はじめに
LLMやAIエージェントを使ってシステム開発を行っていると、気にしなければならないトークンにまつわる事柄が頻発します。
例えば、各LLMの入出力で許容できるトークン数であったり、また、コストを算出するのにもトークン数を基に計算されます。
そこで今回は、トークンがそもそもどういったもので、なぜ必要なのか、テキストプロンプトが英語・日本語の違いがトークン数や精度にどう影響するかなどなるべく伝わりやすいように掘り下げていきたいと思います。
トークンとは?
トークンは、自然言語処理(NLP)や大規模言語モデル(LLM)において、テキストデータを処理するための基本的な単位です。トークンは通常、単語、部分的な単語、または文字や句読点を含むことができます。トークン化は、テキストをこれらの小さな単位に分解するプロセスであり、モデルがテキストを理解し、生成するための第一歩となります。
トークンの役割
トークンは、以下のような重要な役割を果たします:
-
テキストの構造化:
トークン化によって、LLMはテキストをより構造的に処理できるようになります。これにより、モデルはトークン間のパターンや関係を学習し、文法や意味を理解することが可能になります。 -
意味の理解:
トークンは、単語や部分的な単語、記号など、言語の意味単位に近い概念です。トークン化を行うことで、モデルは文脈や意味をより正確に理解できるようになります。例えば、接頭辞や接尾辞を持つ単語は、複数のトークンに分割されることがあります。 -
計算の効率化:
トークン化によって、テキストデータが数値的な表現に変換され、機械学習アルゴリズムが効率的に処理できるようになります。これにより、モデルは大量のデータを迅速に処理し、学習することが可能になります。 -
語彙の構築:
LLMは、トレーニングデータから得られたトークンの集合を「語彙」と呼びます。この語彙は、モデルが理解できるトークンのリストであり、十分な量のトレーニングデータがあれば、数千のトークンを含むことができます。
トークン化の方法:
例えば、日本語の 「私はAIが好きです。」 や英語の 「I love AI.」 という文をトークン化すると、以下のようになります。
-
単語単位のトークン化:
テキストを個々の単語に分割します。この方法はシンプルですが、語彙サイズが大きくなる可能性があります。
["私", "は", "AI", "が", "好き", "です", "。"]
["I", "love", "AI", "."]
-
サブワード単位のトークン化(BPEやWordPieceなど、後述):
テキストを部分的な単語や記号に分割します。例えば、OpenAIのGPTモデルでは、Byte-Pair Encoding(BPE)という手法が使用されています。この方法は、未知の単語や複雑な構文を処理する能力を向上させることができます
["私", "は", "A", "##I", "が", "好", "き", "です", "。"]
["I", "lo", "##ve", "A", "##I", "."]
-
文字単位のトークン化:
テキストを個々の文字に分割します。この方法は、特に未知の単語や入力ミスに対して柔軟性がありますが、トークン数が増えるため計算リソースが多く必要になります。
["私", "は", "A", "I", "が", "好", "き", "で", "す", "。"]
["I", "l", "o", "v", "e", "A", "I", "."]
トークナイザーについて
トークナイザーは、入力されたテキストを小さな単位トークンに分割するツールです。トークンは通常、単語、部分的な単語、または句読点などを含みます。トークナイザーは、テキストを構造化し、機械学習モデルがその意味を理解しやすくするために必要です。各社のLLMモデルに採用されているトークナイザーが異なるため、全く同様のプロンプトでもトークン数が異なります。
トークナイザーの重要性
トークナイザーは、自然言語処理の基盤であり、適切なトークン化が行われることで、モデルのパフォーマンスが飛躍的に向上します。特に日本語のような単語の境界がはっきりしない言語では、トークン化の精度が重要です。また、多言語モデルを扱う際も、言語に依存しないトークナイザーが求められます。
サブワードトークン化の手法
-
Byte-Pair Encoding(BPE):
頻出する文字列のペアを結合して、サブワード単位のトークン化を行います。これにより、語彙サイズを削減し、未知語にも対応可能となります。 -
WordPiece:
BERTモデルで使用される手法、BPEに似ていますが、統計的なもっともらしさに基づいてトークンを選択します。これにより、言語的な意味をより深く反映するトークン化が可能です -
SentencePiece:
言語に依存しないトークナイザーで、サブワードレベルのトークン化を行います。生テキストから直接学習可能で、多言語対応にも優れています
Anthropic Tokenizer

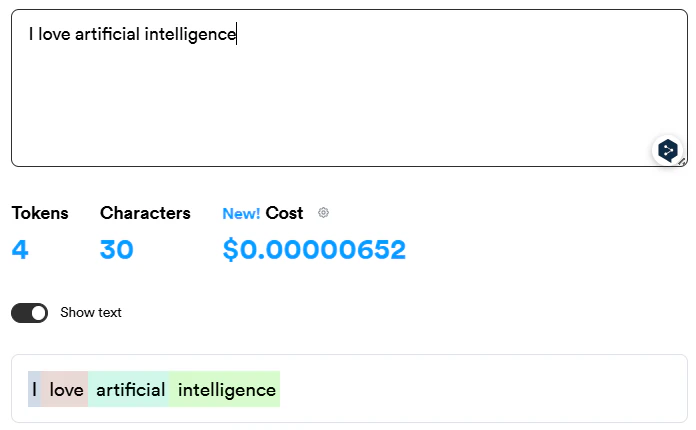
OpenAI Tokenizer
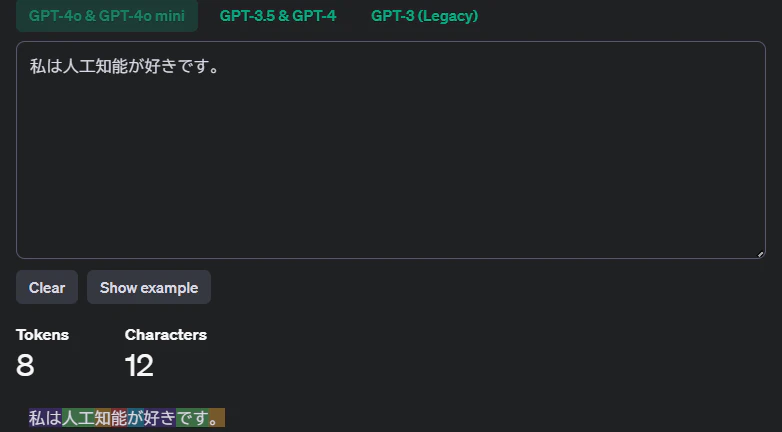
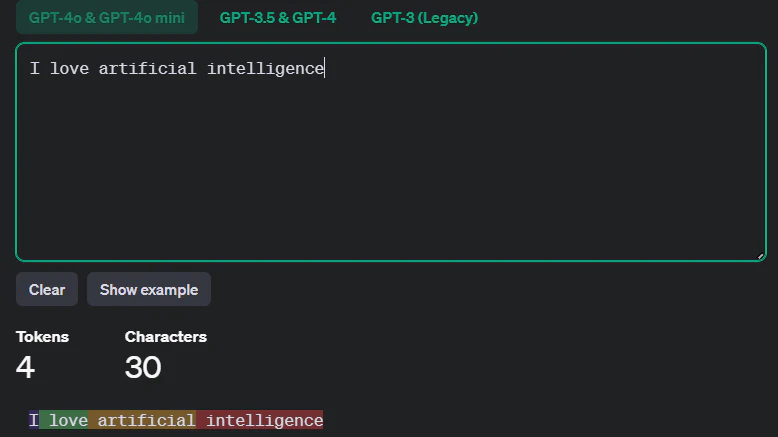
OpenAI Tokenizer:
Anthropic Tokenizer:
トークン化とベクトル化の関係性
ベクトル化(Vectorization)
ベクトル化は、トークン化されたデータを数値的なベクトルに変換するプロセスです。トークンはそのままではコンピュータが処理できないため、各トークンに対して数値を割り当て、ベクトルとして表現します。このベクトルは、トークンの意味や文脈を反映するように設計されており、機械学習モデルがテキストの特徴を理解するために使用されます。
例:「AI」 → [0.12, -0.34, 0.56, ...](埋め込みベクトル)
ベクトル化の主な手法
カウントベースの手法
-
Bag of Words (BoW)
Bag of Wordsは、文書内の単語の出現頻度をカウントしてベクトルを生成するシンプルな手法です。 -
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDFは、単語の重要度を評価するための手法です。TF(Term Frequency)は特定の文書内での単語の出現頻度を示し、IDF(Inverse Document Frequency)はその単語がどれだけの文書に出現するかを考慮します。これにより、一般的な単語の影響を減少させ、特定の文書における重要な単語を強調します。
分散表現を用いる手法
Word Embeddings
Word embeddingsは、単語を低次元のベクトルとして表現する手法です。これにより、単語間の意味的な関係を捉えることができます。代表的な手法には以下があります:
- Word2Vec: 単語の前後の文脈を考慮して、単語をベクトルに変換します。Skip-GramモデルとCBOW(Continuous Bag of Words)モデルの2つのアプローチがあります
- GloVe (Global Vectors for Word Representation): 単語の共起行列(文章の中である単語と別の単語がどれくらい一緒に出てくるかを数えたもの)を基に、単語のベクトルを生成します。文脈情報を考慮し、単語間の関係をより正確に捉えます
- FastText: 単語をn-gramに分解し、部分的な単語情報を考慮することで、未知の単語にも対応できるようにします
まとめ
ベクトル化のあたりは題名からすると蛇足となってしまいましたが、コンピューター・言語モデルがテキストをどう扱っているかなど、概要でもわかるとLLMを扱う上で有用ではないかと思います。
また、一般的に日本語より英語の方がLLMの精度が良い傾向にあるとされています。学習データの量もしかり、言語の構造も影響しているのかなとも思います。