本記事は、データ分析初心者の私がよく迷ってしまう、モデル学習時のデータ分割の手法についてまとめます。
Kaggleで磨く機械学習の実践力によると、trainデータを全てモデルの学習に回すのではなく、trainデータの一部を使ってモデル学習、trainデータの残りを使ってモデルで推論してみて、その精度を確かめる。という手法が説明されています。
その際の手法が主に2つ紹介されているので、ここでそれらの違いを簡単にまとめます。
1.ホールドアウト検証法
データ分析初心者向けに紹介されている教材なんかでは、この手法がよく紹介されています。train_test_splitというコードを使います。
x_tr, x_va, y_tr, y_va = train_test_split(x_train,
y_train,
test_size=0.2,
shuffle=True,
stratify=y_train,
random_state=123)
図解するとこんなイメージです!
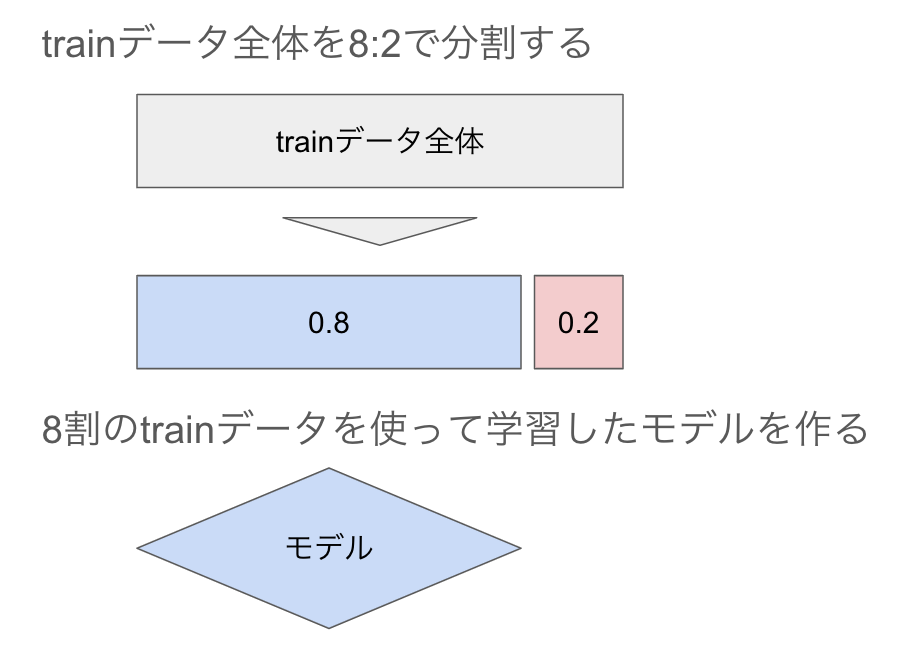
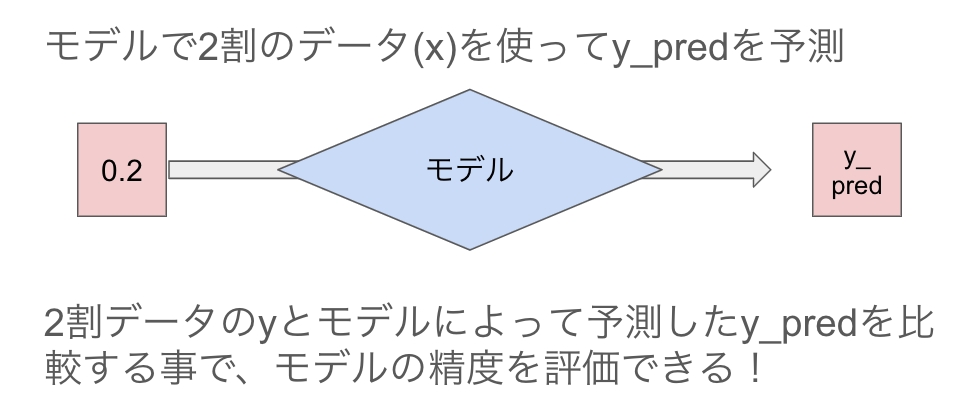
分割した後モデル学習に使わずに2割取っておく事で、正解のyが分かっている状態でモデルを使って予測したy_predとyを比較でき、作ったモデルの性能を評価できるというわけです。
評価できるから、モデルをどんどん改変していき精度改善につなげられます。
2.CV(クロスバリデーション)
ホールドアウト検証法には1つ弱点があります。
それは、分割した2割のデータをモデル学習に使えないという事です。
より精度の高いモデルを作るという観点では、データが揃っている以上モデルの学習使いたいわけです。
そこで、ホールドアウト検証法をベースに、欠点を克服した手法がクロスバリデーションになります。考え方は簡単、ホールドアウト検証法を5回繰り返すというものです。
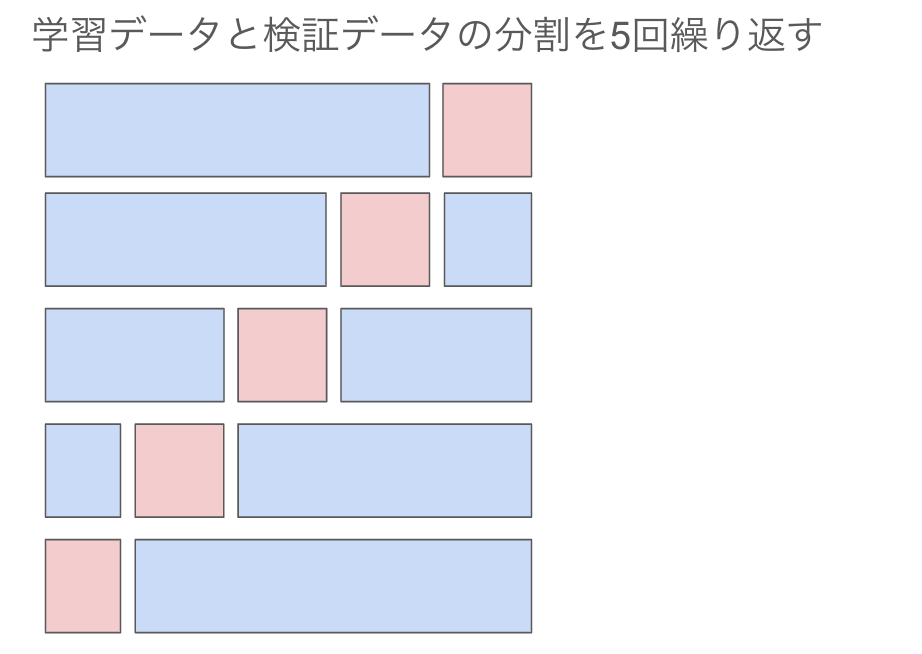
データの分割を行った後、以下の流れを5回繰り返します。
・モデル学習
・モデルを使って検証データのxを使ってy_predを予測
・検証データのyと、予測したy_predの差分を評価した指標(*)を計算する
5回繰り返したら、(*)の平均を取る事で、その値をモデルの評価とします。
かなり省略して説明しましたが、まずはこれくらいを抑えておけば良いです。
ではどのようなルールで分割するのか?
このような疑問を持てたら凄いです。ここでは簡単に紹介して終わりにします。
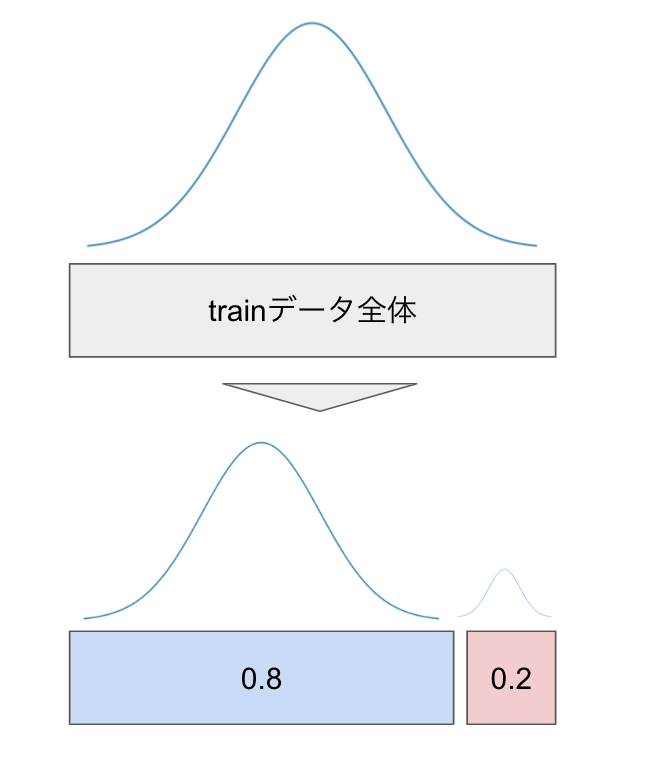
trainデータのyの分布が同じになるように分割
例えば、分割前のtrainデータのy全体の分布が正規分布に従っているとしたら、分割して8:2にする際もそれぞれが正規分布に従うように分割する、という事です。
この辺りは私もまだまだ勉強中なので、もっと知識をつけて行けたらと思います。