こちらの記事はOpenTelemetry Advent Calendar 2023
の19日目のエントリです。
何を書こうか考えたのですが、沢山の方がOpenTelemetryの技術的なノウハウは書いてくださっているので、何故OpenTelemetryが必要なの?という導入の目的について書いてみようと思います。
はじめに
はじめましてラクスというSaaS会社でSREをしています@mekkaと言います。
普段はSREチームのマネジメントをしつつ、各プロダクトチームのモダナイズのお手伝いなどをしています。
私達は現在レガシーなシステムから脱却しシステム、組織のクラウドネイティブ化を進めようとしています。
モノリシックなシステムをマイクロサービス化していく中で、これまでのモニタリングの仕組みもOpenTelemetryへ切り替えようとしています。
「OpenTelemetryサイコーです 明日から切り替えてください。」で導入が進むのであれば楽なのですが、変更コストが掛かりますので、目的はしっかりと説明する必要があります。
まずはObservabilityの重要性を説明し、実現手段としてOpenTelemetryが有用であるという流れで説明するのが納得感があると思います。
OpenTelemetryを導入したいけど皆に理解してもらうにはどうしたらいいだろうか・・・といった悩みを持っている方もいるのではないでしょうか? そういった方に何かしらの情報を提供できれば幸いです。
ObservabilityとOpenTelemetryの関係
OpenTelemetryを語る前にObservabilityについて触れなければいけません。
そもそもObservabilityとは何でしょうか?
「Observabilityとはシステムの内部状態を外部出力から推測できる能力です。」 この様に表現されます。
Observabilityがある状態とはシステムの状態を外部からしっかりと把握出来ていて、何が起きたとしてもその原因が特定出来る状態と言えます。
OpenTelemetryがこの様な状態を作り上げる為の手段(仕組み)となります。
OpenTelemetryの導入を推進するには、関係者に目的(Observabilityのある状態)を理解してもらい、納得してもらうことが重要だと思います。
Observabilityの必要性
社内の勉強会などで「Observabilityがある状態が理想で、そうなっていないと今後の運用に支障をきたしますよ。」と説明すると「モニタリングとか監視は実施しているが何が違うの?」という反応が多いです。
私はモニタリングはリアクティブ、Observabilityはプロアクティブと捉えています。
モニタリングでは事前に必要なデータを定め、収集、ウォッチします。
対象データは過去の経験から決める事になるので、過去に起きた問題に対しては効果的ですが、これまでに経験の無いケースにおいては必要なデータが取得出来ないということになります。
それに対してObservabilityの考え方はシステムの状態を把握するために必要なデータは全て取得する方針になります。
過去に経験が無いような事象が起きたとしても、取得しているデータからその原因を追求出来る様になっているので原因調査に必要なデータが無いということにはなりません。
システムトラブル時に調査に必要なデータが足りず、対象データを追加するといった経験は皆さんもあるかと思います。
この様なケースで事象が再現してくれれば良いですが、そうならなければ原因解明の道筋は閉ざされてしまいます。
社内でこの説明をする際は、実際のトラブル事例を引っ張ってきて説明をしています。
おそらくどこの会社でもこの様な事例は過去にあったのではないでしょうか。
※もしそういったケースが無いとすればそれはとても素晴らしいですし羨ましいことです
マイクロサービスとObservability
Observabilityの必要性についてはマイクロサービスとの関係性も重要なポイントだと考えています。
弊社ではクラウドネイティブ化を進めているとお話しましたが、それに合わせて既存のモノリシックサービスを少しずつ分割してマイクロサービスへ移行しようとしています。
マイクロサービスと言うと、疎結合で開発がし易い、サービス毎にデリバリが出来るといったところに目が行きがちですが、ここでもObservabilityは重要な要素になります。
マイクロサービスの構成を取る場合、コンテナを利用するのが一般的かとは思います。
1つのリクエストを処理するために複数のコンテナを跨いで通信が飛び、メッシュの様な通信経路を構成します。
また、可用性や処理性能のためにコンテナをスケールさせるのが一般的なので、通信経路はさらに複雑な構成となっていきます。
この様な環境ではリクエストがどの通信経路を通って処理されるのかを把握するだけでも困難になり、何も手を打たなければシステムトラブル時の調査には膨大な時間が必要になっててしまいます。
そのためにOpenTelemetryを導入することで、通信経路やトラブル箇所を可視化し、迅速な対応が出来る状態を構築する必要があります。
CI/CDパイプランの整備など、機能開発からデリバリの話はマイクロサービスを検討する際に話題に上がりやすいですがObservabilityは忘れられがちです。
Observabilityもマイクロサービスを実現する上での必須要件だと考えるべきです。
評価のためのObservability
ここまでトラブルシュートにおけるObservabilityの有用性について記載しましたが、動作しているシステムの状態を評価するためにもObservabilityは重要です。
システムの評価の話ですとLeanとDevOpsの科学でも紹介されたState of DevOps ReportのFour Keysが有名です。
2021のレポートより5つ目のメトリクスとして信頼性が追加されていますが、その計測のためにもObservabilityが重要になってきます。
信頼性を測定するということはSLOを定めてその達成度合いから信頼性が担保出来ているのか否かで判断することになります。
SLOの計測には様々なデータを収集する必要があり、Observabilityが確保されていない状態ではデータが不足してしまい、計測することが難しくなります。
また、SLOを定める際には先にSLIを設定することになりますが、この場合もObservabilityが担保されている環境であれば、様々なデータを元にSLIの項目の検討が進められます。
※全くデータが手元にない・・・という状態ですとSLIの検討も困難になります
OpenTelemetryがなぜ良いのか
ここまでObservabilityの必要性について説明をしました。
その必要性に納得してもらったら、次は実際どうやるのか?という話になります。
Observabilityを担保する上で重要となるテレメトリーデータの3本柱として「ログ」「トレース」「メトリクス」が上げられます。
これらを取り扱うツールは世の中に沢山存在しており、有償ツール、OSSなど様々です。
※Datadog, NewRelic, Splunk, Honeycomb, Grafana・・・etc
以前はそれぞれのツールが独自のエージェントやプロトコルを実装していたため、ツールを切り替えようとすると、アプリケーションや連携するエコシステムにまで手を入れる必要がありました。
この様なロックインの環境を打破するべく整備されているのがOpenTelemetryです。
OpenTelemetryはテレメトリデータを収集してバックエンドに転送する方法を標準化するフレームワークです。
OpenTelemetryに対応していれば、アプリケーションに手を加えること無く、より柔軟にシステムや組織の規模に合わせてツールを切り替えることも可能になります。
OpenTelemetry導入のステップ
OpenTelemetryがなぜ良いのかということについて説明しましたので、最後に弊社の事例を元にOpenTelemetry導入のステップも簡単に紹介させて頂こうと思います。
なお、本記事を書いている段階でまだ検証と構築の段階のため、現時点での構想のものも含んでいます。
弊社のインフラは全体の8割以上がオンプレミスで動作しているため、Observabilityの基盤を構築する場合もオンプレミス上に構築するという前提で進めています。
最終的には社内の全プロダクトへ展開することを考えていますが、まずは小さなプロダクトから始めてノウハウを貯めながら広げていく想定で進めています。
ツール選定
導入するツールについてはSREチームでいくつかの候補に対してPoCを実施して判断しています。
有償のツールを利用するための予算は確保していないため、OSSの利用を条件として検討しています。
実際に以下のツール類を試した上で比較を行いました。
SigNoz
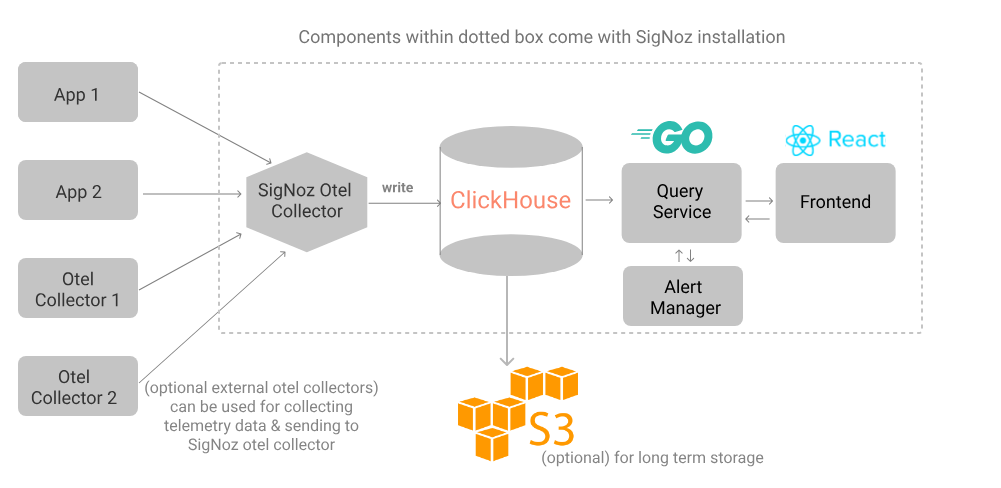
自前の構成図は作っていなかったので公式の画像を拝借しています。
Elastic Stack
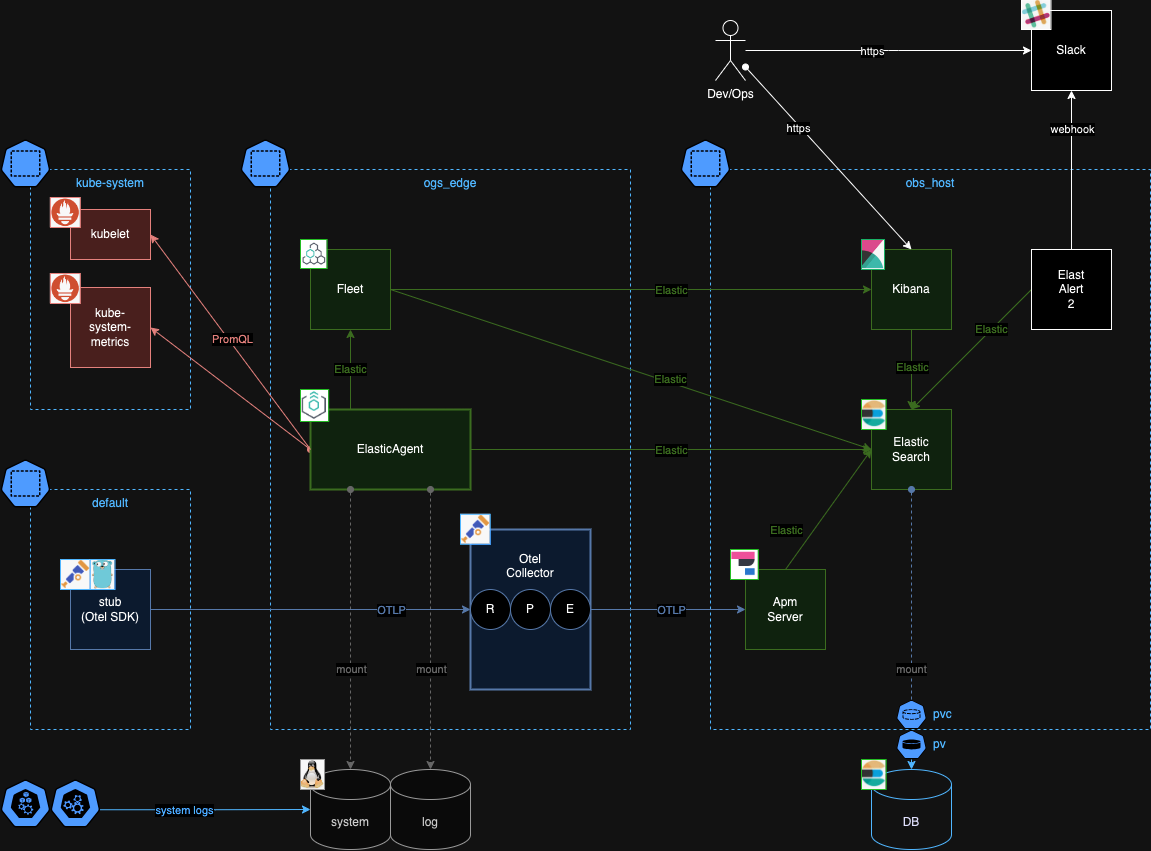
Elastic Agent, Apm Server, Elastic Search, Kibanaを利用した構成で試しています。
Grafana Stack
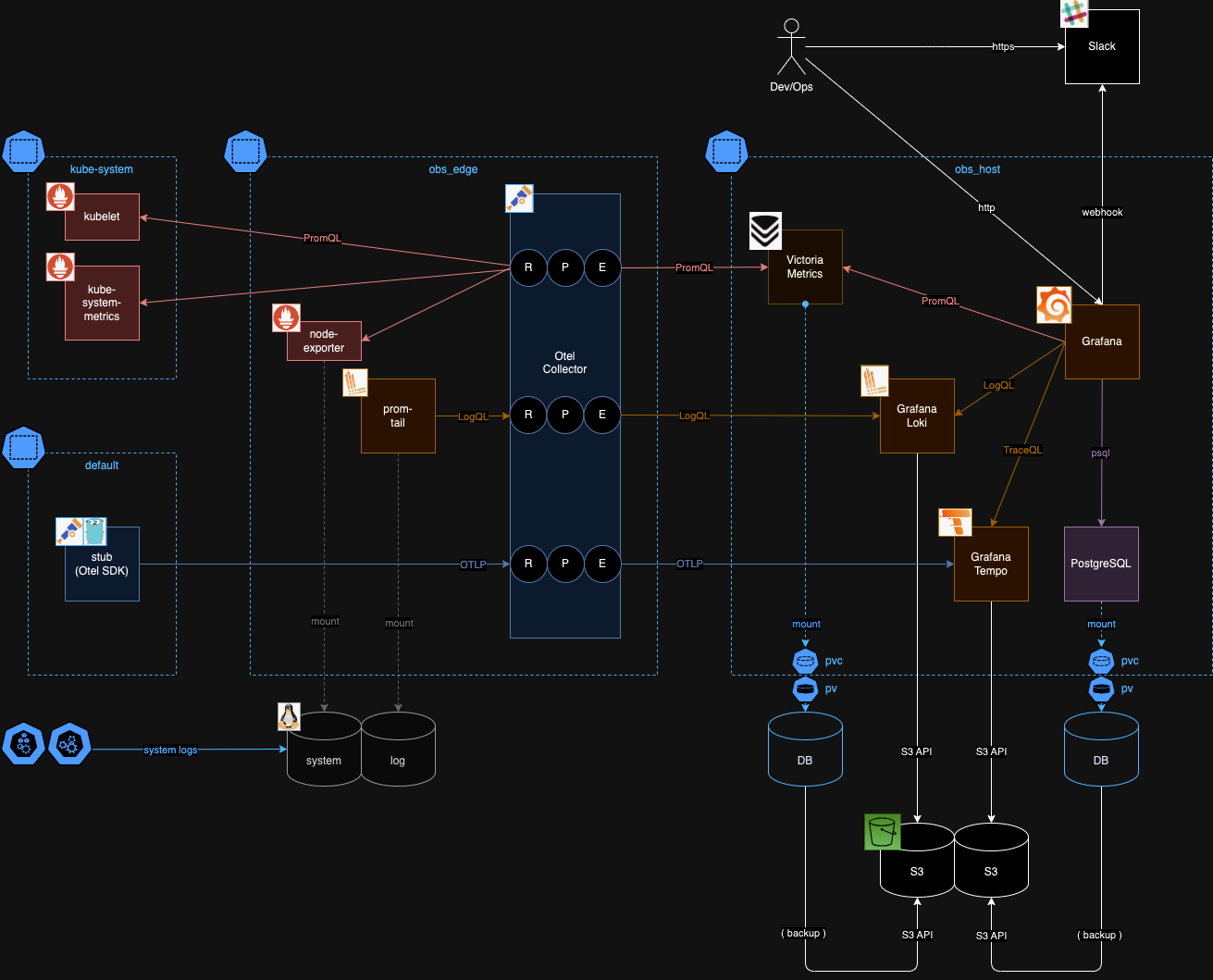
Prometheus, Grafana Tempo, Grafana Loki, Grafanaを利用した構成で試しています。
最終的に私達はGrafana Stackを選択しています。
SigNozについては、手軽にインストール出来る点は良いのですが、スケールの面や利用実績など本番利用にはリスクが高いと判断しました。(社内ツールとかなら十分使えると思います)
最終的にElastic StackとGrafana Stackを比較したのですが、Grafana Stackの方がOpenTelemetryへの対応がしっかり出来ていると判断してこちらを選択しました。
運用を開始した後にバックエンドのツールを切り替える可能性があるため、OpenTelemetryへ対応している範囲が広い方がより求める条件にマッチしていたということになります。
計装について
計装については意見が分かれるところですが、ここの議論を頑張ってもあまり意味がない(先のことは読めないので)という結論になり、まずは実装して使うことを優先することにしています。
そのため、自動計装のライブラリを利用してまずはそのまま導入し、個別の計装は必要性が出てきたところで少しずつ追加していく方向で進めています。
SREチームはGoを使って開発を行っているため、Goの計装ライブラリを利用して自動計装を行っています。
SRE以外の開発チームではJavaを利用しています。こちらについてはJava言語の特性でコードに手を入れること無くDIの様な形で自動計装が可能なため、そちらを利用する想定で進めています。
こちらの方がアプリケーションを開発するメンバーは意識する事が少なくなるのでより良い様に思います。
自動計装については、本アドベントカレンダーの2日目に投稿してくださっていた@k6s4i53rxさんがCNDT2023で分かりやすく解説してくれているのでそちらを見ていただくのが良いと思います。
まとめ
各種ツールが成熟してきたことでOpenTelemetryを導入するための敷居は下がって来ています。
ただし、従来のモニタリングから切り替えるコストは発生するため、目的をしっかりと説明して協力を得る必要があります。
まずはObservabilityの重要性を正しく理解してもらうことから始め、その上でOpenTelemetryを利用することで変更に強い環境を構築していくという流れで関係者が協力しながら進めていけると良いかと思います。
偉そうに書きましたが、私達も現在進行系でOpenTelemetry導入を進めています。
そちらの情報はまた、自社のブログなどで発進していきたいと思います。
明日は@sublimerさんの記事です。
残り少なくなってきましたが引き続き盛り上がっていきましょう。