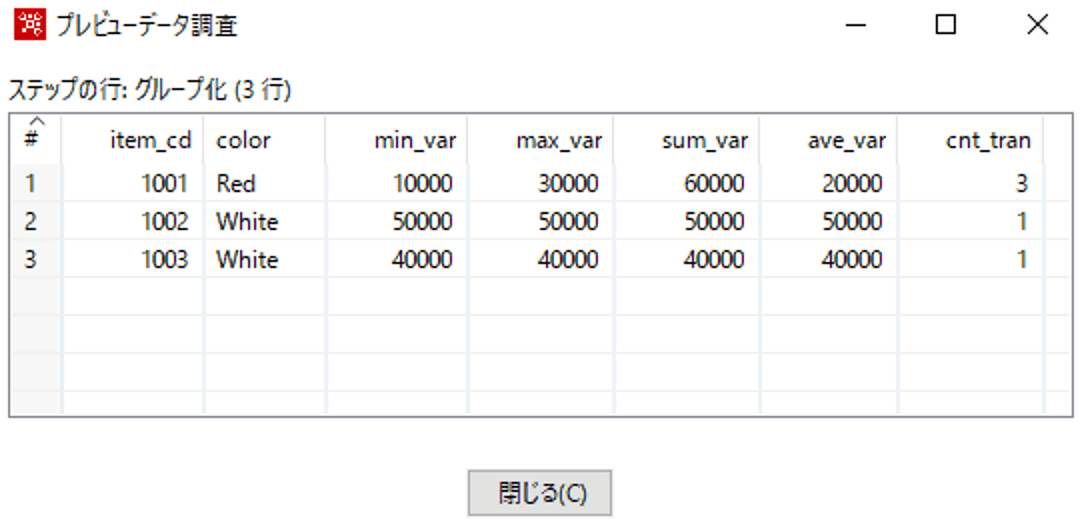
item_cdをキーとして集計しているのでitem_cdでユニークになっています。
colorはitem_cdごとの最初の値を取得しており、以降は、最小値、最大値、合計、平均、tran_idの数が格納されています。
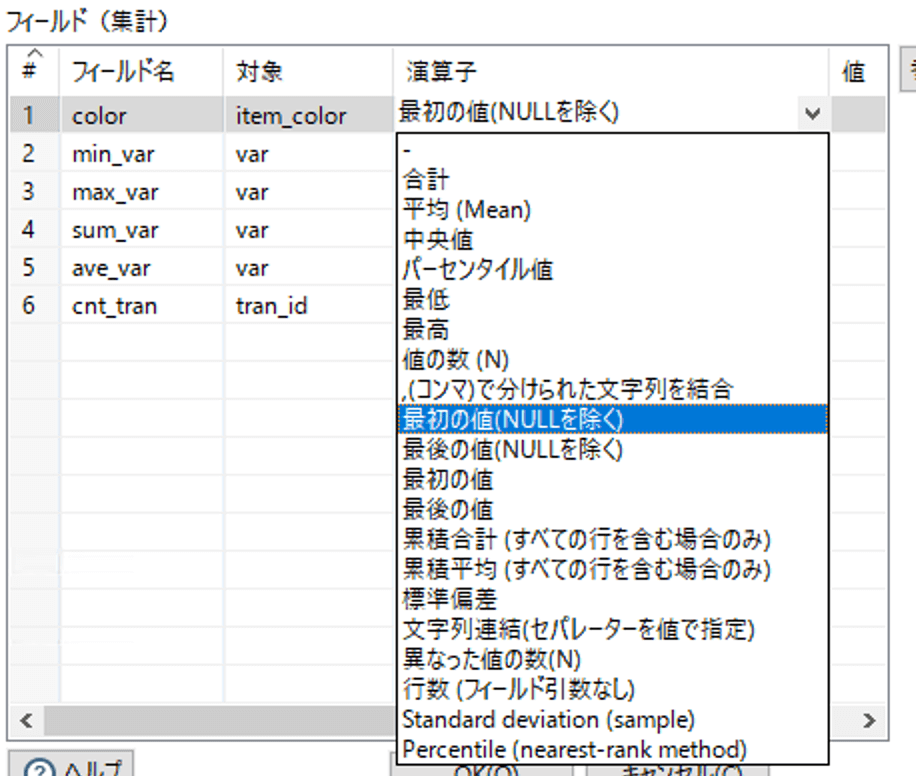
グループ化ステップで使用できる演算子は以下のとおりです。
5. フィルター
フィルターでは条件を指定して、条件に合致したものとしなかったもので処理を変更する際に使用します。
今回は、以下のデータを使用して"item_cd = 1001"の条件でフィルターを実行したいと思います。
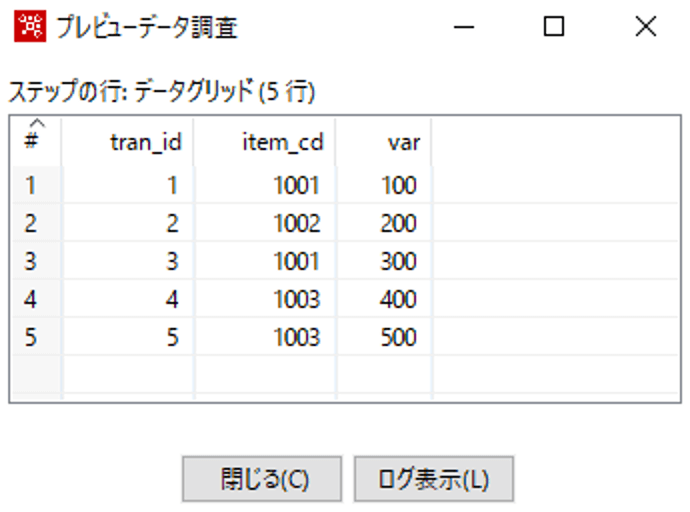
フィルター設定は以下のとおりです。
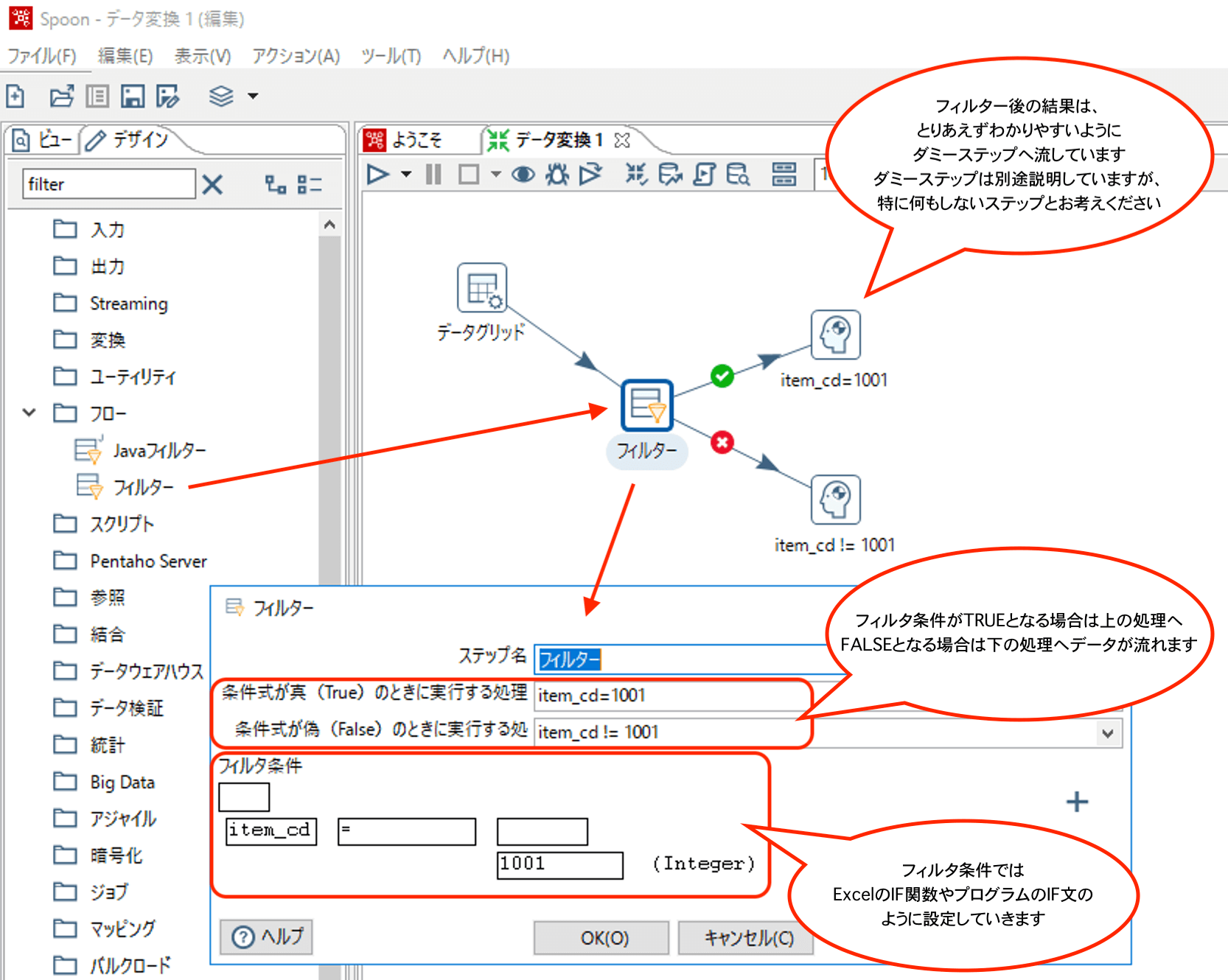
フィルターステップのあとのホップ上に「チェック」マークと「X」マークのアイコンが付いていますが、フィルター条件に合致したデータは「チェック」マーク側の処理に流れ、合致しなかったデータは「X」マーク側へ流れて処理が継続されます。
よく使用されるケースとしては、やはりその名のとおりデータをフィルタしたいときで、処理条件に合うデータのみを抽出する場合が考えられます。
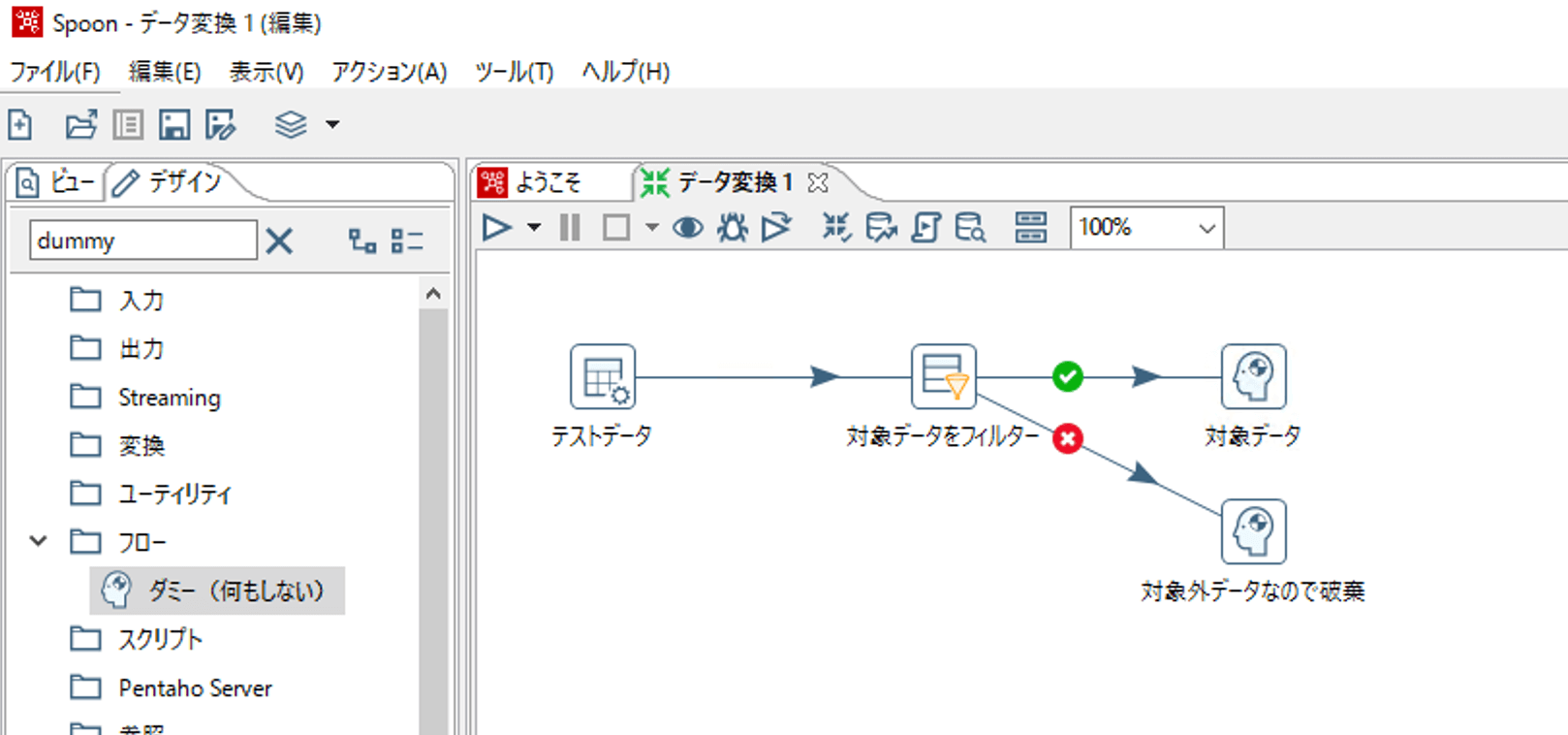
対象外となったデータを捨てたい場合は、ダミーステップを使用します。
ダミーステップは、何も処理を行わないステップなので、ダミーステップにつないで、その後別のステップにホップをつながなければそちらへ流れたデータはそこで破棄されます。
ダミーステップへつないで、ダミーステップ名前を「対象外データ破棄」とかつけておくことで、Transformationの可読性を上げることもできます。
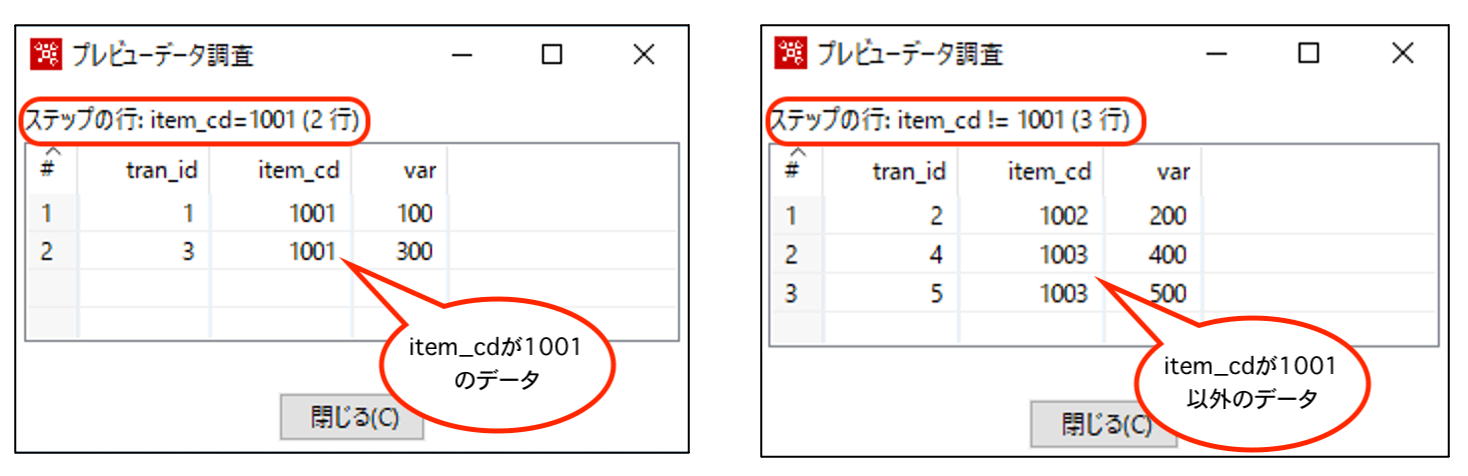
以下、結果です。
なお、処理を分けずに以下のようにすると、Trueのデータのみ後続処理に流すこともできます。
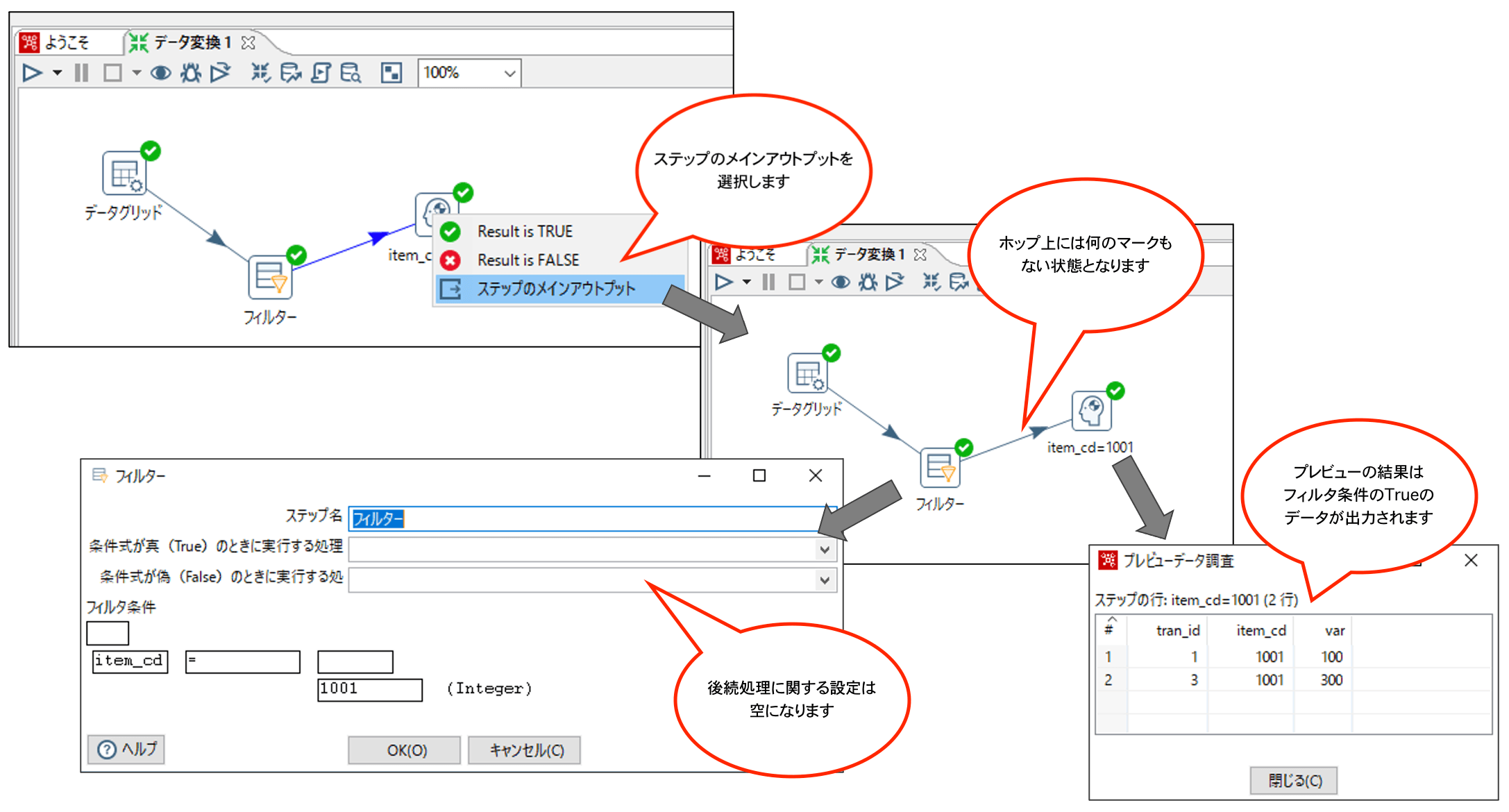
今回は全体的な説明のため単純な式でのフィルターをご紹介しましたが、複数式のANDやOR、NOT、IFの入れ子なども作ることができます。この辺はまた別の記事にしようかと思います。
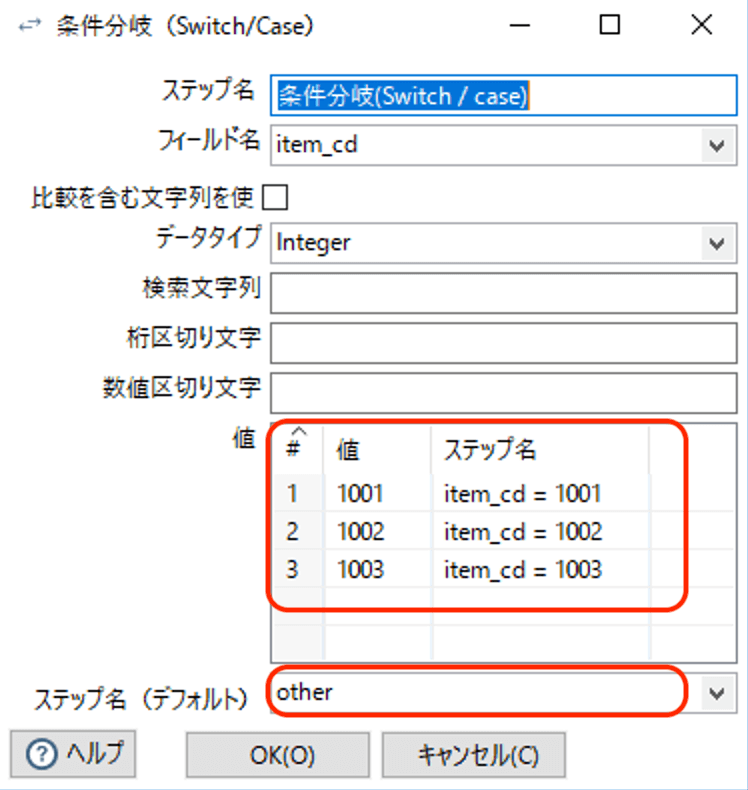
6. スイッチ/ケース
フィルターでは条件式の結果でTrueかFalseの二つの処理へデータを流すことができましたが、スイッチ/ケースでは条件に従い、3つ以上の処理へデータを流すことができます。
今回もフィルターの説明と同じデータを使用し、そのなかのitem_cdを使用して処理を分ける設定の説明をしたいと思います。
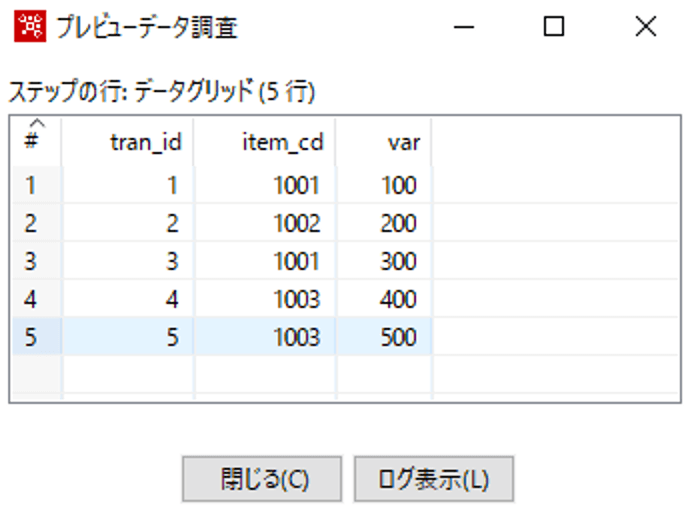
使用する元データです。
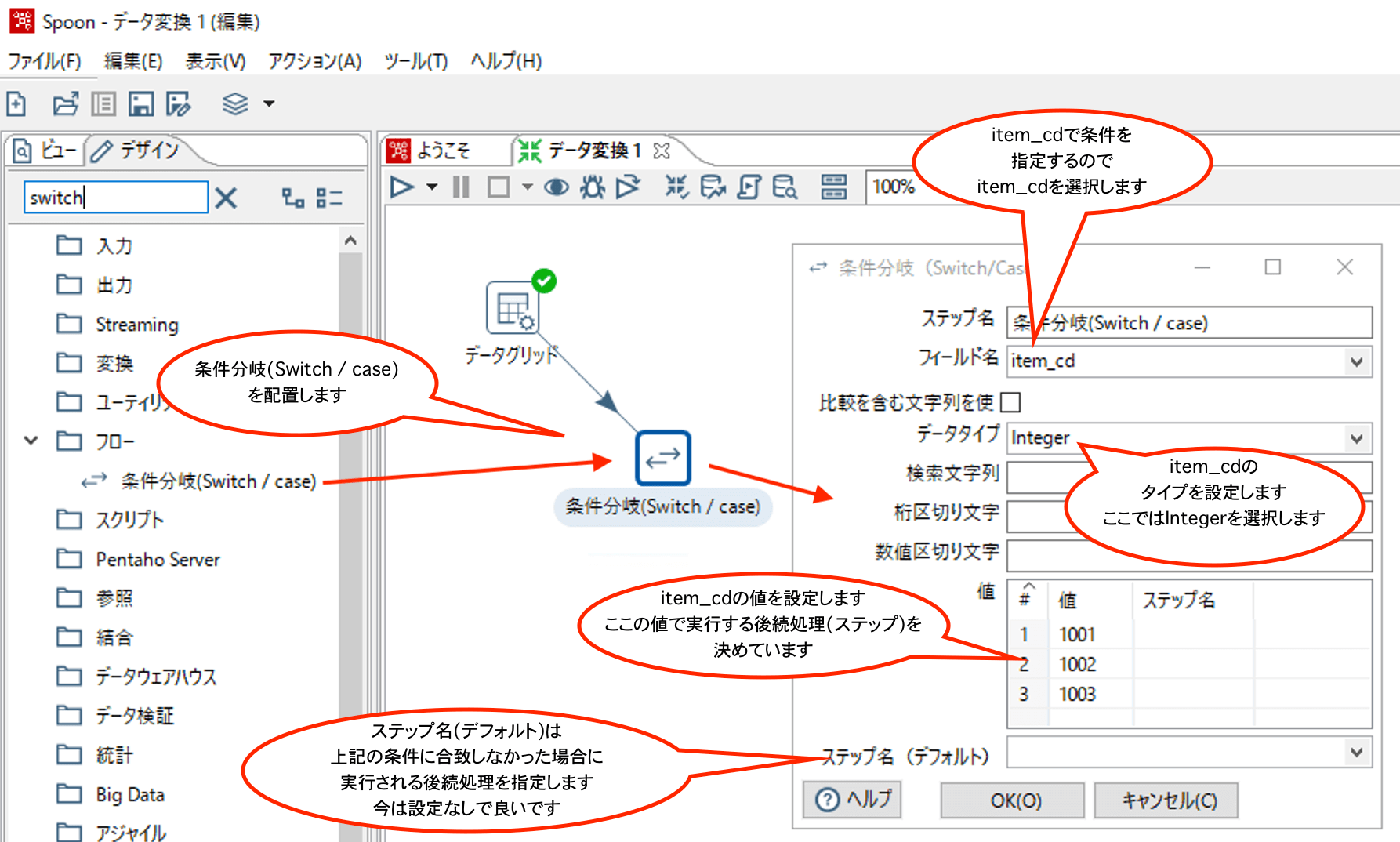
次にスイッチ/ケースステップを配置して、設定を行います。
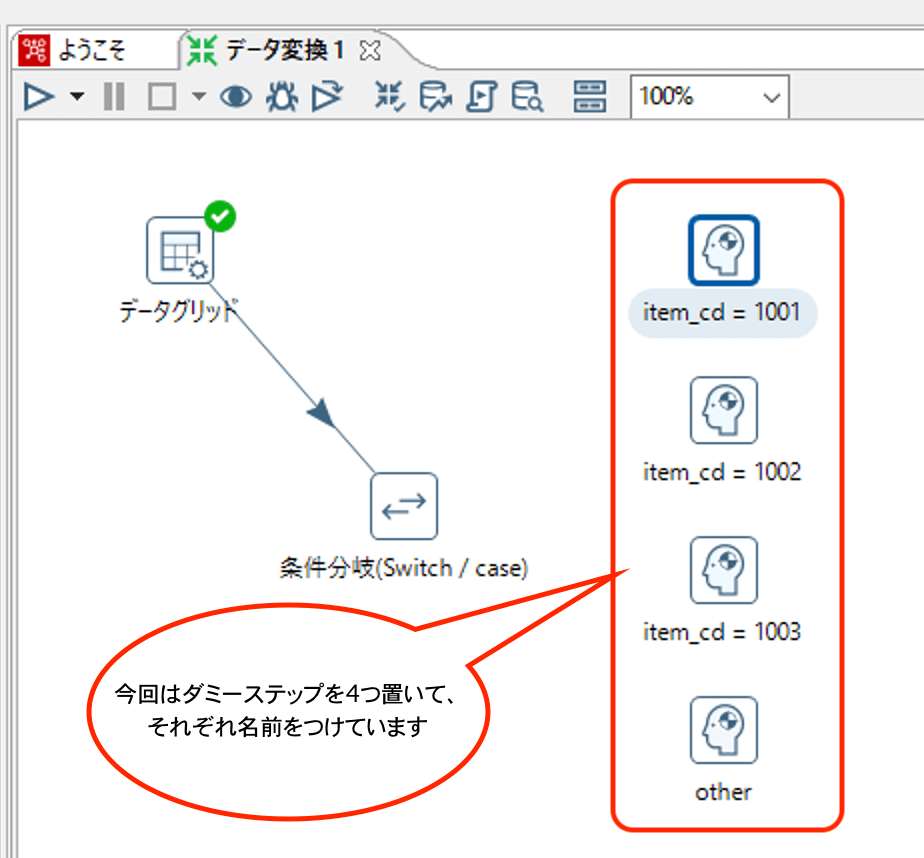
ここまでで、条件指定はできましたので、次に各条件に合致したときに実行される処理をダミーステップで作成しておきます。
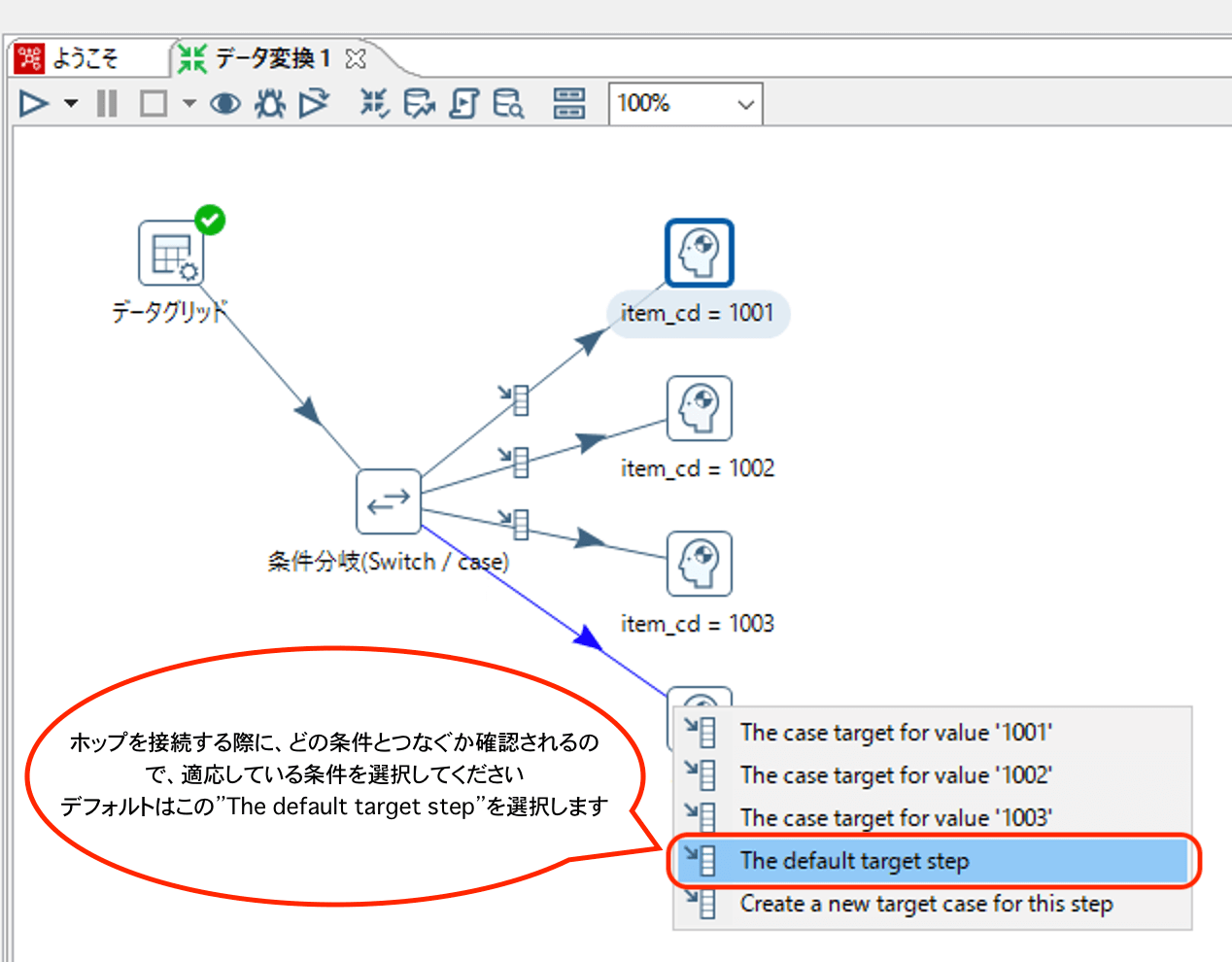
スイッチ/ケースから各ダミーステップにホップを接続していきます。その際にどの条件を使用するのかを確認されるので、以下のように設定していってください。
すべて接続したあとに、スイッチ/ケースの設定を確認して、以下のようになっていればOKです。結果は割愛します。
7. Join
Joinはその名の通り、二つのデータをキーを指定して結合し、一つのデータセットにするものです。
Joinに関してはいくつか機能が提供されていますが、今回は「マージ結合」をご紹介します。
以下のようにTransformationの処理を作成します。
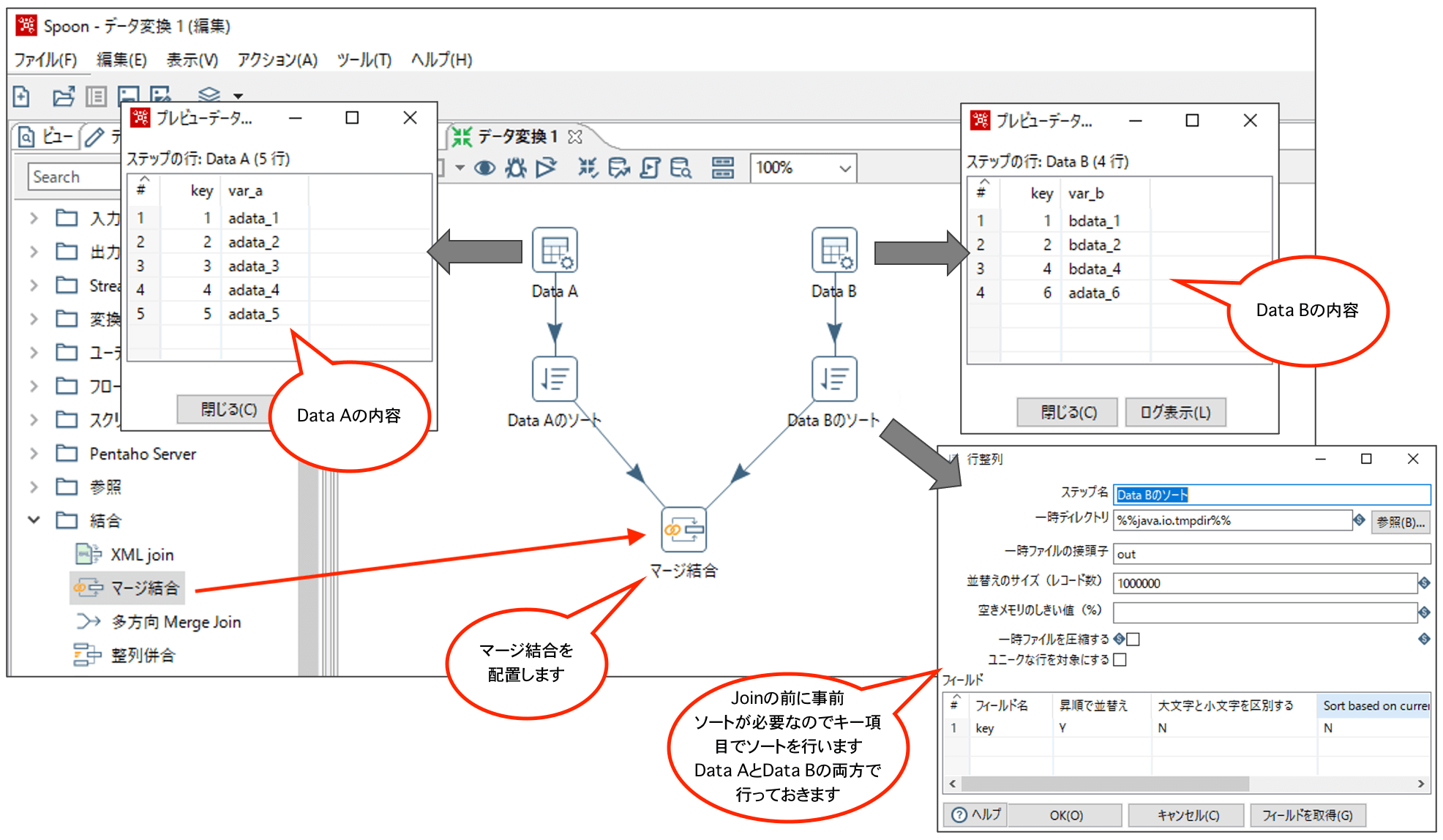
データグリッドを2つ置き、それぞれテストデータを設定したらJoinで使用するキー項目でソートを行い、最後にマージ結合ステップを置いてつなげます。
次に、マージ結合の設定を行います。
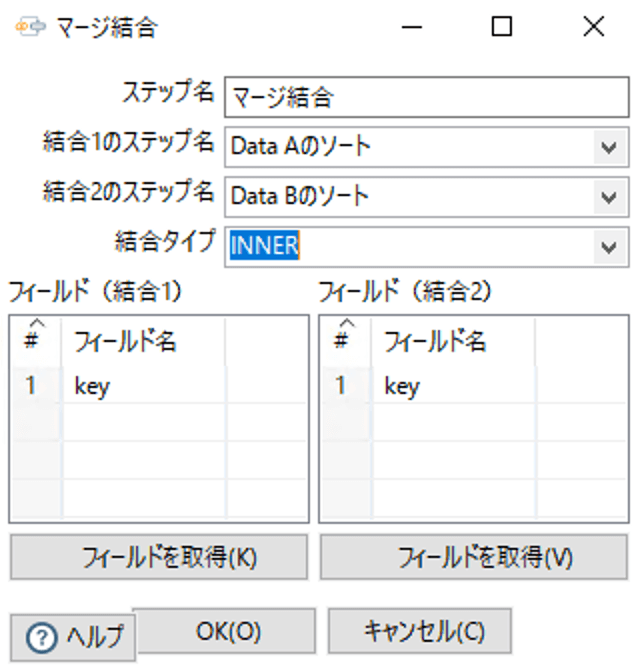
結合1のステップ名はLeftTable、結合2のステップ名はRightTableとなり、フィールドでそれぞれのキー項目を指定します。
結合タイプは、INNER、LEFT OUTER、RIGHT OUTER、FULL OUTERが選べます。
また結合時にLeftとRightTableデータに同じフィールド(カラム)が存在した場合は、RightTable側のフィールド名がリネームされます(_1などがフィールド名の後ろに付く)。
それぞれの結果は以下のとおりです。
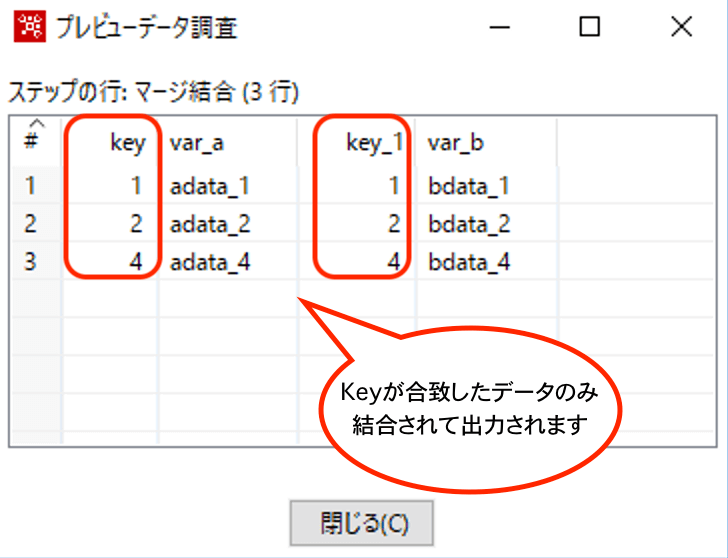
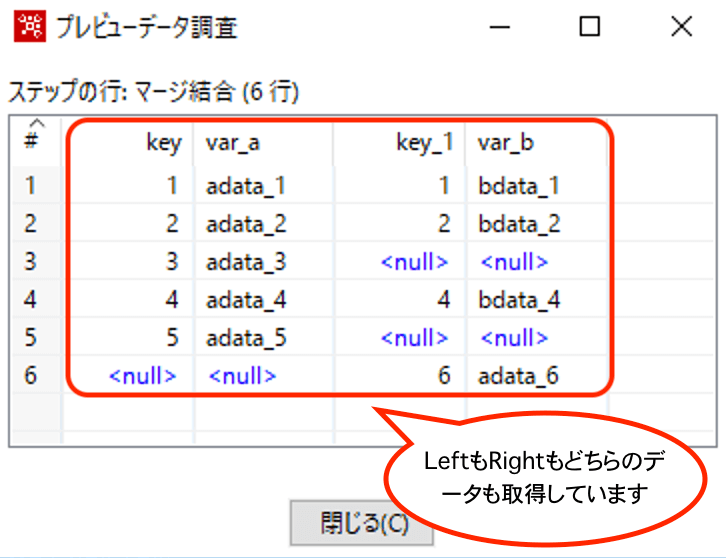
【INNERの結果】
InnerJoinなので、LeftTableとRightTableの両方にキーが存在したデータのみ出力されます。
【LEFT OUTER】
LeftTableのデータはすべて出力し、さらにRightTableからはキーと結合できたデータだけ取得します。取得できなかったデータはNULLが設定されます。
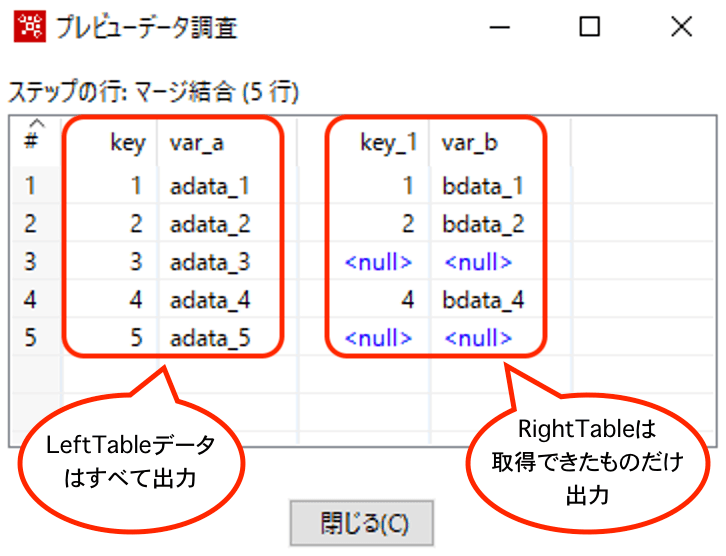
【RIGHT OUTER】
Left Outerとは逆で、RightTable側がすべて出力され、LeftTable側からキーで取得できたデータが出力されます。取得できなった箇所はNULLが設定されます。
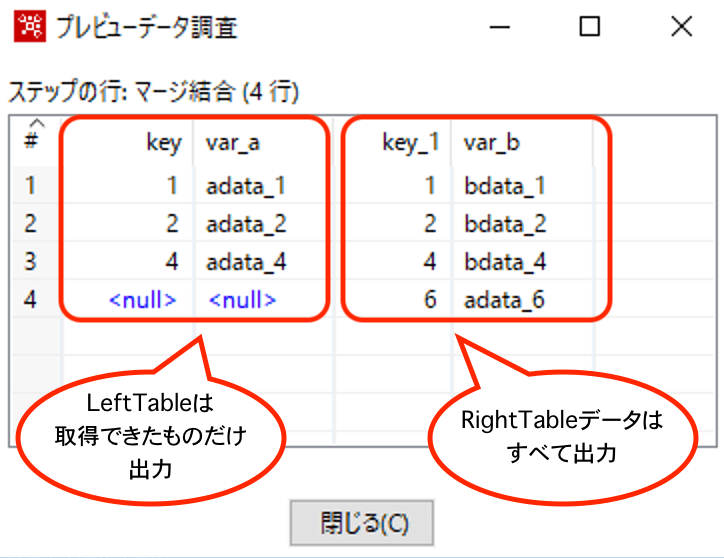
【FULL OUTER】
簡単に言えば直積結合です。
LeftTableとRightTableのデータのすべての組み合わせのデータを作成します。
8. ストリーム結合
Joinのようにキーで結合するのではなく、2つのデータを上下にくっつけてくれる処理です。
SQLでいうところのUnion Allです。
結合するデータは同じフィールド構造でなくてはいけません(違うフィールド名があるとエラーになります)。
以下のように設定していきます。
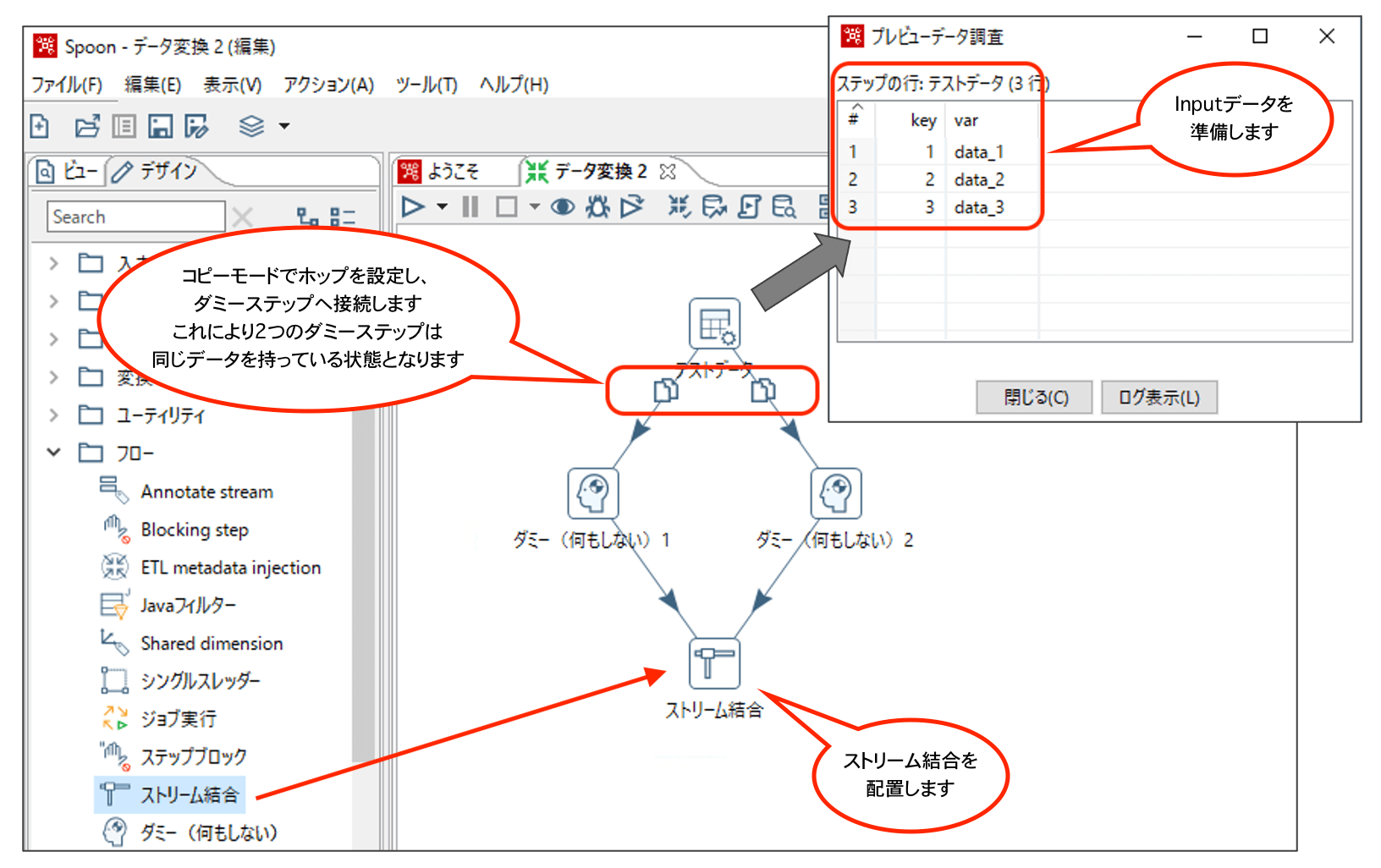
続いて、ストリーム結合の設定を行います。
設定は簡単で、上にくるデータと下にくるデータをそれぞれ指定するだけです。
以下の例では、「ダミー(何もしない)1」のデータを上に追加して、その下に「ダミー(何もしない)2」のデータを追加するという動作になります。
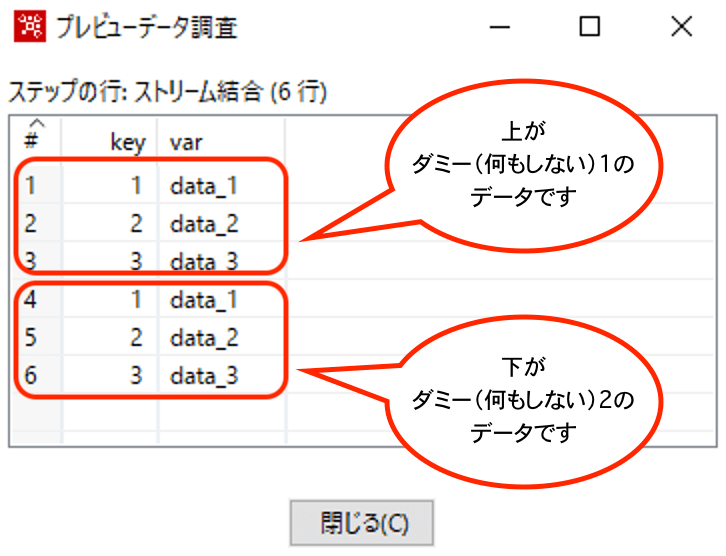
結果は以下のとおりです(同じデータにしてしまったのでわかりにくいですが、データが結合されていることはわかるかと思います)。
9. 数式
少々込み入ったデータ加工などを行う場合、どうしてもPDIが持つ基本的な機能では足らなくなる場合があります。
また、基本機能でETL処理を組むとどうしても手数が増えて処理内容が冗長になってしまい、処理の流れが見えづらくなってしまうような場合もあります。
そういった場合に自分でロジックを組むことができるのが数式ステップです。イメージ的にはExcel関数に近いです。
PDIはデータをストリーム形式で1行ずつ処理していきますので、同じ行のなかのデータを使用した条件処理やデータ加工などで役に立ちます。
今回は以下のテストデータを使用して、varが1000より小さいときは"対象外"、大きいときは"対象"というデータを設定する処理を作成したいと思います。追加するデータは、新しくflgというフィールドを作成して、そこに設定します。
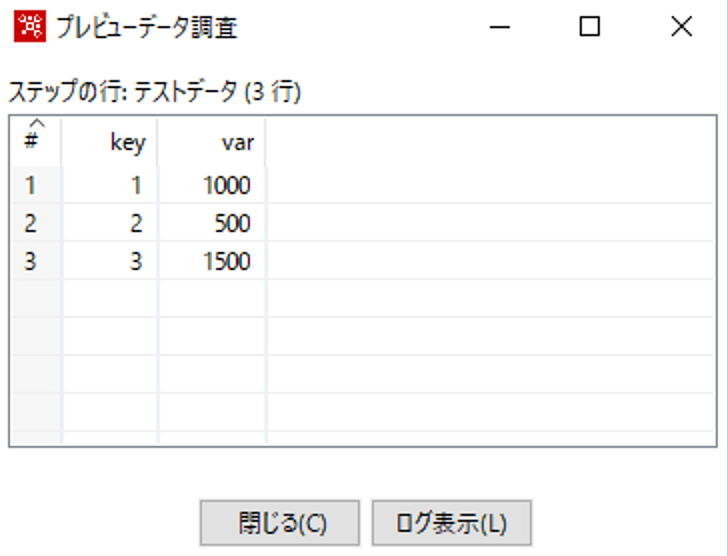
テストデータを数式ステップをつなげます。
次に数式の設定を行います。
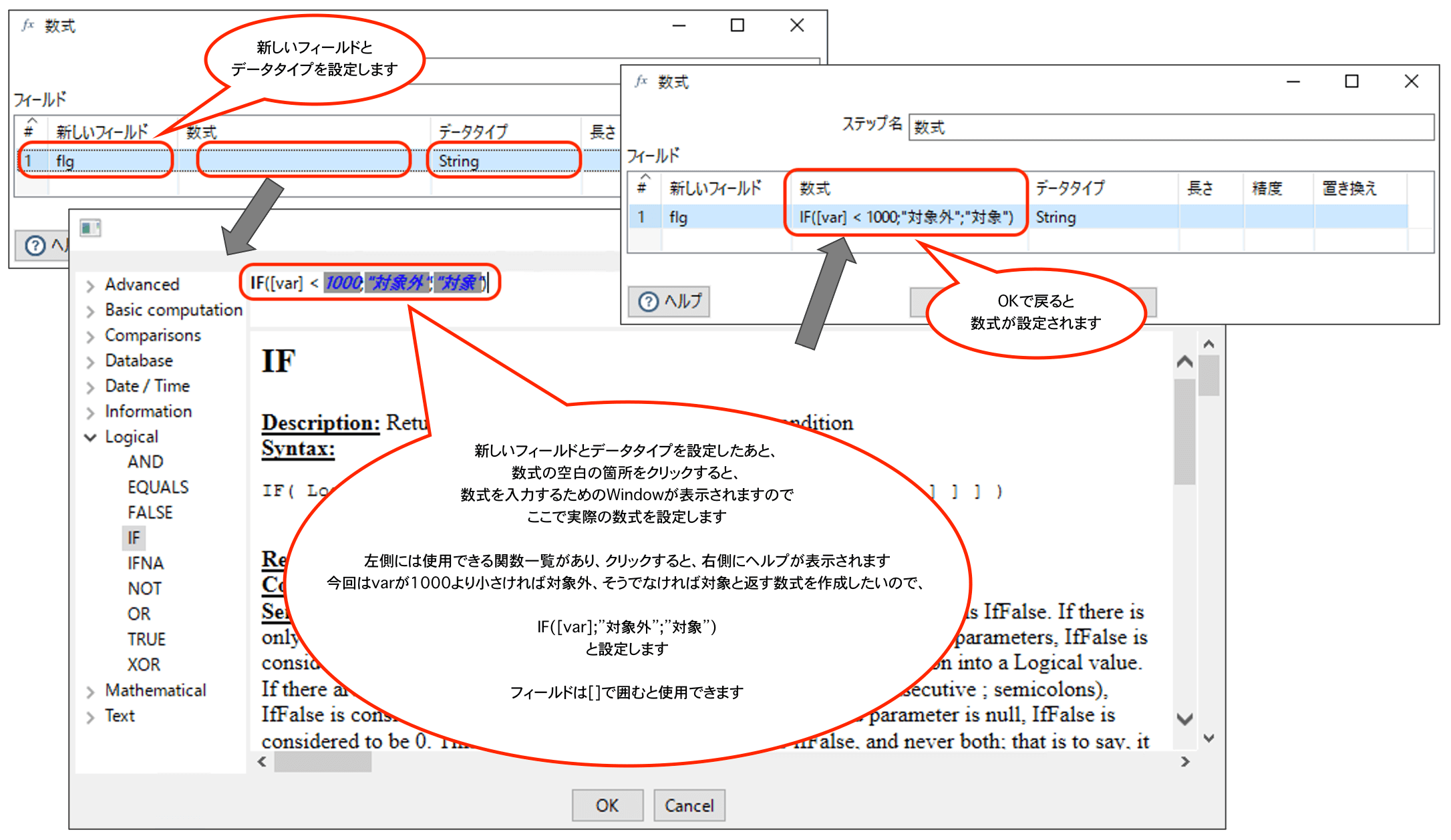
まず新しいフィールドにflgを追加して、データタイプをStringにしておきます。
次に、数式設定が空ですが、その空の場所をクリックすると数式を入力するためのWindowが表示されますので、ここで数式を設定していきます。
式のなかでフィールドの値を使用したい場合は、"[フィールド名]"を指定します。今回はvarを使いたかったので[var]と設定しています。
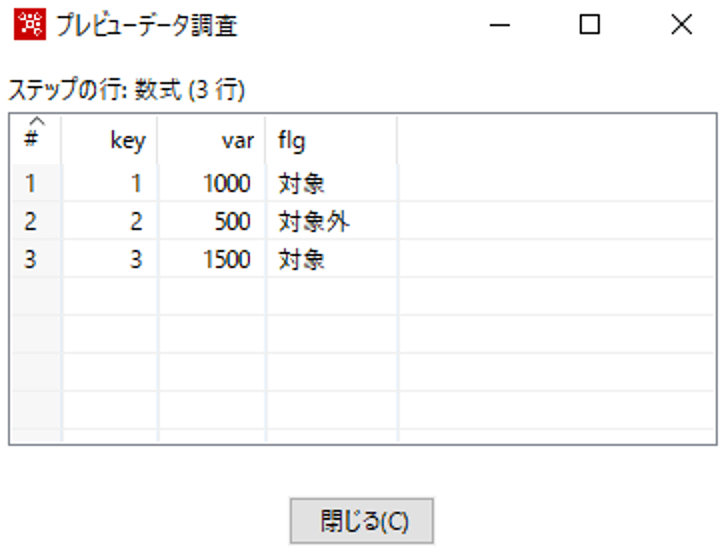
具体的には、「IF([var];"対象外";"対象")」と設定します。
結果は以下のとおりです。
flgフィールドに対象、対象外とデータが追加されていることが確認できます。
【フィルターで作成した場合】
上記では数式ステップを使用しましたが、フィルター機能を使用して同じ処理を作成することも可能です。
その場合は、少々冗長的なフローとなります。参考までに載せておきますので、違いだけご確認いただければと思います。
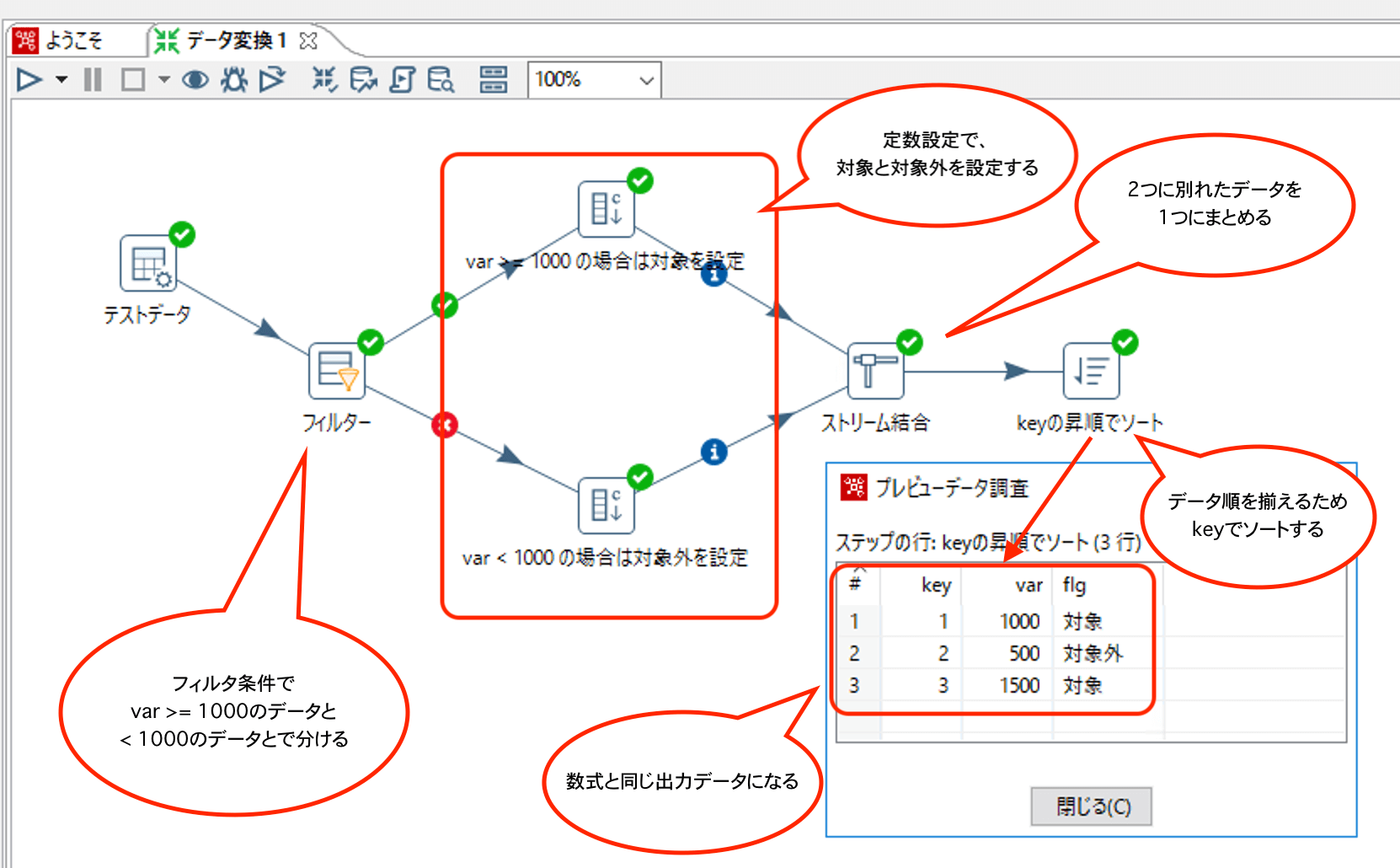
詳細は割愛しますが、数式ステップを使用したほうがスッキリしたフローになります。
10. ダミー
フィルターステップなどでも使用していますが、ダミーステップは何もしないステップです。
データを受け取るとそのまま後続処理へデータを流していきますし、後続処理が設定されていない場合は、そこで処理が終わります(受け取ったデータは渡す先が無いので破棄されます)。
そのため、一番ある使われ方としては、フィルターやスイッチ/ケース後に、処理対象外となったデータを破棄するためにつないでおくというものになります。
あとは、フローが混み合ってきてホップが重なってしまい見にくくなったときなどに、ダミーステップを経由させてホップを整理して見やすくするなどにも使用できますし、なにもせずにデータを受け渡してくれるものと考えればいろいろと使える場面もあるかと思いますので、覚えておくと役立つことがあるかもしれません。
まとめ
個人的によく使うステップを中心に10の機能をご紹介しました。
別の記事になっているInputとOutputの設定と、今回の変換機能を使用することで、かなりいろいろなデータ加工の処理が作成できるかと思います。
また、最初にも記載しましたが文字列加工の機能は今回の紹介には含めていないので、別途記事を書こうかと思っております。
あとは、もっと具体的なケースごとの記事も書いていく予定です。
少々長くなってしまいましたが、今回は以上です!