きっかけ
それまでサーバやアプリケーションのログをためるため elasticsearch 2.x を使っていました。サーバ9台(マスターノード2台、データノード6台、検索ノード1台)でクラスタを組んで運用していたのですが、2年ほどたってくるとindexやdocumentの数が増えてきて常にクラスタの負荷が高い状態になってしまっていました。うーん、なんとかしないとなと考えていたところ少し余裕ができたのでクラスタごと置き換えることにしました。とはいえ潤沢に時間があるわけではないのでデータの移行は考えず、新しいクラスタを作ってそちらに新しくデータを流しはじめることにしました。
Elastic Stackってなんだろう?
さてさてまずは情報集めです。情報を集めたときの最新バージョンは6.4でそれまで elasticsearch 2.x を使っていたのでだいぶバージョンアップが行われていました。とくに5.xからは elasticsearch 関連製品をまとめて Elastic Stack と呼ぶようになっており浦島太郎状態です。インストールマニュアルをみるといろいろな製品をインストールする必要があり以前よりハードルがあがっているなと感じながら、それぞれの役割を整理していきました。
| 製品名 | 役割 | 可動環境 |
|---|---|---|
| Elasticsearch | データ保存と検索 | Elastic Stackクラスタ |
| Kibana | データの可視化 | Elastic Stackクラスタ |
| Logstash | データの変換 | Elastic Stackクラスタ |
| Beats | データの収集エージェント | サーバ |
可動環境はそれぞれの製品をどの環境にインストールして使うかです。Beats以外はElastic Stackクラスタを組むサーバに、Beatsはデータを収集したいサーバにインストールして使うことにしました。BeatsはさらにFilebeat、Metricbeatなど複数の製品にわかれています。
クラスタ構成
実際に新旧環境でデータの流れがどうかわったのかを図で説明します。
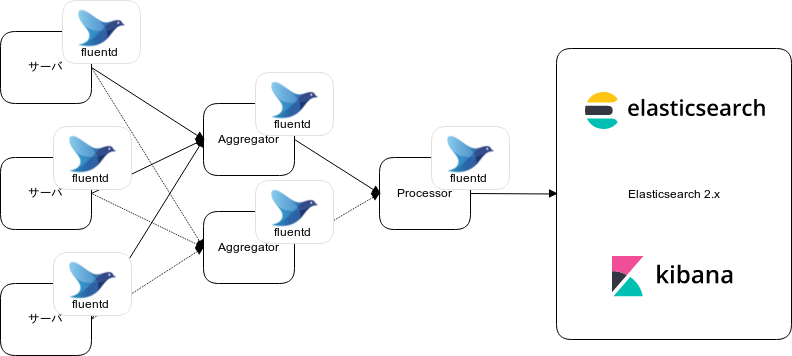
旧環境
サーバにインストールしたfluentdからfluentdのクラスタにデータを転送して、そこからElastichseachクラスタにデータを転送していました。
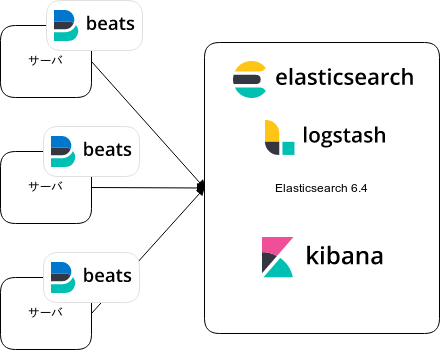
新環境
サーバにインストールしたBeatsからElastic Stackクラスタにデータを転送するようになりました。
まとめ
情報を整理する前は扱いが難しくなった印象があったのですが、整理してみるとそんなことありませんでした。個人的にはfluentdを使わなくて済むようになり、サーバにBeats製品のGoバイナリを置くだけでElastic Stackと連携できるようになったのは管理するサーバが減ってメリットだなと感じました。