読んだ論文
Cheng, Heng-Tze, et al, Wide & Deep Learning for Recommender Systems, Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, 2016
Link: https://arxiv.org/pdf/1606.07792.pdf
TL;DR
アイテム同士の共起性とアイテムの属性の両方を用いてレコメンドしたい
この手法のやりたきこと
- 既知の(よくある)組み合わせに基づいたレコメンド
- アイテムの属性に関する類似度を用いたレコメンド
仕組み
WideパートとDeepパートという二つの部分から以下のように構成されている(元論文p.2より)
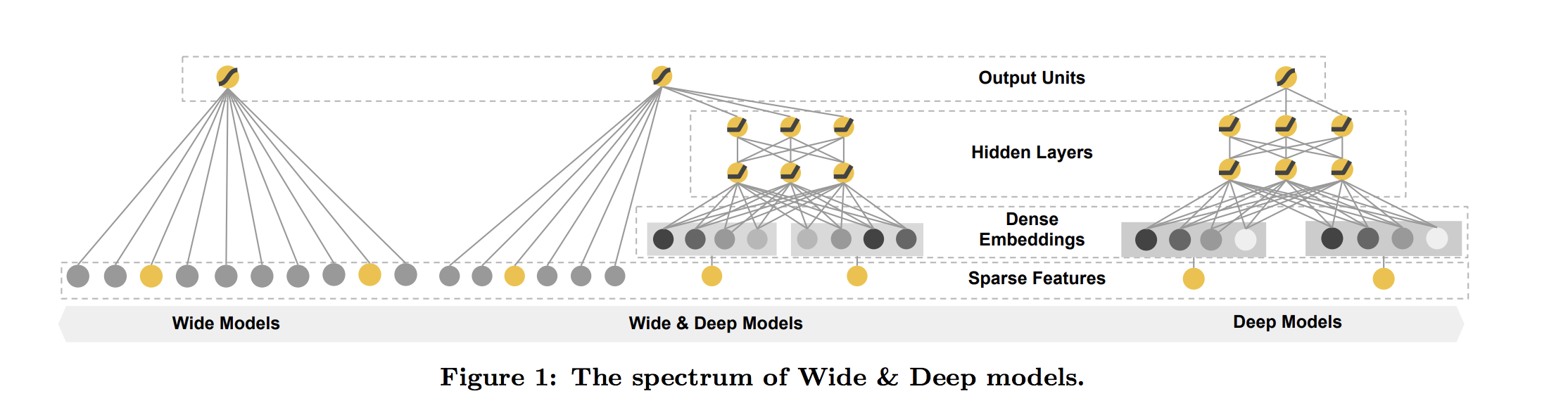
Wideパート
アイテムに対するsparseな特徴量をcross product transformしそれを入力として扱う。
Wideパートだけの出力を考えると以下のように定式化される。
y = w^T \phi_k (\boldsymbol{x}) + b \\
where \ \phi_k (\boldsymbol{x}) = \Pi_{i=1}^d x_i^{c_{k,i}}
ただしそれぞれ定義は以下の通り
- $k$ ... transformationのid
- $c_{k,i}$ ... $i$番目の特徴量が$k$番目のtransformationに含まれれば1,そうでなければ0をとる変数
- $d$ ... 特徴量$\boldsymbol{x}$の次元
つまりuser=hogehoge, item=fugafugaが一致したときだけ値が入るような部分。
Deepパート
アイテム(など)の属性をEmbeddingしたものを用いた部分。通常のNNにおけるEmbeddingとやってることは同じ。
一応定式化すると以下の通り
a^{(l+1)} = \boldsymbol{W}^{(l)}a^{(l)} + b^{(l)}
ただし
- $l$ ... レイヤの層
- $\boldsymbol{W}$ ... 重み
- $a$ ... 活性化関数
- $b$ ... バイアス
WideパートとDeepパートそれぞれの長所
WideパートとDeepパートのそれぞれの長所は以下の通り
- Wideパートの長所: 協調フィルタリングなどで用いられている「似た趣向の持ち主に対してレコメンド」ができる
- Deepパートの長所: アイテム自体の属性を用いることで似たような別のアイテムを特定できる
Wideパートがいわばよくあるレコメンド的な側面に基づく学習で、Deepパートでアイテムをもう少し一般化して学習する、みたいな印象(だと私は理解した/Google AI Blogのこの記述が直感的にわかりやすい)。
しかし論文によるとこの手法のメインはDeepパートであり、Wideパートはあくまで補助的なものだとのこと1。
こういった都合からこの後の実装でもcross product transformationのサイズはあまり大きくしていない(ここは問題に応じてきちんと検討した方がよいのではと個人的には思っている)。
実装
TensorFlowのEstimator APIを用いて実装。2
モデル作成上変更が必須な点のみ記載。
使用するデータセットはMovieLens20M。
コード全体はこちらのGitHubリポジトリにアップしている。
ライブラリのインポート
今回使うライブラリは以下の通り。
この記事ではあまり出てこないが細かい設定にはConfigParserを用いている
import itertools
from time import strftime, gmtime
from configparser import ConfigParser
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import accuracy_score, roc_auc_score
データの準備
カラムの定義は以下の通り
HEADER = ['user_id', 'item_id', 'rating']
HEADER_DEFAULTS = [['0'], ['0'], ['0']]
FEATURE_NAMES = ['user_id', 'item_id']
CATEGORICAL_FEATURE_NAMES_WITH_BUCKET_SIZE = {
'user_id': int(config['model']['user_bucket_size']),
'item_id' : int(config['model']['item_bucket_size'])
}
USED_FEATURE_NAMES = ['user_id', 'item_id', 'rating']
CATEGORICAL_FEATURE_NAMES = list(CATEGORICAL_FEATURE_NAMES_WITH_BUCKET_SIZE.keys())
TARGET = 'rating'
TARGET_LABELS = ['0','1']
特徴量のデータ型定義
wide_feature_dim = int(config['model']['wide_feature_dim'])
user_embedding_dim = int(config['model']['user_embedding_dim'])
item_embedding_dim = int(config['model']['item_embedding_dim'])
categorical_hash_user = \
tf.feature_column.categorical_column_with_hash_bucket('user_id', CATEGORICAL_FEATURE_NAMES_WITH_BUCKET_SIZE['user_id'])
categorical_hash_item = \
tf.feature_column.categorical_column_with_hash_bucket('item_id', CATEGORICAL_FEATURE_NAMES_WITH_BUCKET_SIZE['item_id'])
# cross product transformationの部分
categorical_feature_user_x_categorical_feature_item = tf.feature_column.crossed_column(['user_id', 'item_id'], wide_feature_dim)
# deepパートに使用するEmbedding部分
categorical_feature_user_emb = tf.feature_column.embedding_column(
categorical_column=categorical_hash_user, dimension=user_embedding_dim)
categorical_feature_item_emb = tf.feature_column.embedding_column(
categorical_column=categorical_hash_item, dimension=item_embedding_dim)
# Estimatorに渡すのは以下の二つ
wide_feature_columns = [categorical_feature_user_x_categorical_feature_item]
deep_feature_columns = [categorical_feature_user_emb, categorical_feature_item_emb]
もろもろの設定とともにEstimator作成。
Estimator APIにはWide and DeepモデルがPremade Estimatorであるtf.estimator.DNNLinearCombinedClassifierが用意されているためそれを使用。
先ほど特徴量のデータ型定義でdnn_feature_columnsとwide_feature_columnsを分けて定義していたのはここでの入力のため。
dropout_prob = float(config['model']['dropout_prob'])
hidden_units = [128, 64, 32]
estimator = tf.estimator.DNNLinearCombinedClassifier(
n_classes=len(TARGET_LABELS),
label_vocabulary=TARGET_LABELS,
dnn_feature_columns=deep_feature_columns,
linear_feature_columns=wide_feature_columns,
dnn_hidden_units=hidden_units,
dnn_optimizer=tf.train.AdamOptimizer(),
dnn_activation_fn=tf.nn.relu,
dnn_dropout=dropout_prob,
model_dir=model_dir,
config= run_config
)
学習〜評価まで
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
predict_input_fn = lambda: csv_input_fn(config=config,
phase='predict',
mode=tf.estimator.ModeKeys.PREDICT)
predictions = estimator.predict(input_fn=predict_input_fn)
values = list(map(lambda item: item["logistic"][0],list(itertools.islice(predictions, test_size))))
test_data = pd.read_csv(config['test']['filename_pattern'])
test_value = np.array(test_data.iloc[:,2])
pred_value = np.array(values)
pred_value_binary = np.round(pred_value)
auc = roc_auc_score(test_value, pred_value)
accuracy = accuracy_score(test_value, pred_value_binary)
print('AUC: {:.4f}\nAccuracy: {:.4f}'.format(auc, accuracy))
評価
今回以下の5つのパラメータを以下のような組み合わせで試した
* user,itemそれぞれにbucket_sizeとemb_dimがあるが今回揃えている。
user_bucket_size, item_bucket_size: {100, 1000, 10000}
user_embedding_dim, item_embedding_dim: {128, 256}
wide_feature_dim: {50000, 100000}
なおDeepパートのDense層は[128, 64, 32]の3層でDropout rateは0.3に固定している。
それぞれの結果(Accuracy)は以下の通り
wide_feature_dim = 50000の場合
| bucket_size=100 | bucket_size=1000 | bucket_size=10000 | bucket_size=20000 | |
|---|---|---|---|---|
| emb_dim=128 | 0.5341 | 0.5943 | 0.6986 | 0.7172 |
| emb_dim=256 | 0.5316 | 0.5947 | 0.6996 | 0.7176 |
wide_feature_dim = 100000の場合
| bucket_size=100 | bucket_size=1000 | bucket_size=10000 | bucket_size=20000 | |
|---|---|---|---|---|
| emb_dim=128 | 0.5315 | 0.5945 | 0.6991 | 0.7167 |
| emb_dim=256 | 0.5314 | 0.5948 | 0.6998 | 0.7165 |
うーん他の特徴量入れてない状態だと素のFMに負けてしまっている。
特徴量自体の属性よりは交差項が重要ということなのだろうか...もう少し実験してみよう。
ちなみにWide and Deepに関してはAUCも出しているのだがAUCはAccuracyに比べて0.03~0.05程度高い傾向にあった。
ということで以上。お粗末!
参考リンク
Wide & Deep Learning: Better Together with TensorFlow - Google AI Blog
-
p.3にて'..., for joint training the wide part only needs to complement the weak-nesses of the deep part with a small number of cross-product feature transformations, rather than a full-size wide model'という説明がされている。 ↩
-
Estimator APIの大まかな使い方はこちらの記事参照(といっても手前味噌だが)。もう少しきちんとした説明が必要な場合はこちらの公式チュートリアルも参照(ただし一部TF2.0に対応できない記述もあるので注意)。 ↩