データ基盤 Advent Calendar 202012月22日の記事です。
TL;DR
- 複数のデータ形式を変換する基盤の開発について個人的な振り返りをした
- 設計時にはわからないこともあるので、開発していく中でお客への確認・認識合わせを根気よくやっていく必要あり
- 実行フローの開発部分は早めに共通化しておいたほうがよい
0. 設定説明
0.1 複数のデータ形式を扱う、とは
自分が携わっているサービスではお客から預かったデータをサービス用の統一フォーマットに変換し、アプリケーションを通じて提供している。
ざっくりデータ基盤のフローを書くと以下のようになる。
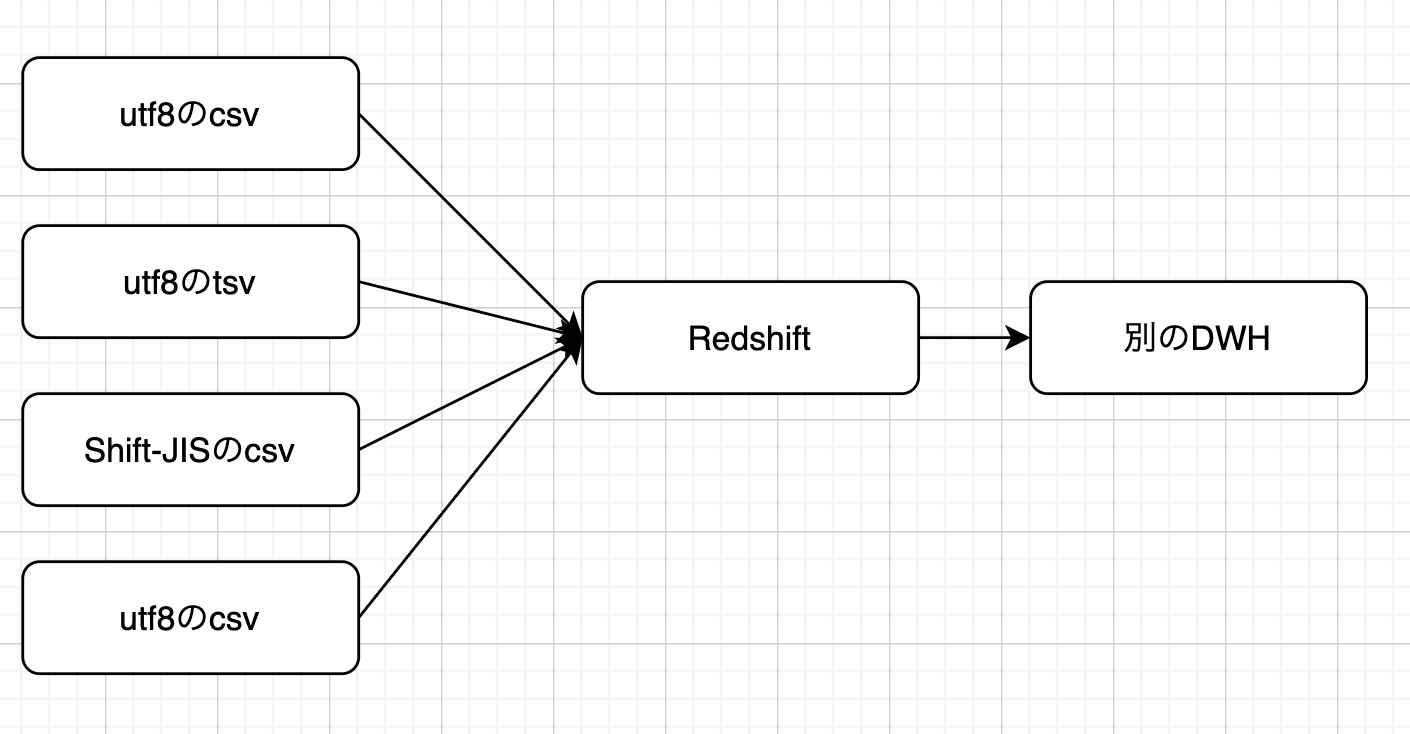
上記フローからも分かる通りデータフォーマット(csvかtsvか)や文字コード(utf-8かShift-JISか)がお客によって異なっている。
また形式だけではなくカラム構成や定義もお客によって異なるため、ファイルごとに処理を変えなくてはいけない。
この記事ではこのように「複数のフォーマットを統一的な形式」へ変換するとき開発部分でどのあたりに気をつけたのかを、個人的に振り返り書いていく。
そもそも形式を統一すればよいのでは?
このような形態の場合真っ先に来る質問は「お客から連携されるデータ形式を統一すればよいのでは?」というものだが、もちろんこれが理想である。
そうすると「お客に指定された形式でデータを連携するよう要請できるのか?」という話になるが、実際問題難しいことが多い。
難しい問題は色々あるが、特に問題となるのは「指定された形式に変換する作業がお客側で発生するとそもそもサービスを継続して使えないのでは?」という部分だと自分は感じている。
このあたりの問題をクリアして統一の形式でデータもらえるような良い仕組みがあれば知りたい。
0.2 開発フロー
開発にて発生する各種工程は以下の通り
- 要件定義: お客のデータをどのように変換するか設計
- 処理作成: 設計に基づき変換処理を作成
- データチェック: 変換処理の結果出力される数字感のチェック
- フロー作成: 日々の運用に載せるためのパイプラインを作成
- テスト: パイプラインが適切に回るかをチェック
処理作成〜フロー作成のところは厳密にこの順序になるというわけではない(ケースバイケースである)。
筆者が関わっていたのは処理作成以降の工程であるため、本記事では上記フローの順番で処理作成以降の部分について述べる
1. フローごとの振り返り
1.1 処理作成
要件定義で上がってきた設計に基づき変換スクリプトを組んでいく工程。
必ずしも設計通りの処理を組めないことがあるので、やっていく中で生じた不都合は設計者・お客へ都度確認していく必要がある。
設計通りの処理を組めない例としては例えば以下のようなものがある
- 「売上」というカラムで集計しようとしたところ、本番のデータには円マークが入っていた
- 商品マスタのPKとして指定されたカラムが、本番データの場合PKになっていなかった
上記の通り、設計段階でつかっていたサンプルデータだけではわからず開発に使っているデータ(≒本番データ)をみて初めてわかることも多い。
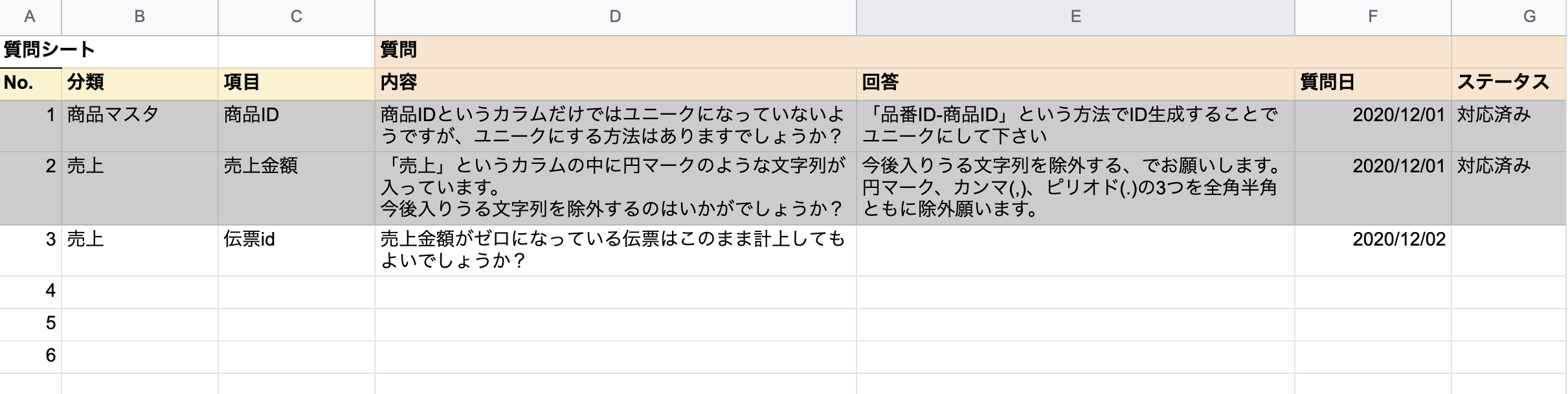
また生じた疑問はどこかにまとめておくのがベター(slackとかだと流れていってしまう)。
Issueだと起票する手間が大きくなりすぎるため、スプレッドシートに質問を記載するようにした(以下の画像は使っていたフォーマットの見本)
ドキュメントは重要
当たり前な話だが、お客と握った設計はきちんとドキュメントに起こしておくことが重要である。
導入するお客が増えるほどドキュメントの数も増えていくので、ドキュメントの形式(大枠)は早いうちに整えておいたほうがよい。
またサービス初期段階の場合、どんなものであってもよいからある程度の形式を作成してしまって、それをもとに一度業務をまわすのがよいと感じた。
統一的な形式のドキュメントがあるとないとではやはり開発のしやすさが格段に変わったというのがその理由。
仮に不都合があったとしても適宜フィードバックしていくことで双方にとって使いやすいものに改善できる。
1.2 データチェック
この工程では設計通りに組んだ処理がお客の想定通りのものになっているかを確認する。
設計通り実装したとしても、「処理自体は動くが出てきた数字が思っていたものと違う」となることは結構な割合で起こる。
本番稼働してから数字を直すのはかなり手間なので、早い段階でお客と数字感の認識をあわせることが重要。
「お客と数字感の認識をあわせる」と書いたのは、データを提供するお客の側でも認識していなかった仕様があったりする都合上、設計自体の確認をするよりかは実際の数字感をみてもらったほうが信頼性があるということが背景にある。
(※念の為補足するとお客が悪いという話ではない。どうしても起こり得る話だ、という意味。)
数字感のところの精度は提供するサービス次第でチェックの基準を緩くできる部分と感じる。
弊PJは性質上だいたいの数字があっていればよい(一の位の精度まではあまりみない)が、会計サービスみたく細かい桁も合わせなくてはいけない場合はかなり気を使うと思われる。
1.3 フロー作成
お客から提供されるファイル数が異なると定期実行のフローも異なってしまう。
しかし「フローを構築するところ」自体は共通化できる作業なので、早いところ共通化してしまうのがよい。
弊PJの場合AWS Data Pipelineを用いてフローを組んでいた1が、フローを作るところのGUI作業が正直手間で、このままスケールするにはこの工程がネックになると感じていた。
このように手作業が発生する部分については早いうちに手作業が減るようなツールを導入し、作業時間の短縮を試みたほうがよい。
(AWS Data Pipelineの場合Dataductというツールがあるが、弊PJでは社内ツール2で対応した)
1.4 テスト
ここでいうテストは「日々のデータ連携がうまくいくか」を主眼においたもの。
数字感や個々の処理についてはこれまでのフェーズで確認をできたものの、日々の更新がうまくいくかもリリース前にみておく必要がある。
この段階のテストで失敗する例としては
- 以前投入したものの打ち消しレコードを投入したはずが、うまく打ち消しされていない(設計の問題)
- 差分更新の処理がうまくいっていない(開発の問題)
といったものが挙げられる。
個人的な所感では2割ぐらいの案件がこのフェーズでエラー検知される。
このテストはいわゆる結合テストに近いものなので、テストするのもテスト失敗してからやり直すのも少々面倒。
前の工程でデータチェックをしておくことでテストする手間が減るので、この段階ではあくまで差分更新のテストだけに集中できるような状態にしておきたい。
全体を通して補足
基本的に設計や数字感の確認のためお客とのコミュニケーションが欠かせない。
ビジネス層のメンバーがコミュニケーションを取ってくれる場合、開発者-ビジネス層メンバーのコミュニケーションを円滑にすすめることも重要。
個人的には日頃から使う単語を揃えたりつらみポイントを共有したりすると話しやすいと感じた3。
2. 課題
個人的に課題と感じていることを箇条書きする
- フローの変更や削除が容易にできるような実行フロー作成処理にできるとよい(AWS Data Pipeline ではそこが面倒だった)
- 数字感のテストをもっと自動化したい
- そもそも処理作成のところももっと自動化(型化)したい
弊 PJ は開発初期(っぽい)フェーズにいることもあり当時はあまり共通化に意識を向けていなかったが、どこまで共通化できるかの見通しを当時の時点でもたてられたかイマイチ検討がついていない。
おわりに
急遽テーマを変えたため(脚注 2 参照)まとまりのない記事になってしまったが、ご容赦頂きたい。
運用していく中で感じたこともあるので、どこかのタイミングでまとめたい。