BPアドベントカレンダー24日目です。クリスマス・イブにもかかわらず特になにも予定がないのが不思議です。仕方ないので、来年のクリスマスに向けてクリぼっち非モテ男子脱却の策を検討したいと思います。
背景
まず来年のクリスマス・イブを楽しむためにはモテる必要があります。モテない要素を数えだすと今年が終わってしまうので、非モテの理由は「話が面白くないから」という点に限定します。会話が面白くないからモテないのです。致命的ですね。面白い応答(受け答え)さえできれば、モテるはずです。今回のゴールはモテるための面白い自動応答の検証です。
【注意】結局、時間内に検証が終わりませんでしたので尻すぼみになっています。途中までの記録を残すことにしました。モテ男子が解決してくれるのを願って。。。
応答のための技術としてseq2seqなどの生成モデルによるアプローチが有名ですが、Retrieval-based(検索ベース)のモデルの話を最近聞いて興味が湧いたので今回そちらをやってみたいと思います。
検討する学習・検証データセットとしては以下を考えています(ここに落とし穴がありました)
- モテる例文集
- 漫才の台本
- 一般的な対話データセット
Retrieval-basedアプローチ
Retrieval-basedは、発話応答のペアから類似度を学習し、その類似度にもづいて、候補となる複数の応答の中から正しい応答を抽出するアプローチを指すようです。情報検索(IR)やレコメンデーションと同じような感じですね。その中でも今回試すのは、Dual LSTMという手法になります。
モテ会話をリアルタイムで行っていくという意味では、「候補文から選定」という部分で柔軟性に欠けそうですが、既存のテンプレートを使うことで、生成モデルより文法的な間違いがないなど安定感のある文章が作れて良いかもしれません。安定感のある解答のできる男はモテそうです。
Dual LSTMの概要
Dual LSTMは、共有されたLSTMに発話(Context)と応答(Response)の2つのシーケンスを入力するというのが特徴で、本当の応答かどうかを分類問題として解くことで類似度を獲得します。2015年6月に提案された比較的古い手法ですが、当時の検索の抽出精度(Recall@k)ではSOTAな手法を上回る精度を出していたようです。論文や他の実装を見たところ、ネットワーク・学習のポイントとしては以下のような感じだと思います。
- 発話・応答のシーケンスペアと、その入力が正しい発話応答のペアか
{0, 1}のラベルを入力し学習。正しい発話応答かどうかのスコア(類似度)を出力 - 発話と応答で共有のEmbedding層とLSTM層を用いる
- 類似度はLSTMの隠れ層の出力を行列内積で変換し推定
図1:Dual LSTMのネットワーク(論文より)
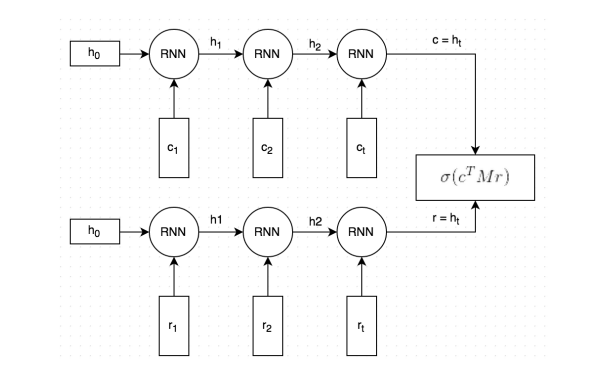
2つのシーケンス入力があり、LSTM層の出力が内積でマージされています。
式1:Dual LSTMの類似度スコア(論文より)
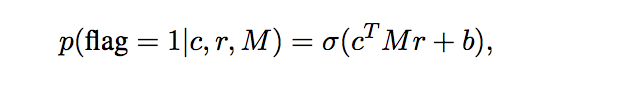
シーケンスが終了した、時刻 $t$ での発話、応答のLSTM出力をそれぞれ $c, r$とし、学習可能な行列$M$により$c$を変換することで正しく$r$と近くなったり、離れたりするようにします。最終的な類似度は$c$と$r$の内積をとってsigmoidにかけることで算出します。
Embedding層とLSTM層による順序を加味した文章の意味合いが抽出され、$M$で良い感じに正解のペア同士が近くなるイメージでしょうか。
式2:Dual LSTMのLoss(論文より)

Lossはcrossentropyを使っています。論文の式には正則化項が入っていますが、実際には $\lambda = 0$ のため考慮されていません。
全体的にネットワークも考え方もシンプルで好印象です。内容としては、順序を考慮した類似度計算といった趣きでしょうか。詳細は、元論文やこのブログに詳しく書かれていますので、もし興味があればそちらを参照ください。
ネットワークの構築
ネットワークを構築します。今回はkerasを使って構築しています。構築部分のソース全体は下の方にあります。部分ごとに見てみます。
Embedding層とLSTM層の共有
まず入力層のshape指定ではシーケンス長を指定します。その後、共有用のEmbedding層とLSTM層を準備し、Embeddingの次元やLSTMのユニット数の指定を行います。今回は時間がなかったのとローカル環境のMac Proで実行するので、パラメータが多くならない事を考慮した以外は、適当です。
# 発話と応答の入力層
input_c = Input(shape=(timesteps,))
input_r = Input(shape=(timesteps,))
# 共有用の層の準備
shared_emb = Embedding(input_dim=dim_input, output_dim=dim_emb)
shared_lstm = LSTM(units=dim_h)
# Embedding層の追加
word_vec_c = shared_emb(input_c)
wrod_vec_r = shared_emb(input_r)
# LSTM層の追加
h_c = shared_lstm(word_vec_c)
h_r = shared_lstm(wrod_vec_r)
類似度算出
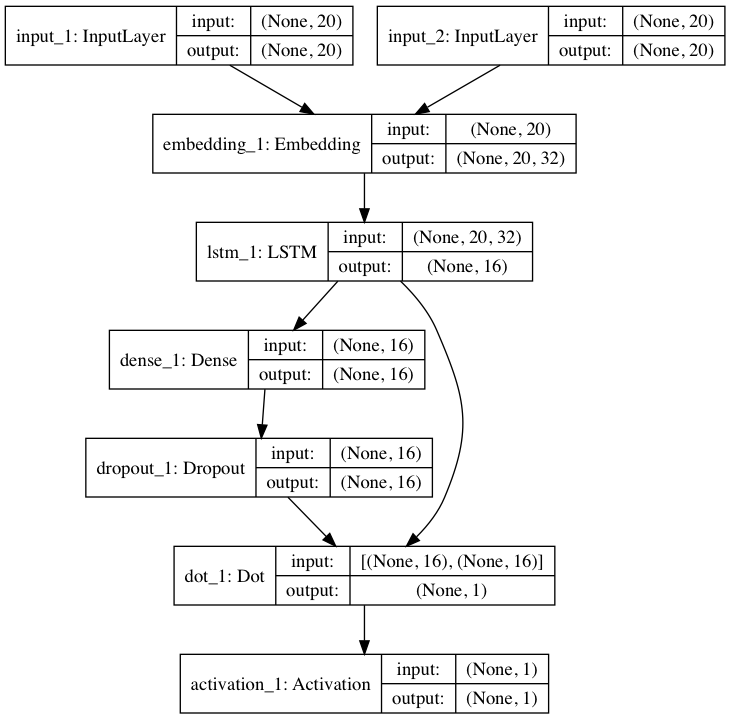
論文では明示的に行列$M$を導入して$c$との内積をとっていますが、全結合層を入れれば同じかなと思って、そのためのDenseをactivationなしで入れてます。Dropout層はデータの数が少なかったので過学習しそうだなと思ってなんとなく入れてみました。その後、類似度スコアとしてdot層で内積を計算しています。
# 行列Mの部分
x = Dense(dim_h)(h_c)
h_c_M = Dropout(0.5)(x)
# 内積を取って類似度算出
dot_vector = keras.layers.dot([h_c_M, h_r], axes=-1)
# 活性化関数を追加
predictions = Activation(activation='sigmoid')(dot_vector)
Lossと最適化
Optimizerは特に考えなくrmspropにしています。論文ではAdamを使っているようです。Lossは論文と同じcross entropy。
# {0, 1}を当てるのでcrossentropy。optimizerは適当
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
以上になります。シンプルですね。ネットワーク構築部分のコードをすべて記載するとこんな感じです。論文では重みの初期値など工夫しているようですが、今回は試してません。
from keras.layers import Input, LSTM, Dense, Embedding, Activation, Dropout
from keras.models import Model
def dual_lstm(dim_input, timesteps, dim_h, dim_emb):
"""Dual LSTMのネットワーク
dim_input: int 入力次元(ボキャブラの数)
timesteps: int シーケンスの長さ
dim_h: LSTM(隠れ層)のユニット数
dim_emb: Embedding層の次元数
returns keras model
"""
# 発話と応答の入力層
input_c = Input(shape=(timesteps,))
input_r = Input(shape=(timesteps,))
# 共有用の層の準備
shared_emb = Embedding(input_dim=dim_input, output_dim=dim_emb)
shared_lstm = LSTM(units=dim_h)
# Embedding層の追加
word_vec_c = shared_emb(input_c)
wrod_vec_r = shared_emb(input_r)
# LSTM層の追加
h_c = shared_lstm(word_vec_c)
h_r = shared_lstm(wrod_vec_r)
# 行列Mの部分
x = Dense(dim_h)(h_c)
h_c_M = Dropout(0.5)(x)
# 内積を取って類似度算出
dot_vector = keras.layers.dot([h_c_M, h_r], axes=-1)
predictions = Activation(activation='sigmoid')(dot_vector)
# 入力が2つのモデル
model = Model(inputs=[input_c, input_r], outputs=predictions)
# {0, 1}を当てるのでcrossentropy。optimizerは適当
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
モデルのネットワーク図はこんな感じになりました。論文などよりパラメータを大幅に少なくしています。
データセット
早速構築したネットワークに(面白い)お手本の発話応答データを突っ込もうと思ったのですが、Webを探しても、データセットがない!!そうかー。でもデータ量としては数万程度のペアは欲しいところです。
論文では、Ubuntu Dialog Copusというコーパスを利用しています。これには100万件近くの英語の会話文があるみたいです。私は日本語圏の人にもモテたいし、そもそもUbuntu Dialogコーパスは技術寄りのサポート対話ぽいので、これを使っても、一部の女子にしかモテない可能性が高く、不特定多数にモテたいので意図と反します。。。
1.モテるための例文集(断念)
これが手に入れば一番良い。。。検索したが、厳しい。。。断念(通勤電車の中でスマホで「モテる 会話 例文集」とか検索してたので、周りの視線が怖かった)
2.漫才の台本書き起こし(断念)
一部2chや趣味でWebに掲載されている方がいて、これをスクレイプして使わせて頂こうと思ったのですが、1サイトだけではまとまった数がなく、とりあえず2chだけからデータを作成してみたのですが学習が進まず。。。ちなみに一応2chからだけでも数千件会話は取得できました。データがまとまってないとサイトごとにパースが必要だったりと、はやりかなり厳しいですね。。。でもいつかはやってみたい。
3.普通の会話データセット
ここまできて、とりあえずなんでも良いから日本語の会話コーパスが欲しいと思って調べたら。名大会話コーパスを良い感じで取得してくれるseq2seqで利用可能な日本語対話データセットをダウンロードするツールという記事があるじゃないですか!!? そのスクリプトを使わせて頂きました。ありがとうございます!今回は、まずモテ会話より前に、普通の会話を出来るようになろうと思います。
前処理など
基本的に前処理などは、ほとんどやっていません。手が回りませんでした。。。というのもありますし、会話のコーパスが結構キレイだったため、もう良いかなと思って後回しにしました。
まず、ツールが吐き出してくれるのは、下のようなフォーマットでした。Inputが発話で、Outputが応答ということでしょう。これを整形してモデルに入力できるようにします。
input: そうよね、そうよね。
output: それでさ、例えばさ、1000円の(うん)ごはんと(うん)1300円のごはんがあって、(うんうん)で1000円はどう見ても観光む、観光客向けって(うん)いう感じで、(うん)味はいまいちそうで。
output: F050さんは、今日何時間あったの?
input: そう、だけどだいじょうぶじゃないかな。
名大コーパスから引用
藤村逸子・大曽美恵子・大島ディヴィッド義和、2011
「会話コーパスの構築によるコミュニケーション研究」
藤村逸子、滝沢直宏編『言語研究の技法:データの収集と分析』p. 43-72、ひつじ書房
実施した前処理の概要は以下です。
-
input、outputの文書を抽出・整形 - 簡単な正規化(大文字小文字とか)や一部記号や会話以外の情報(不用語)の除去
- 短い文章や対がないものの除去
- IPADICによる分かち書き
- カテゴリカル変数化(Embedding層に入力するため)
- シーケンスのPadding
- 学習・テストデータへの分割
論文ではTF-IDFを行っていましたが、やっておりません。シーケンスの入力順序もそのままです。
整形後の学習・検証用データ
最終的に学習用データ約55,000件(Context、Responseそれぞれ)、テストデータ約13,000件
になりました。モデルに入力する学習データはこんな感じです。
# 学習データ 発話
X_c_train[:3]
>>>
array([[13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984,
13984, 13984, 13984, 1552, 3258, 2292, 119, 1552, 3258,
2292, 120],
[13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984,
13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984,
13984, 13984],
[13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984,
13984, 13984, 1552, 119, 1727, 1719, 1407, 2157, 711,
2153, 120]], dtype=int32)
# 学習データ 応答
X_r_train[:3]
>>>
array([[13984, 13984, 1601, 1207, 119, 6890, 1207, 119, 13767,
13765, 13765, 13765, 7121, 2307, 7823, 2337, 372, 1552,
1989, 120],
[13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 110,
37, 1266, 2337, 119, 6626, 6816, 9855, 187, 1626,
2307, 13797],
[13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984, 13984,
13984, 13984, 13984, 6605, 1620, 9068, 2337, 8849, 2157,
3258, 120]], dtype=int32)
# 学習データ ラベル
y_train[:3]
>>>
array([1, 1, 0])
モデルの学習
コードの全体は記載しませんが、以下のような流れで学習してみました。
# データを整形・前処理して取得(ボキャブラリとかも出力)
X_c, X_r, y, voc, voc_freq = get_data_sample()
# 学習・テストに分割
X_c_train, X_r_train, y_train,\
X_c_test, X_r_test, y_test, idx_train, idx_test =\
split_train_test_pair(X_c, X_r, y)
# 分割数の確認
assert(X_c_train.shape[0] + X_c_test.shape[0] == X_c.shape[0])
assert(idx_train.shape[0] + idx_test.shape[0] == X_c.shape[0])
# モデルの構築
# dim_inputは未知語とPadding用に2つ余計につかいました
dim_input = voc.shape[0] + 2
model = get_model(dim_input=dim_input,
timesteps=20, dim_h=16, dim_emb=32)
# モデルのサマリ確認
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
# 学習
hist = model.fit([X_c_train, X_r_train], y_train, epochs=100,
validation_split=0.2, verbose=0, batch_size=500)
結果
学習は回り始めたのですが、結局今回結果を詳しく検証できていません。精度は出ているみたいですが、ちょと当たりすぎてて挙動が怪しいです。
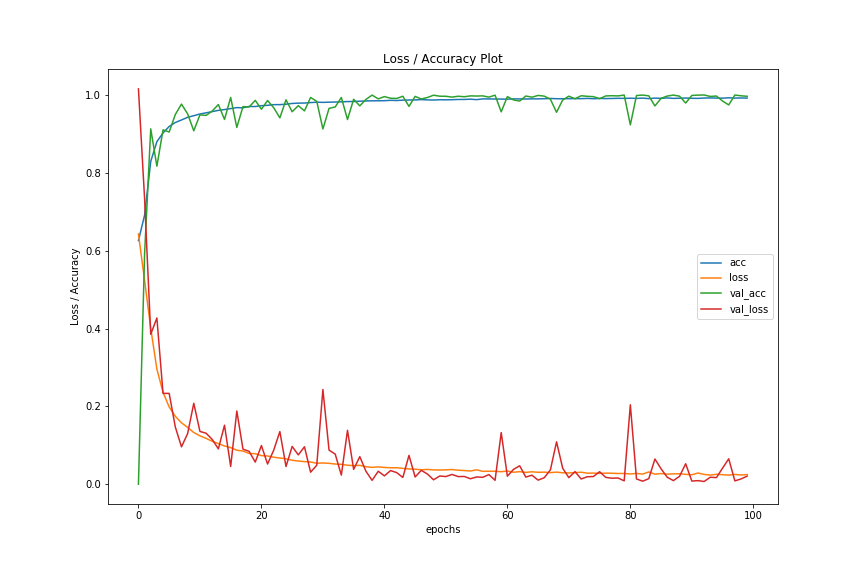
内容をざっと見る限り、誤判別しているものは、コーパスの中にある、発話と応答の順番が逆になっているものみたいで(整形ミスの可能性も高いです)、正解データはそれを「正しい」としているため間違ってしまうというものです。それが結構目立っていました。そういう意味ではうまく学習できているのかもしれません。
活用部分
一番重要な、モテへの活用の部分ですが、残念ながら、活用に向けたテ検証はできませんでした。本当は「女子:メリークリスマス」と入力して、どういう候補が選ばれるか見たかったがタイムアウト。。。今後の検証が必要です。また、活用という意味では、大事な事を忘れていたのですが、コレを使おうと思ったら、事前に応答の候補文が必要なのです。。。モテ会話の模範解答集が必要です。やはりモテ会話に向けた取り組みにはまだまだ手間かかりそうです。
次は生成モデルと、比較してみたいなと思います。
【結論】モテるために必要なこと
今回の検証から女子からモテるためには以下のことが必要だという事が分かりました。
- モテる会話例文データセット(非モテもあると良い)
- 自然言語処理の知識・能力
- 妥当な前処理など
- あと自然言語処理には時間が必要
- もっと最新の手法でアプローチするとモテるかもしれない
- モテ例文の生成モデル
来年のクリスマスまでまだ一年あるので精進したいと思います。
メリー・クリスマス!!