注意事項
悪用厳禁!統計を取るような場所で使えばただのチートツールです!
目的
ひょんなことから職場でタイピングが流行っていたので、腕試しとpyautoguiの習得を兼ねて自動化させてみました。
自動化対象
大まかな方針
ベネッセのタイピング練習のサイト。キーボードの表記があり、外部に成績を送っていないため選定。サイトは下記のとおりです。
https://manabi-gakushu.benesse.ne.jp/gakushu/typing/nihongonyuryoku.html
UIは下記の感じになっています。
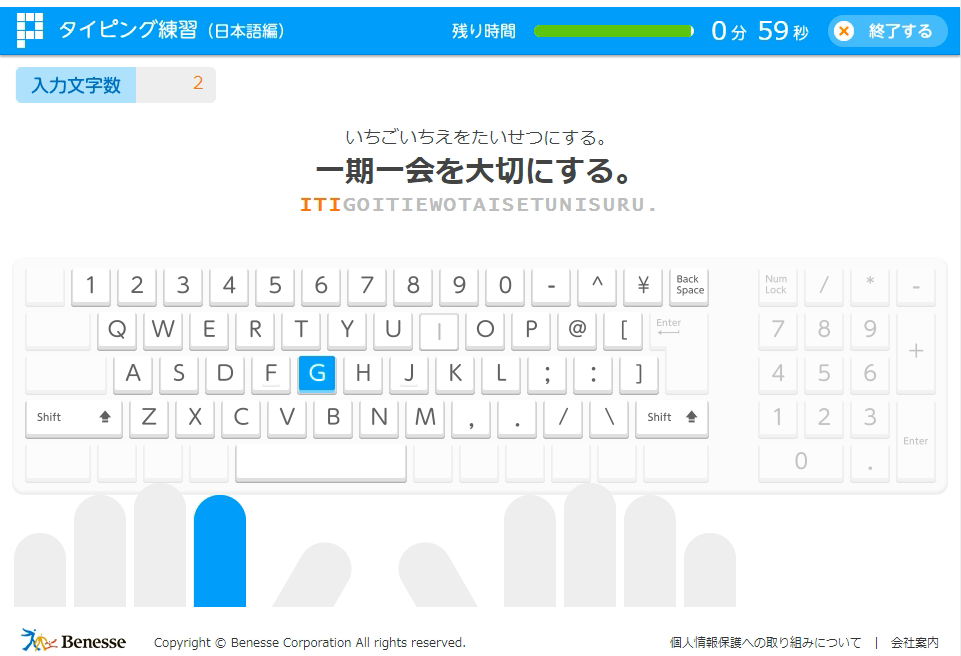
タイピングを自動化するのであれば、方法は3つ思いつく。
- 中央のローマ字をパターンマッチングで取得する。
- 下部のキーボードの部分を取得し、次にタイプするキーを取得する。
- 中央上のひらがなの部分をどうにかして入力キーに変換する。
今回はとりあえず形にするのが目的ということと、どの文字が使われているのかがわからないことからまずは画面下部のキーの画像から次のキーを読み取って打ち込めるようにする。
速度があまり出なければ高速化について考えよう。
画面の詳細な仕様
何度かタイピングを行いながら、画面のより詳細な仕様を確認した。
- キーを打った瞬間に前のキーは白に戻って次のキーが青く表示される。
- 左右のキーの間隔は固定されている。
- もちろん色も固定。
- P検のマークから画面のUIの位置は固定のようだ。
このことから、スクリーンショットを取れば次に打ち込むキーの情報が得られそうだ。
コード
キー検知部分
とりあえず、キーを検知する部分は下記の通り。
import numpy as np
import cv2
import pyautogui
tag_image = cv2.imread("position_tag.png")
_tag_position = None
KEY_Y_SPACE = 43
KEY_X_SPACE = 46
ROW_KEY_START_POSITION = \
((60, 258),
(85, 303),
(103, 346),
(118, 392))
KEYS = ("1234567890-^\\", "qwertyuiop@[", "asdfghjkl;:]", "zxcvbnm,./\\")
DEBUG = True
def get_screen():
pillow_image = pyautogui.screenshot()
np_image = np.asarray(pillow_image)
process_image = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR)
return process_image
def set_tag(screen=None, threshold=0.95):
if screen is None:
screen = get_screen()
match_result = cv2.matchTemplate(screen, tag_image, cv2.TM_CCOEFF_NORMED)
_, max_value, _, max_location = cv2.minMaxLoc(match_result)
global _tag_position
_tag_position = max_location if max_value >= threshold else None
return _tag_position
def get_tag_pos():
global _tag_position
if _tag_position is None:
set_tag()
print(f"tag:{_tag_position}")
return _tag_position
def get_key(screen=None):
if screen is None:
screen = get_screen()
for row_pos, key_value in zip(ROW_KEY_START_POSITION, KEYS):
check_pos = list(get_tag_pos())
check_pos[0] += row_pos[0]
check_pos[1] += row_pos[1]
for key in key_value:
check_color = screen[check_pos[1], check_pos[0]]
if check_color[0] > 240 and 170 > check_color[1] > 160 and 10 > check_color[2]:
return key
if DEBUG:
print(f"{key}:{check_color}")
check_pos[0] += KEY_X_SPACE
return " "
get_screenはpyautoguiでスクリーンショットをとり、numpyで読み込める形に直す関数。
OpenCVはpyautoguiの使っている画像ライブラリとはRGBの順番が違うらしいので注意。
set_tagやget_tag_posはロゴの位置を確認し、ウィンドウの位置を確定させるための関数。
OpenCVの画像を読み込ませてテストさせることも考え、引数に指定できるようにしておいた。
広い画面に対するパターンマッチとなるため、タグの識別の回数はなるべく減らしたいところ。
get_keyはどのキーが押されているかを確認するための関数。KEYSでキーボードの各行のキーを格納し、左から順番に確認することにより全部のキーの位置を調べなくても済むようにした。
なお、ROW_KEY_START_POSITIONはキーボードの各行の一番左にあるキーの色を判別する座標を格納してる。
文字出力部分
確認用のテストと実際のコードを兼ねているのが次のコード。
自動化に使うのはmain_loopの関数の部分。
先程のキー取得の部分で1文字のキーを返すようにしていたので、それをそのままpyautogui.pressに流すだけですんだ。
import keyreader as kr
import cv2
import pyautogui
WAIT_TIME = 1 / 100
def get_next_loop():
last_key = " "
kr.DEBUG = False
while True:
next_key = kr.get_key()
if next_key != " " and last_key != next_key:
last_key = next_key
print(next_key, end="")
pyautogui.sleep(0.001)
def main_loop():
kr.DEBUG = False
pyautogui.FAILSAFE = True
count = 0
while True:
key = kr.get_key()
if key != " ":
pyautogui.press(key)
count += 1
print(f"\r{count}", end="")
# pyautogui.sleep(WAIT_TIME)
def test_image(source_path):
image = cv2.imread(source_path)
kr.set_tag(image)
print(f"ans:{kr.get_key(image)}")
if __name__ == '__main__':
command = input("command > ")
if command == "c":
get_next_loop()
elif command == "t":
test_image("TestImages\\sampleimage.png")
elif command == "o":
print(f"ans:{kr.get_key()}")
elif command == "d":
main_loop()
実行結果
土日を使ってタイピングを自動化してみた。
— Mickie (@mickie_on_Paper) February 21, 2021
※このタイピングサイトは統計を取らないことを確認しています。ランキングなどの統計を取るようなサイトでは使わないようにしましょう。 pic.twitter.com/AUIBcBCFod
いかにも機械がやっていますって感じのものが出来上がった。自分の実力が20点/160文字前後なので1.5倍の速度が出るようになった。
ただ、予想してたよりかなり遅かったので、他の方法も合わせて高速化できないか考えてみることにする。
まずは文字をパターンマッチさせた場合との速度比較だな。