前説
ビートルズが50年経っても未だにポピュラーなのは、
(クオリティの高さは前提として)
把握しやすいキャリアの長さだということもあると思います。
約10年で約200曲という、膨大ながらついていけなくもない曲数。
分析するのにうってつけですね(強引な話の切り替え)。
自分語り
ところで自分も楽曲を作っていて、Spotifyにもあるわけですが、
自分の曲とビートルズの曲を比べてみると何か分かるかもしれないというあやふやな動機の元、
Pythonを走らせてみました。
Spotipy
と言ってもPythonで分析したわけではなく、
Spotifyが(レコメンドのために?)分析しているデータをAPIを通じて取ってきただけです。
取ってくるためのライブラリもあって、 Spotipy といいます。
認証情報
Spotifyの開発者ポータルから、APPを作ります。
このときクライアントIDとSecretをメモっておきます。
Spotipy的には環境変数を使ってほしいみたいですが、うまく行かなかったので 直打ち でIDとSecretを渡します。
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
spotify = spotipy.Spotify(client_credentials_manager=SpotifyClientCredentials(
client_id='hogehoge', client_secret='fugafuga'))
これでSpotifyのAPIが叩ける…というかSpotipyを通じて単に取ってくる感じになるので、
取ってきます。
ちなみにビートルズ213曲を集めたプレイリストを見つけたので使わせてもらいました。
beatles_uri = 'spotify:playlist:57z71mWZeq5xy0zEBvO5Cx'
results1 = spotify.playlist_items(beatles_uri)
songs1 = results1["items"]
results2 = spotify.playlist_items(beatles_uri, offset=100)
songs2 = results2["items"]
results3 = spotify.playlist_items(beatles_uri, offset=200)
songs3 = results3["items"]
songs1.extend(songs2)
songs1.extend(songs3)
songs = songs1
213曲あるけど、同時に取れるのは100曲までのようなので3回に分けました。
for song in songs:
ana = spotify.audio_features(song["track"]["uri"])
audio_featuresは先程のplaylist_itemsとはまた別なAPIで、
ここに分析情報が格納されています。
いろいろ含まれているのですが今回は楽曲の「調」を調べます。
213曲ぶんなので time.sleep(1) を入れて負荷がかからないようにしました。
csvRow = f'"{i}", "{song["track"]["name"].replace(",", " ")}", "{keymode[ana[0]["key"]][ana[0]["mode"]]}"'
with open('beatles.csv', 'a') as f:
print(csvRow, file=f)
あとはファイルへの書き込みです。
ちなみに keymode というのは、Spotifyの分析ではキー(AとかBとか)とモード(長調、短調)が別のところに入っているので、
うまくマップするための自作リストです。
keymode = [
["Cm", "C"],
["C#m", "Db"],
["Dm", "D"],
["D#m", "Eb"],
["Em", "E"],
["Fm", "F"],
["F#m", "Gb"],
["Gm", "G"],
["G#m", "Ab"],
["Am", "A"],
["Bbm", "Bb"],
["Bm", "B"]
]
余談1: Bbm にすべきか A#m にすべきか迷ったんですけど、たぶんBbmが一般的? かな?
余談2: bじゃなくて♭を使いたかったけど、文字化けで断念しました。
csvmod.py
さて、これで beatles.csv ができました。
ほぼ同じ要領で mikiri.csv も作りました。
しかしながらプロットする段になって2つは同じCSVにあったほうが設定しやすいことが判明しました!
なのでマージです。
import pandas as pd
beatles_csv = pd.read_csv("beatles.csv")
mikiri_csv = pd.read_csv("mikiri.csv")
beatles_csv["artist"] = '"beatles"'
mikiri_csv["artist"] = '"mikirihassha p"'
beatles_csv.to_csv("analyze.csv", index=False,
columns=["name", "key", "artist"])
mikiri_csv.to_csv("analyze.csv", mode="a", header=False,
index=False, columns=["name", "key", "artist"])
pandas の read_csv を使用しCSVからデータフレームを作成。
データフレームに新たなカラム "artist" を追加。
to_csv()で吐き出し。
ただし2つ目はheaderをFalse、modeをaとする。
こんなもんでしょう!
できたCSVは 見せたくないけど 見せます。
name,key,artist
" ""Love Me Do - Mono / Remastered"""," ""C""","""beatles"""
" ""P.S. I Love You - Remastered"""," ""D""","""beatles"""
" ""Please Please Me - Remastered"""," ""E""","""beatles"""
" ""Ask Me Why - Remastered"""," ""E""","""beatles"""
" ""I Saw Her Standing There - Remastered"""," ""E""","""beatles"""
" ""Misery - Remastered"""," ""C""","""beatles"""
" ""Anna (Go To Him) - Remastered"""," ""D""","""beatles"""
" ""Chains - Remastered"""," ""Bb""","""beatles"""
" ""Boys - Remastered"""," ""E""","""beatles"""
" ""Baby It's You - Remastered"""," ""Em""","""beatles"""
" ""Do You Want To Know A Secret - Remastered"""," ""E""","""beatles"""
" ""A Taste Of Honey - Remastered"""," ""C#m""","""beatles"""
" ""There's A Place - Remastered"""," ""E""","""beatles"""
" ""Twist And Shout - Remastered"""," ""D""","""beatles"""
なんかクォーテーションが多すぎて煩雑なことになってしまいました。
しかしこのままGOします。
plot.py
次はいよいよプロットです。
import matplotlib.pyplot as plt
import pandas as pd
csv = pd.read_csv( "analyze.csv" )
csv = csv.sort_values("key")
csv["key"].hist(bins=50, by=csv["artist"], sharey=True)
plt.show()
これだけです!
csv["key"].hist() に渡す値は多少試行錯誤しましたが、あとは素直に書けました。
by=column を指定するとそのカラムの値によって比較するプロットが描写できます。
つまりこんな感じ。
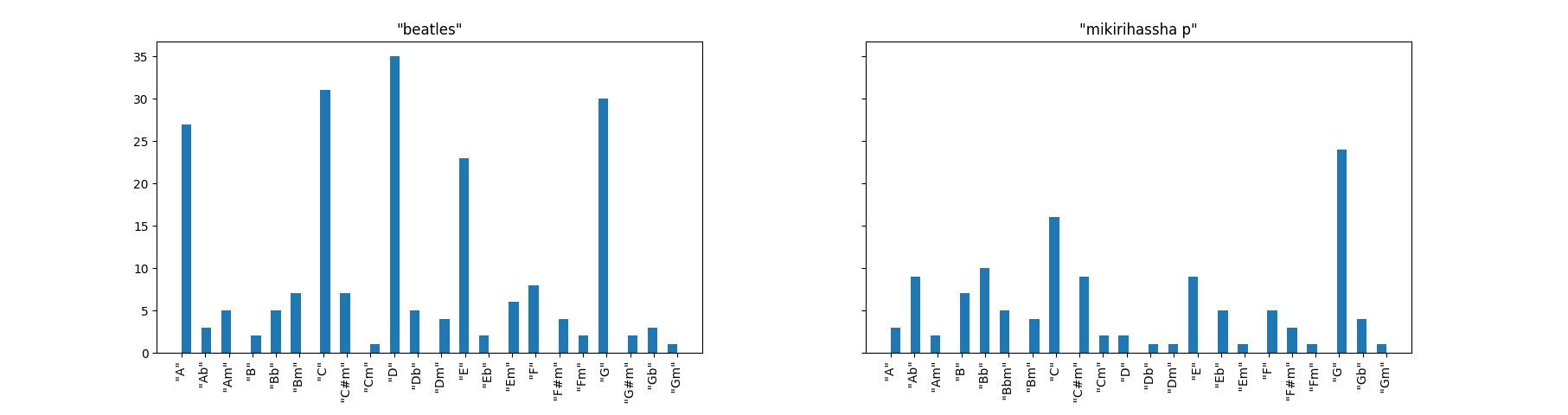
見た感じちゃんとしたデータになってくれたようです。
分析
シンガーソングライターギタリスト
beatles のグラフを見て直ちに気づくのは、
こいつらギターで曲を作ってるなということです。
突出している、A, C, D, E, G はそれぞれ、ギターに於いて押さえやすいフォームがあるコードです。
つまり、バレーコード(弦をガバっと押さえるやつ)ではなく、ローコードで作曲しているのではないでしょうか。
その後演奏時にはバレーコードに変えたりしてるかもしれませんが…
ネアカ
また2番めに気づくのは、メジャー系のキーが多くマイナー系は少ないということです。
これはビートルズのイメージから言っても納得できます。
また、個人的にビートルズにはDのキーが多い気がしていたのですが、実際多かったようです。
比較
mikirihassha p (自分)はGにピークがあるもののあまり波がなく、傾向が掴みづらいグラフになっていました。
よく言えばバランスの取れたグラフです。
調のバランスを取ってどうなるんだって感じですが…
AよりAbが多かったのはちょっと意外。
あと、ビートルズでは多かったDが自作では少ない。
結論
あまり参考にならない
みなさんカラオケで音を半音単位で上げ下げとかするかと思いますが、
半音上にしたからと言って違う曲になったりはしませんよね。
それと同様に、例えばキーをDにしたからといって即ビートルズになれるかというとなれそうにないです。
でもDキーの曲が少なすぎる気がしたので今後ちょっと増やしてみようかなと思いました。