pythonのお勉強に気になっていたWebスクレイピングなるものをやってみました。
参考記事と最終的にやること
下記記事を参考に進めます。
Python Webスクレイピング 実践入門
最終的に日経新聞サイトの為替・金利ページから円相場と前日比、ユーロ~豪ドルまでの円相場と前日比を取得してみようと思います。
実行環境はpython3.7です。
まずは記事通りに
まずは記事通り日経平均株価の取得を行ってみます。
import urllib.request
from bs4 import BeautifulSoup
# 日経新聞の株価のページへアクセスしてhtml取得
url = 'https://www.nikkei.com/markets/kabu/'
html = urllib.request.urlopen(url)
# htmlからspan要素を取得
soup = BeautifulSoup(html, 'html.parser')
span_tags = soup.find_all('span')
nikkei_stock_average = ''
for span in span_tags:
try:
class_name = span.get('class').pop(0)
# 日経平均株価が入ってるclass「mkc-stock_prices」が含まれていれば中身を取得
if class_name in 'mkc-stock_prices':
nikkei_stock_average = span.string
break
except AttributeError:
pass
# 表示
print(nikkei_stock_average)
21,904.17
おお、取得できた。
本題の円相場の取得
一気に全部やろうとすると絶対に失敗してわけわからなくなるので、とりあえず一つずつこなしていきます。
とりあえず株価と同じようにできそうな円相場(ドル)部分からやっていきます。
円相場(ドル)の取得
株価と違い、spanではなくdivとなっていました。
classは同じように「mkc-stock_prices」、前日比は「cmn-plus」のようです。
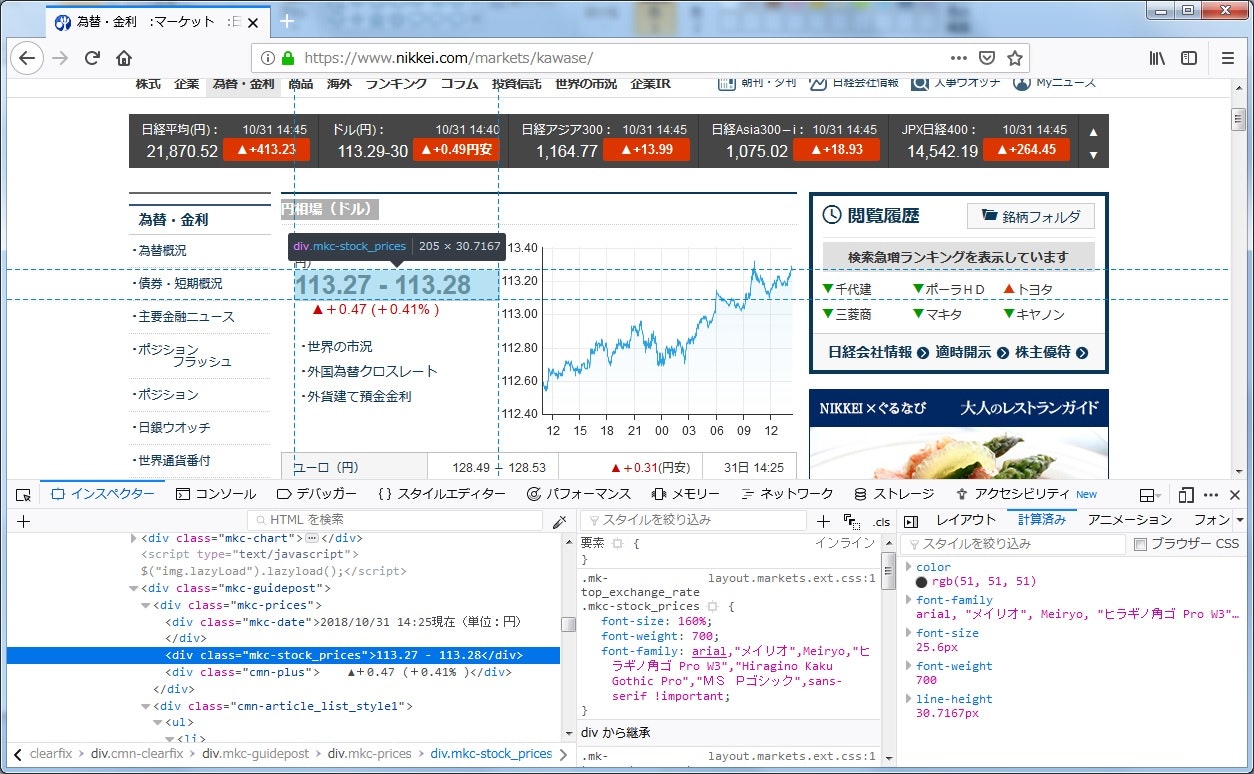
今回は円相場のみでなく前日比も取得するので、2つの親要素のclassである「mkc-prices」の要素をまず探し、その中から対象のものを抜き出そうと思います。
import urllib.request
from bs4 import BeautifulSoup
# class名取得する
def get_class_name(tag):
class_name = ''
try:
class_name = tag.get('class').pop(0)
except AttributeError:
pass
except IndexError:
pass
return class_name
# 日経新聞の為替・金利のページへアクセスしてhtml取得
url = 'https://www.nikkei.com/markets/kawase/'
html = urllib.request.urlopen(url)
# htmlからdiv要素を取得
soup = BeautifulSoup(html, 'html.parser')
divs = soup.find_all('div')
yen_exchange_rate = ''
yen_exchange_rate_between_yen = ''
for div in divs:
class_name = get_class_name(div)
if class_name == '':
continue
# 親要素のclass「mkc-prices」かどうか
if class_name in 'mkc-prices':
for target_div in div.find_all('div'):
class_name = get_class_name(target_div)
# 円相場(ドル)
if class_name in 'mkc-stock_prices':
yen_exchange_rate = target_div.string
# 前日比
elif class_name in 'cmn-plus':
yen_exchange_rate_between_yen = target_div.string
break
# 表示
print(yen_exchange_rate)
print(yen_exchange_rate_between_yen)
113.16 - 113.17
▲+0.36 (+0.31% )
とりあえず取り出せました。
ユーロ~豪ドルの取得
では次にユーロなどテーブルになっているところの値を取得しようと思います。
ページを確認していきます。
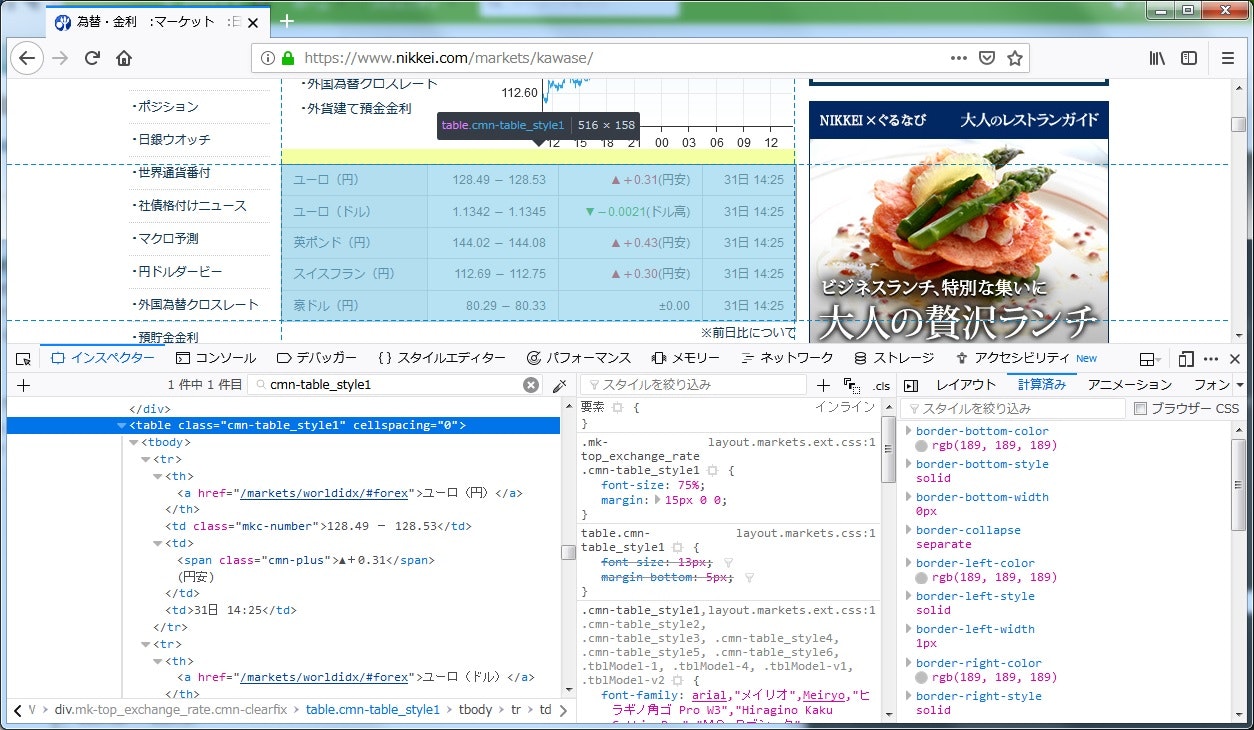
「cmn-table_style1」というクラスのtableの中にあるようです。
どの通貨かわかるようにユーロなどの名前も取得していきます。
見た感じtr毎のaタグ、「mkc-number」というクラスのtd、「cmn-plus」または「cmn-minus」というクラスのspanを取得できれば行けそうです。
ドルの取得部分も変えつつやってみます。
import urllib.request
from bs4 import BeautifulSoup
# 日経新聞の為替・金利のページへアクセスしてhtml取得
url = 'https://www.nikkei.com/markets/kawase/'
html = urllib.request.urlopen(url)
# 各相場のリスト
yen_exchange_rate_list = {}
soup = BeautifulSoup(html, 'html.parser')
# 円相場(ドル)部分
divs = soup.find('div', class_='mkc-prices')
# 通貨名
currency_name = 'ドル'
# 円相場
yen_exchange_rate = divs.find('div', class_='mkc-stock_prices').text
# 前日比
# クラス名が「cmn-minus」「cmn-plus」どちらかのため、
# 「cmn-minus」が見つからなければ「cmn-plus」の値を取得
day_before_rate_div = divs.find('div', class_='cmn-minus')
if day_before_rate_div is None:
day_before_rate = divs.find('div', class_='cmn-plus').text
else:
day_before_rate = day_before_rate_div.text
# 円相場(ドル)部分の円相場と前日比を格納
yen_exchange_rate_list[currency_name] = [
yen_exchange_rate,
day_before_rate
]
# ユーロ~豪ドルのテーブル部分
table = soup.find('table', class_='cmn-table_style1')
table_rows = table.find_all('tr')
for row in table_rows:
# 通貨名
currency_name = row.find('a').text
# 円相場
yen_exchange_rate = row.find('td', class_='mkc-number').text
# 前日比
# クラス名が「cmn-minus」「cmn-plus」どちらかのため、
# 「cmn-minus」が見つからなければ「cmn-plus」の値を取得
day_before_rate_row = row.find('span', class_='cmn-minus')
if day_before_rate_row is None:
day_before_rate = row.find('span', class_='cmn-plus').text
else:
day_before_rate = day_before_rate_row.text
# ユーロ~豪ドルのテーブル部分の通貨名、円相場、前日比を格納
yen_exchange_rate_list[currency_name] = [
yen_exchange_rate,
day_before_rate
]
# 表示
for dic in yen_exchange_rate_list.items():
print(dic)
('ドル', ['112.76\xa0-\xa0112.77', '\xa0\xa0\xa0\xa0▼-0.43\xa0(-0.37%\xa0)'])
('ユーロ(円)', ['\r\n 127.64\xa0-\xa0127.69', '▼-0.79'])
('ユーロ(ドル)', ['\r\n 1.1320\xa0-\xa01.1323', '▼-0.0026'])
('英ポンド(円)', ['\r\n 144.44\xa0-\xa0144.50', '▲+0.26'])
('スイスフラン(円)', ['\r\n 111.87\xa0-\xa0111.93', '▼-0.10'])
('豪ドル(円)', ['\r\n 79.90\xa0-\xa079.94', '▲+0.06'])
取得はできたみたいですが何か色々入ってる…
余分な文字列の削除
「\r\n」とスペースはいいとして、「\xa0」ってお前誰だよとなったのでググってみました。
どうやら「&nbsp」の数字文字参照みたいですね。知らなかった。(何年やってきてるんだよと…)
まぁ消し去ることに変わりはないので消していきます。
import urllib.request
from bs4 import BeautifulSoup
# 余分な文字列の削除
def replace_str(s):
s = s.replace('\r\n', '')
s = s.replace(' ', '')
s = s.replace(u'\xa0', '')
return s
# 日経新聞の為替・金利のページへアクセスしてhtml取得
url = 'https://www.nikkei.com/markets/kawase/'
html = urllib.request.urlopen(url)
# 各相場のリスト
yen_exchange_rate_list = {}
soup = BeautifulSoup(html, 'html.parser')
# 円相場(ドル)部分
divs = soup.find('div', class_='mkc-prices')
# 通貨名
currency_name = 'ドル'
# 円相場
yen_exchange_rate = divs.find('div', class_='mkc-stock_prices').text
# 前日比
day_before_rate_div = divs.find('div', class_='cmn-minus')
if day_before_rate_div is None:
day_before_rate = divs.find('div', class_='cmn-plus').text
else:
day_before_rate = day_before_rate_div.text
# 円相場(ドル)部分の円相場と前日比を格納
yen_exchange_rate_list[currency_name] = [
replace_str(yen_exchange_rate),
replace_str(day_before_rate)
]
# ユーロ~豪ドルのテーブル部分
table = soup.find('table', class_='cmn-table_style1')
table_rows = table.find_all('tr')
for row in table_rows:
# 通貨名
currency_name = row.find('a').text
# 円相場
yen_exchange_rate = row.find('td', class_='mkc-number').text
# 前日比
# クラス名が「cmn-minus」「cmn-plus」どちらかのため、
# 「cmn-minus」が見つからなければ「cmn-plus」の値を取得
day_before_rate_row = row.find('span', class_='cmn-minus')
if day_before_rate_row is None:
day_before_rate = row.find('span', class_='cmn-plus').text
else:
day_before_rate = day_before_rate_row.text
# ユーロ~豪ドルのテーブル部分の通貨名、円相場、前日比を格納
yen_exchange_rate_list[currency_name] = [
replace_str(yen_exchange_rate),
replace_str(day_before_rate)
]
# 表示
for dic in yen_exchange_rate_list.items():
print(dic)
('ドル', ['112.83-112.84', '▼-0.36(-0.31%)'])
('ユーロ(円)', ['127.88-127.92', '▼-0.55'])
('ユーロ(ドル)', ['1.1334-1.1337', '▼-0.0012'])
('英ポンド(円)', ['144.95-145.01', '▲+0.77'])
('スイスフラン(円)', ['112.01-112.07', '▲+0.04'])
('豪ドル(円)', ['80.26-80.30', '▲+0.42'])
何とか綺麗になりました。
CSV出力とかはまた後日にやろうと思います。