動機
AI Dynamics Japan では、様々な物体検知アルゴリズム(画像・映像の中から対象物の位置を特定する技術)をAIや画像処理技術を使って実現していますが、案件の中には、通常の画像からでは人間ですら認識できないようなケースというものがあります。そのような場合に自分達は「Third Eye(第3の眼)」と称して1 特殊なセンシング技術を用いて課題解決することがあります。今回はその中でも「深度センサー」を使って物体検知・差分検知する方法をご紹介したいと思います。
LiDARセンサー(Intel® RealSense™)
LiDAR(Light Detection and Ranging)は、センサーからレーザー光を物体に対して照射し、その反射光を観測することで物体との距離を測定する技術です。今回は Intel®製 RealSense™ シリーズの Lidar Camera L515 を使用しました。

(画像引用元:Intel®製 RealSense™ シリーズ)
Intel® RealSense™ SDK 2.0 をインストールし、PCと L515 センサーをUSB接続2、RealSense™ Viewer を起動すればセンサー画像をすぐに確認することができます。2Dビューだと深度カラー・赤外線・RGBの3種類の画像が表示されます。
3Dビューに切り替えると、深度情報をもとにRGB画像が立体で表示されます。面白いとは思いますが、実運用上の使用用途は今のところ??ですね。参考まで。
SDKインストール・サンプルコード
LiDARセンサー情報を駆使してより柔軟なアプリケーションを作成する場合、Viewer でなくプログラムから操作できたほうが良いので、Python によるプログラミング方法を紹介します。
Realsense SDK を Python から扱いたい場合、パッケージのインストールは pip コマンド一発で完了です。簡単でいいですね。
pip install pyrealsense2
その他、処理結果描画のために OpenCV を別途インストールしています。
今回は以下のようなPythonコードを用意し、動作させてみました。
import pyrealsense2 as rs
import numpy as np
import cv2
# 深度画像、RGB画像の設定
# ※型番によって設定できる解像度が異なるので注意
pipeline = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30)
# 動画保存設定
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer_depth = cv2.VideoWriter('./depth.mp4', fourcc, 30, (640, 480), True)
writer_color = cv2.VideoWriter('./color.mp4', fourcc, 30, (640, 480), True)
# 深度閾値設定
range_min = 2.0
range_max = 4.0
try:
# ストリーミング開始
profile = pipeline.start(config)
while True:
# 画像の取得
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
if not depth_frame or not color_frame:
continue
# 後処理
depth_image = np.asanyarray(depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
depth_image = cv2.resize(depth_image, (640, 480))
color_image = cv2.resize(color_image, (640, 480))
# 深度画像の場合は閾値範囲のみ表示、カラーマップを適用
depth_scale = profile.get_device().first_depth_sensor().get_depth_scale()
depth = depth_image.astype(np.float64) * depth_scale
depth = np.where((depth > range_min) & (depth < range_max), depth - range_min, 0)
depth = depth * ( 255 / (range_max - range_min) )
depth = depth.astype(np.uint8)
depth_colormap = cv2.applyColorMap(depth, cv2.COLORMAP_JET)
# 表示
images = np.hstack((color_image, depth_colormap))
cv2.namedWindow('RealSense Demo', cv2.WINDOW_AUTOSIZE)
cv2.imshow('RealSense Demo', images)
# 動画保存
writer_depth.write(depth_colormap)
writer_color.write(color_image)
# Q押下で停止
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
finally:
# ストリーミング停止
pipeline.stop()
実行結果
左上:元画像
左下:深度センサー出力結果
右上:RGB値による差分検知プログラムによる処理結果(参考)
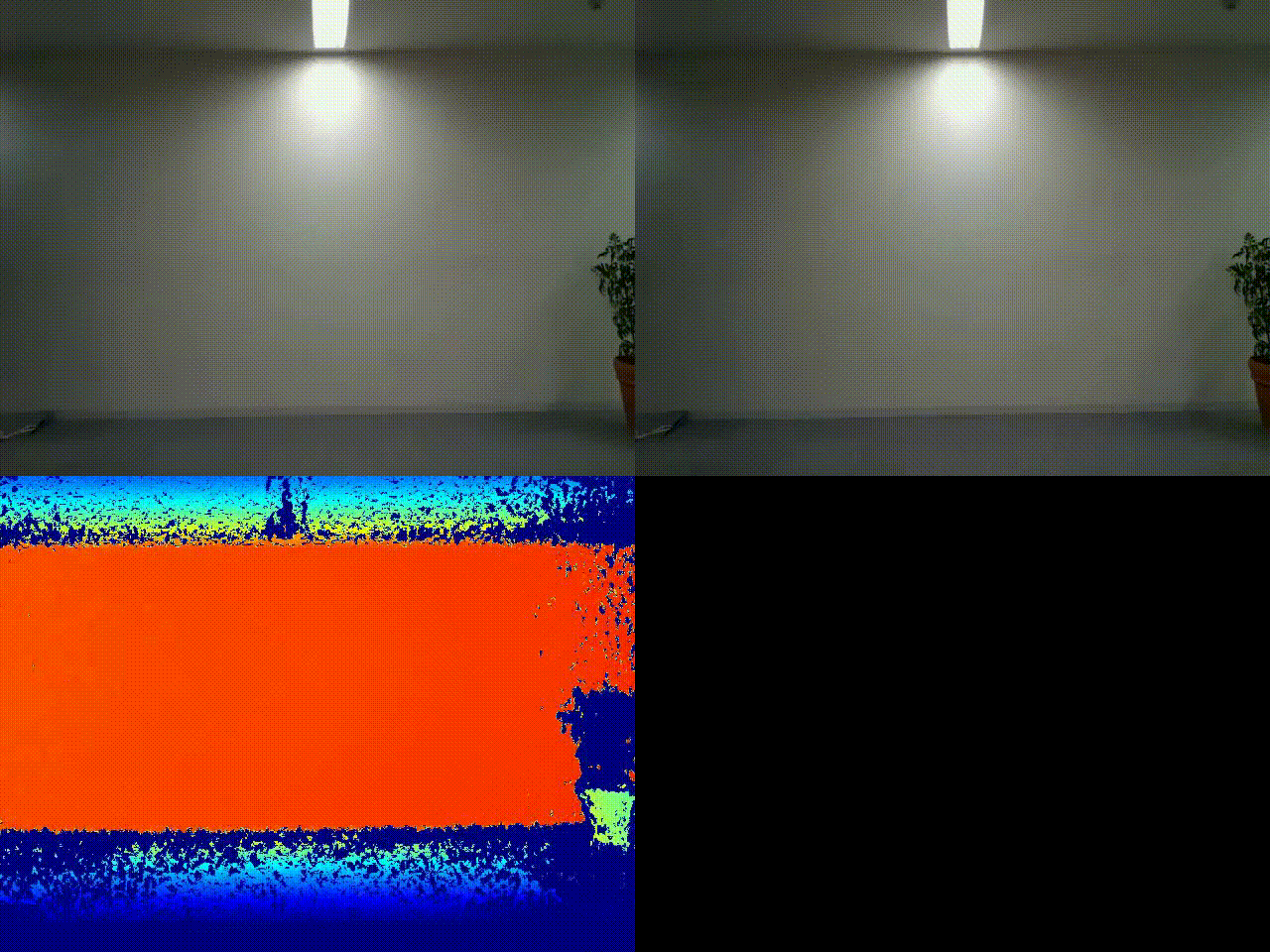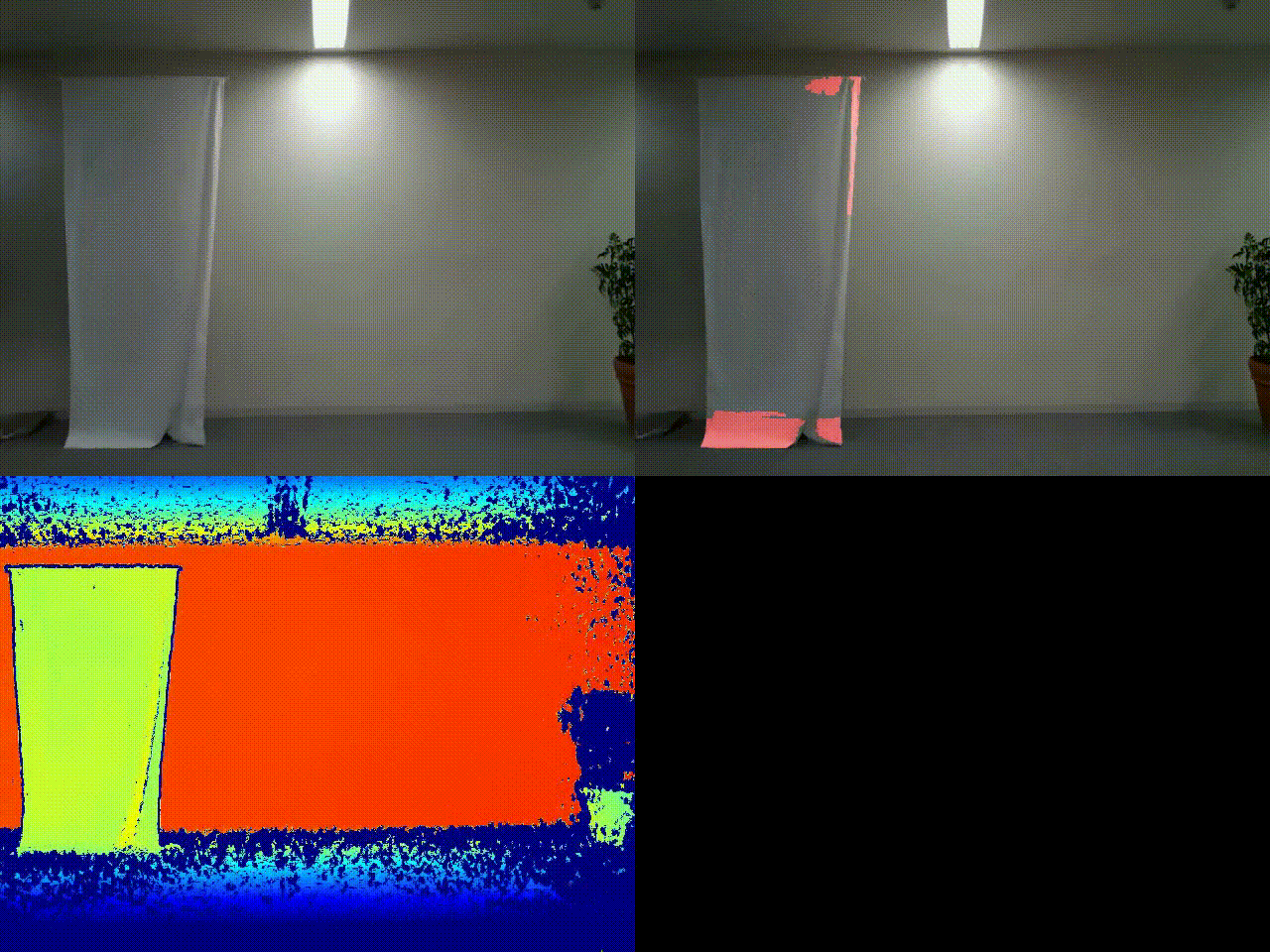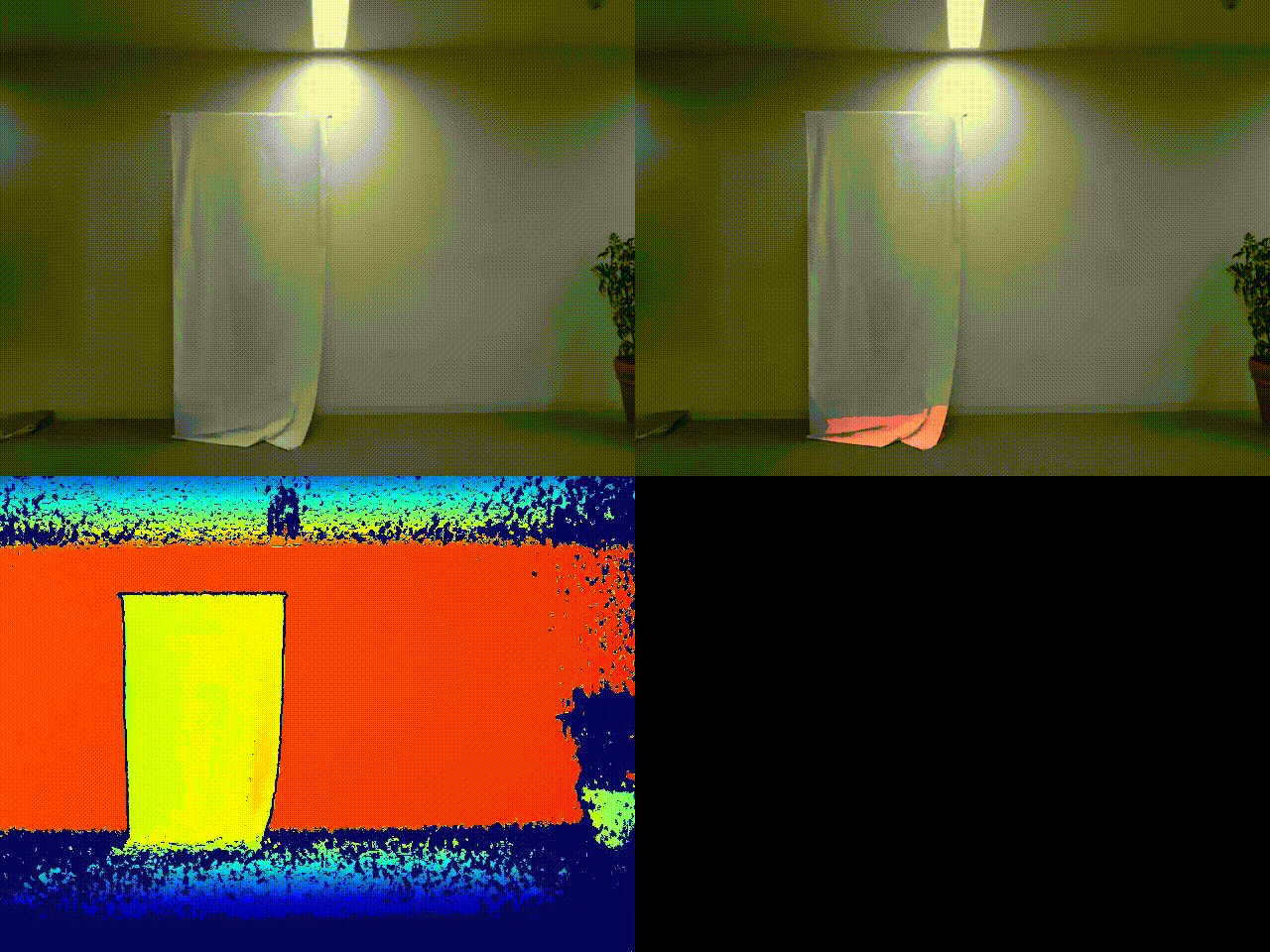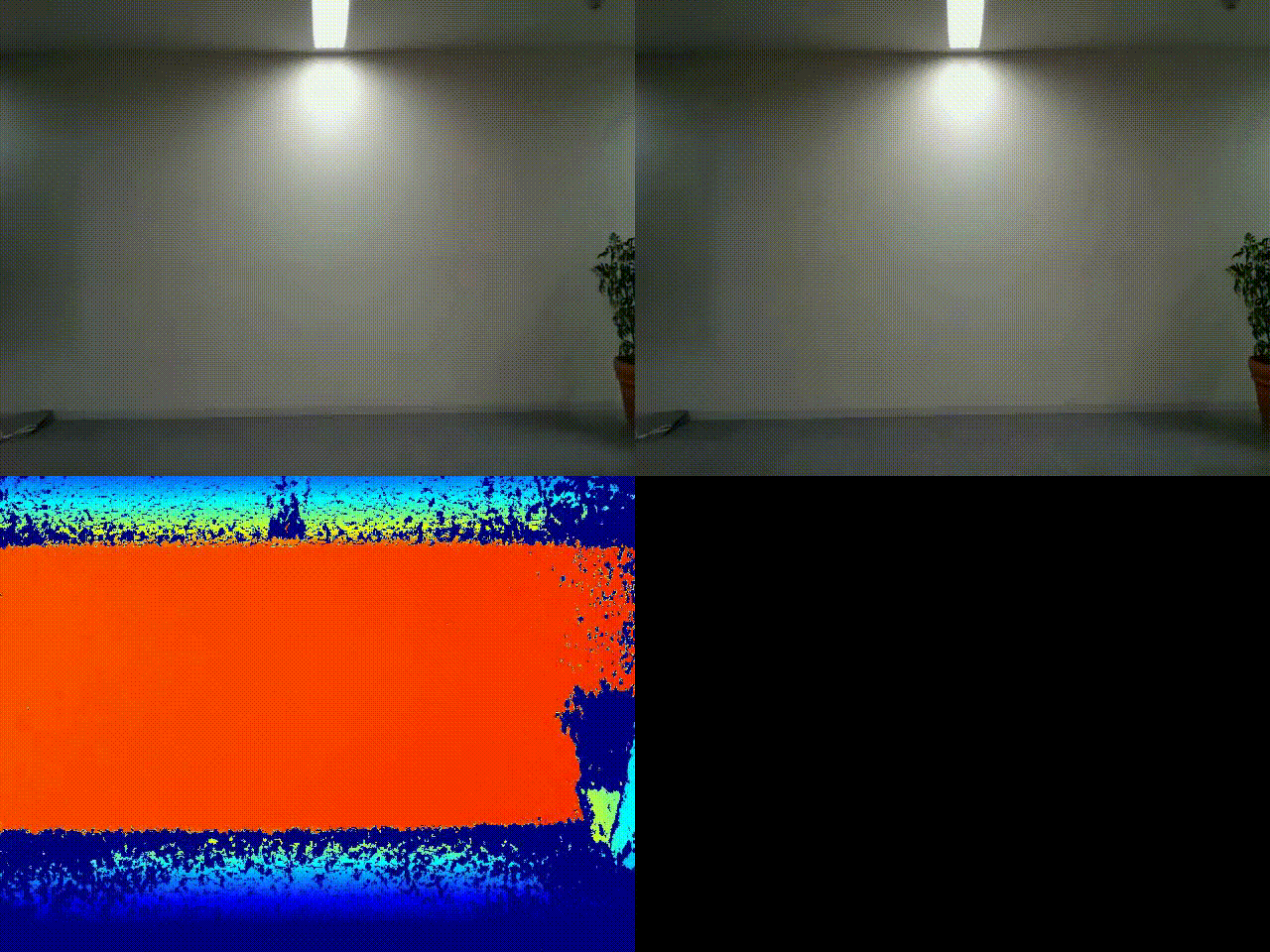
みきをさんの不審者ぶりも大分板についてきました。
今回は上記サンプルコードの結果に加えて、通常のRGB値による差分検知プログラムによる結果(差分判定箇所を赤色で表示)も比較のために加えました(こちらの詳細もいずれ別の記事で紹介したいですね)。
通常のRGB値をもとにした差分検知だと、右上のように背景と物体の色が似ている場合にうまく検知できないことが多いですが、深度センサーだとおかまいなし、実際の物体との距離をもとにカラー出力するので、実際の物体の立体的な形状を正確にとらえることが可能です。実際の壁とカモフラージュとの区別がはっきりとできそうですね。影ノイズに強いのも特徴です。
想定される用途として、様々な物体の検知や、夜間の侵入者検知などへの応用が考えられます。また、上から撮影すれば物体の積み上げ高さもわかるので、在庫管理などにも利用できそうですね。
まとめ
AIに限らず、システムは大きく分けて入力・処理・出力の3要素によって構成されていると自分は考えていますが、AI Dynamics Japan における開発では入力部分における「画像の取得方法」というところにまで検証領域を広げることが多いです。その際の要素技術の一つとして今回は深度センサーを紹介しました。知っているだけで課題解決の幅が広がりそうですね。
読んでいただき、ありがとうございました!