はじめに
本記事では、Ollamaを使用してLlama3.1モデルを実行し、RTX 3060程度のGPUでの使用感を紹介します。
インストール方法(Linux環境)
Ollamaは以下のコマンドで簡単にインストールできます:
curl -fsSL https://ollama.com/install.sh | sh
詳細はOllamaのGitHubをご覧ください。
基本的な使用方法
インストール後、以下のコマンドでモデルを実行します:
ollama run モデル名
初回実行時、モデルが自動的にダウンロードされます。
利用可能なモデルとサイズ比較
- llama3.1 8b: 4.8GB
- llama3.1:8b-instruct-fp16: 16GB
トラブルシューティング
エラー(Could not connect to ollama app, is it runnning?)が発生した場合は、以下の手順を試してください:
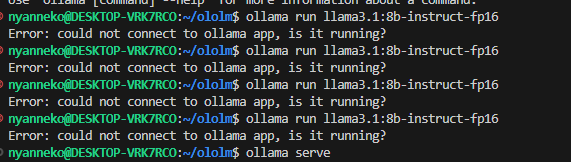
- 新しいターミナルで
ollama serveを実行 - 別のタブでモデル実行コマンドを入力
パフォーマンス比較(RTX 3060使用時)
- llama3.1 8b: 即時応答
- llama3.1:8b-instruct-fp16: 応答開始まで約10秒
RTX 3060クラスのGPUでは、処理速度の観点からllama3.1 8bの使用がいいと思います。
高速なInstructモデルを使いたい場合
ollama run llama3.1:8b-instruct-q3_K_S
このモデルは3.7GBで、即時応答が可能でした。
まとめ
- RTX 3060程度のGPUでは、llama3.1 8bが適切でした。
- Instructモデルが必要な場合は、量子化版(q3_K_S)の使用をおすすめします。