Python用クローリング兼スクレイピングフレームワークであるScrapyを使用して、WebページのタイトルとURLを再帰的に取得してcsv形式に出力してみたいと思います。(サイトマップ的なものをリスト化するイメージでしょうか)
※完成イメージ
result.csv
| URL | タイトル |
|---|---|
http://www.example.com |
トップ |
http://www.example.com/news |
ニュース |
http://www.example.com/news/2015 |
2015年のニュース |
| … | … |
環境
- OS:CentOS7 (64bit)
- Pythonバージョン:2.7.5 (CentOS7に標準でインストールされているもの)
- pipバージョン:6.0.8
- Scrapyバージョン:0.24.5
Scrapyの導入
PythonはCentOS7に標準で2.7系がインストールされているので、そちらを使います。
※ちなみに、Scrapyは現在 Python 3系では動きません。(対応は進められています)
以下のコマンドを使用して、pipからScrapyを導入します。
$ sudo pip install Scrapy
プロジェクト作成
以下のコマンドを使用して、Scrapy用のプロジェクトを作成します。
$ scrapy startproject HelloScrapy
作成したプロジェクトの中身は以下の様になっているかと思います。
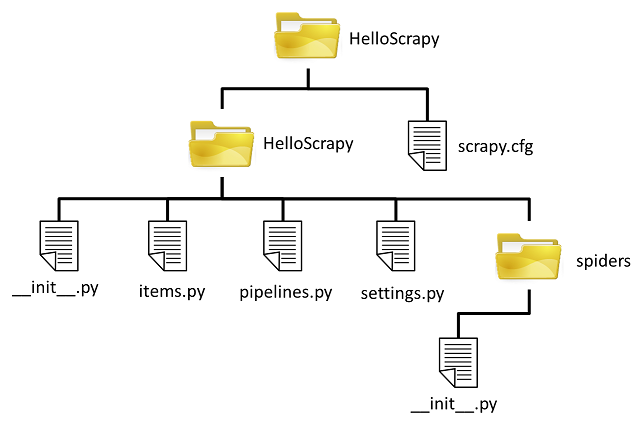
この中で、今回使用するのは以下のファイルです。
- items.py:スクレイプしたデータを保存するためのクラスを定義します。
- settings.py:Scrapyの様々なオプションを指定できます。(指定可能なオプションはScrapyの公式ドキュメント:http://doc.scrapy.org/en/latest/topics/settings.htmlから確認できます)
また、Scrapyは対象のサイトをどのようにクロール、スクレイプするかを定義するためにSpiderと呼ばれるクラスを使用します。
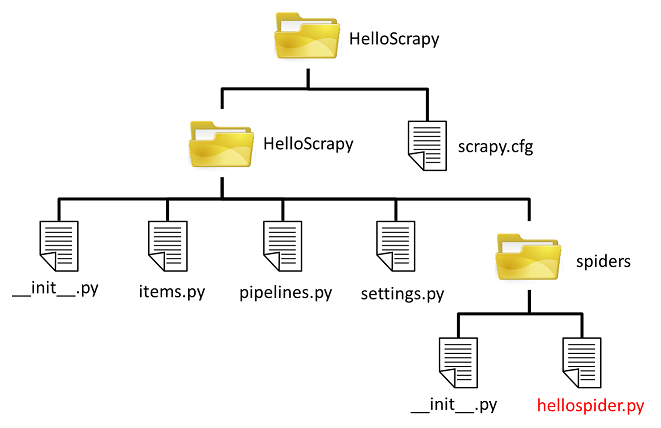
このSpiderを定義するために、先のspidersディレクトリに"hellospider.py"というファイルを作成します。
ここまでで、プロジェクトの構成は以下の様になりました。
items.py
まずはitems.pyを編集していきます。
今回はWebページのタイトルとURLを取得するので、以下の様なクラスを定義します。
from scrapy.item import Item, Field
class PageInfoItem(Item):
URL = Field()
title = Field()
pass
settings.py
続いて、settings.pyを編集していきます。
私は以下のオプションを追加しました。
- DOWNLOAD_DELAY :1つのページをダウンロードしてから、次のページをダウンロードすするまでの間隔(単位:秒)
- ROBOTSTXT_OBEY :robots.txtがある場合は、それに従うかどうか
- DEPTH_LIMIT :再帰的に探査を行う深さ(0は無制限)
DOWNLOAD_DELAY = 3
ROBOTSTXT_OBEY = True
DEPTH_LIMIT = 5
上記の設定の意図は、相手のサーバー負荷をかけないよう3秒程度のクロール間隔を設け、robots.txtに従って探査を行いたかったからです。
(AutoThrottleによる自動調整もできるようなので、詳しく知りたい方は公式ドキュメントを見てください)
また、探査があまり深すぎても時間がかかるので、今回は制限を設けています。
hellospider.py
最後に、本命であるhellospiderに自作のSpiderを定義します。
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.selector import Selector
from HelloScrapy.items import PageInfoItem
class HelloSpider(CrawlSpider):
# scrapyをCLIから実行するときの識別子
name = 'hello'
# spiderに探査を許可するドメイン
allowed_domains = ["www.example.com"]
# 起点(探査を開始する)URL
start_urls = ["http://www.example.com"]
# LinkExtractorの引数で特定のルール(例えばURLにnewを含むページのみスクレイプするなど)を指定可能だが、今回は全てのページを対象とするため引数はなし
# Ruleにマッチしたページをダウンロードすると、callbackに指定した関数が呼ばれる
# followをTrueにすると、再帰的に探査を行う
rules = [Rule(LinkExtractor(), callback='parse_pageinfo', follow=True)]
def parse_pageinfo(self, response):
sel = Selector(response)
item = PageInfoItem()
item['URL'] = response.url
# ページのどの部分をスクレイプするかを指定
# xPath形式での指定に加え、CSS形式での指定も可能
item['title'] = sel.xpath('/html/head/title/text()').extract()
return item
完成です。
実行
後は以下のコマンドを実行すれば、指定した起点URLから再帰的にクロール&スクレイプが実行され、結果がcsvとして出力されます。
$ scrapy crawl hello -o result.csv
(引数はhellospider.pyではなく、その中で定義した識別子であることに注意してください)
ちなみに、結果はjsonやxml形式でも出力可能です。
自作のWebサイトで試してみましたが、完成イメージ通りに出力できているのではないかと思います。
※インターネット上のWebサイトに対して実行する場合は、自己責任でお願いします。
参考:
http://doc.scrapy.org/en/latest/
http://orangain.hatenablog.com/entry/scrapy
http://akiniwa.hatenablog.jp/entry/2013/04/15/001411