(ブログ記事からの転載)

データサイエンスコンペの題材としてデータ公開する際、プライバシー保護は避けて通れない論点と考え「データ解析におけるプライバシー保護(佐久間淳)」を読んだのですが、非常によくまとまっていたので、重要と考えた点をまとめます。
そして願わくば、プライバシー保護についてよくわからないままにデータ公開を避けたり、あるいは推進したりする、思考停止した残念な人種が少しでも減ればと思います。
結構いると思うんですよね、こういう人種。
QA形式で、データ提供者が、いの一番に気になるであろう点をまとめてみました。
内容は私見を加えた上でまとめているので、詳細は原著を読んで確認してください。
尚、「機械学習用・・・」というタイトルにしていますが、個人情報を含み得るデータを公開する場合には、共通して考慮すべき内容と考えます。
Q1. 本のタイトルは「プライバシー保護」になっているけど、個人情報保護とプライバシー保護って同じもの?違うもの?
一言で言えば、個人情報保護は法令に基づき遵守すべきもの、プライバシー保護は世論の反応も鑑みて行うべきもの、です。
従って、個人情報に該当するかグレーな場合でも、プライバシー保護に配慮したデータ加工などをしてからでないと公開しない、という判断は十分あり得えます。
例えば、メールアドレスは個人情報であるか否かグレーな情報ですが、かと言って杜撰な取り扱いをしてよいデータかと言えば、プライバシー保護の観点では良くないという世論が主流と考えられ、相応の対応が必要だと言えます。
Q2. そもそも「個人情報」って具体的に何?
日本の個人情報保護法で定められている「個人情報」の定義は以下の通りです。
生存する個人に関する情報であって、当該情報に含まれる氏名、生年月日その他の記述等により特定の個人を識別できるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)
しかし、マイナンバーや氏名などは明らかに個人情報であると分かりますが、グレーな情報も数多く存在します。
例えば、メールアドレスやSNSアカウント情報など、個人の活動にかかわる様々な情報を蓄積した情報は、法律の枠組みでは個人情報に該当するか明確ではありません。
ただ繰り返しになりますが、個人情報だと明確に言えない情報も、先に述べたプライバシー保護の観点からは保護すべきという世論が優勢なら、データ公開者もその世論に配慮すべきと言えます。
Q3. プライバシー保護って、氏名とかマイナンバーとか、個人を特定できるものを除けば良いと思っていたけど、それじゃダメなの?
最低限の対応としては必須ですし正しいですが、それだけでプライバシー保護上のリスクがなくなるわけではありません。
具体的にどんなリスクがあるか、書籍で説明されています。
日本の個人情報保護法で、明確に配慮が必要なリスクは「特定」「連絡」「直接被害」の3種類です。
さらに言えば、パーソナルデータ提供におけるプライバシー上の問題は5種類に分けられます。
-
特定:ある個人と一意に結びつく情報(マイナンバーや運転免許番号など)が取り除かれ、どの個人に関するデータかわからないデータについて、そのデータを該当する個人と再び結びつけること
-
連結:ある個人に関するデータを、同一人物に関する別のデータと結びつけること(個人の特定がされている・いないに関わらない)
-
属性推定:ある個人に関するデータの一部が削除、あるいは抽象化されているときに、それを復元あるいは推定すること(個人の特定がされている・いないに関わらない)
-
連絡:ある個人に関するデータを保持するものが、何らかの手段でその個人に連絡すること
- 個人を特定しないまま、入手したメールアドレスを通じて連絡するのは、「特定を経ない連絡」
-
直接被害:ある個人に関するデータを保持するものが、その個人に直接的な被害を与えること
- クレジットカードの無断使用、SNSアカウントの無断停止など
この中で「連絡」「直接被害」は分かりやすいと思いますが、「特定」「連結」「属性推定」について具体例で補足します。
「特定」「連結」の事例
マサチューセッツ州のGroup Insurance Comission(GIC)が提供した、州職員とその家族についての医療保険データについて、個人を特定する情報が取り除かれていたはずが、外部データである選挙人名簿との照合によって再び個人が特定できる情報に復元されてしまったケースです。
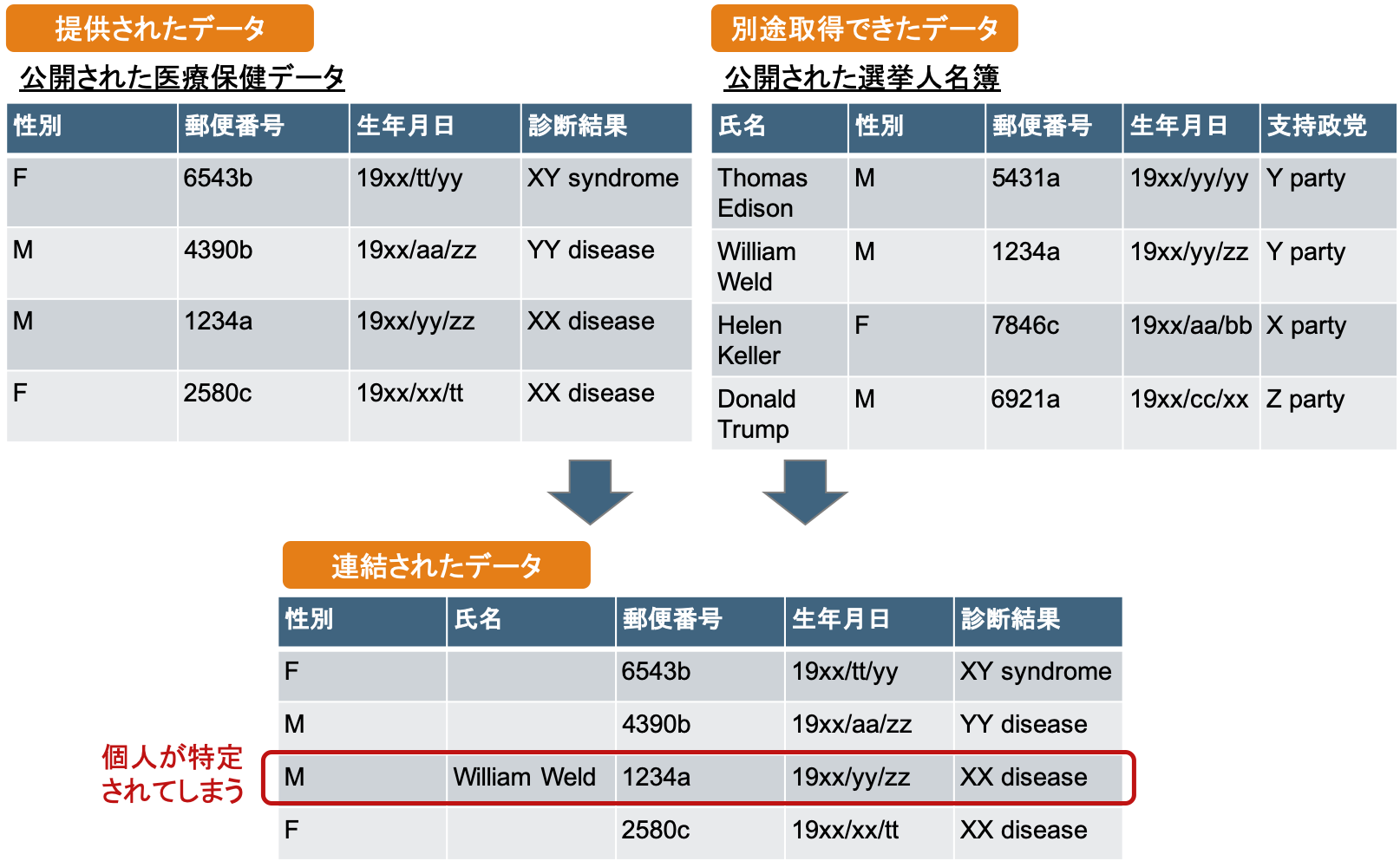
当時のマサチューセッツ州知事のWilliam Weldは、ケンブリッジ在住でした。ケンブリッジの選挙人名簿によれば、6人が彼と同じ生年月日で、うち3人が男性、同じ郵便番号の人は他にいませんでした。
よって、提供情報のみからWilliam Weldの診断結果や利用内容を知ることができた、というケースです。
これは、医療保険データの側から見れば、選挙人名簿の情報を用いて「特定」が発生しており、
選挙人名簿の側から見れば、医療保健データの情報を用いて「連結」が発生したという問題です。
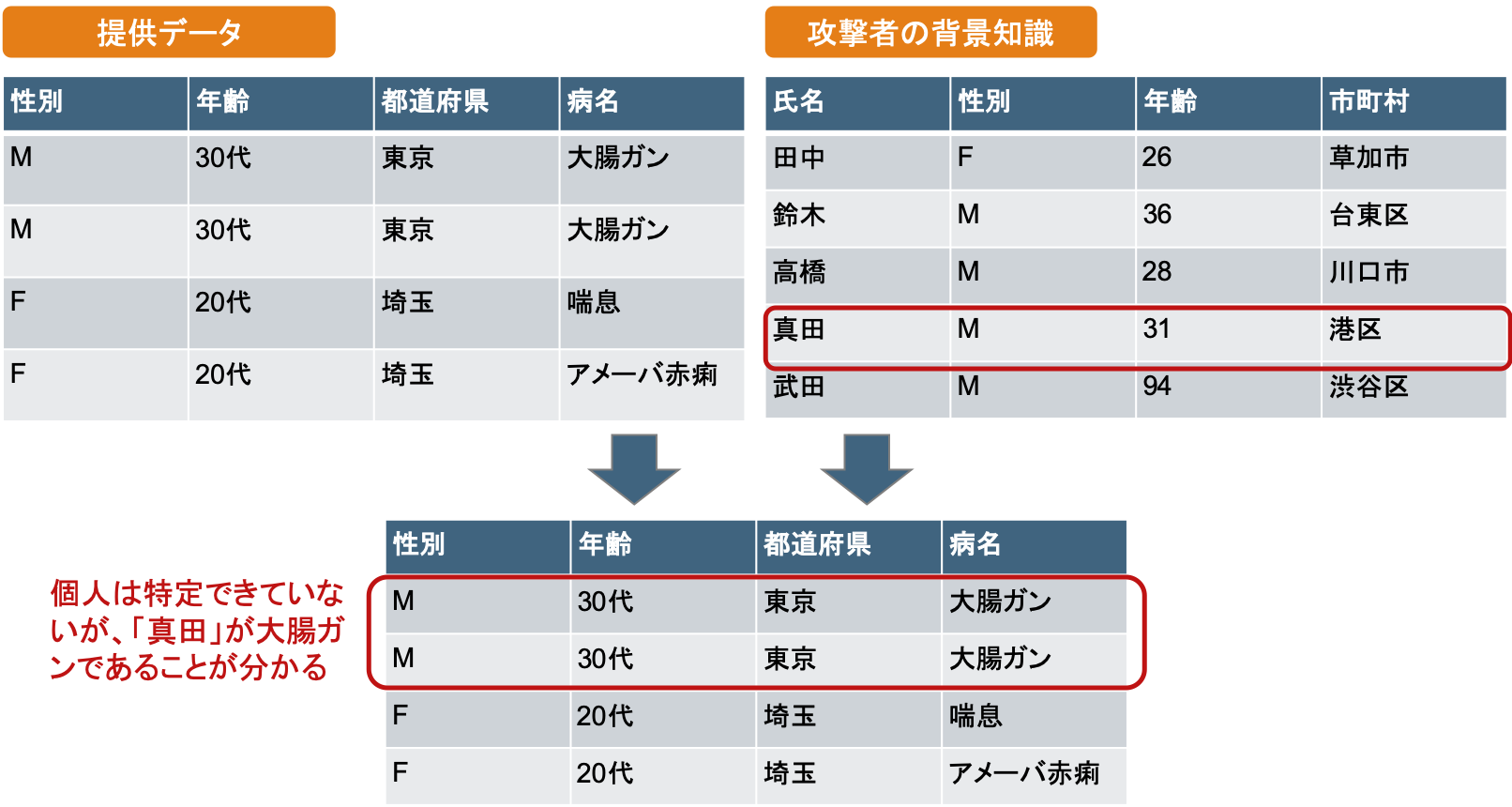
「属性推定」の事例
氏名情報を持たず・病名情報を持つパーソナルデータが提供され、攻撃者(データ利用者)側が氏名情報を持ち・病名情報を持たないデータを保有していたとします。
このとき、特定を伴わずとも個人の属性情報が確定的に知られるリスクがあります。
Q4. 結局、プライバシー保護のためにはどこまで気をつけたら良いの?
Q3の事例の通り、プライバシー上の問題が起こるリスクは攻撃者側が保有するデータにも依存するため、リスクが絶対的に0になることはありません。
かと言って、リスクを0に近づけるために匿名化などのデータ加工を繰り返すと、データの有用性が下がり、当初の目的であるデータ解析が実現できなくなってしまいます。
現実的な落とし所は、
「機械的に照合可能な直接/間接識別情報(※)を経由した特定は、仮名化/匿名化の技術により防ぎつつ、高度なデータ解析技術による特定は法制度によって禁じる」
という対処になると考えられます。
※ 直接識別情報、間接識別情報をはじめとするパーソナルデータの種別は、書籍の中で以下のように定義されています。
-
直接識別情報:それ単体で直接に個人の特定を可能にする情報
- マイナンバー、運転免許番号など
- 氏名は同姓同名者がいることもあるため常に特定可能ではないが、データベースが限られた特徴を持つ個人の集団であれば同姓同名者が存在する可能性は低いため、直接識別情報に準ずる情報と言える
- 具体的に住居が特定できる住所は、世帯についての直接識別情報と解釈することもできる
-
間接識別情報:個人に関する不変な情報で、それ単体は個人を識別可能な状態にしないが、複数組み合わせることで個人を識別し得る情報
- 生年月日、年齢、性別、具体的に住居が特定できない住所など
-
履歴情報:個人の活動にかかわる履歴の情報
- 個人による購買行動、移動行動、Web検索行動など
- 直接・間接識別情報と履歴情報は外形的には異なるが、境目は必ずしも明確でない。例えば特定の店舗での頻繁な購買履歴は、その人物の住居や職場を推測させ、間接識別情報としての性格を持つ
-
要配慮情報:特定とは直接結びつかないが、それ単体の取り扱いに配慮が必要な情報
- 人種、国籍、宗教、犯罪歴、病歴、妊娠状態など
- 日本の個人情報保護法では、人種・信条・社会的身分・病歴・犯罪歴などを要配慮個人情報として、個人情報よりも慎重な扱いを求めている(本人同意を得ていない取得を原則禁止している)
-
連絡情報:特定の個人への連絡を可能とする情報
- 住所、電話番号、メールアドレスなど
- 連絡に個人の特定は必ずしも必要ない。誰のものかわからない電話番号は、背景知識なしに特定は起こらないが、対象の個人への連絡は可能
-
個人に被害を与える情報
- クレジットカード番号や銀行口座の暗証番号など
-
データベースに関する情報
- 多数の個人から収集したデータについては、対象とするデータがどのような集団か、それが標本調査か全数調査か、標本調査なら標本がどのような条件で抽出されたのかというデータベースそのものに関する情報は、そのデータセットが持つプライバシー上のリスクを評価する上で重要
- 従ってデータベースに関する情報が提供されることが、プライバシー上のリスクを増大させることにつながる
Q5. 定量的に、このレベルまでは匿名化などのデータ加工をした方が良いという基準はあるの?
Q3で挙げたデータ提供に伴うリスクのうち、「連絡」「直接被害」は"自明な"リスクと言え、これを可能にする情報(「連絡」なら電話番号やメールアドレス、「直接被害」ならクレジッドカード番号やパスワード)を事前に削除することで防げるので、まずこの対応をすべきです。
問題は「特定」「連結」「属性推定」といった"非自明な"リスクへの対応です。
結論から言えば、特定性を下げるためのデータ加工の要求水準は、決まった基準はありません。
実際、リスクが絶対的に0にならない以上、どこまでデータ加工をすれば良いか?という問いには誰も答えを持たないと思います。
ただ、特定リスクを定量的に評価する指標は存在します。本記事では、$k$匿名性と$l$多様性について紹介します。
k匿名性
$k$匿名性は、簡単に言えば間接識別情報の値の組み合わせが同じデータのレコードが、少なくとも$k$個存在するならば、そのデータは$k$匿名性を持つ、と言えます。
具体例で説明します。下表のデータが提供されたとします。
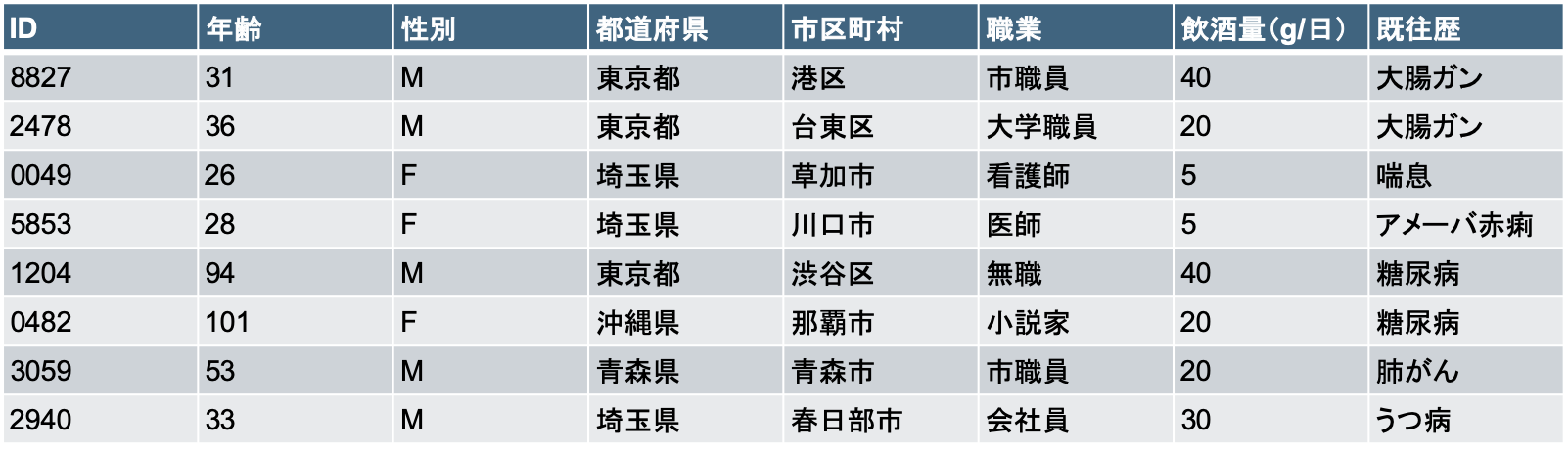
このとき、もし攻撃者側が、このデータの中で「東京都港区在住の31歳の男性は山本だ」という背景知識を持っていたら、「山本は大腸ガンである」ということが特定できてしまいます。
そこで、この表の一部にマスクをかけて、下表のようにしたとします。
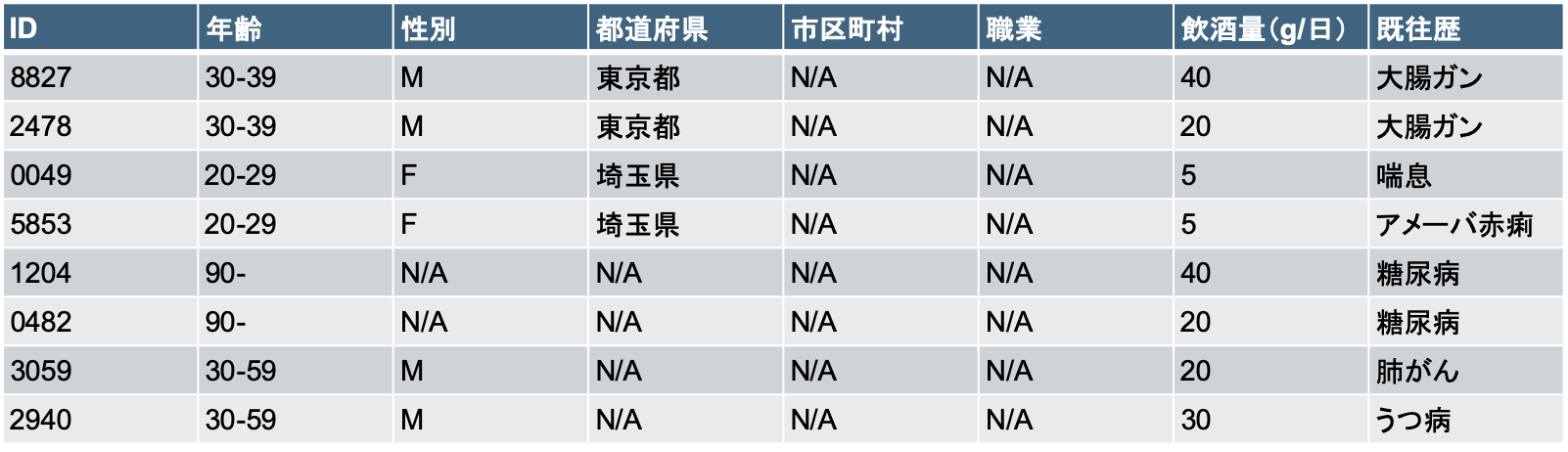
ここで、「東京都在住の30-39歳の男性」は2人存在するので、背景知識に対応するレコードを1件に絞ることはできません。
このとき、本表は2匿名性を持つ、と言えます。
l多様性
Q3でも示した、下表の例について改めて考えます。
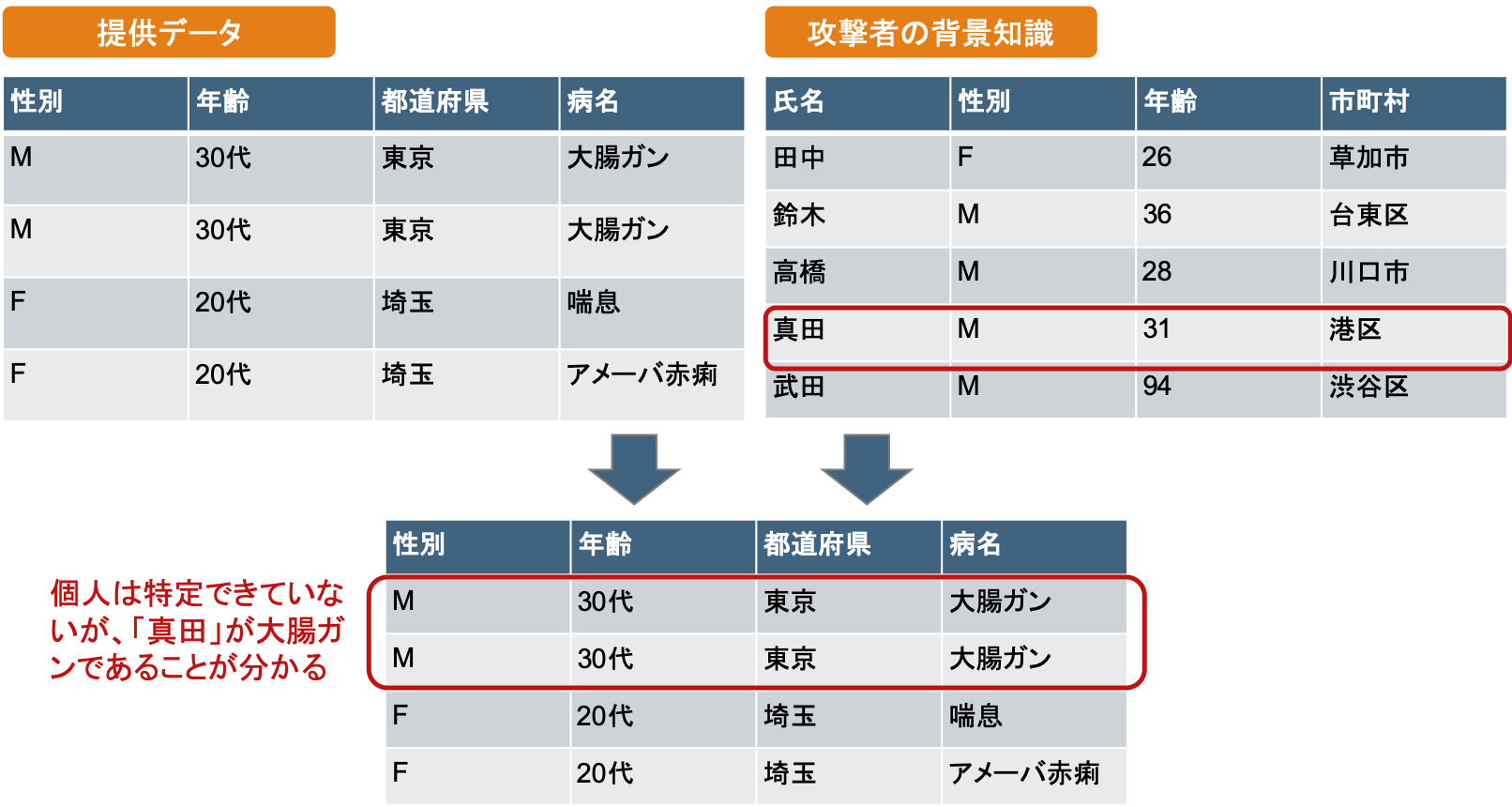
このような特定を伴わない確定的な属性推定は、同一の間接識別情報を共有するレコード同士で、要配慮情報が全て同じ値をとっていたために起こります。
逆に言えば、ここで要配慮情報が多様な値をとっていれば、このような属性推定のリスクは低減できます。
$k$匿名性を持つデータの、間接識別情報の属性値の組み合わせが同じであるレコードについて、要配慮情報の属性値のバリエーションが少なくとも$l$存在しているなら、これを$l$多様性と呼びます。
例えば、既出の下表では、ID8827, ID2478のレコードの組は既往歴がどちらも大腸ガン、ID1204, ID0482の組はどちらも糖尿病で、多様性はありません。
一方、ID0049, ID5853の組は既往歴が喘息とアメーバ赤痢で異なっており、2多様性が保証されています。
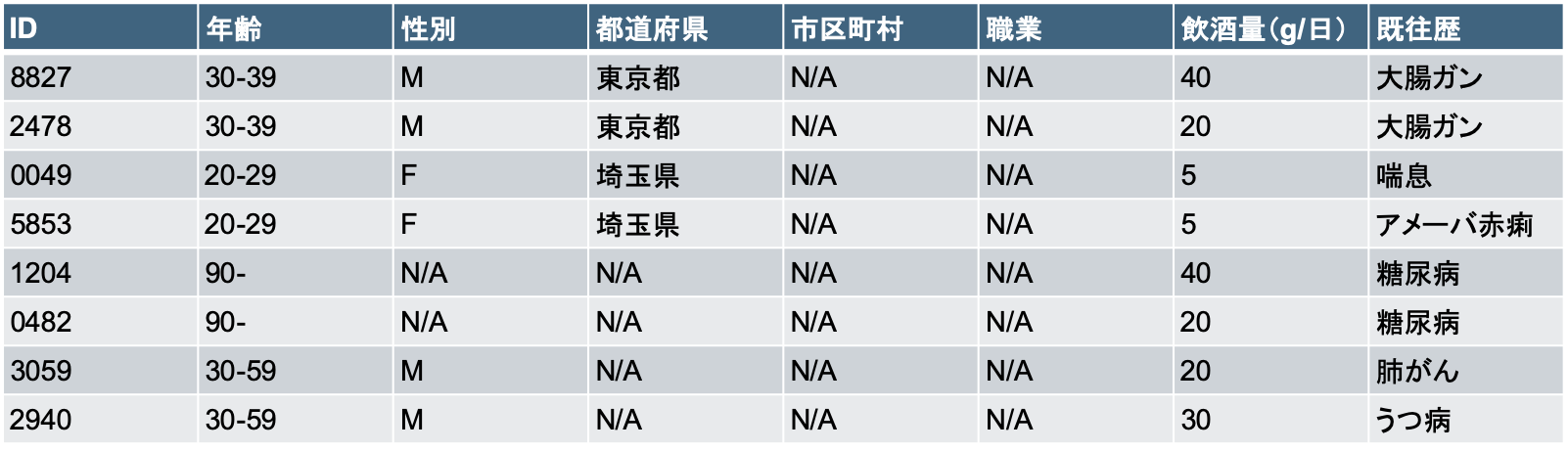
表全体で2多様性を維持するには、多様性のない組のどちらかの既往歴をマスクするか、偽の情報を敢えて混入し、多様化するなどの方法が考えられます。
Q6. データ提供の際、事前にどのようなデータ加工を行なっておくべき?
仮名化
直接識別情報を特定性を持たない仮名IDに置き換える処理を「仮名化」と言います。
仮名IDを生成する最も単純な方法は、下図のように各々の直接識別情報に対応する仮名IDを、重複がないようにランダムに生成し、対応表を作成する方法です。
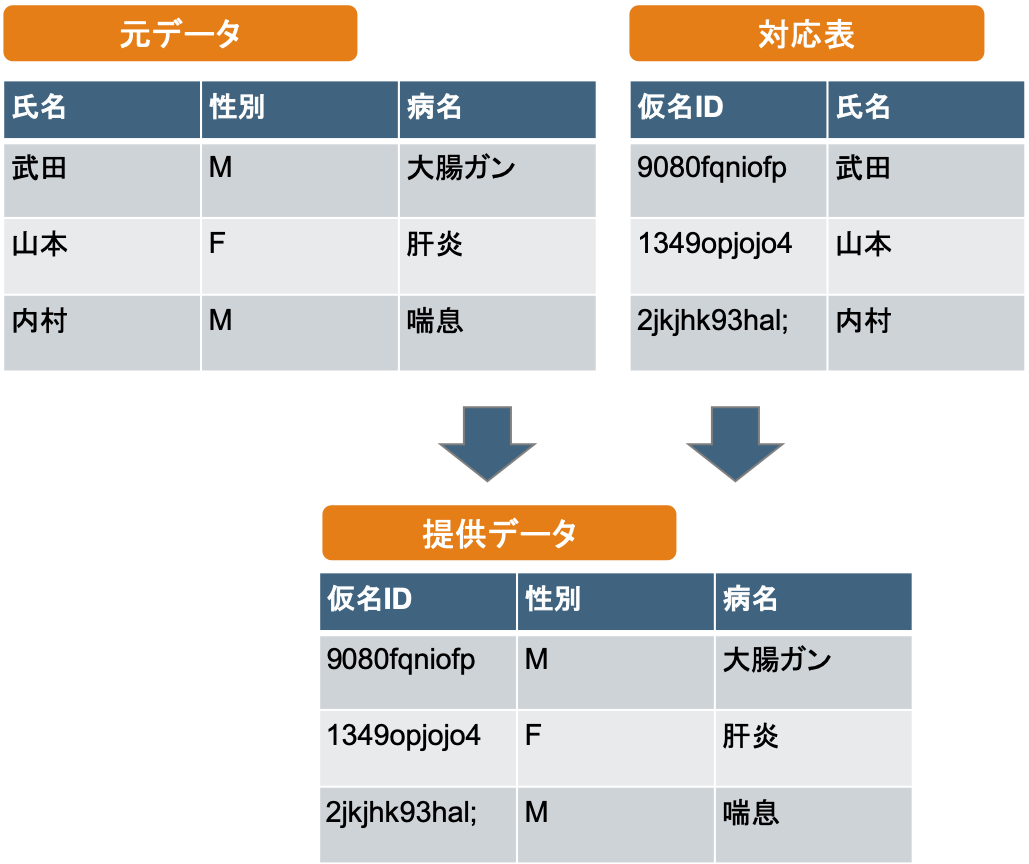
対応表による仮名化では、ある仮名IDから元の直接識別情報が推測できる確率は$1/n$で、ランダム推測と変わらない確率となるので、最も安全な仮名IDの生成方法と言えます。
但し欠点としては$n$人の人物を含むデータの仮名化を対応表を用いて行うには、直接識別情報が$L$bitの情報で構成されている場合、データサイズ$O(Ln)$の対応表を永続的に保持しておく必要があります。これを嫌えば、鍵付きハッシュ関数による仮名化などの手段を考えることになります。
匿名化
間接識別情報を加工し特定性を低減させる処理を「匿名化」と言います。特に、表形式のデータが$k$匿名性を満足するように加工することを$k$匿名化と呼びます。
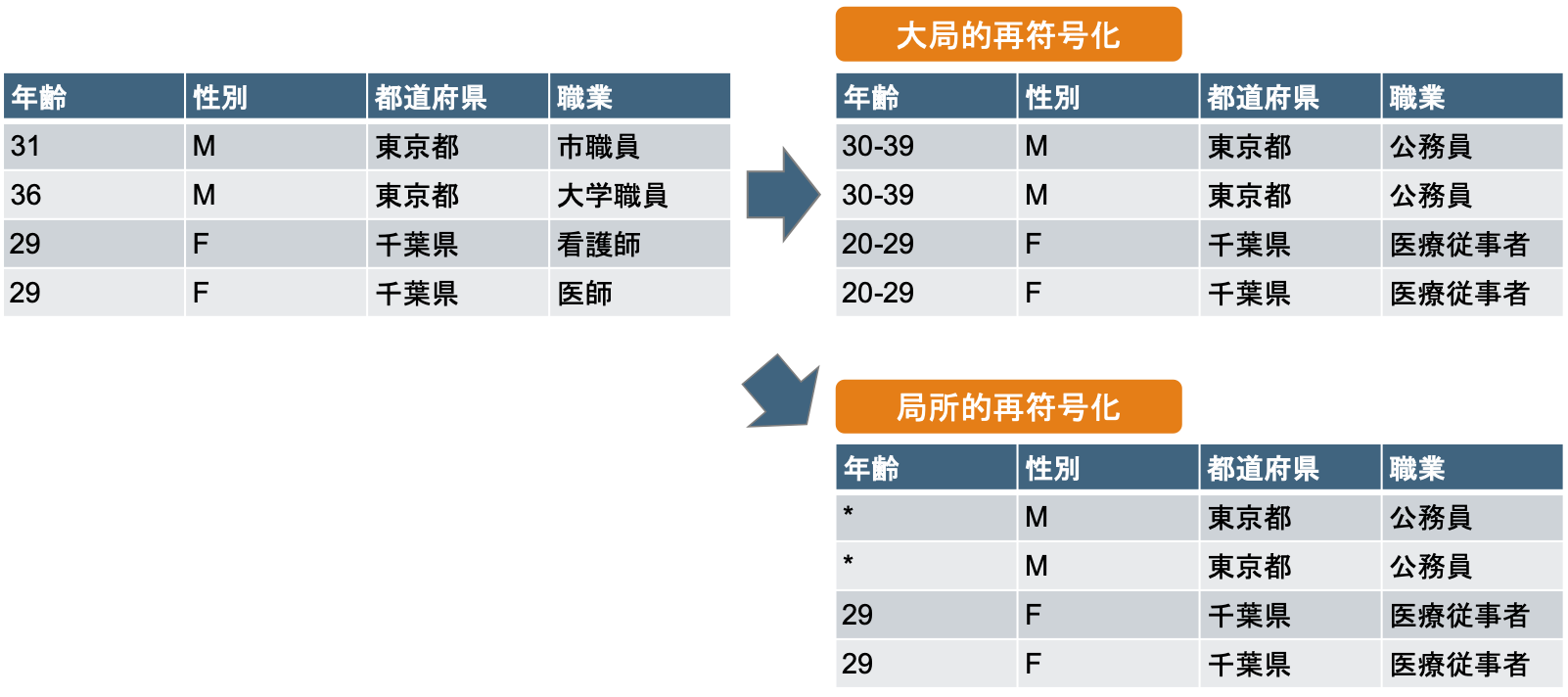
$k$匿名化のための手法として、再符号化、トップコーディング・ボトムコーディング、抑制など、書籍中でいくつか紹介されています。その中の1つ、再符号化について説明します。
再符号化
再符号化はカテゴリカル属性あるいは順序属性のための加工手法で、大域的再符号化と局所的再符号化の2種類があります。
大域再符号化は、複数のカテゴリ値を1つのより抽象度の高いカテゴリ値に統合します。
例えば、年齢属性を1歳刻みの値から10歳刻みの値にしたり、職業属性をグループにまとめ「医師」「看護師」をいずれも「医療従事者」とするなどです。
局所的再符号化は、$k$匿名性を達成したい任意のレコード群を選んで再符号化します。
下表の例だと、女性2人は年齢が同じのため職業を「医療従事者」とすることで2匿名性が達成でき、男性2人は年齢が異なるため職業を「公務員」とした上で年齢をマスクすることで、2匿名性が達成できます。
仮名化・匿名化に加えて
仮名化・匿名化を行なった上で、留意すべき点があります。例えば、履歴データの場合は同一個人が長期に渡って追跡されると、購買履歴などから住所・職場を特定される可能性があるので、一定期間ごとに仮名IDを変更しつつ仮名化する、といった対応がとられることもあります。他の留意点も書籍中でいくつか言及されています。
まとめ:データ公開を推進する立場として
私はデータ公開を推進する立場なわけですが、「プライバシー保護は世論の反応も鑑みて行うものである」という記述を読み、究極、「自分のデータをどんな形であっても使われるのは嫌だ!」という個人が日本の多勢を占めようものなら、一度データ活用先進国に経済的に叩きのめされるしかないかな、と厭世的な気持ちになりました。
しかし翻って私の周囲では、「いやいやプライバシー保護も行き過ぎじゃないの?使うべきところでは使わないとダメでしょ。」という意見が多勢を占めます。
この意見にどのくらいバイアスがかかっているか分かりませんが、決してマイノリティではないと信じてみたいです。
そうなると、データ公開が推進されるか否かは、データ提供者がデータ活用の有用性とリスクを天秤にかけ、どのような判断をするかの問題になってきます。
まずは、リスクとは何か?を定性・定量的に評価した上で取組のGo/NoGoを判断する組織をもっと増やし、そうでない組織を死滅させるしかありません。
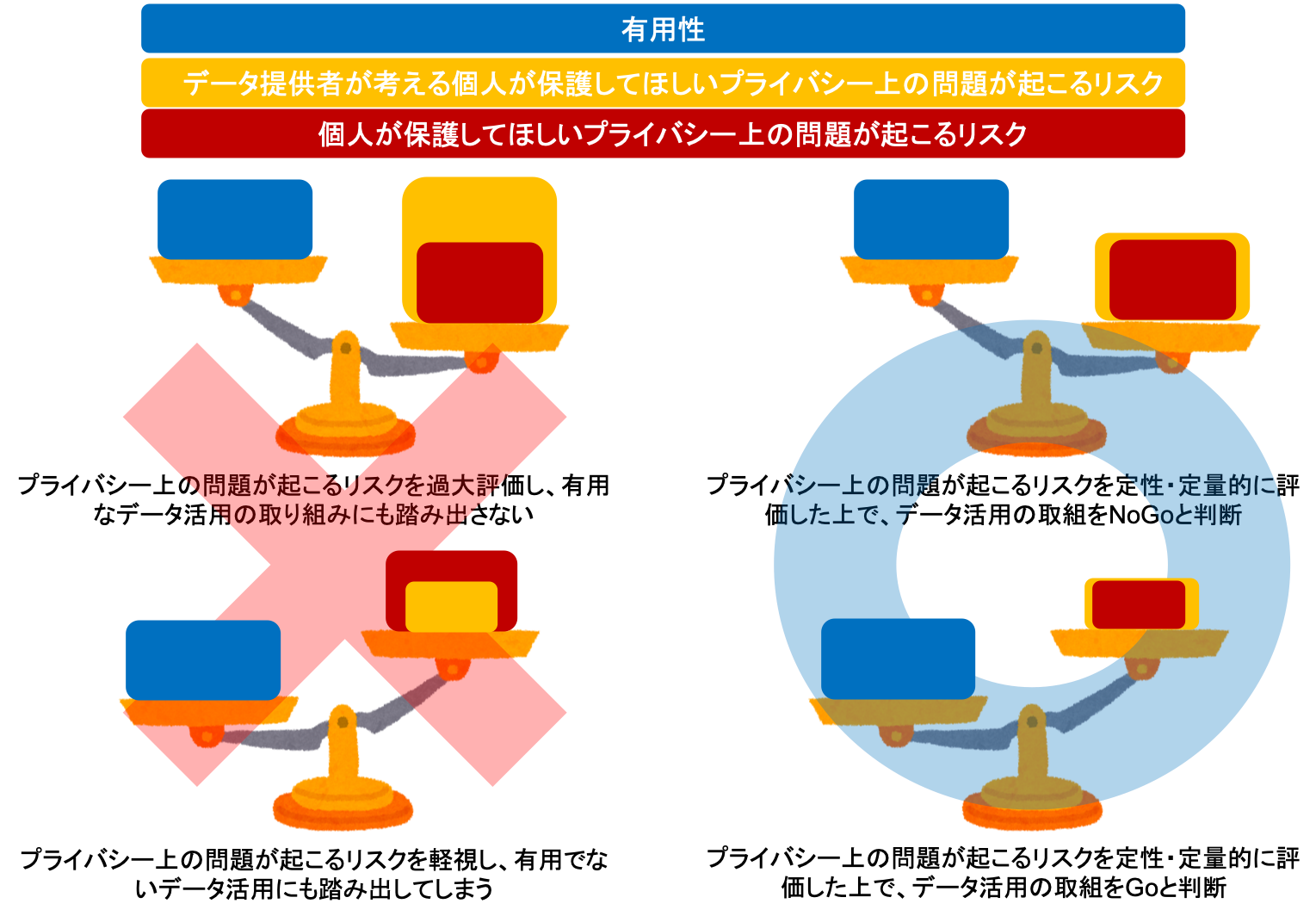
そして、データ活用の有用性ももっと発見・共有される必要もあります。
ここはデータサイエンティストの方々も含め、我々が、データを活用することでこんな未来が開けるという可能性をできるだけ多く・大きく示していくことしかない、と決意を新たにしました。
長文となりましたが、以上です。
本記事は書籍の前半部をまとめたもので、書籍の後半部ではプライバシー保護を達成するための技術についても詳細に書かれています。
そちらに関心のある方は、是非書籍を手に取ってみていただければと思います。