PGDSpiderは、集団遺伝学で使用するソフトウェアのファイル形式を変換してくれるソフトウェアである。スイス・ベルン大学の集団遺伝学者 Laurent Excoffierのラボの出身者のHeidi Lischerが作成している。
カバーしているファイル形式はArlequin、PED, VCF, EIGENSTRAT、などなど。GUIのソフトウェアとして使う前提であるが、コマンドラインでも使用可能。
コマンドラインで使う場合には、ダウンロードしたzipの中に、PGDSpider2-cli.jarがあり、これを使う。以下の説明は、自分が使用したいファイル形式を知っているという前提で進める。
CUI版でコマンドを実行してみる
使い方は基本はGUI版と変わらないが、CUI版の問題点は、ファイル変換のための設定ファイル(SPIDファイル)を作るのがやや面倒であるというところである。
とりあえずCUI版を起動してみるとオプションなどの説明が出てくる。
java -Xmx512m -Xms512m -jar PGDSpider2-cli.jar
--------------------------------------------------------------------------------------
PGDSpider 2.1.1.3 Copyright (c) 2007 - 2017 by Heidi Lischer, University of Bern
Citation:
Lischer HEL and Excoffier L (2012) PGDSpider: An automated data conversion tool for
connecting population genetics and genomics programs. Bioinformatics 28: 298-299.
--------------------------------------------------------------------------------------
Usage: PGDSpiderCli <options...>
Options:
-? or -h For this page.
-inputfile <file> The input file for the conversion (mandatory).
-inputformat <format> Format of the input file. Mandatory if not defined
in the answer (SPID) file.
Possible input formats:
PGD, ARLEQUIN, BAM, BAPS, BATWING, BCF, CONVERT, EIGENSOFT, FASTA,
FASTQ, FSTAT, GDA, GENELAND, GENEPOP, GENETIX, HGDP, HGDP_CEPH,
IMMANC, IM, IMA2, MAF, MEGA, MIGRATE, MSA, NEWHYBRIDS, NEXUS,
ONESAMP, PED, PHYLIP, SAM, STRUCTURE, VCF, XMFA
-outputfile <file> The output file for the conversion (mandatory).
-outputformat <format> Format of the output file. Mandatory if not defined
in the answer (SPID) file.
Possible output formats:
PGD, ARLEQUIN, BAM, BAMOVA, BAPS, BATWING, BAYENV, BCF, EIGENSOFT,
FASTA, FASTQ, FDIST2, FSTAT, GDA, GENELAND, GENEPOP,
GENETIX,GESTE_BAYE_SCAN, IMMANC, IM, IMA2, KML, MEGA, MIGRATE, MSA,
MSVAR, NEWHYBRIDS, NEXUS, ONESAMP, PED, PHYLIP, SAM, STRUCTURAMA,
STRUCTURE, VCF, XMFA
-spid <file> SPID file containing preanswered conversion questions
(mandatory).
READMEによれば、引数としてSPIDファイルが指定されていない場合、ソフトウェアは自動でテンプレートのSPIDファイルを作成するという。例えば、EIGENSTRAT形式のファイルをARLEQUIN形式に変換する際に、SPIDを指定せずに実行してみると以下の通りになる。
java -Xmx2048m -Xms1024m -jar ~/opt/PGDSpider_2.1.1.3/PGDSpider2-cli.jar -inputfile sample.geno -outputfile sample.arp -outputformat ARLEQUIN
WARN 14:10:42 - PGDSpider configuration file not found! Loading default configuration.
A template SPID file was saved under: template_EIGENSOFT_ARLEQUIN.spid
for more details see manual.
initialize convert process...
read input file...
ERROR: Question EIGENSOFT_PARSER_GENOTYPE_FILE_QUESTION not answered!!!
ERROR 14:10:42 - input file error at line: 0
read input file done.
write output file...
ERROR 14:10:42 - No sequence, SNP, RFLP, Microsat, Standard or Frequency data in the input file. Arlequin Writer can only handle DNA, NGS, SNP, RFLP, Microsat, AFLP, Standard or Frequency data!!!
write output file done.
このように、SPIDのtempleteファイルは作成されたものの、ファイル変換は行わずに終了する。しかも、ここで出ているエラーは、templateファイルの中に設定する内容である。
そこでtempleteとして書き出されたSPIDファイルの中身を見てみると、初見ではよくわからない。
$ cat template_EIGENSOFT_ARLEQUIN.spid
# spid-file generated: Mon Feb 05 14:10:42 JST 2018
# EIGENSOFT Parser questions
PARSER_FORMAT=EIGENSOFT
# Open indiv file
EIGENSOFT_PARSER_IND_FILE_QUESTION=
# Select the format of the genotype file:
EIGENSOFT_PARSER_GENOTYPE_FILE_QUESTION=
# Open snp file
EIGENSOFT_PARSER_SNP_FILE_QUESTION=
# Arlequin Writer questions
WRITER_FORMAT=ARLEQUIN
# Specify which data type should be included in the Arlequin file (Arlequin can only analyze one data type per file):
ARLEQUIN_WRITER_DATA_TYPE_QUESTION=
# Do you want to convert SNP/DNA to numeric format with 0 representing anchestral state (for derived (unfolded) SFS estimations in Arlequin)?
ARLEQUIN_WRITER_ANCHESTRAL_STATE_QUESTION=
# Specify the locus/locus combination you want to write to the Arlequin file:
ARLEQUIN_WRITER_LOCUS_COMBINATION_QUESTION=
# Specify the DNA locus you want to write to the Arlequin file or write "CONCAT" for concatenation:
ARLEQUIN_WRITER_CONCATENATE_QUESTION=
実は、後から出てくる実際のSPIDのファイルを見ると分かるが、SPIDファイルの変数には、true/falseを引数としてとるものもあれば、任意の変数をとるものなどが混在している。しかし、このテンプレートからは読み取ることができない。
その場合、GUI版でSPIDファイルのテンプレートを作ってしまうのが最短 である。
GUI版でのSPIDファイルの設定
GUI版のインストール方法は割愛。
GUI版を起動するとこんな画面になる。
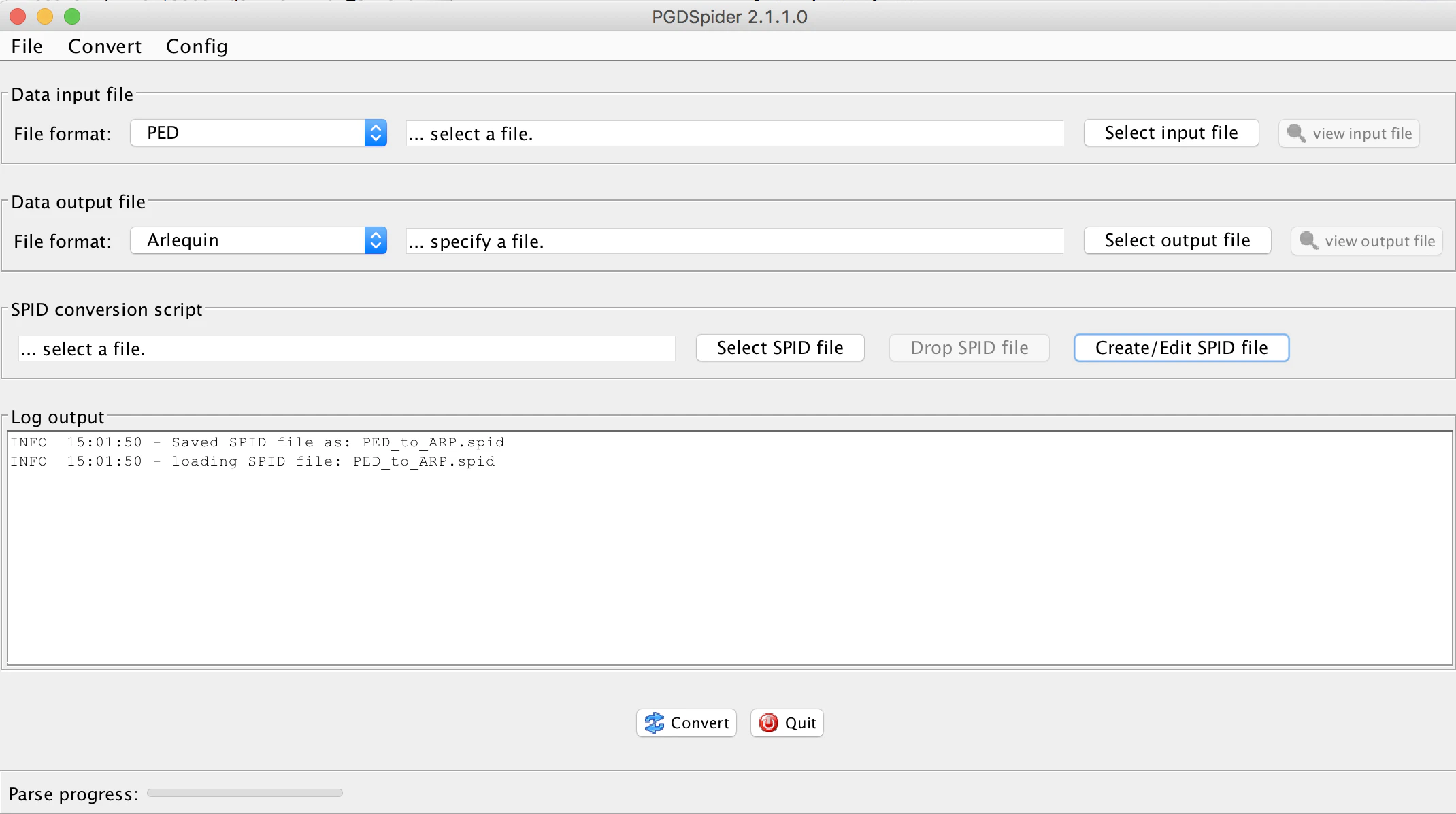
この画面では、"Data input file"と"Data output file"について、file formatと、ファイル名を選択する。SPIDファイルはただのテキストファイルであるので、ファイル名はダミーのファイルにしておいて、後で修正すれば良い。
そして"Create/Edit SPID file"をクリックする。(スクリーンショットはPED -> Arequin の場合)
するとこのような画面が出てくるので、適当にオプションを選択する。これらのファイル形式を使ったことのある人だったら、問題ないと思われる。
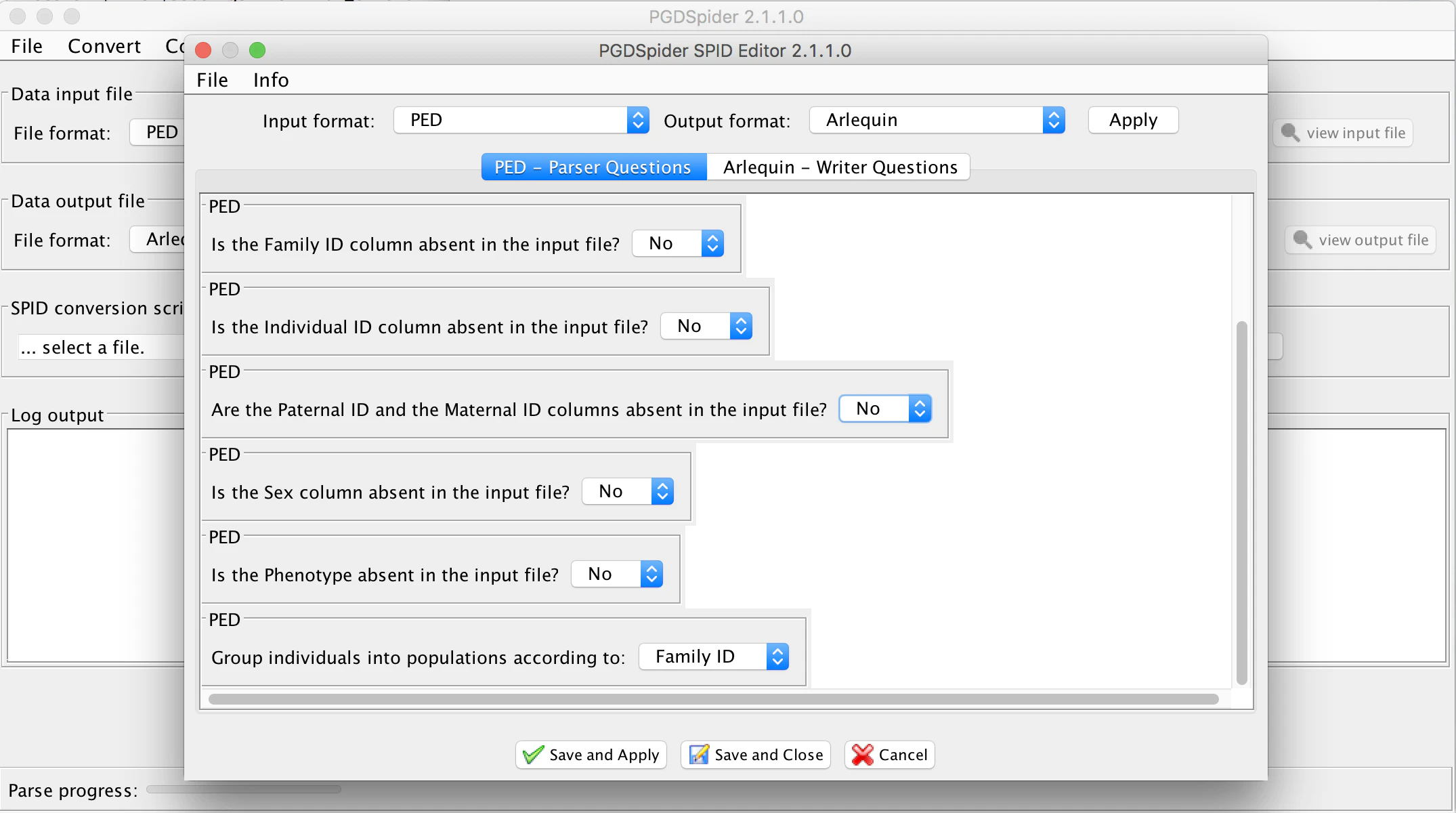
"Save and close"をクリックすると、SPIDファイルを保存できる。ファイル形式特有の設問もあるので、input-outputの組み合わせ毎にSPIDを保存しておく必要がある。
上記の方法で作成されたPED => ArlequinのSPIDは以下の通り。ファイル名やオプションなどを適時修正する。
$ cat ped_to_arlequin.spid
# spid-file generated: Mon Feb 05 15:01:50 JST 2018
# PED Parser questions
PARSER_FORMAT=PED
# Is the Sex column absent in the input file?
PED_PARSER_SEX_QUESTION=false
# Do you want to include a MAP file with loci information?
PED_PARSER_INCLUDE_MAP_QUESTION=false
# Is the Phenotype absent in the input file?
PED_PARSER_PHENOTYPE_QUESTION=false
# Open MAP file
PED_PARSER_MAP_FILE_QUESTION=sample.map
# Is the Individual ID column absent in the input file?
PED_PARSER_IND_ID_QUESTION=false
# Are the Paternal ID and the Maternal ID columns absent in the input file?
PED_PARSER_PATERNAL_MATERNAL_ID_QUESTION=false
# Is the Family ID column absent in the input file?
PED_PARSER_FAMILY_ID_QUESTION=false
# Group individuals into populations according to:
PED_PARSER_POPULATION_QUESTION=FAMILY
# Arlequin Writer questions
WRITER_FORMAT=ARLEQUIN
# Specify which data type should be included in the Arlequin file (Arlequin can only analyze one data type per file):
ARLEQUIN_WRITER_DATA_TYPE_QUESTION=SNP
# Do you want to convert SNP/DNA to numeric format with 0 representing anchestral state (for derived (unfolded) SFS estimations in Arlequin)?
ARLEQUIN_WRITER_ANCHESTRAL_STATE_QUESTION=false
# Specify the locus/locus combination you want to write to the Arlequin file:
ARLEQUIN_WRITER_LOCUS_COMBINATION_QUESTION=
# Specify the DNA locus you want to write to the Arlequin file or write "CONCAT" for concatenation:
ARLEQUIN_WRITER_CONCATENATE_QUESTION=
EIGENSTRAT => Arlequin形式のSPIDファイルはこんな感じ.
cat egensoft_to_arp.spid
# spid-file generated: Fri Jan 19 12:36:15 JST 2018
# EIGENSOFT Parser questions
PARSER_FORMAT=EIGENSOFT
# Open indiv file
EIGENSOFT_PARSER_IND_FILE_QUESTION=sample.ind
# Select the format of the genotype file:
EIGENSOFT_PARSER_GENOTYPE_FILE_QUESTION=EIGENSTRAT
# Open snp file
EIGENSOFT_PARSER_SNP_FILE_QUESTION=sample.snp
# Arlequin Writer questions
WRITER_FORMAT=ARLEQUIN
# Specify which data type should be included in the Arlequin file (Arlequin can only analyze one data type per file):
ARLEQUIN_WRITER_DATA_TYPE_QUESTION=SNP
# Do you want to convert SNP/DNA to numeric format with 0 representing anchestral state (for derived (unfolded) SFS estimations in Arlequin)?
ARLEQUIN_WRITER_ANCHESTRAL_STATE_QUESTION=false
# Specify the locus/locus combination you want to write to the Arlequin file:
ARLEQUIN_WRITER_LOCUS_COMBINATION_QUESTION=
# Specify the DNA locus you want to write to the Arlequin file or write "CONCAT" for concatenation:
ARLEQUIN_WRITER_CONCATENATE_QUESTION=
"PED Parser questions"や"EIGENSOFT Parser questions"では、PGDSPider本体のinputfileオプションの引数ではとれなかったファイルの指定をする。具体的には、PEDを変換したい場合、PGDSpiderの本体では.pedファイルを指定し、.mapはこちらに記載する。またEIGENSTRATを変換する場合、PGDSpiderでは.genoファイルをinput fileの引数に取っていて、残りの.snpと.indファイルはSPIDで指定する。
下の方の"Arlequin Writer questions"は、Arlequin形式の中でのオプションの指定方法。今回はSNPs(SNPアレイ)のデータなので、"ARLEQUIN_WRITER_DATA_TYPE_QUESTION"はSNPとする。Arlequinファイルの上位の[Profile]に書く内容と同じなので、ここのあたりはArlequinのファイル形式を確認する。
SPIDファイルを使って変換する
java -Xmx2048m -Xms1024m -jar ~/opt/PGDSpider_2.1.1.3/PGDSpider2-cli.jar -inputfile sample.geno -outputfile sample.arp -outputformat ARLEQUIN -spid egensoft_to_arp.spid
INFO 14:15:29 - load PGDSpider configuration from: /opt/PGDSpider_2.1.1.3/spider.conf.xml
initialize convert process...
read input file...
read input file done.
write output file...
write output file done.
コンバートできた。中身をチェックする。
出来上がったSPIDは(ファイル変換の組み合わせ毎に)、適時ファイル名やオプションを修正して使い回せばよい。
なぜCUI版?
一度GUI版を起動するくらいならば、GUI版を使えば良いではないかと思われるかもしれないが、大きなファイル(10GBとか) の変換には大量のメモリを使用する。ラップトップやデスクトップではできないことがあるので、そのようなときは解析サーバでCUI版を使用することになる。