こんにちは、NECの入江です。NEC デジタルテクノロジー開発研究所 Advent Calendar 2023の14日目として本記事を執筆しております。
私は普段、模倣学習を用いた技術や、最近はLLM関連の応用研究などを行っています。よって今回は、模倣学習って何だ?という所から、代表手法や直近の話題について、今回は数式を省いて簡単にご紹介していこうと思います。
模倣学習とは?
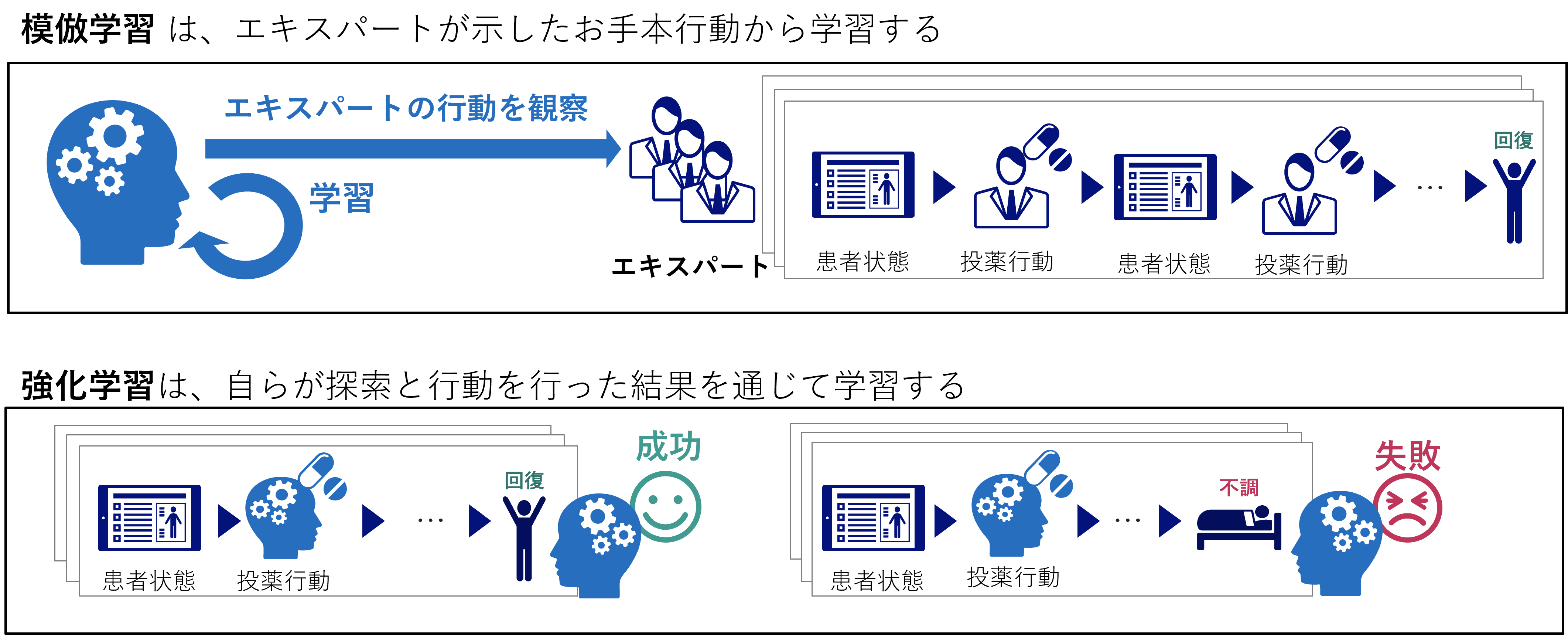
模倣学習とは、簡単に言うと強化学習と同じ問題をお手本の行動を用いて学習する手法です。
強化学習は、環境の中で自らが探索を行い失敗と成功を繰り返しながら最適な行動を学習します。
強化学習といえばロボットやゲームなどにおいて利用されるイメージが強いと思います。というのも、強化学習では何度も失敗を繰り返しながらモデルを学習させる必要があるため、仮想的に構築したシミュレーション環境のような何度も失敗が許されるような環境を用意しなくてはなりません。
そのため、医療の現場において患者の状態に合わせた最適な治療の行動方策を強化学習で学習できないか?と考えたとしても、当然ですが探索のために治療を失敗するわけにはいきません。このように現実的な場面では、失敗が許されないことが多いです。
そこで、お手本となる行動を与えて学習させる手法が模倣学習になります。模倣学習は問題設定は強化学習と同じになりますが、探索して報酬が最大となる行動を学習する強化学習のやり方とは異なり、教師あり学習のように学習します。
シンプルな学習のやり方としては、お手本中にある状態を入力、行動を出力として教師あり学習で学習するBehavior Cloning(BC)があります。しかしながら、一般的に模倣学習で取り組むタスクは、多数の状態数に対して限られたお手本データ数で学習しなければならないため、BCでは学習したデータ分布外の状態に対して行動の予測が難しい、分布シフトと呼ばれる問題に苦しむことが多いです。
代表手法 - GAIL
模倣学習の手法の中でも代表的な手法としては、GAIL(Generative Adversarial Imitation Learning)が挙げられます。GAILは2016年のNIPSで発表された論文手法ですが、執筆時点でもよくベンチマークで比較されるような代表手法になります。
Generative Adversarial Imitation Learning, 2016
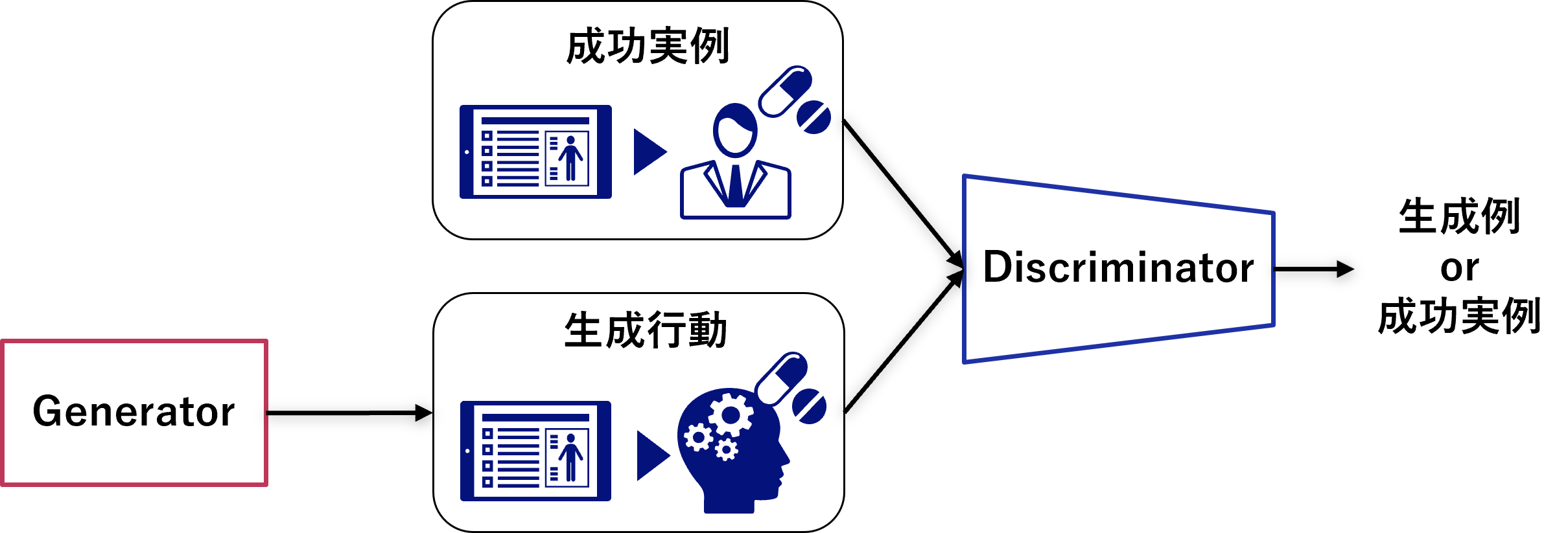
GAILはGAN(Generative Adversarial Network)のように、お手本となる成功事例データを模倣して行動を生成するGeneratorと、成功実事例データと生成例データを見分けるDiscriminatorを敵対的に学習させます。すなわち、GeneratorはDiscriminatorを欺くようなお手本そっくりのデータを生成するように学習することで、高精度な模倣データを作り出すことができます。
NEC技術
私たちNECではこのGAILの手法をベースとして、模倣させたくない失敗行動例のデータからも反面教師的に学習することで、成功事例の行動をより精度よく模倣する手法を開発しました。
AIで熟練者の暗黙知を形式知へ行動模倣学習技術
GAILのモデルアーキテクチャをベースに、成功事例か失敗事例かを見分けるClassifierを追加導入しています。
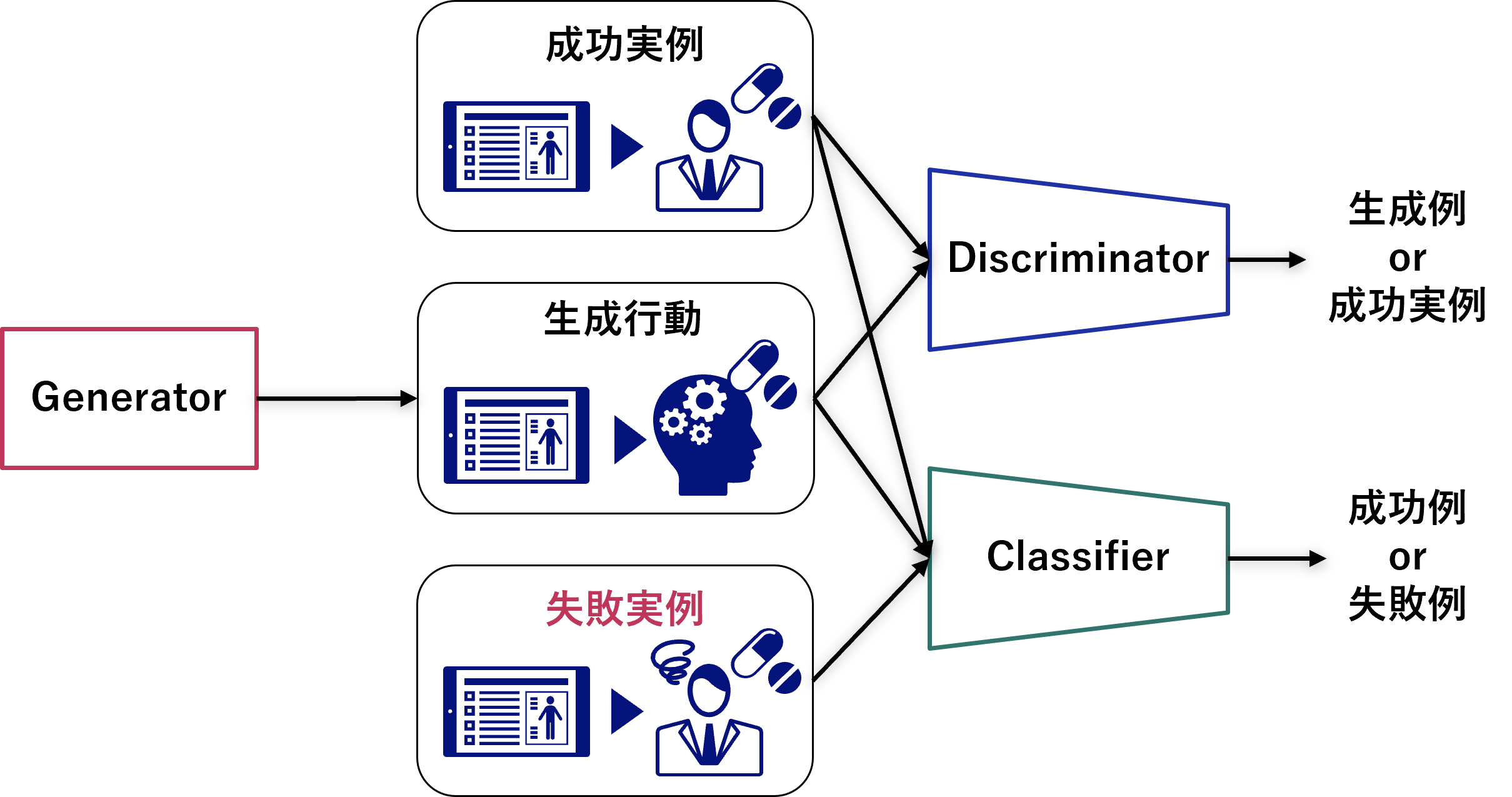
Generatorは成功事例に近い行動を生成するようにClassifierと協調的に学習することから、敵対的に学習するDiscriminatorと合わせて敵対的協調模倣学習と呼んでいます。私たちはこの敵対的協調模倣学習の技術を用いて、医療の分野などで実証検証を行っています。
最近の話題 - 模倣学習×LLM
最後に直近話題として、著しく発展しているLLM×模倣学習の論文 について少し紹介したいと思います。
Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning, 2023
動作を指示するコマンドを入力し、そのコマンドの指示通りにロボットが動作するようなタスクを模倣学習によって実現するのが目的です。教師データにはロボットの動作と、ラベルとしてその動作を指示するコマンドテキストが用いられます。コマンドテキストをプロンプトとしてLLMに入力し、動作の指示をプランニングさせることで、Zero-shot学習が可能になります。
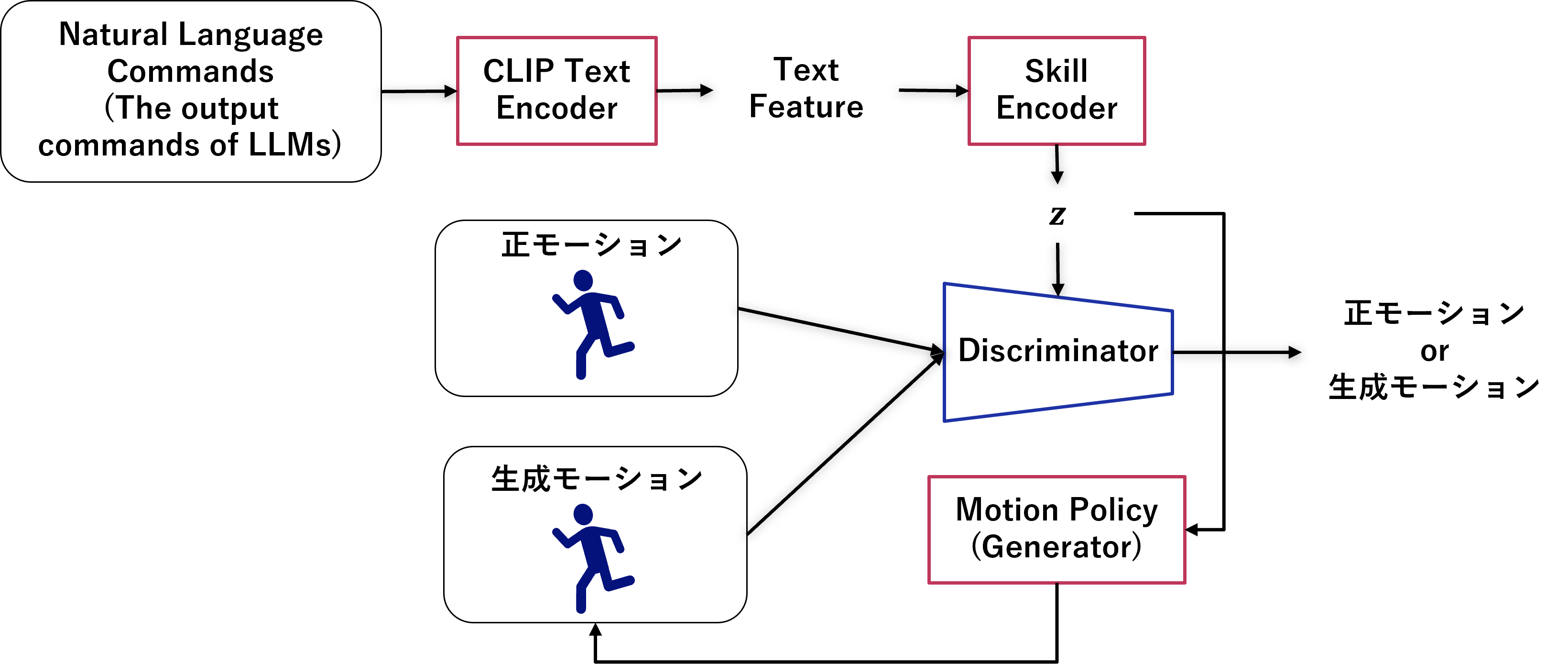
図のように、模倣学習には上記のGAILのフレームワークを採用しています。
学習の流れとしては、まずコマンドテキストをエンコードしていき、スキルと呼ばれる潜在変数zに変換します。このzをGeneratorとみなせるMotion Poilicyに入力し、ロボットの動作を生成します。そして、zを入力した時(=コマンドを前提した時)の生成した動作と正しい動作をdiscriminatorに見分けさせ、GAILと同様に敵対的に学習していきます。実際には、Motion Policyは上記のdiscriminatorに見分けられなかったことによる報酬+生成動作とお手本動作のベクトルの一致度に応じた報酬によって学習します。
まとめ
本稿では、代表手法であるGAILを中心に、模倣学習の紹介をさせていただきました。
AIの分野においてLLM絡みの研究が急加速していますが、模倣学習もLLMと組み合わせた手法が今後増えていきそうです。
私たちも新しい模倣学習技術を応用し、より高性能で幅広い適応が可能な熟練者行動の模倣AIの開発を進めていこうと思います。