はじめに
アルゴリズムとデータ構造に興味が出て少し学んでみたので、
学習成果というか、学んだことを復習するついでにまとめてみた。
これからアルゴリズムを学ぶ人とか、アルゴリズムの課題を解く人とかに参考になれば幸い。
二分探索木ってなんぞ?
まず、ノードとエッジで表現される二股に分かれる木構造のデータ構造を二分木という。
図においては以下のように示される。

※線の部分がエッジにあたる。
このうち、二分探索木とは「左の子ノードの値 ≤ 親ノードの値 ≤ 右の子コードの値」という制約を持つ二分木のことである。具体的に言うと、2、1、3という順番で数値が渡された時には、以下の図のように格納される二分木のことである。

この構造にデータを代入することで、ある一定の手順で1,2,3とソートされたデータを取得する処理を実現できる。例えば、上の図の構造から1→2→3の順番でデータを取り出せば下から順にソートされたデータが得られる。
これはアルゴリズムで処理しやすいデータ構造とも言える。実際、複雑なアルゴリズムを利用することで、少ない計算量で二分探索木の構造に入ったデータを高速に検索し、取り出す処理も実現できるため、高速な処理が必要なデータベースなどに構造として採用されることも多い。
詳しく知りたい方は、wikipediaの”木構造(データ構造)”を参照。
https://ja.wikipedia.org/wiki/%E6%9C%A8%E6%A7%8B%E9%80%A0_(%E3%83%87%E3%83%BC%E3%82%BF%E6%A7%8B%E9%80%A0)
また、北海道大学情報知識ネットワーク研究室、アルゴリズムとデータ構造の講義資料で丁寧に解説されているので、これを参考にすると良いかもしれない。
http://www-ikn.ist.hokudai.ac.jp/~arim/pub/algo/
プログラムで表現するためには?
必要なのは
1.二分探索木におけるノードの構造を表現すること。
2.二分探索木の構造や処理を表現すること。
以上の2つである。
ということで、ノードクラスと二分探索木クラスを
それぞれ作り、Pythonで実装していくこととする。
ノードクラスの定義
まずはノードクラスを作る。
エッジについては、ここでは内容は考えずとりあえず空の構造を用意する。
ただし、ノードは「左の子ノードの値 ≤ 親ノードの値 ≤ 右の子コードの値」
という制約を持つことになるので、ノードのエッジは少なくとも左と右で区別しなければならない。
よって、以下のように示される。
# ノードクラスの定義
class Node:
def __init__(self, data): #コンストラクタ
self.data = data #ノードがもつ数値
self.left = None #左エッジ
self.right = None #右エッジ
これで
ノード
左エッジ/ \右エッジ
の表現ができる。
二分木探索木クラスの定義
先ほど作ったNodeクラスを二分木にするためには、
pythonにおいてはエッジ部分に対象のNodeクラスを代入する形にすればよい。
先程の2,1、3の数列の例でNodeクラスの中身を具体的に書くと
# Node(2)の中身
self.data = 2 #ノードがもつ数値
self.left = Node(1) #左エッジ
self.right = Node(3) #右エッジ
こんな感じにすれば、二分探索木が表現できる。
(余談だが、C言語で書く場合はこれはクラスのポインタで表現できる)
これを元に二分探索木のクラスのコンストラクタを考えていく。
なお、二分探索木が入るものをroot(根、二分木における一番上のノードの意)とし、
とりあえず空の構造を用意しておく。
class BST:
def __init__(self, number_list): #コンストラクタ
self.root = None #ルート初期化
for node in number_list: #数値を持つ配列から二分木を生成
self.insert(node) #挿入メソッドを使ってノードを挿入する
今回は、コンストラクタ部分に挿入の処理を書いた。
また、入力に数字を持つ配列を想定した。
挿入(insert)メソッドについては、次の項で書く。
挿入メソッドの実装(BSTクラス内)
先程の具体例に則って作っていく。
まずself.rootは空なので、最初にNode(data)を入れる。
その後に、if処理でleft,rightにNode(data)をそれぞれ入れていく。
以下のような感じになる。
詳細は、コードとコメントアウトを読んで理解して欲しい。
#挿入
def insert(self, data):
n = self.root #nにルートを代入
if n == None: #ルートに何も入っていない場合
self.root = Node(data) #ルートにノードを代入(二分探索木の一番上の部分が出来る)
return #呼び出し部分に戻る
else: #ルートノードに既に数値が入ってる場合
while True: #return等が入るまでずっと実行
entry = n.data #entryにnが持つデータ(数値)を入れる
if data < entry: #entryとdata(代入するデータ)を比較してentryの方が大きい場合
if n.left is None: #nの左エッジに何も入っていない場合
n.left = Node(data) #nの左エッジにdata(代入するデータ)を代入
return ##呼び出し部分に戻る
n = n.left #nの左に何か入っている場合nにnのleftを代入
elif data > entry: #entryとdata(代入するデータ)を比較してentryの方が小さい場合
if n.right is None: #nの右エッジに何も入っていない場合
n.right = Node(data) #nの右エッジにdata(代入するデータ)を代入
return #呼び出し部分に戻る
n = n.right #nの右エッジに何か入っている場合nにnのrightを代入
else: #上2つの条件分岐以外の場合
n.data = data #nのdataにdata(代入するデータ)を代入
return #呼び出し部分に戻る
検索メソッドの実装(BSTクラス内)
生成された二分探索木に対して検索する機能を作る。
True,False,Noneの3つの出力を返すメソッドを考えた。
また、それを利用したインターフェースを作った。
#検索機能(インターフェース)
def search(self, search):
searcher = self._search_bool(search)
if searcher is None:
print("Search target is not found.")
elif searcher == True:
print(str(search) + " is found!")
elif searcher == False:
print(str(search) + " is not found.")
#検索機能本体(出力:boolean),深さ優先探索
#nodeのvisitedはpopで代用
def _search_bool(self, search):
n = self.root
if n is None:
return None
else:
lst = []
lst.append(n)
while len(lst) > 0:
node = lst.pop()
if node.data == search:
return True
if node.right is not None:
lst.append(node.right)
if node.left is not None:
lst.append(node.left)
return False
おまけ:中間順探索メソッド(BSTクラス内)
二分探索木の説明で書いた最小値から最大値までをソートで出力するアルゴリズム。
再帰的に実装できる。
メソッドは以下のようになる。
#中間順探索
def inorder(self,node):
if node is not None:
self.inorder(node.left)
print(node.data)
self.inorder(node.right)
まとめ
# !/usr/bin/python
# coding: UTF-8
# import
import random #入力整数列Aの生成に使用
class Node:
def __init__(self, data): #コンストラクタ
self.data = data #ノードがもつ数値
self.left = None #左エッジ
self.right = None #右エッジ
class BST:
def __init__(self, number_list): #コンストラクタ
self.root = None #ルートノード初期化
for node in number_list: #数値を持つ配列から二分木を生成
self.insert(node) #挿入メソッドを使ってノードを挿入する
#挿入
def insert(self, data):
n = self.root
if n == None:
self.root = Node(data)
return
else:
while True:
entry = n.data
if data < entry:
if n.left is None:
n.left = Node(data)
return
n = n.left
elif data > entry:
if n.right is None:
n.right = Node(data)
return
n = n.right
else:
n.data = data
return
#検索機能(インターフェース)
def search(self, search):
searcher = self._search_bool(search)
if searcher is None:
print("Search target is not found.")
elif searcher == True:
print(str(search) + " is found!")
elif searcher == False:
print(str(search) + " is not found.")
#検索機能本体(出力:boolean),深さ優先探索
#nodeのvisitedはpopで代用
def _search_bool(self, search):
n = self.root
if n is None:
return None
else:
lst = []
lst.append(n)
while len(lst) > 0:
node = lst.pop()
if node.data == search:
return True
if node.right is not None:
lst.append(node.right)
if node.left is not None:
lst.append(node.left)
return False
def inorder(self,node): #中順探索 l->r->p^n
if node is not None:
self.inorder(node.left)
print(node.data)
self.inorder(node.right)
テストコードはこんな感じ
# 整数列Aの生成---------------------------------------------
# ランダム整数列Aの生成
iarray_A = list(range(50))
random.shuffle(iarray_A)
print(iarray_A)
# ---------------------------------------------------------
# テスト----------------------------------------------------
tree = BST(iarray_A) #配列から二分探索木生成し、treeに代入
tree.search(10)#10がtreeに存在するか検索
tree.inorder(tree.root) #中順走査、1~順にソート
# ---------------------------------------------------------
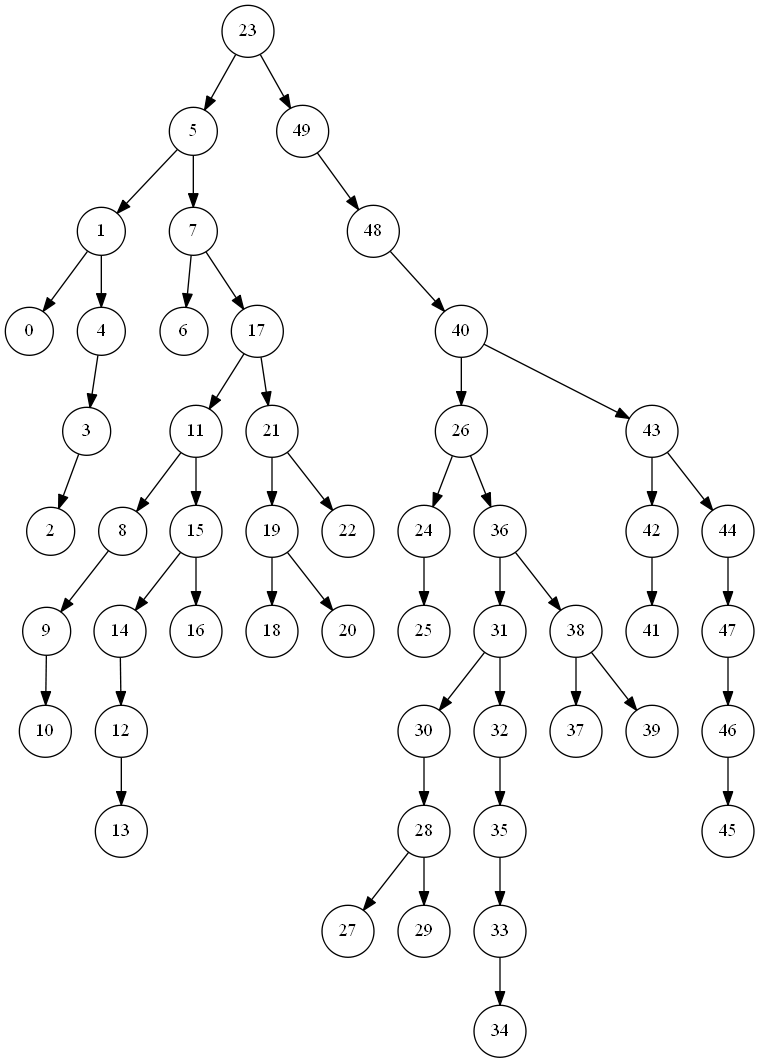
これで出来る二分探索木の一例を可視化すると以下の感じ
最後に
今回は探索には深さ優先探索を用いたが、幅優先探索など他にも色々な探索アルゴリズムがある。今回は考えなかったが、二分探索木の生成においては平衡化(根からの階層の数の出来る限り小さくすること)をしないと処理が多くなり非効率的になるので、この処理がマスター出来たら、その適応についても考えるとよいかもしれない。単純にコードも、よりスマートな書き方があると思われるので、これを読んだ機会に色々と考えてみて欲しい。