サポートベクトルマシーンについて改めて理解する
サポートベクトルマシーンは
軽量なアルゴリズムとして、
用いられて居ます。
まずは、サポートベクトルマシンはそもそも
どの様にして生まれたのか、
用いる上での注意点は
どのあたりにあるのかについて、纏めたいと思います。
(あくまで、本記事は著者本人の理解であり、もしかしたら理解が間違っている
かも知れません。)
サポートベクトルマシンの特長
(1)ソフトマージンの考え方を用いることによって、
トレーニングデータセットのエラーを許容したこと。
ただし、下記の状態が存在していることが前提
Pr(test error) < Frequency(training error) + Confidence Interval
つまり、テストデータの質が悪い(負例の割合が多い)場合には、
役に立たない。
(2)訓練データの件数が少ない場合には有効
大まかには数百件程度のデータ数でも有効
(ランダムフォレスト系は1000件程度以上、NNは一般的には2万件以上)
(3)元々は2クラス(1VSその他)分類問題を解くために生み出された。
2クラス分類問題器を複数個用いることで多クラス分類問題を解く事になるが
多クラス分類問題を解く決定的な方法は存在しない(かも知れない)。
次に、サポートベクターマシンを使って
[iris データセット]
https://github.com/pandas-dev/pandas/blob/master/pandas/tests/data/iris.csv
ひとまずは、綺麗なiris データセットを扱ってみる。
まずは、線形関数を用いて
Iris setosa
Iris versicolor
Iris virginica
を分類してみる。
svm = SVC(kernel='linear', C=1.0, random_state=1)
svm.fit(X_train_std, y_train)
y_combined = np.hstack((y_train,y_test))
X_combined_std = np.vstack((X_train_std,X_test_std))
plot_decision_regions(X_combined_std, y_combined, clf=svm)
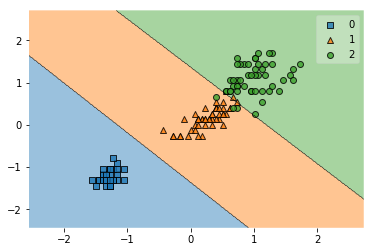
Iris setosa 0
Iris versicolor 1
Iris virginica 2
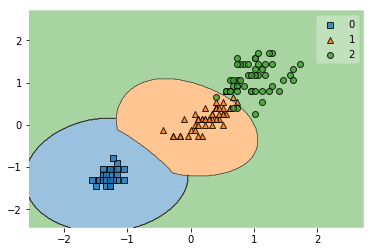
次に関数を線形関数からガウスカーネルSVMにかえてみよう
svm = SVC(kernel='rbf', C=1.0, random_state=1, gamma=1.0)
svm.fit(X_train_std, y_train)
y_combined = np.hstack((y_train,y_test))
X_combined_std = np.vstack((X_train_std,X_test_std))
plot_decision_regions(X_combined_std, y_combined, clf=svm)
この数式は
\ k(x,y) = \phi(x)^i\phi(y)^j
ガウスカーネルSVMを用いて分類を行う場合には
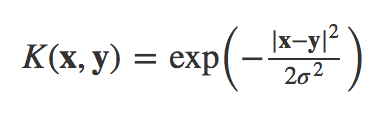
\gamma = \frac{1}{2\sigma^2}
を用いて上記数式を置き換えると
\ k(x,y) = exp(\gamma||x^i - x^j||^2)
となり、r を最適化する事が重要だとわかる
無限個の ϕ1(x),ϕ2(x),⋯ を用いて、K(x,y) が構成さているが、無限個のϕには
無限の特徴が含まれているのでγの値を決めて仕舞えば、最適化が出来る事になる
上記の例では
γの値を100に変更してみた。
svm = SVC(kernel='rbf', C=1.0, random_state=1, gamma=100.0)
svm.fit(X_train_std, y_train)
y_combined = np.hstack((y_train,y_test))
X_combined_std = np.vstack((X_train_std,X_test_std))
plot_decision_regions(X_combined_std, y_combined, clf=svm)
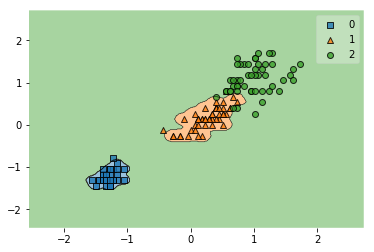
すると、適切に分類できることがわかる。
ただし、そもそもγの値をどの様に決めれば良いのかという問題が残る
そこで、グリッドサーチを用いて、最適なγの値を探してみる事にしたい。
param_grid = [
{'gamma': [120.0, 110.0, 100.0, 90.0, 80.0, 70.0, 60.0, 50.0, 40.0, 20.0, 1.0], 'kernel': ['rbf']},
]
scores = ['accuracy', 'precision', 'recall']
for score in scores:
clf = GridSearchCV(SVC(C=1), param_grid, cv=5, scoring=score, n_jobs=-1)
clf.fit(X_train, y_train)
for params, mean_score, all_scores in clf.grid_scores_:
print( mean_score / 2 * 100 , params)
結果
42.38095238095238 {'gamma': 120.0, 'kernel': 'rbf'}
42.38095238095238 {'gamma': 110.0, 'kernel': 'rbf'}
42.38095238095238 {'gamma': 100.0, 'kernel': 'rbf'}
42.857142857142854 {'gamma': 90.0, 'kernel': 'rbf'}
42.857142857142854 {'gamma': 80.0, 'kernel': 'rbf'}
42.857142857142854 {'gamma': 70.0, 'kernel': 'rbf'}
42.857142857142854 {'gamma': 60.0, 'kernel': 'rbf'}
43.333333333333336 {'gamma': 50.0, 'kernel': 'rbf'}
44.761904761904766 {'gamma': 40.0, 'kernel': 'rbf'}
47.61904761904761 {'gamma': 20.0, 'kernel': 'rbf'}
47.61904761904761 {'gamma': 1.0, 'kernel': 'rbf'}
カーネルがrbf の中では
結果としてスコアが高いのがγの値が90.0 であることがわかる
これにより、パラメータが90.0の時に最適化される事がわかる。
グリッドサーチによってハイパーパラメータを最適化してみた。
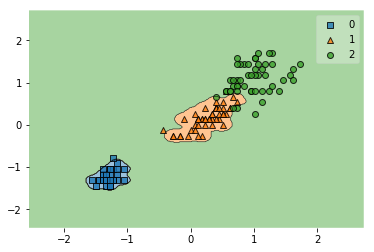
[gammna=90の場合]
svm = SVC(kernel='rbf', C=1.0, random_state=1, gamma=90.0)
svm.fit(X_train_std, y_train)
y_combined = np.hstack((y_train,y_test))
X_combined_std = np.vstack((X_train_std,X_test_std))
plot_decision_regions(X_combined_std, y_combined, clf=svm)
<参考>
https://link.springer.com/content/pdf/10.1007/BF00994018.pdf