はじめに
ベクトルタイルの表示ライブラリである Mapbox GL JS では、Style Specification に従って地図のデザイン設定を行うことができます(以下、「スタイリング」と言うことにします)。
スタイリングは、第3者が提供するベクトルタイルを利用して Web 地図等を構築する際に、データ作成に介入しなくても、自らの手で描画速度向上に寄与できる重要なステップであると考えられます。様々な会社・機関からベクトルタイルが提供されていますが、(利用規約の範囲で)自分でスタイリングして、自分の Web 地図等に表示させることができるわけです。そのため、スタイリング技術の普及は、データ作成とは別のレイヤで、ベクトルタイルの活用につながると期待できると考えています。
Style Specification には、データやフォントデータ、アイコン画像等の設定も含まれますが、スタイリングの際の主な興味は、どの地物をどのような色や形状で表現するかだと思います。Style Specification では、layer という単位(以下、「スタイルレイヤ」と呼ぶことにします。)で、地物の絞り込み条件や色や形状のデザイン設定を行うことになります。
オープンに使えるベクトルタイルの提供機関のひとつである国土地理院では、9月初めに最適化ベクトルタイルを試験公開しています。このレポジトリでは、最適化ベクトルタイルの仕様のほか、表示用の「サンプルスタイル(標準地図風)」も提供されています。このスタイルを観察してみると、従来の地理院地図Vector 用のスタイルと比較して、スタイルレイヤ数が大幅に削減されており、その代わり、スタイルレイヤ内の設定が複雑に条件分岐していることがわかります。
スタイルレイヤを削減する代わりに、スタイルレイヤ内の設定が複雑になっているわけですが、これがパフォーマンスにどのように影響が出るのか気になりました。そこで、今回は、「スタイルレイヤ数と条件分岐のパフォーマンスへの影響」を実験して検証してみます。
Mapbox GL JS におけるスタイリング
ベクトルタイルをスタイリングする際は、まず、スタイルレイヤ毎に1つの source-layer(Mapbox Vector Tile のデータ格納単位)を指定できます。複数の source-layer を跨いだ指定はできません。その後、filter 設定により、地物の属性値等で、そのスタイルレイヤの適用範囲となる地物を絞り込みます。最後に、layout や paint の各設定で、色や形、レイアウト等の条件を決めていきます。ここで、layout や paint の設定では、さらに条件分岐を行うことができます。
そのため、以下のような順番で絞り込みが行われていくことになります。1~2は、データ作成段階、3~4は、スタイリングの段階の話です(とはいえ、データ作成時は、3~4も見据えて設計する必要はあるかと思います)。
- source(今回はタイルデータ)
- source-layer
-
filter設定 -
layoutやpaintでの条件分岐(data-driven)
さて、ここで気になるのは、「どこで絞り込みを行うのが適切か?」という点です。
1のsource(タイルデータ)単位の場合は、そもそもタイルの URL から別に分けるというものです。うまくいけば、データ通信量を削減できますが、ファイル IO が増えたり、ファイル管理が煩雑になるなどのデメリットも考えられます。
2のsource-layer単位で分ける場合は、基本的に通信するタイルの量には変化ありません。一方、タイル内のデータを分割しているので、目的のデータへアクセスしやすくなる可能性があります。私が先に行った以下の実験だと、source-layer 数を増やすことでパフォーマンスの改善が見られましたが、一方、闇雲に source-layer 数を増やしても効果は頭打ちであるほか、タイルそのものの容量が増加する懸念があります。
また、1~2の場合は、データに合わせてスタイルレイヤを分割せざるを得なくなり、スタイルレイヤ数は増加することになります。
1~2はデータ作成者側の視点でしたが、ここからは、データ作成者でなくとも関与できる段階(スタイリング)になります。
3の filter 設定を使う場合は、あるデザインを適用したい地物を絞り込み、デザインごとにスタイルレイヤを作成するという形になるかと思います。少なくとも、source-layer 内の地物に対して走査を行う必要が生じます。デザインが増えるごとにスタイルレイヤ数も増加しますが、条件分岐に対応していない設定についても、地物やデザインごとに柔軟な設定ができます。
4のスタイルレイヤ内の各設定内で条件分岐(data-driven なスタイリング)をさせる場合、スタイルレイヤを増やさずに、地物に応じたデザインを適用させることができます。ただし、data-driven に対応していない設定があるほか、1つの地物を別のデザインで二重に表示したいという需要の際は、スタイルレイヤを複製する必要があります。
条件分岐では、match や case を駆使することになります。以下の例では、ラインデータの色設定の条件分岐で、code が1なら赤、2なら青、その他は白になります。
"line-color": [
"match",
["get", "code"],
1, "rgba(255,0,0,1)",
2, "rgba(0,0,255,1)",
"rgba(255,255,255,1)"
]
なお、地物の描画順番を制御するために、スタイルレイヤを分離することもあるかもしれませんが、スタイルレイヤ内の地物を制御するのに *-sort-key という設定が用意されています。
実験内容
サンプルデータ
サンプルデータは、過去の実験で用いたタイルを利用することにします。このデータは source-layer 数と、source-layer 当たりの地物数を変えた 10/908/403 のタイルです。今回使うのは以下の条件のタイルです。
- タイル1:source-layer 数が1で、1つの source-layer にラインデータが10000地物入ったタイル
- タイル2:source-layer 数が10000で、1つの source-layer にラインデータが1地物入ったタイル
また、各地物は、属性値として code を持っており、1~10000 の数字のいずれかが他の地物と重複しないように格納されています。また、各地物の頂点は2つだけです。
ラインデータを対象にするのは、経験上、複雑なスタイリングが必要になるのは、道路や鉄道などのラインデータであることが多いからです。
スタイリングの条件
- Treatment 1 (
T1):タイル1に対して、filterを用いて、codeの数字毎にスタイルレイヤを地物数と同じ10000レイヤ作ります。各スタイルレイヤでは、別々の色を指定します。- ラインデータとして表示させる(スタイルレイヤの
type:line)ほか、頂点をポイントデータとして表示させる(スタイルレイヤのtype:circle)パターンも試します(それぞれT1-Ls、T1-Ptとします)。データ自体は変えずに、ラインデータの頂点をポイントとして表示させるものです。
- ラインデータとして表示させる(スタイルレイヤの
- Treatment 2 (
T2):タイル1に対して、色のスタイル設定(*-color)に対して data-driven な条件分岐を用いて、地物のcode毎に別の色を指定します。スタイルレイヤは1つだけ作ります。- ラインデータとして表示させるほか、頂点をポイントデータとして表示させるパターンも試します(それぞれ
T2-Ls、T2-Ptとします)。 - 色だけでなく、
line-gap-width、line-width,line-opacityにも条件設定を適用したパターンも試しました(T2-Ls2とします)。しかし、T2-Ls2で、line-widthを0に設定してしまい、地物が表示されずにパフォーマンスへ影響が出た可能性があるため、使わないことにしました(計測は実施しました)。 - 代わりに、
line-widthが0にならないように再設定した処理も行いました(T2-Ls3とします)。 - レイヤの順番制御のコストも確認したかったため、
T2-Lsに以下のようにline-sort-keyを設定した処理も行いました(T2-Ls4とします)。
"line-sort-key": ["get", "code"] - ラインデータとして表示させるほか、頂点をポイントデータとして表示させるパターンも試します(それぞれ
- Treatment 3(
T3):タイル2に対して、source-layer によりスタイルを指定する条件も試します。スタイルレイヤでは、source-layer のみを指定して、filterやスタイル設定での条件分岐は使いません。スタイルレイヤは、source-layer 数分の10000レイヤ作ります。- ラインデータとして表示させるほか、頂点を点データとして表示させるパターンも試します(それぞれ
T3-Ls、T3-Ptとします)。
- ラインデータとして表示させるほか、頂点を点データとして表示させるパターンも試します(それぞれ
以下の表に、処理毎の条件をまとめました。
| 処理名 | スタイルレイヤ上での地物の種類 | source-layer 数 | 絞り込み | スタイルレイヤ数 | 備考 |
|---|---|---|---|---|---|
| T1-Ls | LineString | 1 | filter |
10000 | - |
| T1-Pt | Point | 1 | filter |
10000 | - |
| T2-Ls | LineString | 1 | data-driven | 1 | - |
| (T2-Ls2) | LineString | 1 | data-driven | 1 |
line-gap-width、line-width, line-opacityにも条件分岐。line-width が0になる可能性あり。今後の解析では不使用。 |
| T2-Ls3 | LineString | 1 | data-driven | 1 |
line-gap-width、line-width, line-opacityにも条件分岐。line-width が0になる可能性なし。 |
| T2-Ls4 | LineString | 1 | data-driven | 1 |
line-sort-key設定。 |
| T2-Pt | Point | 1 | data-driven | 1 | - |
| T3-Ls | LineString | 10000 | source-layer | 10000 | - |
| T3-Pt | Point | 10000 | source-layer | 10000 | - |
また、スタイルの例を示します。
-
T1-Ls:スタイルレイヤ数10000、単一の source-layer からfilterで絞り込み
"layers":[
{
"id": "1", "type": "line", "source": "v",
"source-layer": "1", "minzoom": 10, "maxzoom": 22,
"filter": [ "all", [ "==", [ "get", "code" ], 1 ] ],
"layout": { "visibility": "visible" },
"paint": { "line-color": "rgba(99,0,255,1)" }
},
...
{
"id": "10000", "type": "line", "source": "v",
"source-layer": "1", "minzoom": 10, "maxzoom": 22,
"filter": [ "all", [ "==", [ "get", "code" ], 10000 ] ],
"layout": { "visibility": "visible" },
"paint": { "line-color": "rgba(100,100,255,1)" }
},
]
-
T2-Ls:スタイルレイヤ数1、line-colorを data-driven で10000通り(default を入れると10001通り)の条件分岐
"layers":[
{
"id": "1", "type": "line", "source": "v",
"source-layer": "1", "minzoom": 10, "maxzoom": 22,
"layout": { "visibility": "visible" },
"paint": {
"line-color": [
"match",
["get", "code"],
1, "rgba(99,0,255,1)",
...
10000, "rgba(100,100,255,1)",
"rgba(0,0,255,1)"
],
}
}
]
-
T3-Ls:スタイルレイヤ数10000、filterを使わずに、source-layerで絞り込み
"layers":[
{
"id": "1", "type": "line", "source": "v",
"source-layer": "1", "minzoom": 10, "maxzoom": 22,
"layout": { "visibility": "visible" },
"paint": { "line-color": "rgba(99,0,255,1)", }
},
...
{
"id": "10000", "type": "line", "source": "v",
"source-layer": "10000", "minzoom": 10, "maxzoom": 22,
"layout": { "visibility": "visible" },
"paint": { "line-color": "rgba(100,100,255,1)" }
}
]
計測用のサイト
上記で説明したベクトルタイルを実際に Mapbox GL JS を利用したサイトで、設定した条件のスタイリングで表示させて、描画にかかった速度を計測します。計測は、Mapbox GL JS で Map オブジェクトの作成から、idle イベントが起きるまでとします。なお、idle イベントは、最後のレンダリングが終了して idle 状態に入る前に起きます。参考に style.load イベントと、load イベントも測定しています。
- Chrome のデベロッパーツールで、キャッシュを無効化して行いました。
- タイル、Mapbox GL JS のライブラリ(js、css、map)、フォントデータ、アイコン用の Sprite ファイルは localhost (python による簡易サーバでホスト)から取得しています。
- 画面には、
10/908/403のタイルが含まれるようにしましたが、周囲の8タイルの領域も画面に含まれていたので、404 エラー処理の影響も含まれます。 - なお、idle イベント時に
location.reload()を実行することで、何度も地図の描画を繰り返します。Chrome のデベロッパーツールで console のログをページ読み込み後も残すように設定することで、待っているだけでログがたまります。 - 表示のたびに、処理をランダムに変更します。これにより、ネットワークや PC の調子などの影響が生じる誤差をなるべく防いでいます。
- ランダムに表示させている関係上、各処理数ごとのサンプル数はばらついています。
計測
計測は、3回に分けて行いました。
1回目の計測では、T2-Ls3 を除く、全処理の試験を行いました(計測1)。その後、T2-Ls2 で、line-width が0に設定されると、地物が表示されずにパフォーマンスへ影響が出た可能性に気が付きましたので、改めて T2-Ls と T2-Ls3 を比較しました(計測2)。また、レイヤの順番を制御するとどの程度パフォーマンスに影響がでるのか、T2-Ls と T2-Ls4 を比較しました(計測3)。
統計処理
計測1の結果は、T2-Ls2 の結果を除いた後、2元配置の分散分析(ANOVA)で処理(T1、T2、T3)とスタイル上の図形の種類(ラインかポイントか)の効果を検定後、有意差があった場合に、Tukey 検定で有意差のある組み合わせを確認しました。計測2、3は2群の比較なので、Welch の t 検定を行っています。
統計処理は R 4.2.1 で行いました。ANOVA や t 検定、作図における参考文献は以下の通りです。
レポジトリ
本実験に関するレポジトリは以下です。「実験結果」フォルダに測定結果を格納しています。各処理の具体的なスタイル生成プログラムは、index.htmlに直接記載しています。
実験結果
計測1 (T2-Ls2、T2-Ls3、T2-Ls4 を除く全処理の比較)
- 分散分析により、処理と図形の種類の両方で有意差(どちらも p<0.001)がありましたが、相互作用は見られませんでした。
- Tukey 検定の結果、
T1、T2、T3の各処理の間では有意差(p<0.001)がありましたが、ラインとポイントの違いは見られませんでした。
以下は、分散分析の結果です(treatment が処理、geom が図形の種類を意味します)。
Response: df$idle
Df Sum Sq Mean Sq F value Pr(>F)
df$geom 1 3.5966e+08 359655907 14.4444 0.000198 ***
df$treatment 2 1.2732e+10 6366171197 255.6761 < 2.2e-16 ***
df$geom:df$treatment 2 6.2319e+07 31159252 1.2514 0.288606
Residuals 178 4.4321e+09 24899362
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1
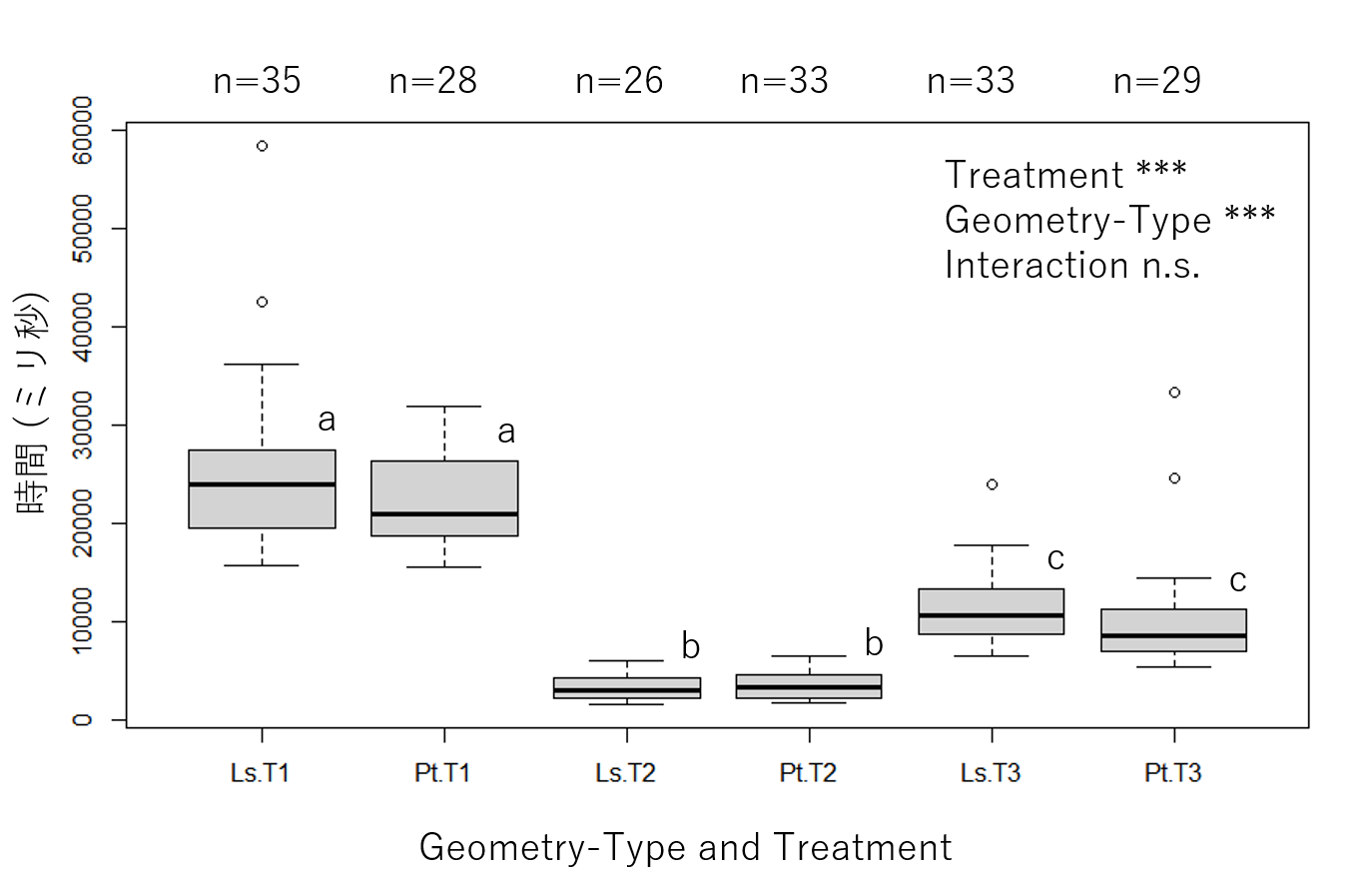
各箱ひげ図に同じ文字がある場合は、Tukey 検定による有意差がないことを示します。
ちなみに、各処理を表示させたときの様子は以下の通りです。
計測2 (T2-Ls と T2-Ls3 の比較)
- Welch の t 検定の結果、
T2-LsとT2-Ls3には有意差(p<0.001)が見られました。
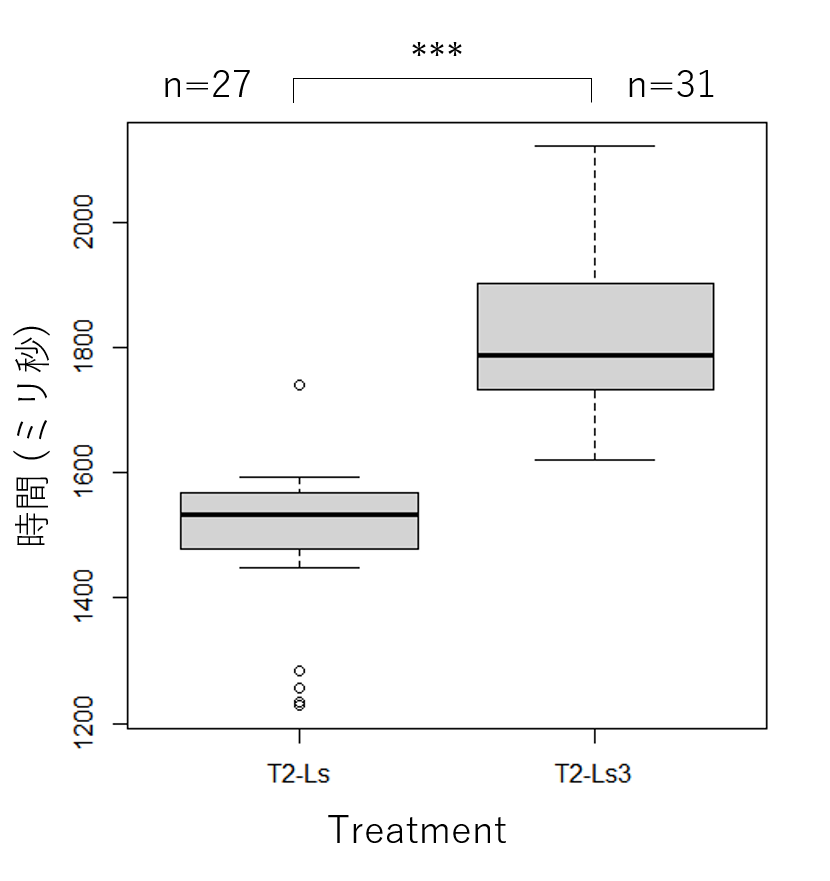
各処理を表示させたときの様子は以下の通りです。

計測3 (T2-Ls と T2-Ls4 の比較)
- Welch の t 検定の結果、
T2-LsとT2-Ls4には有意差が見られませんでした。
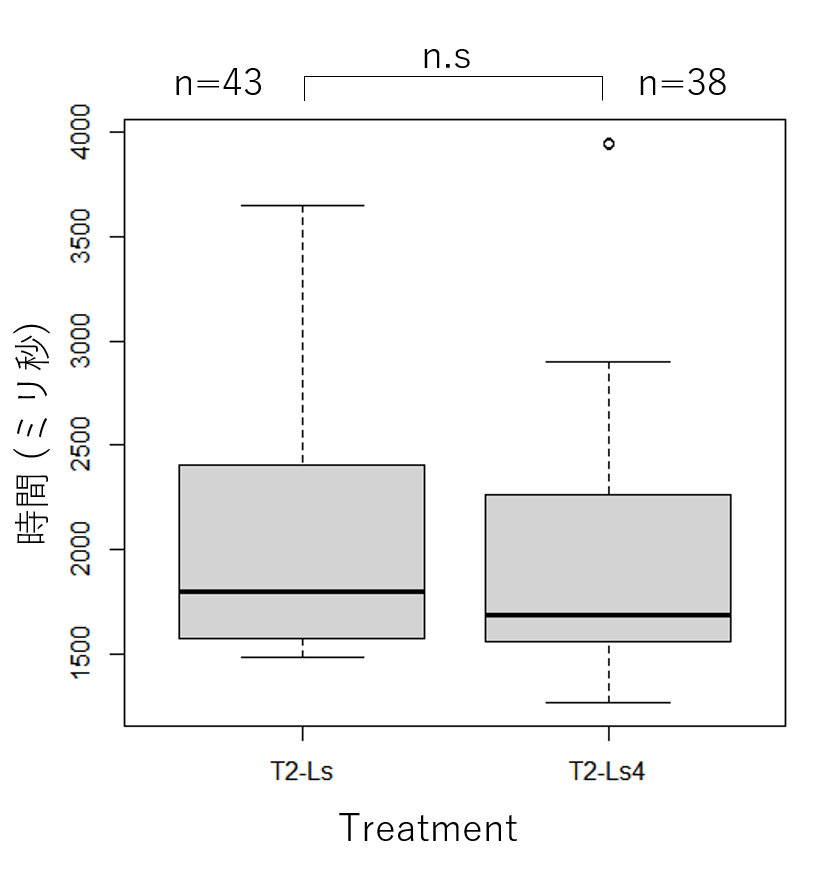
各処理を表示させたときの様子は以下の通りです。

考察
特筆点として、data-driven なスタイリングを活用してスタイルレイヤ数を削減することで、パフォーマンスを大幅に向上できることがわかりました。計測1では、同じデータに対して、スタイルレイヤ数が10000(T1)と data-driven を活用してスタイルレイヤ数を1に抑える(T2)とでは、6~7倍のパフォーマンス向上が見られました。また、計測2の結果から、data-driven による条件分岐を増やすと、パフォーマンスは悪化はしますが、その差は、スタイルレイヤ数を変更した際と比べると小さいです。
この実験結果をもとにすると、スタイルレイヤ数を削減し、data-driven なスタイリングを多用している国土地理院の最適化ベクトルタイル用「サンプルスタイル(標準地図風)」では、パフォーマンスの観点からスタイルも最適化されているのではないかと考えられます。ただし、最適化ベクトルタイル用スタイルに関する記事で触れたとおり、あまりに最適化されたスタイルでは、編集の難しさから、ベクトルタイルの強みである「自分でスタイリングができる」という体験を提供するのが難しい可能性があります。パフォーマンスとユーザビリティのバランスを考えながら、データ、スタイル、Web 地図等を合わせたエコシステムを考えていくことが大切になりそうです。
計測3の結果から、スタイルレイヤ内で line-sort-key を用いて、地物の描画順を制御した場合でも、影響はあまり大きくなさそうです。そのため、地物の描画順制御においても、安易にスタイルレイヤを増やさずに、なるべくスタイルレイヤ内の *-sort-key 設定で済ませた方がパフォーマンスが向上すると考えられます。
また、今回議論しているベクトルタイルや Mapbox GL JS の開発主体である Mapbox 社は、ベクトルタイルのパフォーマンス向上のヒントを掲載されています。パフォーマンス向上のための戦略が提示されていますが、その最初の項目が、スタイルレイヤを統合して、スタイル数を削減する、というものです。
スタイルレイヤ数が同じく10000の T1 と T3 ですが、計測1の結果から、filter ではなく source-layer を用いてスタイルを適用する T3 の方が、コストを半分近くに抑えることができました。この結果は、以前の実験の結果とも合致します。そのため、データの段階で、スタイリングまで見据えて、source-layer を適切に分離しておくことが必要と考えられます。
なお、source-layer を分離した場合、スタイルレイヤ数を source-layer 数よりも抑えることはできないため、スタイリングの際のパフォーマンスの工夫を損ねる可能性もあります。パフォーマンス向上のために、安易に source-layer を分割することについては、以前の実験でも懸念のコメントをしましたが、本実験の結果からも、過度な source-layer の分離には、ますます慎重になる必要がありそうです。
適切に soruce-layer を分離させる際のヒントとしては、たとえば、スタイルレイヤを独立して設計できるグループごとに soruce-layer を分離する方法が考えられます。図形の種類(ポイント・ライン・ポリゴン)ごとに分離したり、地理院地図Vector のように、もう少し細かい粒度で分けることは妥当と考えられます。
ただし、上記のMapbox 社のパフォーマンス向上のヒントでは、source に関する事項(タイルの統合や分離)については触れられていますが、source-layer への言及はありません。
分散分析の結果、同じデータでもラインデータとして表示させる(スタイルレイヤの type:line)よりも、頂点をポイントデータとして表示させる(スタイルレイヤの type:circle)方がパフォーマンスが良いことがわかりました。ただし、Tukey 検定による個々の比較では、有意差がなかったことから、わずかな差であると考えられます。
最後に
本実験から、今後、パフォーマンスを上げたいのであれば、スタイルレイヤ数はなるべく減らすという明確な方針を見出すことができました。
しかし、data-driven なスタイリングは、編集が非常に難しくなることから、最適化までできるかというと難しいという感想です。なんらかスタイルを書いたら、それをコンパイルするように最適化してくれるツールがあると便利だなと感じました。
この記事冒頭でも書きましたが、ベクトルタイルの場合は、第3者のデータを使う際でも、スタイリングというステップで各自で工夫できる余地が残されております。そのため、ベクトルタイルまわりのエコシステムにおいて、コミュニティのスタイリング経験の蓄積や多様性は、そのベクトルタイルの隆盛を左右するひとつの要素かもしれません。一方で、見慣れたデザインが一番わかりやすい、という話も聞いたことがありますから、成熟したエコシステムでは、最適化された少数のスタイルで寡占状態になるのかもしれません。