1.はじめに
本記事では、シンプルで軽量に動作することを目指した、音声認識(話者識別、年齢推定、性別推定)モデルについて紹介します。音声は簡便な情報伝達の手段であり、音声認証、話者を区別した議事録作成、感情推定、特殊詐欺検知など応用範囲は広いです。手軽に使うためには、低スペックのデバイスでも動作することや、処理スピードも求められるため、音声認識モデル構築に当たっては、うまい(高性能)、安い(軽量)、早い(高速)をコンセプトとしました。このモデルは2021年に社内で行われたAIコンテストに取り組んだ際に考案したものです。
当社では2018年度から2022年度まで、社内でAIコンテストが開催されています。コンテストの課題は年度によって異なり、文書データや音声データ、画像データなど様々なデータを題材としています。本記事では音声データを対象とした課題への取り組みについてご紹介します。
2. AIコンテスト2021ルール

コンテスト開始時に提供される学習用の音声データ(以下、提供データ)を用いてモデルを作成し、コンテスト終了後に公開される評価用の音声データ(以下、最終評価データ)に対して、話者識別と年齢・性別推定を行います。
提供データの構成としては、男女250名ずつからなり、それぞれの話者が発話した1秒弱~15秒程度の音声データが10ファイル、計5,000ファイルあります。話者の年齢は18~49才で、一様な分布ではなく偏りがあります(上図)。
話者識別で使用する最終評価データの中には、「学習用の話者」には含まれない「未知の話者」も含まれており、未知の話者は「NA」として識別することとします(いわゆるOOD検出)。また、学習用の話者に対しては、話者識別に成功すると自動的に年齢・性別が分かってしまうため、年齢・性別推定に使用する最終評価データは未知の話者のみとなっています(上図)。
3. 方針
- まず、人の音声の特徴量を考えます。単純に音声データ全体を特徴量として使うことが考えられますが、ファイル毎に長さが違うので扱いづらそうです。一方、音声の一部を短い固定長で切り取り特徴量とすることを考えると、その中では、一音から数音しか発声されておらず、別の一部ではまた異なる音が発声されており、切り取る場所によってばらつきが大きく、その人を表す特徴量としてはうまく使えなさそうです。
- 音声は、「あ」、「い」、「う」、・・・、「ん」と限られた数の音(濁音等もありますが)から成っていますので、ある程度長い音声の中から特徴的な音を拾えれば、その人の声の特徴量となりそうです。ここではシンプルをモットーに、音声データ全体からランダムに複数切り取り集めてくることとします。
- 次にモデルについて考えます。上記で集めたいくつかの音を入力として、ニューラルネットで学習しようと思いますが、集めてきた音の順番で出力が変わるようでは困ります(例えば、「ひ、り、さ」を入力した場合と、「さ、ひ、り」を入力した場合で出力が異なってしまうとおかしい)。そこで、入力の順番によらない構造であるDeep Sets1の考え方を導入します。
- 話者識別と年齢・性別推定を別のモデルで作っても良いのですが、ここではシンプルをモットーに、一つのニューラルネットを途中で分岐させ、話者識別、年齢推定、性別推定の3つのタスクを同時に解くモデルとします。
以下、入力データやモデルについて詳しく見ていきます。
4. 入力データの前処理

提供データは上図の青枠と緑枠に示すように、学習用と評価用に分割し、評価用データで確認を行いながら学習を行います。NAを含む最終評価データを模擬するため、学習用データはランダムに抽出した400名の1~8番目の音声データを使用し、評価用データは500名全員の9~10番目の音声データを使用します。最終評価データでは、上図の500名はNAではなく、別のNAとなる話者が追加されるため、コンテスト終了直前に500名全員のデータ(上図赤枠)を使って学習し直しています。(念のため過学習しないか確認するため、評価用を残しています。)
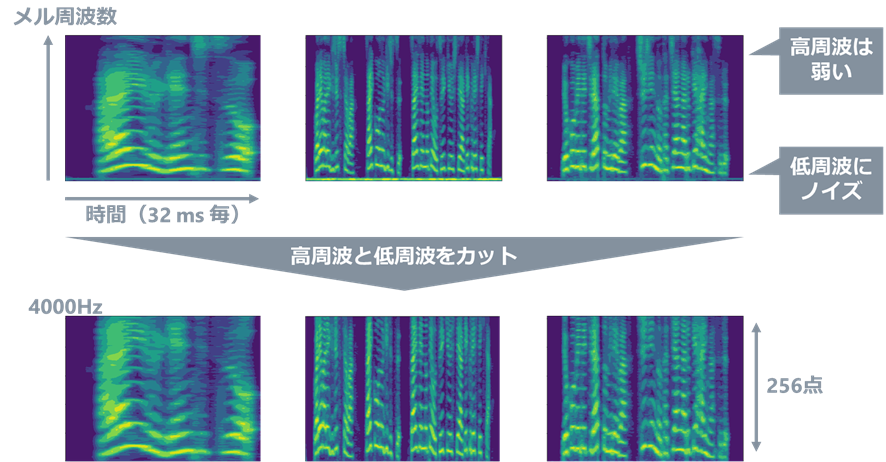
実際に提供データの音声を聞いてみると、早口な人やゆっくりしゃべる人、空音の部分があったり無かったり、ザーッという砂嵐のような音が入っているファイルもちらほらあります。音声のままだと扱いづらいので、まず、音声認識の分野における常套手段であるメルスペクトログラムに変換します(上図)。ここで、高周波成分が弱いということが見えたり、低周波部分にノイズが乗っていることが分かったりしますので、高周波と低周波をカットします。
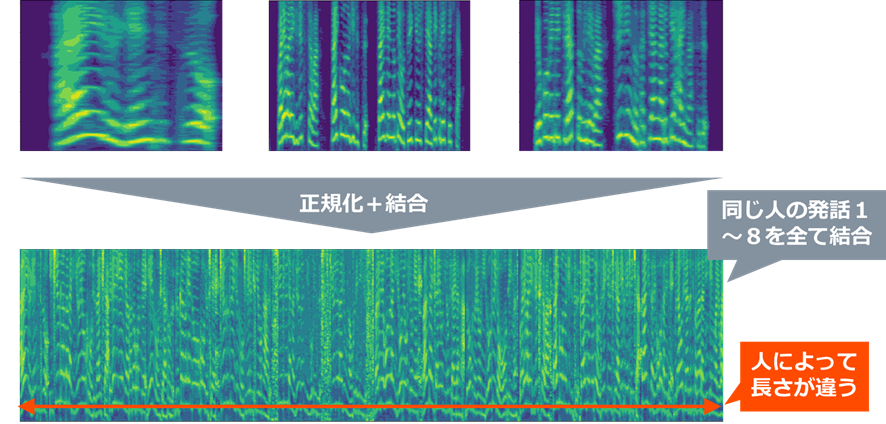
次に、上図のように無音区間を削除し、各人の1~8番の音声データを結合します。この時、人による音声の強弱や周波数間の強弱の影響を低減するため、正規化を行っています。具体的には、平均的な周波数分布を差し引き、周波数ごとに-1~1で正規化しています。
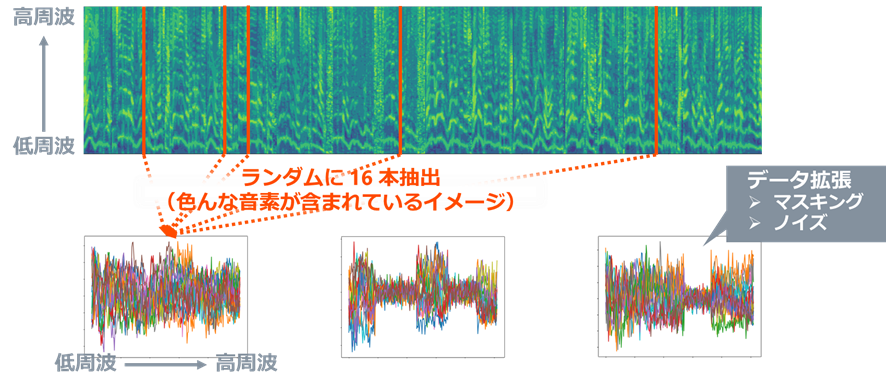
その後、このデータからランダムに16本の列ベクトルを抽出します(下図)。16本というのは、色々と試したところ、これ以上増やしても性能にあまり影響せず、これより少ないと性能が下がるということが分かったため、この数としています。この16本の列ベクトルが入力データになります。なお、ランダムに0~2か所、ランダムな長さだけ周波数方向にマスキングを行い、ノイズを乗せることでデータ拡張を行っています。
5. モデル概要
モデルの概要を下図に示します。モデルは上記の16本の列ベクトルを入力として、特徴抽出部、そこから3つに分岐した話者識別部、年齢推定部、性別推定部からなります。話者識別部、年齢推定部、性別推定部のネットワーク構造は全て、全結合層を数層繋げただけのシンプルなものとなっています。また、学習時のlossは、話者識別のloss、年齢推定のloss、性別推定のlossの単純な和としています。
推論時は、Test Time Augmentation(TTA)2を行います。すなわち、上記の入力データ(瞬時のメル周波数スペクトル16本)を複数回抽出し、複数回の推論を行った結果をもとに多数決で決定しています。ここでは、TTAにおける抽出は16回行っています(16本のスペクトルの抽出を16回行っています)。
以下、それぞれの部分について詳しく説明します。

特徴抽出部
冒頭の方針で示した通り、入力データ(瞬時のメル周波数スペクトル16本)は順序に依らないためDeep Setsの考え方を導入します。下図の$\phi$は一次元コンボリューションを多層にしたものであり、16本それぞれに同じ$\phi$を適用しています。最後に和を取ることにより順序に依存しない特徴量となっています。

話者識別部
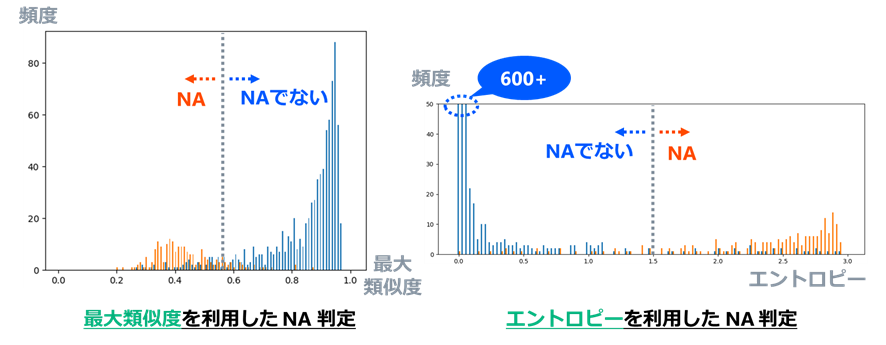
500人の識別を行うため500クラス分類を行っています。また、NAの判定を行うために、ArcFace3のAdditive Angular Margin Lossを使用し距離学習を行っています。距離学習によって、出来るだけ同じクラス内の出力データを近づけ、異なるクラス間の出力データを遠ざけるように学習し、どのクラスからも遠い出力データの場合にNAと判定します。ある出力データが、どのクラスからも遠いというのは、下図のように各話者を代表するベクトルとのcos類似度を測った時に、突出したcos類似度が無い、すなわち、最大類似度が低い状態のことと言い換えられます。

この最大類似度をNAの判定基準に用いることとし、評価用データ(NAでない話者:400人×2ファイルNA:100人×2ファイル)で推論を行い、各入力データに対し最大類似度がどのような値を取るか調べました。
TTAを行わず、推論を一回だけ行った場合の最大類似度の頻度を示した図が下図左です。NAでない話者(青線)は最大類似度が高くなる傾向があるのに対し、NA(赤線)の場合、そのような傾向はみられません。ただし、NAの場合でも、0.7以上の高い最大類似度を取るようなものが半分くらいあります。
TTAを行いcos類似度の分布(上図のような分布)を平均化した場合の、最大類似度の頻度を示した図が下図右です。このとき、NAの最大類似度のほとんどは0.7を下回るようになります。一回だけの推論だとたまたま大きな値を取ってしまったものが、平均化によって分布がならされた結果だと考えられます。一方、NAでない話者の場合は、正解の話者で毎回大きな値を取るため、平均してもならされる影響は少ないです。

上図右において、閾値を0.6あたりに置くことでNAかそうでないかの判定は十分に行えると思います。ただし、上図ではcos類似度の分布の「最大値」の情報しか使っていないため、もう少し改良の余地がありそうです。cos類似度の分布をsoftmaxにより確率に変換し、そのエントロピーを計算することで、「分布全体」の情報を使えるようになります。エントロピーが高いということは、一様分布に近いということであるため、モデルが話者を特定できず、NAである可能性が高いということを示しています。下図の左右に、最大類似度を使用した場合とエントロピーを使用した場合をそれぞれ示していますが、エントロピーを使用した方がはっきりと分かれていることが分かります。
年齢推定部
18~49才の32クラス分類を行っています。ただし、クラス間に順序があるため、間違える際には年齢が近いクラスに間違えるようにしたいです(コンテストの評価基準もそのようになっていましたので)。正解ラベルをone-hotとしてしまうと、隣のクラス同士の関連が無くなり、たとえば、正解が21才の時に45才等と大幅に間違えてしまうような問題が起こりかねません。その対策としてLabel Distribution Learning4を行っています。下図のように正解に分布を持たせることで±5才の範囲のクラスに関連性が出ることを狙っています。

(実は、冒頭の学習データについての説明にある通り、年齢はかなり偏った分布をしておりましたが、時間の都合上そのための対策を取ることは出来ませんでした。。)
性別推定部
2クラス分類を行っています。簡単なタスクなので、特に工夫はしておりません。
6. 推定結果
最後に、評価用データ(NAでない:400人×2ファイル、NA:100人×2ファイル)での推定結果について説明します。
下表は、話者識別、年齢推定、性別推定のタスクにおいて正解した割合を示したもの(赤字で示した部分が実際にコンテストで評価される部分)です。話者識別はNAの判定も含めて94%と良好な結果であり、性別推定も100%を達成しています。年齢推定も73%と決して低くはありませんが、もともと難しいタスクであることに加え、データの不均衡に対する対策を取っていないことで、他のタスクに比べるとあまり高くないという結果になりました。

話者識別のNAの判定についての詳細を以下に示します。NAでない音声全800例の内、正しくNAでないとして推定されたものは770例、間違えてNAとして推定された音声は30例でした。正しくNAでないと推定された770例の中だけで見ると、話者を間違えたものは5例だけであり、正解率は99%以上となっています。NAの音声全200例の内、正しくNAと推定されたものは178例、間違えてNAでないと推定されたものが22例という結果でした。

また、上記推定にかかる時間は、標準的なPC上で800例に対して数分程度と、1例あたり1秒を切るスピードとなっており、うまい(高性能)、安い(軽量)、早い(高速)という当初のコンセプトを達成できたと思っています。
なお、実際のコンテストにおいて、コンテスト期間終了後に提示された最終評価データを用いて評価した際も、上記と似たような成績でした。
7. おわりに
2021年に社内で開催されたコンテストで考案したシンプルな音声認識モデルを紹介しました。
ここで構築したモデルよりも性能が良いモデルは世の中に沢山あるかと思いますが、シンプルなモデルでそこそこの成績が出せたと思います。本記事が音声認識における手法検討の一助になれば幸いです。
情報通信研究部 小泉 拓
-
M. Zaheer, et al., “Deep Sets,” NeurIPS, 2017. ↩
-
D. Shanmugam, et al., “Better Aggregation in Test-Time Augmentation,” ICCV, pp.1214-1223, 2021. ↩
-
J. Deng, et al., “ArcFace: Additive Angular Margin Loss for Deep Face Recognition,” CVPR, pp.4690-4699, 2019. ↩
-
B. B. Gao, et al., “Deep label distribution learning with label ambiguity,” IEEE Transactions on Image Processing, pp.2825-2838, 2017. ↩