プロダクション環境の機械学習システムを構築・運用する機会がなかなかないので、まずは座学から入ることにして、CourseraでGoogle Cloudが提供しているProduction Machine Learning Systemsを受講してみました。
Courseraは受講から1週間過ぎると月額課金に切り替わるシステムなので、金欠な私は怒涛のようにカリキュラムを消化してみました。
スピードを重視した弊害であまり頭に入った気がしないので、ここでまとめてみます。
本記事の内容について、正確性、詳細を求める場合は是非受講してみていただければと思います。
全体構成
プロダクション環境の機械学習システムというお題ですが、内容は幅広いです。その分1つ1つの深い掘り下げは他に譲る、という感じです。
- Architecting Production ML Systems
- プロダクション環境のMLシステムが持つべき構成要素、トレーニング・推論を静的or動的のどちらで行うかの判断基準
- Ingesting data for Cloud-based analytics and ML
- クラウド環境へのデータ投入方法
- Designing Adaptable ML Systems
- データの予期せぬ変化などに適切に対応できるMLシステム
- Designing High Performance ML Systems
- ハイパフォーマンスのMLシステム
- Hybrid ML Systems
- クラウド/エッジ/オンプレミスで稼働するハイブリッドMLシステム
一通り学習はしましたが、元々関心があったのがプロダクション環境のMLシステムの全体像だったので、ここではArchitecting Production ML Systemsを中心にまとめます。
Architecting Production ML Systems
What percent of system code does the ML model account for?という問いかけから講義が始まります。
Factはともかく、5%という答えが提示されます。なぜ5%しかないかと言えば、プロダクション環境でシステムを動かし続けるには、インプットに対してモデルがアウトプットする以上に様々な機能が必要だから。具体的には以下の機能が必要です。

確かに、サービスインまで持っていくことだけを考えると工数の割合は感覚に合います。
MLシステムの構成要素は以下のように整理されています。本講義はこの絵の1つ1つの要素を説明する形で進みます。
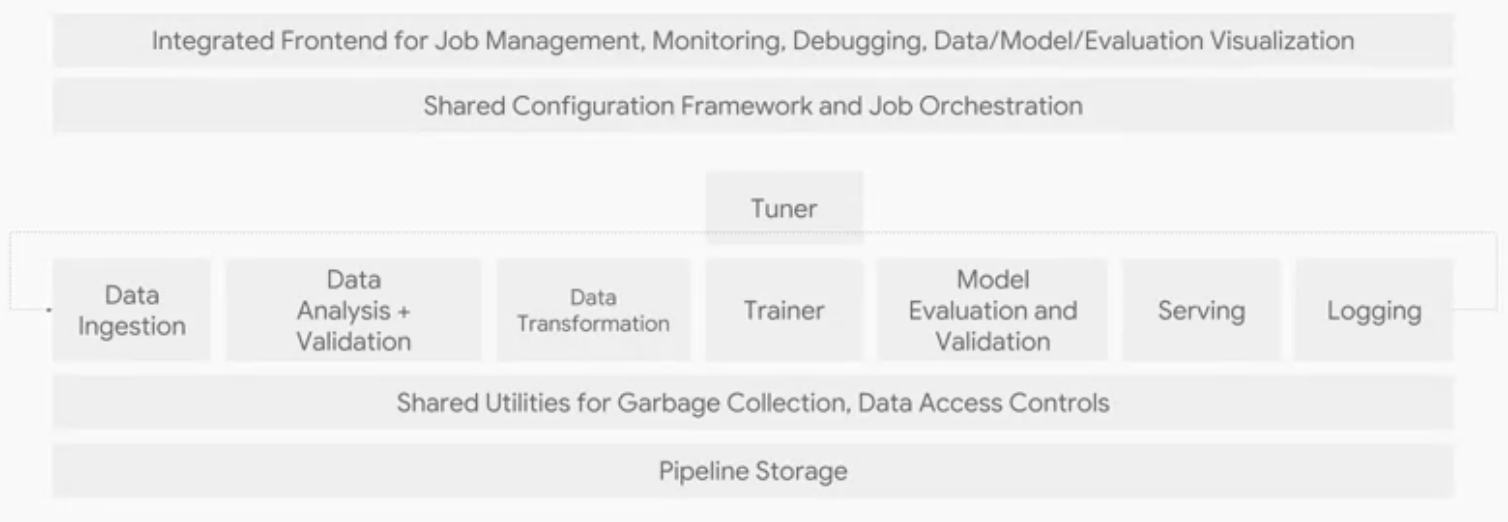
Data Ingestion
データをシステムに投入する工程です。データの投入元はアプリであったり、デバイスであったり、DBであったりします。
ingestされるデータによって、GCPでは3つのサービスが使い分けられます。大きくはストリーミングデータかバッチデータかによって分かれるところです。
- ingestされるのがストリーミングデータならPub/Sub
- 構造化データを直接モデル構築に使うならBigQuery
- 後で加工する予定のデータならCloud Storage
Data Analysis + Validation
1度MLシステムを構築したと言って安心してしまい、日々投入されるデータを確認しないと、データの予期せぬ変化に気づかずMLモデルが汚染され、おかしな学習や推論結果を吐き出してしまう可能性があります。
例えば、以下のようにカテゴリ変数として扱っていた製品番号が割り当て直された場合や、カテゴリ変数のカテゴリ数が変わった状態で改めてOne-Hotエンコーディングを行い、エンコーディングのされ方が変わった場合など、学習や推論結果が好ましくない方向に変化する可能性があります。
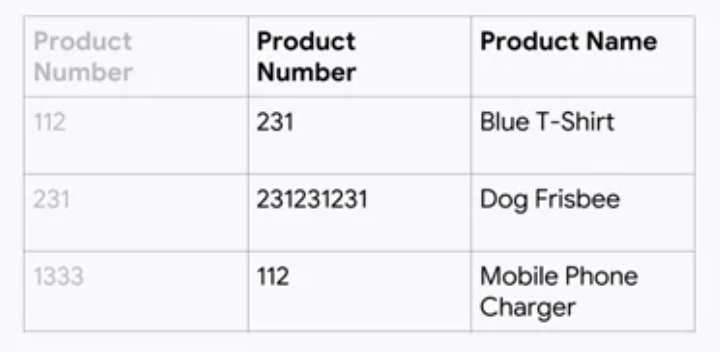
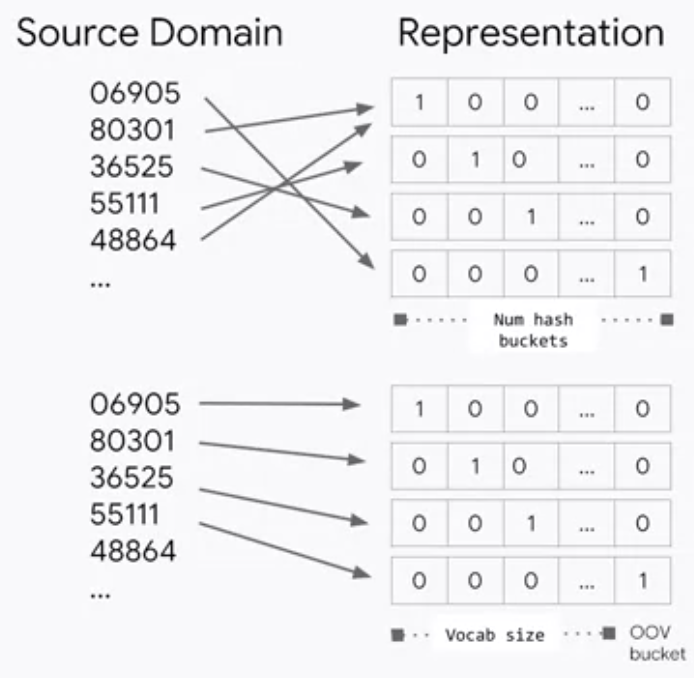
MLモデルのアウトプットは、推論結果の悪化という形で状況を知らせてくれても、それがなぜかは教えてくれません。
データの変化に気がつくには、インプットデータの分布の確認が重要です。典型的には、以下のような明らかな変化が認められれば、異常に気づくべきです。
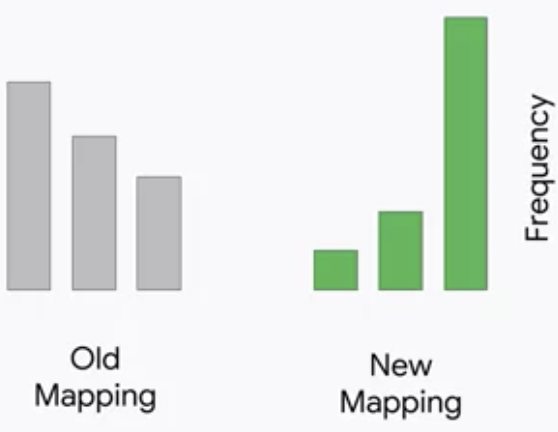
データの変化がもたらすバグについては、Designing Adaptable ML Systemsのモジュールで詳しく言及されています。
データが健全かどうかをチェックする観点として、以下6つが挙げられています。
- 新たなデータの分布は以前の分布と同様か
- 5 number summariesをチェックする
- 歪度や尖度を比較するためにユニークな値の数をカウントする
- 元の分布のもとで新たな分布が観測される確率を計算する
- 期待される全ての特徴量は存在しているか
- 期待しない特徴量は存在していないか
- 特徴量は期待する型になっているか
- 特徴量を有するサンプルの割合は期待される程度か
- 特徴量を有するサンプルにおいて、特徴量の値は期待される程度か
analysis, validationを行うサービスとして、GCPでは以下3つを提供しています。
- Datalab: スクリプトの作成・実行
- Data Studio: ダッシュボード
- Cloud Reliability: モニタリングシステム
Data Transformation
データ加工の工程です。当然ながら、学習と推論で同じデータ加工経路を辿るようにフローを設計することが重要です。
GCPでは3つのサービスを提供しています。
- Dataflow
- Dataproc
- Dataprep
これらの詳細はEnd-to-End Machine Learning with Tensorflow on GCPで言及されているようです。
Trainer, Tuner
学習およびパラメータチューニングの工程です。
GCPでは2つのサービスを提供しています。
- ML Engine: Tensorflowのマネージドサービス
- GKE(Kubeflow): KubeflowにおけるハイブリッドMLモデルのマネージド環境
ML Engineは以下の特徴を備えています。
- Scalable: 数百のワーカーまでスケールアップ可能
- Integrated with Tuner, Logging, Serving components: 他の3つの構成要素の機能も備える
- Experiment-oriented: 実験ベースの考え方で、モデルの取捨選択が可能。ABテストによるモデルの比較ができ、特定モデルによるロックインは当然なし
- Open: 構築したモデルはどこでも運用可能
ハイブリッドMLモデルおよびKubeflowは、Hybrid ML Systemsのモジュールで言及されています。
Model Evaluation and Validation
EvaluationとValidation、近しい言葉に見えますが、工程としては全く異なるものを指します。
Evaluationは、予め決めたmetricについてモデルを評価し、一定水準を超えたらプロダクションへpushする工程を指します。多くの場合人が介在するプロセスです。
Validationは、予め決めたmetricについてモデルを検証し、一定水準を下回ったらアラートを出す工程を指します。基本的に人は介在せず自動で行われるプロセスです。
尚、Evaluationではモデルを評価しますが、評価するには良いモデルとは何かを定義しなくてはいけません。
予測精度が高いものが良いモデルであることはもちろんですが、モデルがSafeであるという観点も重要です。
データをロードしたり、データを受け取って推論するときにクラッシュしない、期待している以上のリソース(メモリなど)を使わない、といったモデルはSafeだと言えます。
Serving
モデルをデプロイし、推論する工程です。
モデルの推論において重要なのは、一言で言えばスループットを最大化し、レスポンスのレイテンシを最小化することとなります。
より詳細に言えば、システム上で推論を担う構成要素に求められるものは、以下4つになります。
- Low-latency: 早く推論できる
- High efficient: 多くのインスタンスを同時実行できる
- Scale horizontally: 起こる問題に対してロバストで信頼できる
- Easy to update versions: 柔軟にモデルのバージョンをアップデートできる
GCPのサービスはこの4つの観点を充足できるぞ、というアピールですね。
Orchestration
なぜorchestrationが重要かと言えば、MLシステムは一部の構成要素に変更があっただけで他のほとんどの要素も影響を受けるためです。
具体的には、全ての構成要素がリソースとコンフィギュレーションフレームワークを共有することが重要です。
共有がなかったときのことを想像してみれば、その重要性が分かります。
共有がなければ、大量のglue codeが生み出されることになります。確かに、想像したくない(けど容易に遭遇する)事態ですね。
glue codeが発生する典型例は、researchとengineeringが組織的に分断されているケースです。
research側の独自環境でプロダクションで動かすことを想定していないコードが生み出されると、glue codeがなければプロダクションで動かない、という状況に陥ってしまいます。
この問題に対する処方箋は、システム面ではR&Dとproduction deploymentで共通のアーキテクチャーを用いること、組織の面では両チームを束ねること、とまとめられています。
当たり前じゃないかと思われるかもしれませんが、この点に言及した勉強会やLTをよく拝見することから、実はそう簡単なことではなく、思った以上に重要性は高いと言えると思います。
GCPでは2つのサービスが提供されています。
- Cloud Composer: managed Apache airflow
- Argo on GKE: container management tool
Cloud Composerでワークフローを定義する手順は以下の通りです。
- オペレーションフローを定義
- フローをDAGとして作成
- DAGを環境にアップロード
- Web UIでExplore DAG Run
この講義ではCloud Composerの詳細には立ち入らないということでしたが、サンプルコードを示してくれていました。
# BigQuery training data query
t1 = BigQueryOperator(params)
# BigQuery training data export to GCS
t2 = BigQueryToCloudStorageOperator(params)
# ML Engine training job
t3 = MLEngineTrainingOperator(params)
# App Engine deploy new version
t4 = AppEngineVersionOperator(params)
# Establish dependencies
t1 >> t2 >> t3 >> t4
Training Design Decisions
トレーニングのデザインというタイトルですが、静的トレーニングと動的トレーニング、どちらを選ぶか?という論点について議論されています。
| 静的トレーニング済みモデル | 動的トレーニング済みモデル |
|---|---|
| 学習は一度、オフラインで良い | 時間と共に学習データが追加される |
| ビルド、テストが容易 | エンジニアリングがより大変、より積極的なvalidationが求められる |
| 容易に古くなる | 定期的にアップデートされ変化にも対応していく |
具体的なユースケースでどちらを選ぶべきか見てみましょう。
| ユースケース | トレーニングスタイル |
|---|---|
| スパムメールの検知 | 静的or動的(スパムの変化速度による) |
| スマーフォトンのVoice2Text機能 | 静的(グローバルに使うモデルなら)、動的(パーソナライズするモデルなら) |
| 広告のConversion Rate | 静的(多くの場合ユーザーの購買間隔は長く、購買行動の変化も緩やかなので、頻繁な再トレーニングの必要性は低い) |
多くのケースで動的トレーニングはより好ましいものだが、エンジニアリングに工数がかかるので、まず静的トレーニングから始めるのが多くの場合現実的ではないか、と結ばれています。
静的トレーニングのアーキテクチャは以下の通りシンプルなものになります。
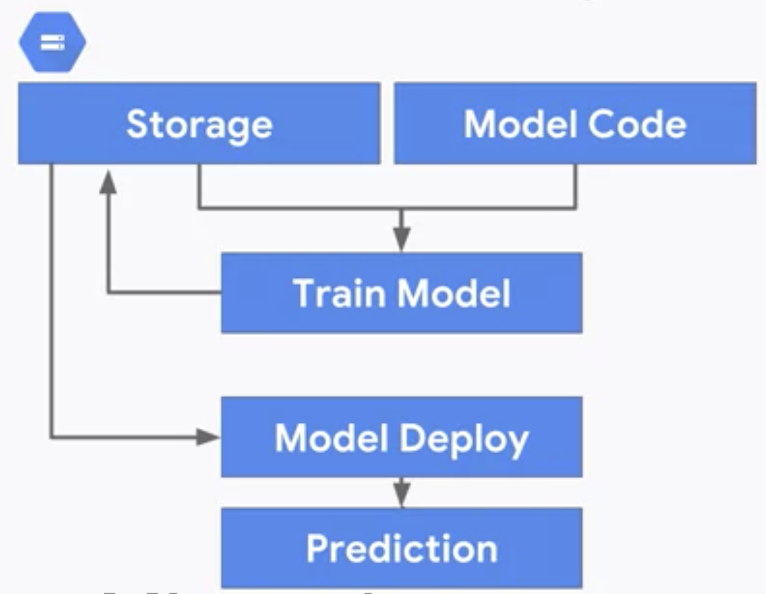
一方で動的トレーニングのアーキテクチャは、GCP上では3つ候補があるとされています。
- Cloud Functions: 非同期トレーニング
- App Engine: ユーザーがジョブのトリガーを引くトレーニング
- Cloud Dataflow: 継続的トレーニング
Serving Design Decisions
学習のデザインに続いて、推論のデザインについてです。
静的な推論は、分類問題であれば予めラベルを推論しインプットをkeyとしてテーブル化しておき、新たなインプットが来たらkeyが合致するレコードを探して値を返す、というものになります。動的な推論は、新たなインプットに対して都度推論を行います。
静的推論と動的推論のどちらを選ぶかは、一言で言えばspace-time trade-offになります。
| 静的推論 | 動的推論 |
|---|---|
| ストレージコストが高い | ストレージコストが安い |
| レイテンシが低く、固定 | レイテンシが変動 |
| メンテナンスは低工数 | メンテナンスは高工数 |
| 空間計算量が大きい | 時間計算量が大きい |
ただ、このトレードオフを持ってどちらの推論にすべきか判断しきれない場合もあります。
そこで、別の観点から2つの推論スタイルを比較します。
その観点は、インプットデータに関するPeakednessとCardinalityです。
Peakednessは、インプットデータの分布がどれだけ集中しているかを意味します。Cardinalityはユニークなインプットデータのセットの数を意味します。
Cardinalityが低い、つまり限られたインプットデータのパターンしか想定されない場合は、静的推論で十分となります。
Cardinalityが高い、つまりインプットデータのパターンが多岐に渡り、かつPeakednessが高くない、つまり特定のインプットの割合が高いわけではない場合は、動的推論が必要となります。
実用的には、CardinalityもPeakednessも高い場合がほとんどです。その場合、頻度が高い特定のインプットについての推論は静的にキャッシュしておき、残りのロングテールの推論を動的に行う、というハイブリッドの推論方法が有力になります。
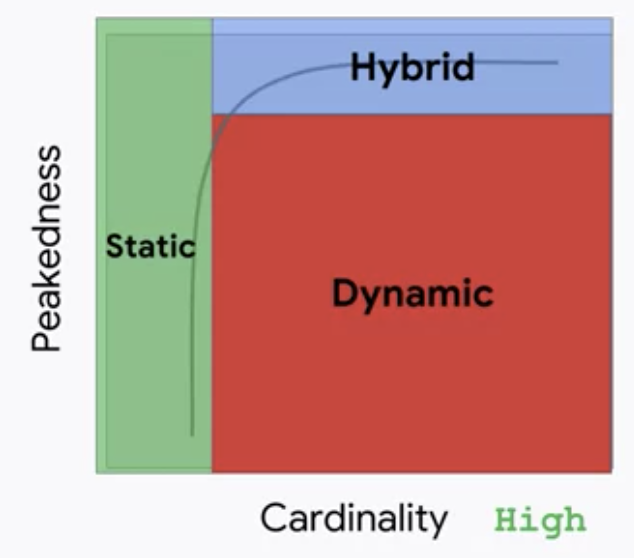
既出のユースケースについて、どちらの推論スタイルが適切か見てみましょう。
| ユースケース | 推論スタイル |
|---|---|
| スパムメールの検知 | 動的(Cardinalityは高く、Peakesnessは高くない) |
| スマーフォトンのVoice2Text機能 | 動的orハイブリッド(Cardinalityは高いが、挨拶など定型的な文句もあるのでPeakednessは比較的高い) |
| 広告のConversion Rate | 静的(Cardinalityは低い) |
終わりに
まさに全体像の把握に主眼が置かれていて、実際に使いこなすには足りず、受講後は実データで一度構築してみる必要があるな、と思わされる内容でした。
もちろん内容が悪いわけではなく、私のように局所的な学習を重ねてきた人間にとっては、各パーツをglueする感じでとても勉強になるものでした。
コース中のissueについて
コース中には、QwiklabsというGCPのコンソールや各サービスを触りながら構築を体験するカリキュラムがあるのですが、カリキュラムが古いようでいくつかエラーに遭遇しました。対処方法をメモしておきます。
尚、スタッフにエラーを報告したところ、対応は非常に迅速で的確だったことも付記しておきます。
Predict Babyweight with TensorFlow using AI Platform
train_deploy.ipynbの中で、ai-platformのtraining jobを実行するセルで、runtime-versionが1.4になっていますがdeprecatedのようです。1.14に変更する必要があります。
%%bash
OUTDIR=gs://${BUCKET}/babyweight/trained_model
JOBNAME=babyweight_$(date -u +%y%m%d_%H%M%S)
echo $OUTDIR $REGION $JOBNAME
gsutil -m rm -rf $OUTDIR
gcloud ai-platform jobs submit training $JOBNAME \
--region=$REGION \
--module-name=trainer.task \
--package-path=$(pwd)/babyweight/trainer \
--job-dir=$OUTDIR \
--staging-bucket=gs://$BUCKET \
--scale-tier=BASIC \
--runtime-version 1.14 \
-- \
--bucket=${BUCKET} \
--output_dir=${OUTDIR} \
--pattern="00001-of-" \
--train_steps=2000
Serving ML Predictions in batch and real-time
学習済みモデルをコピーしデプロイするところで、指定されているtensorflowのversionが合っていないようです。TFVERSIONを2.1に変更する必要があります。
REGION=us-central1
BUCKET=$(gcloud config get-value project)
TFVERSION=2.1
gsutil mb -l ${REGION} gs://${BUCKET}