はじめに
すごーい!きみはでばっぐじょーほーがよめるフレンズなんだね!
(雑な挨拶)
実行時に解釈するスクリプト言語ではなく、ソースコードをコンパイルしてマシン語バイナリを作るコンパイル言語では、プログラムを実行する時に出たバグを解析するのに、ソースコードとの突き合わせ作業が必要になります。とはいえIDEやエディタの拡張機能を使っていれば、ユーザはほとんど何も気にすることなく、プログラムのソースコード上のある行番号で実行を止めたり、その時の変数の値を調べたりすることが出来るでしょう。
この記事では、そうした技術の裏側にあるデバッグ情報について説明をし、デコードしたデバッグ情報からある程度の情報を得られることを目指します。前半部分ではデコードしたデバッグ情報を読むためのDWARFの基礎知識について説明し、後半部分ではサンプルコードをコンパイルし、そこからデバッグ情報を実際に表示させて辿ってみます。
デバッグ情報の基礎知識
デバッグ情報とは、コンパイル言語においてソースコードから生成された実行可能なマシン語バイナリに対して、元々のソースコードとの対応付や、プログラム実行中のスタック解析を助けるための情報です。ここで扱うのはLinuxなどで利用されているELF形式の実行バイナリに対するDWARF形式のデバッグ情報になります1。
DWARF形式とは何か
上記のようなデバッグ情報をどのようにバイナリに格納するか、どういうエンコーディングを行うかといったことの取り決めは、DWARF( Debug With Arbitrary Record Format )形式として定義されています。DWARF形式の定義はThe DWARF Debugging Standardからダウンロードすることが可能です(GNU Free Documentation Licenseの下で公開されています)。2017年2月現在、DWARF形式はversion 4まで公開され、version 5が公開レビュー中です。コンパイラやツールによってサポートされる形式のバージョンが異なりますので注意が必要ですが、基本的には上位互換性は保たれていますので、全く動かないということはないです。
また、RFCと異なり、ほとんどの場合の定義がmustではなくcanであるため、割と寛容な記述になっているのも特徴的です。このため、特にDIEの属性(後述)はコンパイラの種類やそのバージョンによって異なることがあります。
ここでは、このDWARF Debugging Information Standard V4(以下DWARF DIS4と記述)の内容を参照しながら解説していきます。ちなみに、本格的なバイナリフォーマットの解説はここでは省きます。既にelfutilsのlibdwやlibunwindなど、DWARF情報を読み取って解釈してくれるライブラリはいくつかあるので、そちらを使えば直接バイナリを解釈する必要はないからです2。
バイナリファイルに格納されたデバッグ情報
デバッグ情報とは簡単に言えば、実行バイナリの情報とソースコード情報を対応させるためのデータテーブルになります。ここで取り上げるDWARFでは、複数のテーブルやツリーを駆使して、ソースコード上の情報と実行バイナリの情報を対応させています。
以下に代表的なデバッグ情報とそのセクション名を示します。
-
デバッグ情報(.debug_info)
実行バイナリのデータ構造(構造体や型情報)とコード構造(関数やサブルーチンなど)、ローカル変数や引数の情報などをツリー構造にして格納しています。これがメインの情報になります。 -
行情報(.debug_line)
ソースコードのファイルと行番号の情報と、実行バイナリのアドレス情報の対応をテーブルにして格納しています。 -
アドレス情報(.debug_aranges)
実行ファイル内における、コンパイルしたソースファイル毎のアドレスの領域をテーブルにして格納しています。 -
フレーム情報(.debug_frame)
個々の関数内におけるスタックフレームの情報をテーブルにして格納しています。 -
ロケーション情報(.debug_loc)
関数内におけるスタック上の位置やレジスタ割当が変わりうるローカル変数などの情報をテーブルにして格納しています。 -
名前情報(.debug_pubnames)
実行バイナリ内のシンボル名をテーブルにして格納しています。ご想像の通り、これはELFのシンボル情報と同じであるため、ほとんどの場合省略されます。
個々の情報は、それぞれ別のELFセクションとして実行バイナリ内に格納されます。これらの情報は、(eu-)readelfコマンドを使うことで表示することが出来ます。ここでは、elfutilsパッケージに含まれるeu-readelfを使うことにします。binutilsのreadelfコマンドでもダンプすることが出来ますが、elfutilsのeu-readelfの方が詳細な(解釈された)情報を得ることが出来ます。
$ eu-readelf -w a.out | less
ソースコードと実行バイナリの対応を調べる場合、基本的にはこのデバッグ情報(.debug_info)を中心にして解釈を行います。他の情報には、このデバッグ情報への参照あるいはデバッグ情報からの参照があります。ただしフレーム情報だけは独立して処理することが可能になっています。
この参照関係については、DWARF DIS4 Appendix Bの Page 214 Figure.43に詳細な関係図が記されています。
デバッグ情報の概要
デバッグ情報の中核となるdebug_infoの登場人物と構造について説明をしていきます。
デバッグ情報はツリー構造をしており、ツリーのノードに当たるオブジェクトをDIE(デバッグ情報エントリ:Debug Information Entry)と呼んでいます。このDIEは自身のオフセット値と複数の属性を持ったオブジェクトで、属性の中には他のDIEへの参照オフセット値を含むことも可能です。実際、単純な数値データ以外(例えば文字列やロケーション情報など)は、他のDIEを参照するようになっています。
DIEの種類
DIEには非常に多くの種類がありますが、代表的なものは以下になります。
-
CU DIE
CUはCompile Unitの略です。これはコンパイラが一度に生成するオブジェクトファイルに対応しますが、C言語では一つのソースファイルに対応しています。つまり、1CU=1ソースファイルに対応しています。 -
Type DIE
名前の通り型情報に対応します。ローカル変数や戻り値などで使われる型情報を格納するDIEです。構造体や型定義(typedef)、基本型(basic_type)、列挙型、構造体のメンバなどを表し、これらの型が定義されている箇所や、型のサイズ、符号ありなしなどの情報を示します。 -
Subprogram DIE
関数を表すDIEです。内部に引数やローカル変数、レキシカルスコープや他のインライン関数のDIEを保持しており、ツリー構造をなしています。 -
Lexical Block DIE
レキシカルスコープ(関数内の特定のブロックに一時的なスコープを持つ変数などがある場合に現れる)を表すDIEです。 -
Inlined Subroutine DIE
関数内に展開されたインライン関数を表すDIEです。 -
Formal parameter DIE/variable DIE
それぞれ関数の仮引数と、(ローカル及びグローバル)変数に対応するDIEです。
DIEの種類は"DW_TAG_"で始まる定数によって管理されており、どのような種類が存在するかは、DWARF DIS4の Page 8 Figure.1に記されています。
DIEの属性
DIEは複数の属性値(Attribute)を持っています。また、DIEの種類によって、どのような属性を持つことが出来るかということはDWARF形式の中で決められています(DWARF DIS4 Appendix Aの Page 211 Figure.42に一覧が記載されています)。代表的な属性として以下のようなものがあります。
-
name
name属性はそのDIEの名前を表します。例えば関数名や変数名などを指します。 -
entry_pc/low_pc
entry_pcやlow_pc属性は、そのDIEのスコープのエントリアドレスを示します。ただし、インライン関数など、コードが細切れの範囲に散らばっている場合は、ranges属性が使われます。 -
type
type属性はそのDIEの型情報を示すDIEへの参照になっています。 -
inline
inline属性は、そのDIE(通常Subprogram DIE)がインライン関数であるかどうかを示します。(DWARF DIS4 Page 59 Figure.11に記されています。) -
location
location属性は、そのDIE(通常Variable DIEかFormal Parameter DIE)のロケーション(レジスタやスタックの割当情報)への参照になっています。 -
sibling
sibling属性は、DIEの木構造を表すのに用いられ、木構造の隣の枝のDIEを参照しています。
属性の種類は"DW_AT_"で始まる定数によって管理されており、どのような属性が存在するかは、DWARF DIS4の Page 14 Figure.2に記されています。
属性のクラス
それぞれの属性は、属性値のエンコーディングに応じていくつかの属性クラスに分類されています。ここでは代表的な属性クラスについて説明します。
-
address
addressクラスはプログラム内のアドレス空間上のアドレス値を属性値として持つクラスです。 -
reference
referenceクラスは他のDIEを参照する属性値を持つクラスです。恐らくデバッグ情報を読む中で最もよく目にすると思います。 -
string
stringクラスは文字列を属性値として持ちます。ツールを使うことで自動的に解決されて表示されますが、本当のデータは.debug_stringセクションにあります。 -
constant
constantクラスは様々な即値を属性値として持つクラスです。 -
flag
flagクラスは1バイト以下ビットフラグデータを属性値として持つクラスです。
これらの属性クラスについては、DWARF DIS4のPage 15 Figure.3および属性クラスのデータの格納フォーマットについては、Page 146 7.5.4 Attribute Encodingsに記されています。
DIEの木構造
debug_infoセクション内部のDIEは、セクション先頭から順々に詰められています。個々のDIEはセクション先頭からのバイトオフセット値を持っています。オフセット0は、必ずCU DIEになっています。CU DIEの次からは、そのCU内部で使われる型情報ノードがツリー構造で格納されています。型の定義に続いてグローバル変数とインライン関数の定義、そして実際の関数の定義が続きます。これらの定義はCU DIEの子ノードとして扱われます。
あるDIE Aの属性にsiblingが存在し、DIE Cを指している場合、DIE Aの次に格納されているDIE BはDIE Aの子ノードになり、DIE CがDIE Aと親ノードを共有する隣の枝のノードになります。CU DIEの直下にDIE Aが存在する場合の.debug_info内の物理的な構造、および、それをもとにした論理的なツリー構造を以下に図示します。
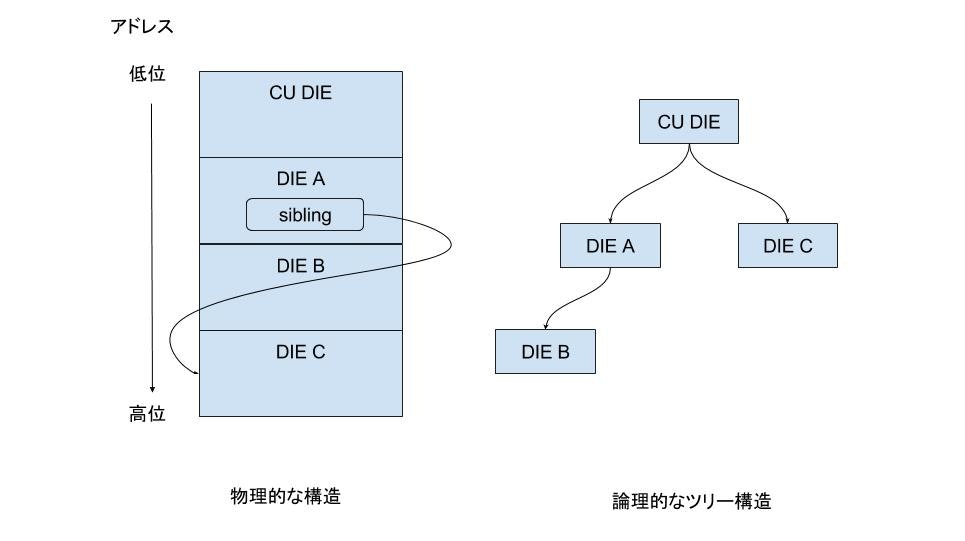
CU DIEはsiblingを持ちませんが、次のCU DIEが出てくるまでの全てのDIEのルートノードになります。このため、debug_infoセクション内には、CU DIEの数だけの木構造が存在することになります。
DWARF表現
DWARF表現(DWARF Expression)あるいはDWARF演算(DWARF Operation)というのは、DWARF内部で主にLocationを表現するために用いられるスタックマシンに対する演算命令(オペコード)になります。詳しくはDWARF DIS4の2.5節(Page 17)と2.6節(Page 25)を参照してください。詳しい内容の解説は又の機会に譲りますが、変数のレジスタ割当などの表記はDWARF表現で表されているので、ローカル変数の場所を知るためには、ある程度覚えておく必要があります。
-
reg0,reg1,...,reg31
汎用レジスタを示します。対象となる汎用レジスタは、オペコードのサフィックスで示されます。実際のアーキテクチャで定義されているレジスタとの対応については、個々のアーキテクチャに移植する際に決められます。x86の例をこの節の最後に示しておきました。 -
regx
汎用レジスタを示します。このオペコードは一つの引数を取り、この引数の値がレジスタの番号を示します。(regx 0はreg0と同じという意味です) -
fbreg
フレームレジスタ(スタックフレーム)の値からの相対オフセットでメモリ上に保存されている場所を示します。スタックに積まれた変数は通常このオペコードを使います。このオペコードはオフセットを表す引数を一つ取ります。 -
breg0,breg1,...,breg31
汎用レジスタからの値からの相対オフセットでメモリ上に保存されている場所を示します。このオペコードはオフセットを表す引数を一つ取ります。 -
bregx
汎用レジスタからの値からの相対オフセットでメモリ上に保存されている場所を示します。このオペコードはレジスタ番号とオフセットを表す引数を2つ取ります。 -
addr,const*
アドレス値や定数値を示すオペコードです。仮引数が定数の場合などに使われます。
x86における汎用レジスタのオペコードへの割当は以下のようになっています。詳細はDWARF Definitionなどを参照してください。
| reg0 | reg1 | reg2 | reg3 | reg4 | reg5 | reg6 | reg7 | reg8 | ... | reg15 |
|---|---|---|---|---|---|---|---|---|---|---|
| rax | rdx | rcx | rbx | rsi | rdi | rbp | rsp | r8 | ... | r15 |
サンプルコードを使った解析
ではサンプルコードを使って実際にどうDWARFが記述されるのかを見ていきましょう。
サンプルコードのビルド
以下のC言語で書かれた単純なプログラムを例にして、デバッグ情報の確認をしていきましょう。
# include <stdio.h>
static int func1(int p1)
{
printf("hello world %x\n", p1);
return 0;
}
static int func2(int p2)
{
return func1(p2 + 0xcafe);
}
int main(void)
{
register int p = 0xbeef;
return func2(p);
}
まずは最適化をしない(-O0)でコンパイルしてみましょう。また出来上がったバイナリから逆アセンブル及びデバッグ情報のダンプも行っておきます。
$ gcc -O0 -g -o sample sample.c
$ objdump -d sample > sample.S
$ eu-readelf -winfo sample > sample.debug
$ eu-readelf -wline sample > sample.line
Compile Unitのデバッグ情報を読む
sample.debugを読むと頭の方は以下のようになっていると思います。
オフセット 0x10ac の DWARF セクション [28] '.debug_info':
[オフセット]
オフセット 0 のコンパイル単位:
バージョン: 4、略語セクションオフセット: 0、アドレスの大きさ: 8、オフセットの大きさ: 4
[ b] compile_unit
producer (strp) "GNU C11 6.3.1 20161221 (Red Hat 6.3.1-1) -mtune=generic -march=x86-64 -g -O0"
language (data1) C99 (12)
name (strp) "sample.c"
comp_dir (strp) "/tmp/samples"
low_pc (addr) 0x00000000004004f6 <func1>
high_pc (data8) 94 (0x0000000000400554)
stmt_list (sec_offset) 0
[ 2d] typedef
name (strp) "size_t"
decl_file (data1) 2
decl_line (data1) 216
type (ref4) [ 38]
[ 38] base_type
最初の[ b] compile_unitがCU DIEを示しています。このことから、CU DIEのオフセットは0xbであることがわかります。なぜオフセットが0ではないかというと、CU DIEの前にコンパイルユニットのヘッダがあるからです。ヘッダにはこのコンパイルユニットのオフセットや略語セクション(.debug_abbrev)にあるテーブルの対応するエントリのオフセットや、アドレスサイズなどが記載されています。
CU DIEの行より下にあるのが、CU DIEの属性と属性値になります。producerはコンパイラの情報で、languageは使った言語、nameにはソースコードファイルの名前、comp_dirにはコンパイルしたディレクトリ、low_pcとhigh_pcはこのCUが対応するバイナリ内のアドレス範囲が示されています。
また、属性値の前の(strp)や(addr)は、前述の属性クラスと属性値のエンコーディングを表しています。例えば(strp)はstring属性クラス、(addr)はaddress属性クラス、(data1)と(data8)はそれぞれ1バイトと8バイトのconstant属性クラスを示しています。言語については言語名ではなくてそれぞれの言語に番号が割り振られており、DWARF DIS4の7.12 Figure 31に詳細な定義が書かれています。
変数や構造体の定義をたどる
さて、compile_unitの次のDIEは[ 2d] typedefとなっています。注目してほしいのは、インデントが少し深くなっているところです。これはCU DIEを親として次のDIEが子のノードになっているということを示しています。また、typedefのDIEのname属性はsize_tになっています。sample.cでは明示的にsize_tを定義していませんが、stdio.hの中で定義されている何かの変数の定義に依存しています。この依存関係を調べたければ、オフセット値の2d]をキーにして検索すると良いです。
[ 1f6] member
name (strp) "__pad5"
decl_file (data1) 4
decl_line (data2) 302
type (ref4) [ 2d]
data_member_location (data1) b8
memberというDIEが引っかかりました。これは構造体のメンバ(フィールド)を表すDIEなので、この親ノードが大元の構造体になります。sample.debugの上の方にたどっていくと、次のような記述が見つかりました。
[ a1] structure_type
name (strp) "_IO_FILE"
byte_size (data1) 216
decl_file (data1) 4
decl_line (data1) 241
sibling (ref4) [ 21e]
これはstructure_typeのDIEなので構造体の定義を表します。構造体の名前は_IO_FILEで、byte_sizeが構造体のサイズを表しています。デバッガはこれを読み取って構造体のデコードをしています。また、decl_fileとdecl_lineはそれぞれ、構造体を定義しているファイルを示す番号と、その中の行番号を示しています。ファイル番号は実は.debug_infoではなく.debug_lineセクションに含まれています。
ディレクトリーテーブル:
/usr/lib/gcc/x86_64-redhat-linux/6.3.1/include
/usr/include/bits
/usr/include
ファイル名テーブル:
Entry Dir 時刻 大きさ 名前
1 0 0 0 sample.c
2 1 0 0 stddef.h
3 2 0 0 types.h
4 3 0 0 libio.h
5 3 0 0 stdio.h
6 2 0 0 sys_errlist.h
sample.lineの中のファイル名テーブルのEntry列で、decl_fileの番号に対応する行が対象のファイルです。今回は"4"なのでlibio.hで定義されていることがわかります。また、Dir列の番号がディレクトリテーブルと対応しています。ここでは"3"なので定義ファイルは/usr/include/libio.hであることがわかります。
さて、構造体の属性の最後はsibling (ref4) [ 21e]となっています。これはsibling属性つまり木構造の隣の枝を指しています。実際、21e]で検索すると、 [ 21e]のDIEの直前で一つインデントが戻っているのがわかります。
[ 210] member
name (strp) "_unused2"
decl_file (data1) 4
decl_line (data2) 305
type (ref4) [ 278]
data_member_location (data1) c4
[ 21e] typedef
name (strp) "_IO_lock_t"
decl_file (data1) 4
decl_line (data1) 150
ポインタの定義をたどる
この_IO_FILEは何処から参照されているのでしょうか。同じように a1]を辿ってみましょう。
[ 25c] pointer_type
byte_size (data1) 8
type (ref4) [ a1]
インデントの様子から、これはCU DIEの直下のDIEだということがわかります。pointer_typeなのでポインタ型の定義であり、byte_sizeもアドレスサイズと同じ8バイトとなっているのがわかります。面白いことにname属性がありません。
DWARF形式ではポインタを表す*も一つの型として定義されます。ちなみにconstも一つの型になり、const_typeというDIEで表されます。
次にstruct _IO_FILE *の参照元を探してみましょう。
[ 2bc] variable
name (strp) "stdin"
decl_file (data1) 5
decl_line (data1) 170
type (ref4) [ 25c]
external (flag_present) はい
declaration (flag_present) はい
無事variableのDIEにたどり着きました。stdinがポインタ型の定義を参照していたことがわかります。external属性は他のオブジェクトファイルから参照可能なこと3を示し、declaration属性は、この変数の型が不完全に定義されている(メンバの定義などに不完全な所がある)ことを示しています。
main関数の定義を読む
では関数のコードがどのようにデバッグ情報として格納されているのかを見ていきましょう。subprogram DIEを探すと以下のDIEにたどり着きます。
[ 303] subprogram
external (flag_present) はい
name (strp) "main"
decl_file (data1) 1
decl_line (data1) 14
prototyped (flag_present) はい
type (ref4) [ 62]
low_pc (addr) 0x0000000000400538 <main>
high_pc (data8) 28 (0x0000000000400554)
frame_base (exprloc)
[ 0] call_frame_cfa
GNU_all_tail_call_sites (flag_present) はい
sibling (ref4) [ 330]
[ 324] variable
name (string) "p"
decl_file (data1) 1
decl_line (data1) 16
type (ref4) [ 62]
location (exprloc)
[ 0] reg3
name属性で分かるように、これはmain関数を示しています。low_pcとhigh_pcの属性値がmain関数のアドレス範囲を示しています。ちなみにtype属性は関数の型ではなく、戻り値の型なので注意が必要です。frame_base属性はスタックフレームの解析に用いられます。ここでは[ 0] call_frame_cfaとなっているので、厳密には.debug_frameの情報を用いることになりますが、ちょっと難しいので脇においておきましょう。
このsubprogram DIEはローカル変数を一つ持っています。[ 324] variableがローカル変数(実際には親DIEのスコープ内で定義されている変数、例えばCU DIE直下のvariable DIEはグローバル変数を表す)を示します。元のプログラムではregister変数として定義したため、rbxレジスタにレジスタ割当されていることがlocation属性がreg3であることからわかります。これを実際に逆アセンブルの結果と突き合わせてみましょう。
0000000000400538 <main>:
400538: 55 push %rbp
400539: 48 89 e5 mov %rsp,%rbp
40053c: 53 push %rbx
40053d: 48 83 ec 08 sub $0x8,%rsp
400541: bb ef be 00 00 mov $0xbeef,%ebx
400546: 89 df mov %ebx,%edi
400548: e8 cf ff ff ff callq 40051c <func2>
40054d: 48 83 c4 08 add $0x8,%rsp
400551: 5b pop %rbx
400552: 5d pop %rbp
400553: c3 retq
400554: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
40055b: 00 00 00
40055e: 66 90 xchg %ax,%ax
まずmain関数の先頭が0x400538になっていて、これはlow_pc属性と同じ値になっています。またhigh_pcと同じ0x400554を見ると、その直前にretqがあり関数が終わっていることがわかります。つまりlow_pcからhigh_pcを含まない範囲がこの関数のアドレス範囲ということがわかります。
また、0xbeefが扱われている命令を見ると、mov $0xbeef,%ebxとなっていて、ちゃんとrbxレジスタ(ここではint:32bitで定義したのでrbxの下位32ビットであるebxレジスタ)に割り当てられていることがわかります。
func2関数の定義から関数のprologueを考える
[ 330] subprogram
name (strp) "func2"
decl_file (data1) 1
decl_line (data1) 9
prototyped (flag_present) はい
type (ref4) [ 62]
low_pc (addr) 0x000000000040051c <func2>
high_pc (data8) 28 (0x0000000000400538 <main>)
frame_base (exprloc)
[ 0] call_frame_cfa
GNU_all_tail_call_sites (flag_present) はい
sibling (ref4) [ 35f]
[ 351] formal_parameter
name (string) "p2"
decl_file (data1) 1
decl_line (data1) 9
type (ref4) [ 62]
location (exprloc)
[ 0] fbreg -20
では続いてfunc2について見てみましょう。main関数とほぼ同じですが、子DIEがvariableではなくformal_parameterになっています。これらはローカル変数ではなく、関数の仮引数だからです。
さて、この仮引数のlocation属性を見ると、[ 0] fbreg -20となっています。fbregはその関数のスタックフレームを意味しますが、x86では基本的にcall命令を呼び出す直前のspレジスタの値がスタックフレームの先頭を指しているようです。このため、実際の関数の先頭ではスタックフレーム-8のところにspがいることに注意しなければいけません。
そうすると、fbreg-20とはsp-12ですから、スタックポインタより先に仮引数が存在することになってしまいます。これは関数のコードが、本体以外にprologue、eplogueの3つの部分から成り立つためです。関数のprologueでは関数のスタックフレームを準備しますから、このfbreg-20が有効になるのはprologueの部分が終わった後になります。
ではそのprologueの終わりなのですが、再び.debug_lineを参照することになります。
行 番号 文:
[ b5] 拡張命令コード 2: set address to 0x4004f6 <func1>
[ c0] 特殊命令コード 21: アドレス+0 = 0x4004f6 <func1>, 行+3 = 4
[ c1] 特殊命令コード 173: アドレス+11 = 0x400501 <func1+0xb>, 行+1 = 5
[ c2] advance address by constant 17 to 0x400512 <func1+0x1c>
[ c3] 特殊命令コード 61: アドレス+3 = 0x400515 <func1+0x1f>, 行+1 = 6
[ c4] 特殊命令コード 89: アドレス+5 = 0x40051a <func1+0x24>, 行+1 = 7
[ c5] 特殊命令コード 49: アドレス+2 = 0x40051c <func2>, 行+3 = 10
[ c6] 特殊命令コード 173: アドレス+11 = 0x400527 <func2+0xb>, 行+1 = 11
[ c7] 特殊命令コード 229: アドレス+15 = 0x400536 <func2+0x1a>, 行+1 = 12
[ c8] 特殊命令コード 49: アドレス+2 = 0x400538 <main>, 行+3 = 15
[ c9] 特殊命令コード 145: アドレス+9 = 0x400541 <main+0x9>, 行+1 = 16
[ ca] 特殊命令コード 89: アドレス+5 = 0x400546 <main+0xe>, 行+1 = 17
[ cb] 特殊命令コード 117: アドレス+7 = 0x40054d <main+0x15>, 行+1 = 18
[ cc] advance address by 7 to 0x400554
[ ce] 拡張命令コード 1: end of sequence
特殊命令コードは前の行情報から、行番号とアドレスの両方がどの程度差分があるかをエンコードしたものです。これらのコードは解釈されて:の右の方に表示されています。ここで、解析したい関数の先頭の次の行が、基本的には関数の本体とみなせます。func2で言うと、0x40051c <func2>, 行+3 = 10が先頭行を表し、次の行が0x400527 <func2+0xb>, 行+1 = 11ですから、0x400527まで行けばfbreg-20と解釈しても良いことになります。
実際にこの辺りに対応するアセンブリ命令を見てみましょう。
000000000040051c <func2>:
40051c: 55 push %rbp
40051d: 48 89 e5 mov %rsp,%rbp
400520: 48 83 ec 10 sub $0x10,%rsp
400524: 89 7d fc mov %edi,-0x4(%rbp)
400527: 8b 45 fc mov -0x4(%rbp),%eax
40052a: 05 fe ca 00 00 add $0xcafe,%eax
40052f: 89 c7 mov %eax,%edi
400531: e8 c0 ff ff ff callq 4004f6 <func1>
400536: c9 leaveq
400537: c3 retq
アドレス0x400527の命令はmov -0x4(%rbp),%eaxですが、一つ前の命令でmov %edi,-0x4(%rbp)と、ediレジスタの値をrbpレジスタ相対のメモリに記録しています。
少し前に「x86では基本的にcall命令を呼び出す直前のspレジスタの値がスタックフレームの先頭を指している」といったことを思い出してください。callq命令でfunc2が呼び出されると、そもそもspレジスタの値はスタックフレームfbreg-8になっています。さらに一命令目で、push %rbpしているのでspレジスタはfbreg-16になります。次にrspをrbpにコピーしているので、rbpレジスタの値はfbreg-16となっています。つまり-0x4(%rbp)は、fbreg-16-4 = fbreg-20を表していることがわかります。
これで、アドレス0x400527の命令ではfbreg-20=の値をeaxレジスタに代入しているということがわかります。つまりこの命令は、変数p2の値をレジスタにロードしているということになります。p2の値がレジスタに入っていてメモリ上では更新されていないのは、元々のプログラムの中でもreturn func1(p2 + 0xcafe);と書かれているためです。
実際にはprologue部分(0x40051cから0x400526まで)では以下のような処理を行っています。
- スタックポインタにrbpレジスタ(呼び出し元の関数のスタックフレームの値が入っている)の値を保存する(
push %rbp) - スタックポインタの値をrbpレジスタに保存する(
mov %rsp,%rbp) - スタックを伸長する(
sub $0x10,%rspでrspの値を-16して、16バイトのローカル作業用領域を作っています) - 仮引数をスタック上に作る(
%edi,-0x4(%rbp))
このprologueの処理は、アセンブリ命令を見ればわかりますが、ほとんど無意味です。例えばスタックは伸長しすぎていて始めの4バイトしか使われていない上、そもそも仮引数をスタック上に作る必要がありません。
最適化を行うと、prologueの処理などはほとんどスキップされてしまうので、また違った結果を得ることになります。
最適化したバイナリを見てみよう
最適化したバイナリがどうなるかを見てみるために、-O1オプションでコンパイルしてみましょう。このくらい単純なコードだと-O1ぐらいでも十分すぎるほど単純化されます。
$ gcc -O1 -g -o sample sample.c
$ objdump -d sample > sampleO1.S
$ eu-readelf -winfo sample > sampleO1.debug
$ eu-readelf -wloc sample > sampleO1.loc
まず逆アセンブル結果を見てみましょう。main関数から直接printfを呼び出していて、func1とfunc2は影も形もないですね。すごーい!
00000000004004f6 <main>:
4004f6: 48 83 ec 08 sub $0x8,%rsp
4004fa: be ed 89 01 00 mov $0x189ed,%esi
4004ff: bf b0 05 40 00 mov $0x4005b0,%edi
400504: b8 00 00 00 00 mov $0x0,%eax
400509: e8 e2 fe ff ff callq 4003f0 <printf@plt>
40050e: b8 00 00 00 00 mov $0x0,%eax
400513: 48 83 c4 08 add $0x8,%rsp
400517: c3 retq
400518: 0f 1f 84 00 00 00 00 nopl 0x0(%rax,%rax,1)
40051f: 00
では対応するデバッグ情報を見てみましょう。以前と比較して目につくのはmain関数のツリーが深くなっていることです。これはfunc1とfunc2の処理を取り込んだためですね。アドレス範囲も少し大きくなっています。
[ 303] subprogram
external (flag_present) はい
name (strp) "main"
decl_file (data1) 1
decl_line (data1) 14
prototyped (flag_present) はい
type (ref4) [ 62]
low_pc (addr) 0x00000000004004f6 <main>
high_pc (data8) 34 (0x0000000000400518)
frame_base (exprloc)
[ 0] call_frame_cfa
GNU_all_call_sites (flag_present) はい
sibling (ref4) [ 396]
[ 324] variable
name (string) "p"
decl_file (data1) 1
decl_line (data1) 16
type (ref4) [ 62]
const_value (data2) 48879
[ 32f] inlined_subroutine
abstract_origin (ref4) [ 396]
low_pc (addr) 0x00000000004004fa <main+0x4>
high_pc (data8) 20 (0x000000000040050e <main+0x18>)
call_file (data1) 1
call_line (data1) 17
[ 346] formal_parameter
abstract_origin (ref4) [ 3a6]
location (sec_offset) location list [ 0]
[ 34f] inlined_subroutine
abstract_origin (ref4) [ 3b1]
low_pc (addr) 0x00000000004004fa <main+0x4>
high_pc (data8) 20 (0x000000000040050e <main+0x18>
)
call_file (data1) 1
call_line (data1) 11
[ 366] formal_parameter
abstract_origin (ref4) [ 3c1]
location (sec_offset) location list [ 26]
variable DIEで示された変数pも、location属性の代わりにconst_valueが定義され、レジスタにアサインされずに即値が代入されたことがわかります。次に [ 32f] inlined_subroutine DIEが現れますが、これはインライン展開された関数を示します。abstract_origin属性が、オフセット[ 396]を示しています。これは下記のようにfunc2の定義を参照していることがわかります。prototyped属性があり、inline属性がinlinedになっているので、この関数は定義としては存在しているが、実体はインライン化されていることがわかります。
[ 396] subprogram
name (strp) "func2"
decl_file (data1) 1
decl_line (data1) 9
prototyped (flag_present) はい
type (ref4) [ 62]
inline (data1) inlined (1)
sibling (ref4) [ 3b1]
また、func2がインライン展開されたmain関数の中でもlow_pcとhigh_pcがあることから、何処から何処までの命令に変換されたのかがわかります。func1も同様にインライン展開されています。
ところで、func2とfunc1の仮引数(formal_parameter)には、両方共location属性が設定されています。アセンブリ命令レベルでは存在していないはずなのに、おかしいですよね?この謎は、属性値に示された.debug_locのエントリを読めばわかります。
func2のp2仮引数は(sec_offset) location list [ 0]となっているので、debug_locセクションのオフセット0を、func1のp1仮引数は同様にオフセット26のエントリに対応しています。
オフセット 0x195f の DWARF セクション [32] '.debug_loc':
[ 0] 0x00000000004004fa <main+0x4>..0x000000000040050e <main+0x18> [ 0] const2u 48879
[ 3] stack_value
[ 26] 0x00000000004004fa <main+0x4>..0x000000000040050e <main+0x18> [ 0] const4u 100845
[ 5] stack_value
.debug_locセクションを読むと、それぞれconst2u 48879とconst4u 100845つまり0xbeefと0xbeef+0xcafeの値が示されていることがわかります。
このように、最適化したバイナリであっても可能な限りデバッグ出来るよう、デバッグ情報が追加されていることがお分かりいただけたでしょうか。4
さいごに
ここまで読んだみんなは、もうりっぱなでばっぐじょーほーがよめるフレンズだね!
たっのしーい!と思ったみんなが多ければ続きも書くかもよ!じゃあね!
-
WindowsではPDB(Program Database)形式のデバッグ情報が利用されているようです。 ↩
-
実際にはlibdwのドキュメントが少ないので、libdwを使うにはlibdwのヘッダファイルや、時にはソースコードまで読み込まないとどういう動作を期待して良いのかがわからないことが多いです。早くonline manualを・・・。 ↩
-
C言語で言えばextern宣言されているということです。 ↩
-
ここまで読んでわかったかと思いますが、これだけの情報を詰め込んだデバッグ情報は、相当サイズが大きくなります。Linuxカーネルなどの大規模なものだと、大体実行バイナリの8倍程度の大きさになります。また配布用パッケージにするときには、行番号に対応するソースコードも付けないといけないので、実行バイナリの大体10倍程度の大きさを覚悟しておく必要があります。 ↩