はじめに
今まで2次推論で分類モデルを使う場合、MobileNetV3 smallしか使っていなかったため、他に使用できそうな分類モデルがあるかを検証した。YOLOv8の分類モデルは学習も簡単にでき、組込みが可能なため(こちらの記事参照)、YOLOv8sとMobileNetv3 smallの精度と速度を比較した。
目的
人の顔画像から性別を推定するクラス分類モデルをYOLOv8sとMobileNetv3 smallを使用して作成し、精度とDeepStreamで動かした場合の速度を比較する。
環境
- Jetson Nano 4GB
- JetPack 4.5
- DeepStream SDK 5.1
学習条件
データセット
All Age Face Datasetを使用した。このデータセットには、2~80歳のアジア人の女性と男性の顔画像が含まれている。以下のように前処理と分割を行った。
- 自分で作成したYOLOv5s head検出モデルを使用して、頭部分をCROPした。
- 目で見て上手くCROPできていない画像を削除した。
- 性別、年代(10歳未満、10代、20代、30代、40代、50代、60歳以上)ごとの画像枚数を調べた。


- 年代ごとの画像枚数にばらつきがあったため、各年代415枚をランダムにサンプリングした。
- 各年代415枚をtrain: val: test = 7: 2: 1に分割した。
- 各年代のデータを性別ごとのフォルダにまとめた。
最終的な画像枚数は下記表の通り。
| split | gender | image num |
|---|---|---|
| train | female | 2037 |
| male | 2037 | |
| val | female | 581 |
| male | 581 | |
| test | female | 287 |
| male | 287 |
MobileNetv3 small
TensorFlowのMobileNetV3Smallを使用した。
| input size | batch size | epoch | pretrained model |
|---|---|---|---|
| 224 x 224 | 192 | 300 | ImageNet |
YOLOv8s
YOLOv8のリポジトリ(2023.07.17時点)を使用した。このリポジトリだと前処理で画像をリサイズする際にcenter cropしていたため、アスペクト比を維持したまま拡大縮小し、パディングするようにコードを修正した。また、学習時にaugmentationを行わないようにした(こちらのnotebook参照)。
| input size | batch size | epoch | pretrained model |
|---|---|---|---|
| 224 x 224 | 192 | 300 | ImageNet |
精度評価
正解率を指標として精度を比較した。精度はTensorFlowまたはPytorchモデルで評価した(こちらのnotebookを使用した)。
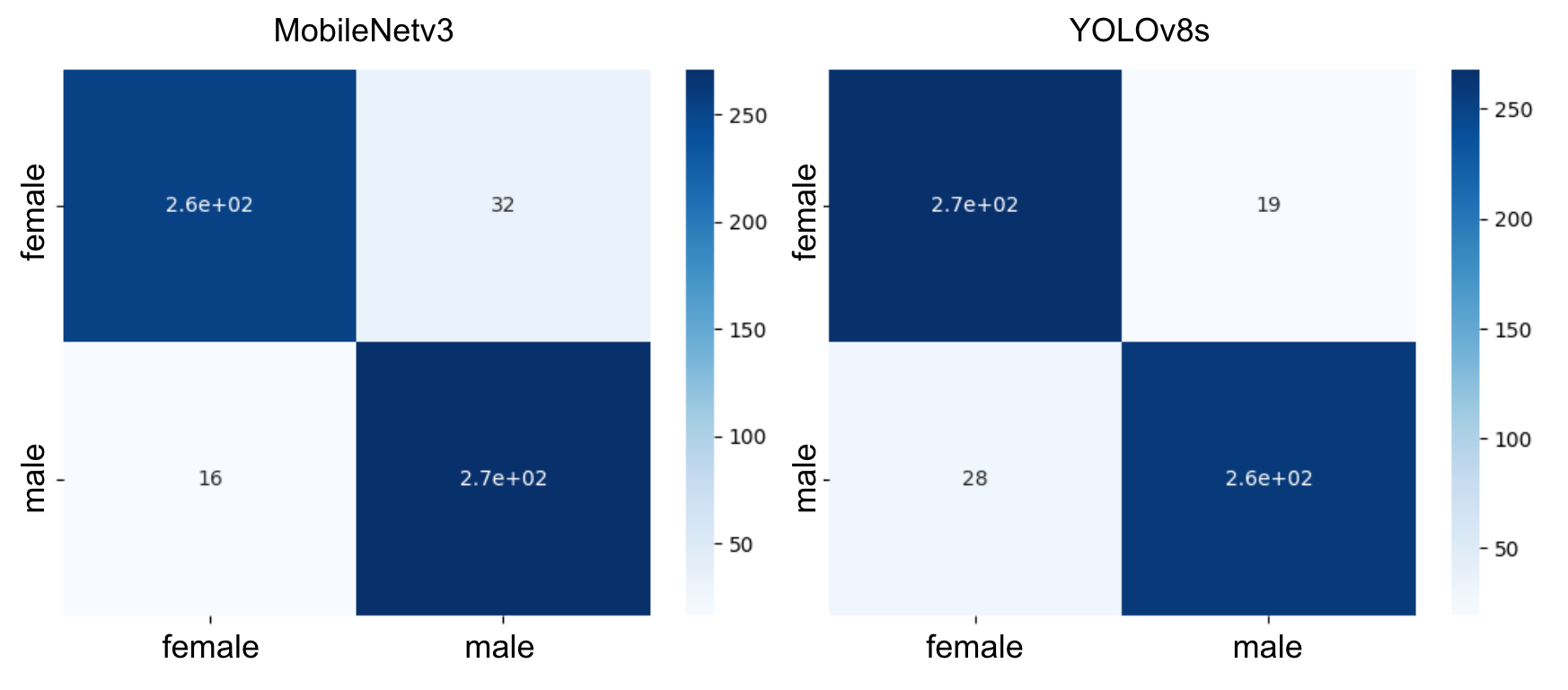
全テストデータに対する正解率は、MobileNetV3 smallよりもYOLOv8sの方が正解率が0.2%高かった。 MobileNetv3 smallではmaleの正解率の方が高かったが、YOLOv8sではfemaleの方が高かった。
正解率
| model | all | female | male |
|---|---|---|---|
| MobileNetv3 | 0.916 | 0.889 | 0.944 |
| YOLOv8s | 0.918 | 0.934 | 0.902 |
混同行列
推論速度比較
deepstream python のtest1, test2アプリを修正し、推論を行った。
1次推論モデルとした場合
以下のアプリを使用して推論を行った。
https://github.com/mihara-shoko/compare-MobileNetv3-YOLOv8/tree/main/deepstream-test1_gender
出力されたFPSの平均を求めた。
YOLOv8sのの方がFPSが高かったが、それほど差はなかった。
| Primary | FPS |
|---|---|
| MobileNetv3 small | 58.7 |
| YOLOv8s | 58.9 |
2次推論モデルとした場合
以下のアプリを使用して推論を行った。1次モデルとして自分で作成したYOLOv5sのhead検出モデルを使用した。
https://github.com/mihara-shoko/compare-MobileNetv3-YOLOv8/tree/main/deepstream-test2_gender
出力されたFPSの平均を求めた。
MobileNetv3 smallを2次推論モデルとして使用した場合の方がFPSが高かったが、それほど差はなかった。
| Primary | Tracker | Secondary | FPS |
|---|---|---|---|
| YOLOv5s(input size=416) | NvDCF | - | 19.9 |
| YOLOv5s(input size=416) | NvDCF | MobileNetv3 small | 19.9 |
| YOLOv5s(input size=416) | NvDCF | YOLOv8 s | 19.5 |
推論結果(YOLOv8s)

おわりに
精度と推論速度に大きな差はなかった。入力サイズが224 x 224と小さいため、差異が見られなかった可能性がある。YOLOv8の方が学習しやすいので、今後はYOLOv8を使ってみてもいいのではないかと思った。
参考サイト
- https://github.com/JingchunCheng/All-Age-Faces-Dataset
- https://www.tensorflow.org/api_docs/python/tf/keras/applications/MobileNetV3Small
- https://github.com/ultralytics/ultralytics
- https://forums.developer.nvidia.com/t/error-a-lot-of-buffers-are-being-dropped-when-running-ds-sdk-python-sample-ipcamera-on-nano/110886