はじめに
最近(といっても今年の始め)、LinuxにXArray (extensible array) というAPIが、MicrosoftのMatthew Wilcoxによって実装されました。これは彼の説明によれば、radix treeの代わりに使える、ULONG_MAXの範囲がNULLで埋められた巨大な配列として扱えるデータ構造ということです。
今回はこのXArrayの簡単な使い方を調べ、実際にkprobesのハッシュテーブルと入れ替えてみて、どの程度の性能の違いが出るのかを調べたいと思います。
XArrayのAPI
Kernel DocにXArrayのドキュメントがあるので、リファレンスには不自由しないと思いますが、まだあまりカーネル内部で使われていないのでサンプルコードが欲しくなるかもしれません。
XArrayには大別して2種類のAPIがあります。Normal APIとAdvanced APIと呼ばれていますが、Normal APIはXArrayを疎な配列として捉えた時に使うAPIで、Advanced APIはXArrayの裏側の木構造をある程度意識して利用する場合に使うAPIという位置づけと言えるでしょう。今回は後述するkprobesへの適用(ハッシュテーブルの置換)を目指したのですが、Normal APIのみで十分でした。
Normal API
Noraml APIはそれほど多くのことを覚える必要はありません。
初期化API
初期化系はLinked Listと似ています。
XARRAY_INIT(name, flags)は構造体の初期化などに使うマクロです。例えば
struct {
...
struct xarray xa;
...
} something = { .xa = XARRAY_INIT(xa, 0)};
という感じで使います。flagsには取り敢えず0を入れておけば良いようです。
構造体の一部ではなく、独立したxarrayを初期化したい時は、DEFINE_XARRAY(name)が使えます。これはlist_headと同じように直接xarrayが定義できます。
static DEFINE_XARRAY(my_array);
一方、XArrayをどうしても動的にオブジェクトとして確保して使いたいんだ、という人のためにはxa_init(xarray)とxa_destroy(xarray)がありますが、恐らく使うことはまれでしょう。カーネル内では小規模なリストならlinked listを使う方が良いですし、大規模なリストは複数持つことがあまりないからです。
上記のように定義したXArrayは、既に初期化が終わっているのでそのまま使い始めることが出来ます。
配列値の操作
まず配列に値を入れるのはxa_store(xarray, index, entry, gfp)、値を参照するのはxa_load(xarray, index)です。配列といっても実際には木構造なので、storeする時にメモリを確保する必要があるためGFP_XXXフラグを必要とします。大抵の場合はGFP_KERNELを使えばいいでしょう。特定のエントリを削除したい場合はNULLをstoreするか、xa_erase(xarray, index)を使う必要があります。
/* my_array[0xbeef] = &data */
ret = xa_err(xa_store(&my_array, 0xbeef, &data, GFP_KERNEL));
if (ret)
return ret;
...
/* entry = my_array[0xcafe] */
entry = xa_load(&my_array, 0xcafe);
if (!entry)
return -ENOENT;
...
/* my_array[0xdead] = NULL */
xa_erase(&my_array, 0xdead);
配列の走査
他に利用する機会が多い機能としては、配列内の要素(とインデックス)の走査があります。これにはxa_for_each(xarray, entry, index, max, filter)を使います。引数が多いですが、基本的には後ろの2つはULONG_MAXとXA_PRESENTで固定と考えていいでしょう。それぞれ、unsigned long型の最大値まで走査し、値が存在するエントリだけ抜き出す、という意味になります。
unsigned long index = 0;
void *entry;
xa_for_each(&my_array, entry, index, ULONG_MAX, XA_PRESENT) {
pr_info("my_array[%lu] = %lx\n", index, entry);
}
最初にindex = 0としているのは、0以上のインデックスで最初にヒットするエントリを探すためです。
seqfileの実装
これだけでもほぼ十分なのですが、最後にseqfileとの連携を考えましょう。seqfileについては@akachochinさんの記事が詳しいので、そちらを参照してください。要するに(procfsやdebugfsなどの)疑似ファイルシステム上でread()システムコールを実装するためのフレームワークです。
xa_for_each()は下記のようなマクロで定義されています。
# define xa_for_each(xa, entry, index, max, filter) \
for (entry = xa_find(xa, &index, max, filter); entry; \
entry = xa_find_after(xa, &index, max, filter))
このxa_find(xaray, *index, max, filter)と、xa_find_after(xaray, *index, max, filter)は、それぞれ「指定したindex以上でmax以下の最初の要素を探す」「指定したindexよりも大きくmax以下の最初の要素を探す」という処理になります。
seqfileを実装するにはstart(seq_file, *pos),next(seq_file, val, *pos),stop(seq_file, *pos)、show(seq_file, val)の4つのメソッドを定義する必要があります。この内、start()とnext()に上記のxa_find()とxa_find_after()を使うことになります。基本的には、以下のような感じで実装できるでしょう。
static void *my_start(struct seq_file *m, loff_t *pos)
{
unsigned long idx = *pos;
void *p;
mutex_lock(&my_lock); /* traverseの最中に内容が変わらないようにする */
if (idx == 0)
p = xa_find(&my_array, &idx, ULONG_MAX, XA_PRESENT);
else /* startですがposが0でないこともあります(以前の読み出し処理の続きなど) */
p = xa_find_after(&my_array, &idx, ULONG_MAX, XA_PRESENT);
*pos = *(loff_t *)&idx;
return p;
}
static void *my_next(struct seq_file *m, void *v, loff_t *pos)
{
unsigned long idx = *pos;
void *p;
p = xa_find_after(&my_array, &idx, ULONG_MAX, XA_PRESENT);
*pos = *(loff_t *)&idx;
return p;
}
static void my_stop(struct seq_file *m, loff_t *pos)
{
mutex_unlock(&my_lock);
}
static int my_show(struct seq_file *m, void *v)
{
seq_printf(m, "my data is %lx", (unsigned long)v);
return 0;
}
気持ちが悪いのはloff_t(long long型)とunsigned long型との変換の部分でしょうか。直接posを使えないので、ローカル変数を介して操作してから書き戻すということをしています。
基本的にはこれだけで巨大な疎なポインタの配列、あるいはunsigned longをキーにした連想配列を扱うことが出来ます。
その他のNormal API
あまり使わないかもしれませんが、この他にもエントリが指定した値の場合だけ更新するxa_cmpxchg()や、エントリが存在しない場合だけ値を追加するxa_insert()などがあります。
XArrayの注意点
殆どの場合XArrayはvoid *[]と同じように使えますが、使用に当たってはいくつかの注意点があります。
保存できる値
XArrayのインデックスは0からULONG_MAXの任意の値が使えますが、エントリに保存できる値には制限があります。これはエントリの値の下位2ビットをタグとして利用しているためです。
- ポインタ値を保存する場合は、下位2ビットが0でなければなりません(つまり4バイト単位です)。通常kmalloc()やvmalloc()で確保したオブジェクトのアドレスは4バイト単位になっていますが、文字列中の文字のアドレスなどは注意が必要です。
- 即値を保存する場合は、0-LONG_MAXの値が利用できます(つまりBITS_PER_LONG - 1ビットの情報)。また、即値の場合はxa_store()に
xa_mk_value(value)で変換した値を渡し、xa_load()で取得した値をxa_to_value(entry)で変換する必要があります。
排他制御
XArrayは基本的にRCU listと同じような排他制御モデルを採用しています。参照操作にはrcu_read_lock()だけで良いですが、変更操作にはspinlockなどが必要です。Normal APIは実はAPI内部でこのロックを取っているため、通常ユーザが意識する必要はありません。ただし、割り込みハンドラやsoftirqハンドラ内部でXArrayを変更する場合や、エントリの値を操作の前後で保持する必要がある場合は、特別な注意が必要になります。
割り込みコンテキストとの排他
XArrayのNormal APIではspin_lock()によってロックを確保しているため、割り込みやソフトウェア割り込みを禁止していません。このため、Normal APIを使ってXArrayを更新している最中に割り込みが発生し、その中で同じXArrayを更新しようとすると、デッドロックが発生します。
XArrayでロックを保持しないNormal APIとして、前方に__(ダブルアンダースコア)を付加したAPIを提供すると共に、xa_lock_bh(xarray)、xa_lock_irq(xarray)(それぞれソフトウェア割り込み、及び割り込みを禁止しつつロックする)などの各種ロックAPIを提供しています。これを適切に組み合わせて利用すればデッドロックを回避できます。また代表的なxa_store()やxa_erase()には、予めこれらのロックを使った変種であるxa_store_bh()やxa_store_irq()のAPIが用意されています(xa_load()は参照しかしないのでロックは必要ありません)。
注意点としては、これらの変種APIは割り込みコンテキストではない方のコンテキストで使うAPIということです。通常コンテキストの方で割り込みコンテキストの発生を防ぐための変更だからです。
syscall_context(...)
{
...
/* 通常コンテキストでデータを保存し、ソフトウェア割り込みを待つ。
* 保存中にソフトウェア割り込みがあるとデッドロックするので_bhで防ぐ */
ret = xa_store_bh(&my_array, index, data, GFP_KERNEL);
...
}
softirq_context(...)
{
...
/* ソフトウェア割り込みでデータを受け取って消す */
data = xa_erase(&my_array, index);
...
}
エントリを操作の前後で保持したい
これはXArrayに限った話ではありませんが、例えばエントリの値そのものではなく、その値が示すデータ構造体の一部を参照したい場合、その参照が終わるまではデータ構造体を消さないで欲しいという場合を考えます。
xa_load()はXArray内部から値を取り出すまでの一貫性をrcu_read_lock()で保証しますが、その後の一貫性は保証していません。最悪の場合、xa_load()を呼んだ直後にpreemptされて、読み出した先の値が消える可能性があるわけです。
eraser() {
entry = xa_erase(&my_array, index);
kfree(entry);
}
reader() {
entry = xa_load(&my_array, index);
/* ここはもうrcu_read_lock()外部 */
if (entry)
ref = entry->ref; /* 本当に安全か? */
...
}
これを解決するには色々な方法があります(別途ロックを用意する、rcu_read_lockとkfree_rcuを使うなど)が、XArrayで保証する話ではないのでここでは割愛します。並列処理のプログラミングをする際には、XArrayそのものの操作の保証は不要ですが、そこで保持している値の操作の排他制御は自前で用意しなければなりません。
XArrayをkprobesに適用する
このXArrayのほぼNormal APIを使ってkprobesに適用しました。詳細は省きますが、kprobesのハッシュテーブルをXArrayで置き換えたものです。コード量自体の増減は殆ど無いので、書いていても筋が良いAPIだと思いました。一部、kprobesではプローブが色んなコンテキストから実行されるため、rcu_read_lock()を含むxa_load()をそのまま使うと警告が出てしまう問題が残っていますが、修正にはXArrayそのものも変更が必要な上、kprobes特有の問題なので、ここでは横においておきましょう。
kprobesのスケーラビリティ性能
では実際にXArrayの適用で性能はどの程度変わるのでしょうか。2014年にkprobesのハッシュテーブルを置き換えるなどして性能を計測した話(PDF注意)をまとめたのですが、その当時の手法と比べてみることにしました。(ちなみにこのシリーズ、最終的にやり取りが終了してしまいUpstreamには入っていません。v11まで行ったのに・・・。)
現在のkprobesはあまり大量のプローブを同時に扱うことを想定していません。そのため、ハッシュテーブルのサイズも64と小ぶりです。しかし、例えばカーネルの全ての関数の先頭にプローブを入れることを考えると、30,000個以上のプローブを同時に扱う必要が出てきます。この時、プローブそのもののオーバヘッドよりも、個々のプローブに対応するハンドラを探し出す探索ルーチンの実行に時間がかかることになります。これには現在の所、先程のハッシュテーブルを使っているのですが、例えば32,000個のエントリを64スロットしかないハッシュテーブルに入れると、1ストットあたり平均500個のエントリが存在し、概算の期待値では250個もリストをたどって見つける必要が出てくるわけです。
これをXArrayに置き換えれば、バックエンドが2log(n)ぐらいの小ささに収まって、探索にかかる時間が16回ぐらいで済んでくれるんじゃないかなー?、という想定の元、前回と同じようなテストを行うことにしました。
性能テストの方法
kallsymsから関数のリストを取り出し、ランダムにシャッフルしたものをターゲットリストとして使います。これらの関数に対して、ftraceを使ってkprobeイベントを追加・有効化します。これを繰り返し、1000個ごとに経過時間とメモリの消費量の概算値を出します。
# !/bin/sh
TRACING=/sys/kernel/debug/tracing
# kallsymsから存在する関数のリストをシャッフルしたものを生成。リストが存在すれば再利用する
if [ ! -f function-list ]; then
cat /proc/kallsyms | grep " [Tt] " | cut -d " " -f 3 | shuf > function-list
fi
start=`date +%s`
num=1
cat function-list | while read f; do
echo -n "[$num] Probing on $f "
if echo "p:kp/probe_$num $f" >> $TRACING/kprobe_events; then
# プローブ出来た場合の処理
echo 1 > $TRACING/events/kp/probe_$num/enable
time=`date +%s`
elaps=`expr $time - $start`
echo "$elaps sec"
if [ `expr $num % 1000` = 0 ]; then
echo $num $elaps >> result.log
free | grep ^Mem >> result.log
[ $num = 20000 ] && exit 0
fi
num=$((num + 1))
else
# 関数の中にはプローブ禁止されているものもある。単に無視する。
echo "fail"
fi
done
このテストでは、プローブがヒットするたびに参照される探索ルーチンの性能と、プローブを追加するたびに実行される追加ルーチンの性能が、総合的に判断されることになります。マイクロベンチマークというよりは実際に利用されることを想定したパフォーマンスのベンチマークといえるでしょう。(とは言えこれほどのプローブを一度に挿入する場面は今の所無いですが)
今回は厳密に測るようなものではないため、KVM仮想マシンをつかって計測をしました。また、前回の計測結果を踏まえ、ハッシュテーブルのテーブルサイズが64のものだけでなく、テーブルサイズを512に拡張した場合とも比較してみました。
対象とするマシンは、少し古いですがCore i7-4770S(8コア8MBキャッシュ)上で動かした仮想8コアのKVMマシンとしました。
性能テストの結果
性能テストの結果を下記の図に示します。まずはかかった時間(Elapsed Time)の結果です。
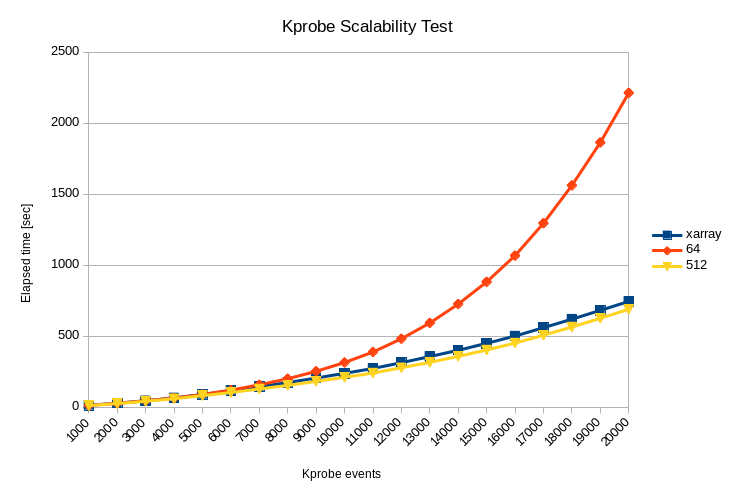
XArrayは現状の64スロットのハッシュテーブルよりは非常に良好な性能であることがわかります。ただ、ハッシュテーブルサイズを512にした場合に比べると、20Kプローブで若干(8%程度)の性能差が出ています。これは改善の余地がまだあるということでしょう。
次にメモリの使用量です。
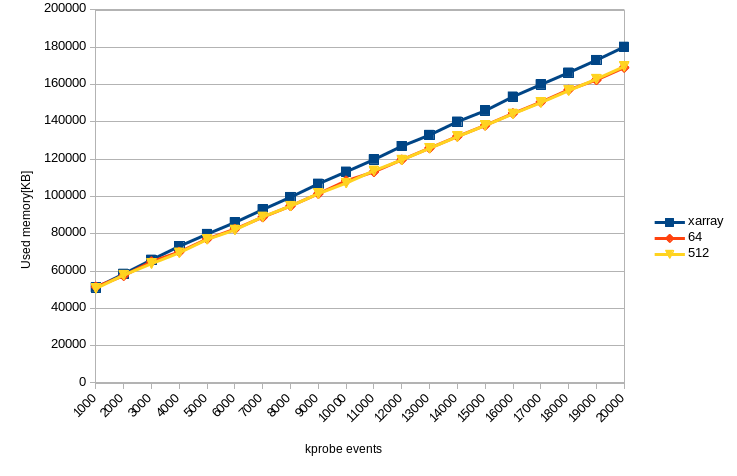
当然ですがメモリの使用量についてはハッシュテーブルを利用したときよりも大きくなる傾向があります。ツリー構造にする以上、1エントリあたり少なくともインデックス、値、関係を示す情報などが必要ですし、使っていないブランチも存在するからです(XArrayのデータ構造はもっと複雑ですが、ここでは説明を省きます)。それでも20Kエントリで10MB程度のメモリ消費量の差しかありません。
(厳密には各kprobesの構造体からhlist_nodeを削除しないといけないので、もう少しメモリ消費量は減るでしょう。)
検討と改善
性能については、恐らくツリーの深い所にあるノードに頻繁に使うプローブが入ってしまっているのだと思われます。探索される回数が多くなるイベントほどツリーの上に来て欲しいのですが、ツリー構造が元々そういうものではない(通常indexに従ってソートされる性質を持つ)以上、(単一の)ツリー構造だけではこれを解決することは出来ません。
つまりXArrayとは別に使用頻度順に並んだリストがあれば・・・おっ、こんなところにソフトウェアキャッシュがあるじゃないか。早速移植してみましょう。
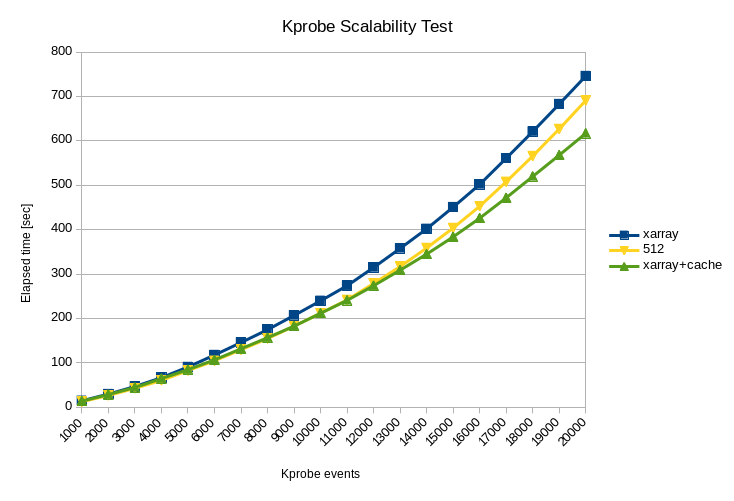
XArrayとCache(4ウェイ64セットアソシエイティブ・ラウンドロビン方式)を組み合わせた結果、kprobesのスケーラビリティ性能については512スロットのハッシュテーブルよりも良くなる(20Kプローブ時に約10%)という結果が得られました。
これをupstreamカーネルで制式採用するかどうかは、さらなる検討と議論が必要だと思います(メモリ消費量に加え、RCU周りのデバッグ処理で偽陽性の警告が出るなど)が、キャッシュとの併用を前提とすれば採用の目はあるかもしれません![]() 。
。
まとめ
Linuxカーネルで新しく導入されたXArrayについて、そのNormal APIの使い方や注意を説明し、実際にkprobesの参照テーブルに適用した場合のサンプルと、その性能を測定しました。
XArrayはハッシュテーブルに匹敵する性能の良さと使いやすさを両立したデータ構造であることがわかります。エントリ数が増えた場合のメモリ使用量はどうしても増えがちですが、下手にハッシュテーブルや双方向リストを使うのであれば、お手軽な連想配列として利用することを検討して良いものと思います。