- Field : Amodal Instance Segmentation, Amodal Instance Complete
- Conference : NeurIPS
- Year : 2020
- URL : https://proceedings.neurips.cc/paper/2020/hash/bacadc62d6e67d7897cef027fa2d416c-Abstract.html
どんなもの?
アモーダル補完のためのVAE
→ 部分的に隠されたマスクから完全なマスクを再構成する
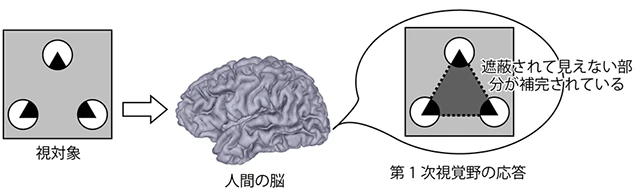
アモーダル補完とは(https://www.kyoto-u.ac.jp/static/ja/news_data/h/h1/news6/2013_1/131023_3.htm)
先行研究と比べてどこがすごい?
セマンティックセグメンテーションの研究のほとんどは、オブジェクトの可視ピクセルをセグメント化することに焦点を当てている。[6, 11, 34]
→ なぜ?: アモーダルセグメンテーションのためのラベル付きデータが不足しているから。アノテーションタスクの難しさと曖昧さが原因であると考えられる。
→ 学習時にアモーダルなラベルを必要とせず、現在のデータセットで広く利用されているオブジェクトの可視部分のインスタンスマスクを利用する。
技術や手法のキモはどこ?
Amodal-VAE
部分的に見えるマスクy^
→ 潜在空間にエンコード
→ 潜在コードzをフルマスクyにデコード
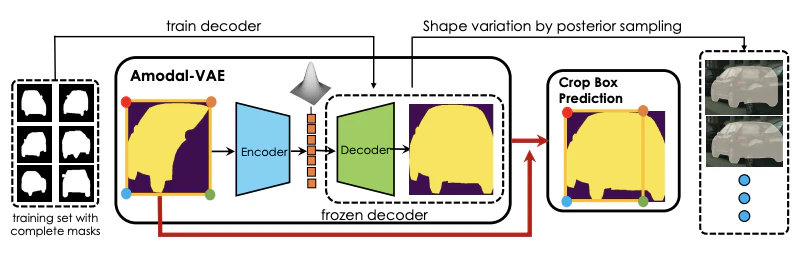
学習方法(弱い教師付きアプローチ)
0. 学習データセット Dtrain = {yi , yˆi} を用意。
部分インスタンスマスク yˆi 、それに対応する完全なマスク yi
(潜在的にはインスタンスクラス ci などの追加情報)
1. VAELossを用いてフルマスクyのみでAmodalVAEを学習
VAELoss : ELBO(変分下限)を最大化する(https://nzw0301.github.io/assets/pdf/vae.pdf)
- y: 現実的な完全なマスク
- y^: 部分的にしか見えないマスク
- z: 潜在変数
- pw1 (y|z):パラメータw1を持つニューラルネットワークによってパラメータ化されたデコーダー
- qw2 (z|y): パラメータw2を持つ別のニューラルネットワークでパラメータ化されたエンコーダー
- c: クラス情報
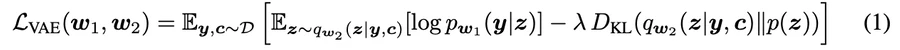
→以降 デコーダpw1 (y|z)は固定
2. 部分マスクy^で新しいエンコーダーqˆw3 (z|yˆ, c)のみを学習
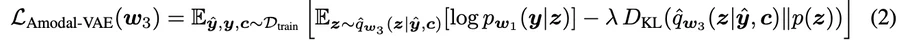
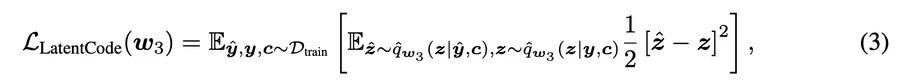
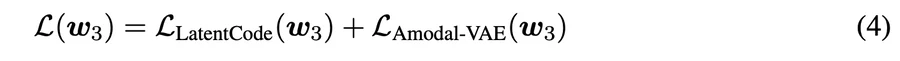
3. y^の部分マスクを用いてエンコーダを微調整
部分的に可視化されたマスクyˆに対して、その可視ピクセルをyˆ visとする
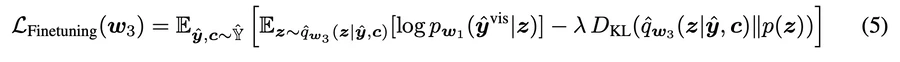
リサイズ
出力マスクは部分的な入力マスクと同じ縮尺ではない。
→アフィン変換で調整
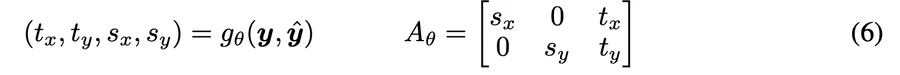
- gθ : ニューラルネットワーク→学習ステージ(2)と(3)でトレーニングされる。
- Aθ : yの各ピクセルに適用される2次元アフィン変換行列
どうやって有効だと検証した?
データセット
KINS : ストリートシーンデータセットKITTI から派生した大規模データセット
- インスタンスアノテーションとアモーダルアノテーションの両方を含む
- トレーニング用画像7,474枚、テスト用画像7,517枚
- トレーニング用完全インスタンス18,241、テスト用完全インスタンス17,646
→データセットをみないとわからない
→ トレーニングではインスタンスマスクのみを利用し、評価ではamodal ground truthラベルのみを利用する。

定量評価
- De-occlusion : 最先端Amodal補完モデル
→ 不可視領域のmIOUで5.66%、フルmIOUで0.64%上回った。 - Nearest Neighbor Mask : 部分マスクに対して、コサイン類似度が最も高い完全マスクを出力
- RGB-Amodal-VAE : 入力にRGB情報を追加
→ 性能がわずかに低下
→ より慎重に設計されたモデルアーキテクチャでは、RGB入力からより有用な情報を抽出できる可能性がありますが、これは今後の研究に委ねます。 - Amodal-VAE + GT Box : 部分マスクのBBoxでクロップしていたが、GTBoxによってクロップ
→ 入力されたマスクを自動的にうまく切り取ることで、改善の余地があることを示している。

定性評価

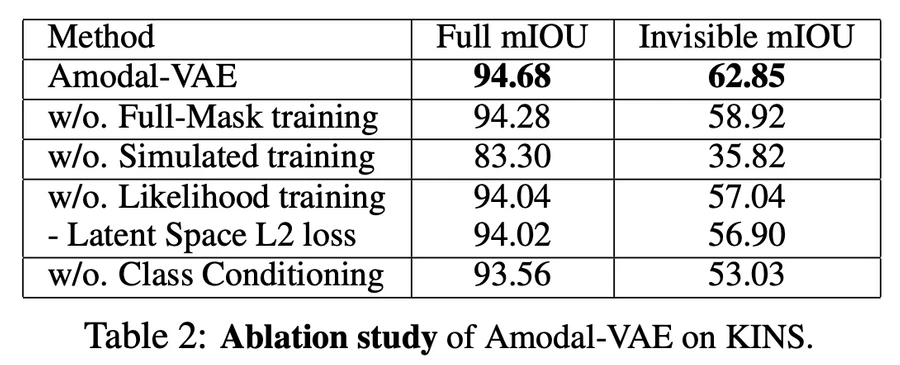
(その他)Ablation
(応用1)インスタンス補完
FID(↓)比較
- Amodal-VAE: 41.44
- De-occlusion: 50.36

(応用2)インスタンス姿勢変換

議論点は?
- 学習時に完全なマスクを持つ高品質なデータセットが必要であり、各カテゴリには十分な数のオブジェクトが含まれていなければならない。
→ このモデルを、より複雑なシーンやデータが限られている環境に適用することは、今後の課題とする。 - RGB-Amodal-VAEだと精度が下がる。
次に読むべき論文は?
Self-supervised scene de-occlusion(これ以前の最先端Amodal補完モデル)
→ グラフを用いてインスタンスを順序付けながらAmodal補完してそうhttps://arxiv.org/abs/2004.02788
→ 日本語まとめ [http://xpaperchallenge.org/cv/survey/cvpr2020_summaries/246/](http://xpaperchallenge.org/cv/survey/cvpr2020_summaries/246/