あらまし
homebrew は主にMac向けのシステムです。
ジャンルはパッケージ管理になるのかな?
Formulae と呼ばれるアプリというかライブラリというかパッケージというかをターミナルから簡単にインストールできるソフトウェアです。
そんな homebrew には homebrew-cask という親戚がいて、こちらはいわゆるアプリ、アプリケーションフォルダに入れたりDockにアイコンが並んだりするアプリをインストールするのに使います。
homebrew-cask の Formulae は こちら から一覧できるのですが、
名前とバージョン番号以外の情報が無いのでスクレイピングで補ってみました。
完成したのがこちらです。
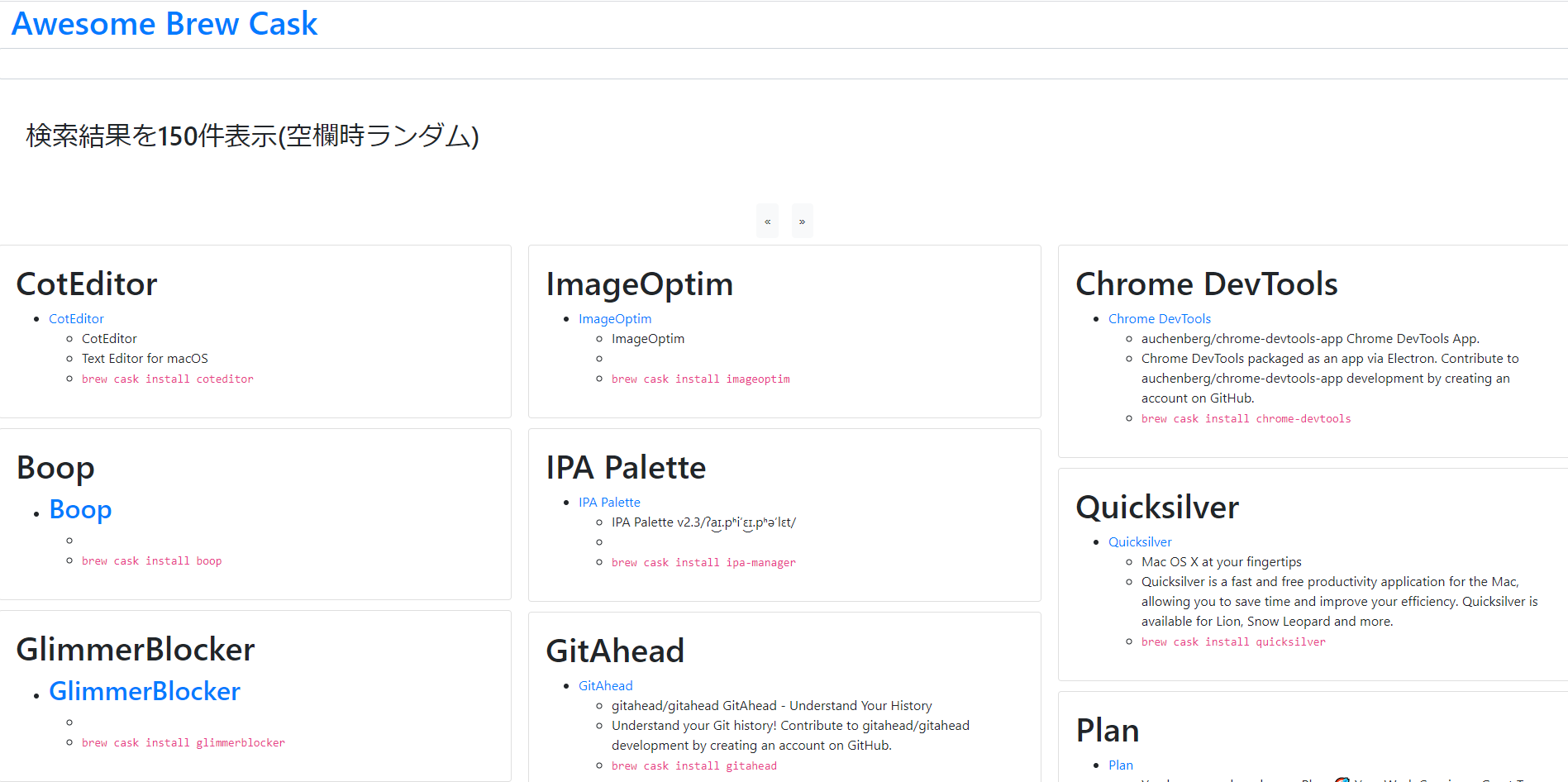
Awesome Brew Cask (https://mi-ki-ri.github.io/awesome-brew-cask-site/)
スクレイピング部分( BeautifulSoup )
まず、formulae一覧ページ からリンクされていた JSON API を叩きました。
この時点では BeautifulSoup ではなく、普通の requests ライブラリを使用しています。
JSON ファイルの中には Formulae 情報のオブジェクトが配列になって入っていました。
その中で、 homepage というキーに URL が格納されていたので、それを BeautifulSoup で取ってくる処理です。
JSONファイルのイメージは
[
{token:"hogehoge", name:["hogehoge"], homepage: "https://hogehoge/"},
{token:"fugafuga", name:["fugafuga"], homepage: "https://fugafuga/"}
]
こんな感じです。
取ってくる処理は簡単で、
import requests
casks = "https://formulae.brew.sh/api/cask.json"
casks_get = requests.get(casks)
for cask in casks_get.json():
# 個別処理
こんな感じ。
この辺は気軽にできて Python はいいなと思いました。
で、ループ内で BeautifulSoup を用いて、
- meta タグの description 情報
- title タグ
を取ってくることにしました。
homepage キーがセットされてない場合なのか、エラーが出ることもあったのでエラーをキャッチする文も書きました。
こんな感じ。
import requests
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
from bs4 import BeautifulSoup
try:
url_get = requests.get(url, verify=False)
except Exception as exc:
print(exc)
else:
if url_get.status_code == 200 or url_get.status_code == "200":
html = url_get.content
soup = BeautifulSoup(html, "html.parser")
# タグ解析処理
requests.packages.urllib3.disable_warnings(InsecureRequestWarning) はワーニングの表示を抑制するためのものです。
こういう書き方ができるのを初めて知りました。
Python 部分の最後では、
name, token, url, title( BeautifulSoup 由来 ), meta( BeautifulSoup 由来 )の5つの情報を md ファイルに保存しました。
hugo 部分
md ファイルが揃ったら( 2時間はかかったと思います )、静的サイトジェネレーターの hugo を用いてフロントを作ります。
「検索できる・パラパラと一覧できる」という要素が揃ったテーマを探したのですがちょうどいいのがなかったので、自作になりました。
( .gitmodule ファイルにその痕跡がある…… )
hugo の場合、テーマの自作は hugo new theme themename を入力して、出力されたファイルを元に改造していく形になります。
themeフォルダ/layouts/_default/ にある、
- baseof.html
- list.html
- single.html
の3ファイルに必要に応じて読み込み先のファイルなどを追加していく形です。
が、今回はlistをスルーしてbaseofにリストの役割を負わせたり、
singleが都合によりベタ書きになったりしていて参考にはなりません。
参考になりそうなのは、検索機能に Lunr というライブラリを使った点。
予めインデックスファイルを作成してそれを読み出して検索する方式で、
hugo-lunr という npm ライブラリを使えば簡単にインデックスファイルを作れます。
そして公式サイトを参考に、
let documents = [];
let idx = null;
await axios
.get("{INDEX_FILE_PATH}")
.then((res) => {
documents = res.data;
idx = lunr(function () {
this.ref("uri");
this.field("content");
documents.forEach(function (doc) {
this.add(doc);
}, this);
});
});
let sch = idx.search("{SEARCH_WORD}");
大体こんな感じで実装しました。
検索が軽快なのがいいです。
あとは公開
公開は github pages にしました。
公開までに細かい調整が必要だったので、hugo-lunr や hugo を気楽に叩けるように、
package.json に次のような行を加えました。
"scripts": {
"fetch": "python app.py",
"fetch3": "python3 app.py",
"build": "rm -rf docs && hugo-lunr -i \"content/docs/**\" -o \"{{INDEX_FILE_PATH}}\" && hugo && mv public docs"
}
これでコンソールから npm run fetch3 とすれば python3 が動いてスクレイピングをし、
npm run build とすればインデックスファイルの作成、 hugo のビルド、フォルダ名の変更を一気にできます。
あとは git でコミット、プッシュをすれば数分後には github pages に上がっています。
便利です。
注意事項
スクレイピングには一般的に迷惑がかからないよう注意が必要です。
サーバー負荷への配慮, 個人利用, 利用規約の遵守 あたりがキーワードのようで、
サーバー負荷については一つのサイトへの集中的なスクレイピングではなく、
多くのサイトへの並列的なスクレイピングだったのでおそらく大丈夫なのですが、
個人サイトでの公開が個人利用なのかについてはいまいち確信が持てていません。
なので消えてたら苦情が入ったものと思ってください。
終わり
長かった!
いずれ今回のサイトを利用しての「brew caskで入れられるおすすめのアプリ」的な記事も書こうと思います。