Word2Vecに対するざっくりとした理解&説明です。
人に聞かれた時に簡単に概要を説明できるようになるくらいのレベル感です。
ゼロから作るDeep Learning2――自然言語処理編 の本を参考にしました。
Word2vecとは?
単語の分散表現の一つ。
推論ベースの手法で、2層のニューラルネットワークで構成されている。
ロジックとしては、単語を推測することを目標として、その副産物として単語の分散表現を得ることができる。
カウントベース vs 推論ベース
Word2Vecなどの推論ベースの手法に対して、カウントベースと呼ばれる手法がある。
カウントベースは、その名の通り単語の出現頻度によって単語の分散表現を得る。
カウントベースの問題点
- 学習データを一度にまとめて処理する必要がある
- 計算コスト高
推論ベース手法の利点
- 逐次的に学習する
- 並列計算も可
精度に明確な優劣はなく、
現在は両方の手法を融合させたようなGloVeという手法もある。
word2vecが使用するニューラルネットワークのモデル
Word2Vecが使用するニューラルネットワークのモデルは以下の2つがある。
- CBOW (continuous bag-of-words)
- skip-gram
ニューラルネットワークによる単語の処理方法
前提として、ニューラルネットワークによる単語の処理を説明する。
1. 単語をone-hot表現というベクトルで表す
you say goodbye and I say hello .
という文があるとする。
それぞれの単語に以下のように番号を振る。
|you|say|goodbye|and|I|hello|.|
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|0|1|2|3|4|5|6|
one-hot表現では該当する単語の番号のところを1,それ以外を0とする。
例えば次の単語を以下のようなベクトルで表すことができる。
you -> [1,0,0,0,0,0,0]
goodbye -> [0,0,1,0,0,0,0]
2. ベクトルをニューラルネットワークの入力層のニューロンとして、全結合層による変換を行う
単語をone-hot表現というベクトルで表したため、ニューラルネットワークの入力層として扱うことができる。
ここでは隠れ層を3つとすると、以下の図のように表現できる。
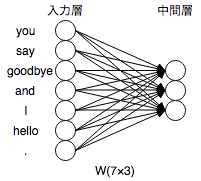
この重み付け(矢印)の7*3の行列をWと置く。
バイアスのない全結合層は、行列の積と同じ処理である。
※バイアス…重みをつける際に加算される定数のこと
※全結合層…隣接するニューロン間の全てに矢印による結びつきがあること
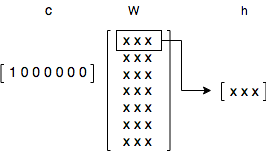
よって、入力ベクトルをc, 中間層をhと置くと
c × W = h
と表すことができる。
ちなみに、one-hot表現であるから、hは行列の性質で**「Wの該当の列を抜き出す」**ことに相当する。
CBOWとは
CBOW(continuous bag-of-words)は、**コンテキスト(周囲の単語)からターゲット(中央の単語)**を推測する。
コンテキストの抜き出す個数は任意に決められるが、ここでは前後1単語とする。
|you|?|goodbye|and|I|hello|.|
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
上記の文に対して、?の単語を推測する。
ターゲットがsay、コンテキストはyouとgoodbyeとなる。
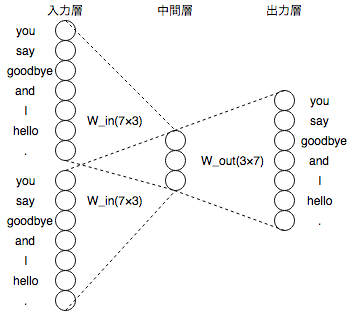
入力層:[you, goodbye]の2つ
中間層:ニューロンの値は各入力層の全結合による変換の値を平均したもの
出力層:7個のニューロンは各単語に対応しており、各単語の**「スコア」**を表す
このスコアにSoftmax関数を適用して**「確率」を求める。
このW_inの重み**こそが単語の分散表現。
CBOWモデルの学習
スコアをSoftmaxで確率に変換し、その確率と教師ラベルから交差エントロピー誤差を求め、それを損失として学習を行う。
W_inの初期値をランダムにおいて学習を行う。
学習を繰り返すことによってW_inの値は収束し、それが単語の分散表現となる。
※損失…学習段階のある時点におけるニューラルネットワークの性能を表す指標。どれだけ悪いかをスカラとして算出。
※交差エントロピー誤差…多クラス分類を行うニューラルネットワークに対して良く用いられる損失関数の一つ。
skip-gramとは
skip-gramは、**ターゲット(中央の単語)からコンテキスト(周囲の単語)**を推測する。
|?|say|?|and|I|hello|.|
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
上記の文に対して、?の単語を推測する。
CBOWと同様に、ターゲットがsay、コンテキストはyouとgoodbyeとなる。

入力層:[say]の1つの層。
中間層:ニューロンの値は各入力層の全結合による変換の値を平均したもの
出力層:2つの層が得られる。7個のニューロンは各単語に対応しており、各単語の「スコア」を表す
あとはCBOWとだいたい同じ。
CBOWに対するskip-gramの特徴
- skip-gramの方が良い結果が得られる傾向がある
- 計算コスト高
最後に
今後はDoc2Vec使ったクラスタリング実装したいです。
間違いや不明点があれば遠慮なくご指摘ください!