この記事はリクルートライフスタイル Advent Calendar 2016の2日目の記事です。
はじめに
弊社ではログ収集にfluentd v0.12を主に使っており、システム自体はAWS上に構築しています。
fluentdのAggregatorには、ノードの追加がしやすいように負荷分散にELBを使う構成にしています。
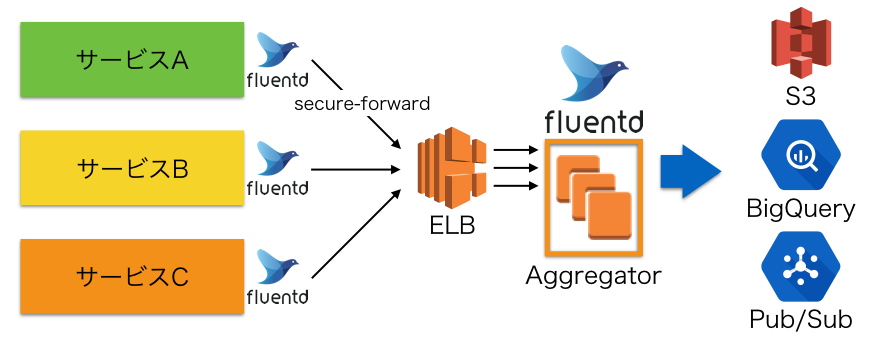
ここ最近までは、複数のサービスからのログを1つのELBで受け、各Aggregatorノードで処理するという構成をとっていました。
ただログが増えてくると安定性に問題が出てきたため、その際に対策として行ったことについてまとめます。
やったこと
1. コネクション数とログ量のアンバランスを解消する
fluentdのsecure-forward output pluginは、コネクションを切らずにログを送り続けます。
またELBは最もコネクション数が少ないノードへ接続を行う負荷分散の方式です。
1コネクションあたりのログ量がほぼ同じであれば、このロードバランシングはうまく機能します。
しかし、1コネクションあたりのログ量にばらつきがある場合においては、うまく負荷分散できない場合があります。
fluentdの負荷はログ量に対して上がっていきますが、ELBの負荷分散はコネクション数によって行われるためです。
例えば、サービスAとBは同じくらいのサーバー台数で、Aは非常にログ量が多く、Bは少ないといった場合に、特定のノードにログ量の多いコネクションが集中してしまうことがあります。
Aggregatorにログが流すサービスが増えることで、そういった状況が多く発生するようになり、ノード単位での負荷が安定しないという問題に遭遇しました。
検証実験
以下は2台のfluentd Aggregatorに対して、4つのfluentdプロセスからログを送ったときのAggregatorのCPU使用率のグラフです。

4つのfluentdプロセスのうち、1プロセスだけ1000レコード/secに設定し、残りの3プロセスは10レコード/secに設定しました。keep_aliveは60秒に設定しています。
グラフを見るとログ量の多いプロセスからログを受けているノードの負荷が高くなっています。
またkeepaliveの時間ごとに接続先が変わり負荷が安定しないことがわかります。
なお、この間2つのノードのでコネクション数には差はありませんでした。
対策したこと
コネクションあたりのログ量のばらつきを抑えるためにサービスごとにAggregatorを分割する対応を行いました。
同じサービス内であれば、ログ量の多いサーバーは台数が多く、ログ量が少ないサーバーは台数が少ないため、上記のような問題は発生しにくくなるからです。
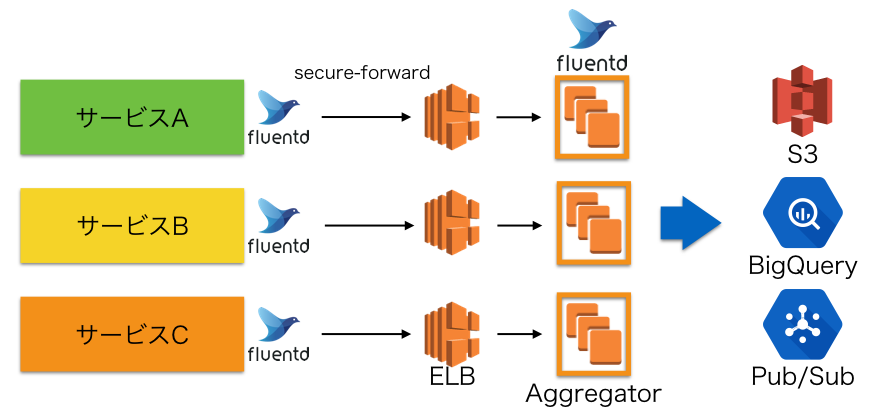
この対策を行った結果、ばらつきの大きかった各ノードの負荷がだいたい均一になりました。
これは効果の大きかった対策です。
2. アイドルタイムアウトを設定する
ELBは無通信のコネクションを切る時間としてアイドルタイムアウトを設定できます。
もしログが長時間流れない状態になるとELBから強制切断されてしまい、以下のようなWarningが出ます。
[warn]: disconnected host="xxx.xxx.xxx.xxx" port=xxxxx
[warn]: dead connection found: xxx.xxx.xxx.xxx, reconnecting...
[warn]: recovered connection to dead node: xxx.xxx.xxx.xxx
これを防ぐにはアイドルタイムアウトをsecure-forward output pluginのkeep_aliveより長い時間に設定すれば解消します。
3. 接続のストリーミングを設定する
ELBにはデタッチしたインスタンスへのコネクションを切れるまで維持してくれる機能として接続のストリーミングがあります。
この値も同じくsecure-forward output pluginのkeep_aliveより長い時間に設定しておかないと、デプロイ時などにインスタンスをデタッチした際に上記と同じWarningが出ます。
まとめ
ELBを経由したAggregatorの構成はあまり情報がなく、試行錯誤を繰り返して安定化してきました。
ELBとは関係なく負荷を下げるために行ったことは他にもありますが、最も効果的だったのはAggregatorを分割したことでした。
Aggregatorを分割するとデプロイ時の手間が増えたりしますが、それをどうやって解消していったかについてはRecruit Engineers Advent Calendar 2016に書く予定です。