こんにちは、グレンジ Advent Calendar 2022の10日目担当のmesshiです。
Advent Calendar駆動の発信となっていますが、今年もニッチな記事を書こうかなと思います。
さて本記事は、Androidアプリのメモリ使用量を「 軽量に 」取得する方法について取り上げます。
Unityを前提とした記事とはなっていますが、取得方法に関してはAndroid OS共通の手法となります。
背景
よくある取得方法
UnityでAndroidのネイティブコードからプロセスのメモリ使用量を取得する方法は、パッと探しただけで以下の記事がありました。
- 標準Profilerだけに頼らないUnityのプロファイリングに挑んでみる
- 【UnityAsset】FPSMemoryFriends – UnityでAndroid/iOSのFPSとメモリ使用量を取得する
これらの記事はどちらも同じ方法でメモリ使用量を算出しています。
まずActivityManagerのgetProcessMemoryInfoという関数を利用してプロセスのメモリ情報を取得します。
その後、得られたメモリ情報からPss形式で使用メモリの総量を算出しています。
Debug.MemoryInfo[] memoryInfos = activityManager.getProcessMemoryInfo(new int[]{ Process.myPid() });
for(Debug.MemoryInfo mi : memoryInfos) {
usedMemoryKB += mi.getTotalPss();
}
私も当初はこれらの記事を参考にして社内ツールに組み込み、正しく値を取得できていることを確認しました。
しかし、この実装には大きな落とし穴がありました。
落とし穴
ある日、社内のエンジニアより 致命的な不具合報告 を受けました。
それはAndroidOS 9.0以下の場合に「フレームレートが2~3ぐらい」になってしまうという事象です。
半信半疑でGalaxyS8 (OS 8.1)で実際に計測すると、処理時間が「 95ms 」という驚きの結果となりました。 (Deep Profileとはいえ...)
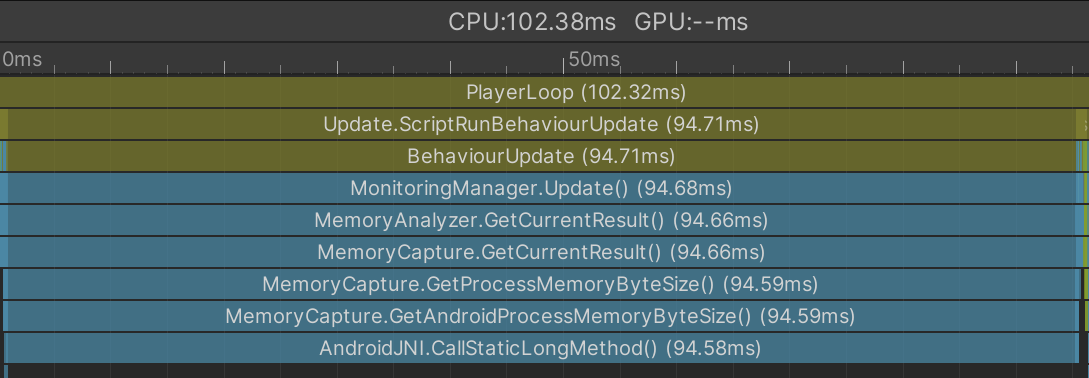
ところが、私がデバッグの際に利用していたAndroidOS 11の端末では1msほどの処理コストとなっていました。
この原因について調べた結果、APIドキュメントのgetProcessMemoryInfoに理由が記載されていました。
Also of Android Q the sample rate allowed by this API is significantly limited, if called faster the limit you will receive the same data as the previous call.
(意訳) AndroidQ (10.0)では、このAPIのサンプルレートは大きく制限されています。制限以上に早く再度APIをコールすると、同じ値を返却します。
つまり、正常に取得できていると思っていた値はキャッシュされた値が返却されていただけで、キャッシュがない場合は同程度の処理コストが掛かっているようでした。
もちろんOS9.0以下では、この仕様がないためフレームレートが非常に低くなります。
ちなみに、このサンプルレートはソースコードを確認すると300秒となっています。
Androidのソースコードの詳細を知りたい方はトグルの中をご確認ください。
Androidのソースコード
private static final long DEFAULT_MEMORY_INFO_THROTTLE_TIME = 5*60*1000;
// The minimum time we allow between requests for the MemoryInfo of a process to throttle requests from apps.
public long MEMORY_INFO_THROTTLE_TIME = DEFAULT_MEMORY_INFO_THROTTLE_TIME;
public Debug.MemoryInfo[] getProcessMemoryInfo(int[] pids) {
enforceNotIsolatedCaller("getProcessMemoryInfo");
final long now = SystemClock.uptimeMillis();
final long lastNow = now - mConstants.MEMORY_INFO_THROTTLE_TIME;
~~~~
if (proc != null && proc.lastMemInfoTime >= lastNow && proc.lastMemInfo != null) { |
// It hasn't been long enough that we want to take another sample; return the last one.
infos[i].set(proc.lastMemInfo);
continue;
}
~~~
どうして処理コストが高いのか?
さて、そもそも処理コストが高い理由はどうしてなのでしょうか?
それはメモリ使用量の指標となる「PSS」や「RSS」について理解する必要があります。
RSSはシンプルなメモリ指標で、共有ライブラリも含めてメモリ使用量として計算します。
ただしRSSを用いて、OSで稼働しているプロセスすべてのメモリ量を計算すると、共有ライブラリを利用しているプロセス数分だけ重複して加算されることになります。
これを防ぐためにPSSという指標が考案されました。
PSSは共有ライブラリをそのまま計算せず、共有しているプロセス数で分割して計算します。
文字だけだと分かりにくいので図にしてみます。 (図は公式ドキュメントより拝借しました)
いま、あるAppが共有ライブラリの「Location Service」を利用しています。
更に、この共有ライブラリはGoogle Play ServicesのAppも利用しています。
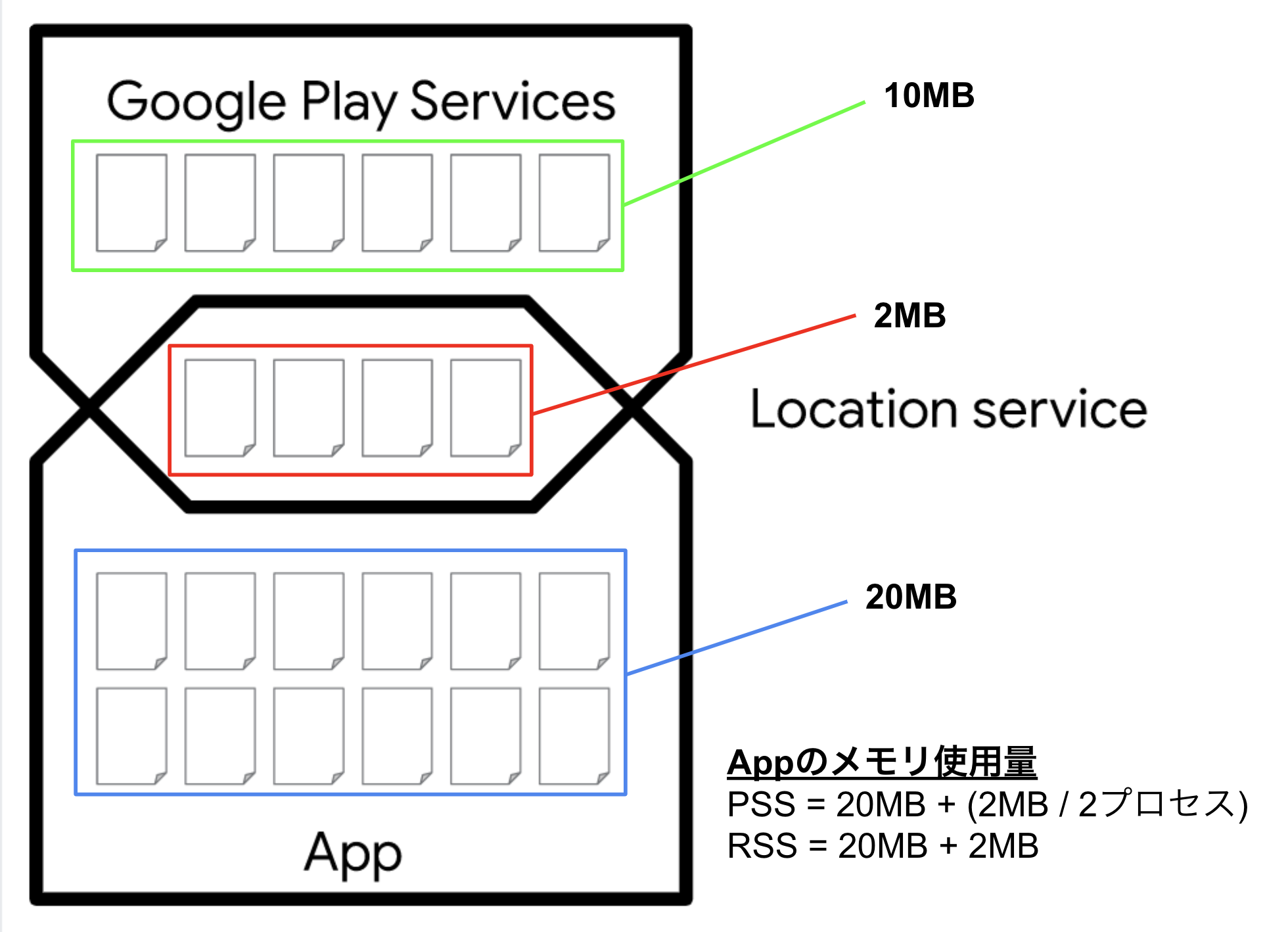
このときAppのRSSはシンプルに22MBとなります。
しかし、PSSではLocation Serviceを利用している2プロセスで分割するので、21MBとなります。
このように、PSSという指標を利用する場合、他のプロセスを考慮する必要があるため処理コストが高くなると言えるでしょう。
公式ドキュメントにも以下のように記載されていました
PSS は、共有するページとプロセスの数をシステムで調べる必要があるため、計算に時間がかかります。
RSS は、共有ページと非共有ページを区別せず、計算が高速化されるため、メモリ割り当ての変化を追跡するのに適しています。
対策方法
ここまでの話が理解できていれば、処理速度を改善するためには、RSS方式でメモリを取得すればよいことが分かるでしょう。
RSS方式で取得する方法についてはStackoverflowにて取り上げられていました。
ポイントは「proc」というプロセスの情報を含む疑似ファイルシステムから、RSSの値をファイル読み込みで取得するという方法です。
以下が対応したソースコードになります。
private static final String PROC_STATM_PATH = "/proc/self/statm";
private static final int PAGE_SIZE = 4 * 1024;
public static long getUsedMemoryKB(Context context) {
// RSSベースで高速に取得するためにprocのstatmファイルを読んでパースする
String statm = readFirstLine(PROC_STATM_PATH);
if (statm == null) {
return 0;
}
String[] stats = statm.split("[ \t]", 3);
if (stats.length < 2) {
return 0;
}
return Long.parseLong(stats[1]) * PAGE_SIZE / 1024; // KB変換
}
private static String readFirstLine(String path) {
try (BufferedReader reader = new BufferedReader(new FileReader(path))){
return reader.readLine();
} catch (IOException e) {
return null;
}
}
ソースコードの補足として、procに関するドキュメントに記載されているstatmの情報を記載します。
(ページ単位で計測した) メモリー使用量についての情報を提供する。 各列は以下の通りである。
size プログラムサイズの総計 (/proc/[pid]/status の VmSize と同じ)
resident 実メモリー上に存在するページ (/proc/[pid]/status の VmRSS と同じ)
share 共有ページ (ファイルと関連付けられているページ)
text テキスト (コード)
lib ライブラリ (Linux 2.6 では未使用)
data データ + スタック
dt ダーティページ (Linux 2.6 では未使用)
ソースコードでstats[1]となっているのは上記のドキュメントの通り、residentが1列目にあるためです。
また、ページサイズは4KBを単位としているためPAGE_SIZE = 4 * 1024となります。
結果
同じGalaxyS8にて約1.0msほどの処理コストとなりました。

まとめ
メモリ指標の概念としてRSSとPSSの違いを理解し、よく紹介されている手法がなぜ処理コストが高いのかを理解することができました。
またRSSのメモリ量を取得するために、procという疑似ファイルシステムを利用すれば良いこともわかりました。
しかし、まだ1.0msのコストが掛かっています。
更にこれを最適化する場合は、AndroidJNI呼び出しをスレッド化すると良いでしょう。
スレッド呼び出しを行う場合、以下のようにAttachCurrentThreadとDetachCurrentThreadを呼び出すことで可能になります。
private void SubThread() {
AndroidJNI.AttachCurrentThread();
// RSSのメモリ量を取得する
AndroidJNI.DetachCurrentThread();
}
最後にいつものごとく、Grengeで一緒に働くメンバーも募集していますので、興味を持って頂けた方は是非弊社のサイトもご覧ください。
それでは、最後まで読んで頂き、ありがとうございました。