概要
衛星画像データと深層学習による湖水のクロロフィル濃度推定の研究を行っております。
衛星画像データを取得し、衛星画像データから該当する水質拠点の緯度経度を指定して抽出したピクセル値(DN値)や、雲の情報を元に表を作成しました。これからまたディープニューラルネットに学習させるために、データの前処理・成形したいと思います。その時役に立ったPythonプログラミングモジュールやメソッド等について今回は記述していきたいと思います。
元になるデータ表
こんな感じのデータを作成しています。
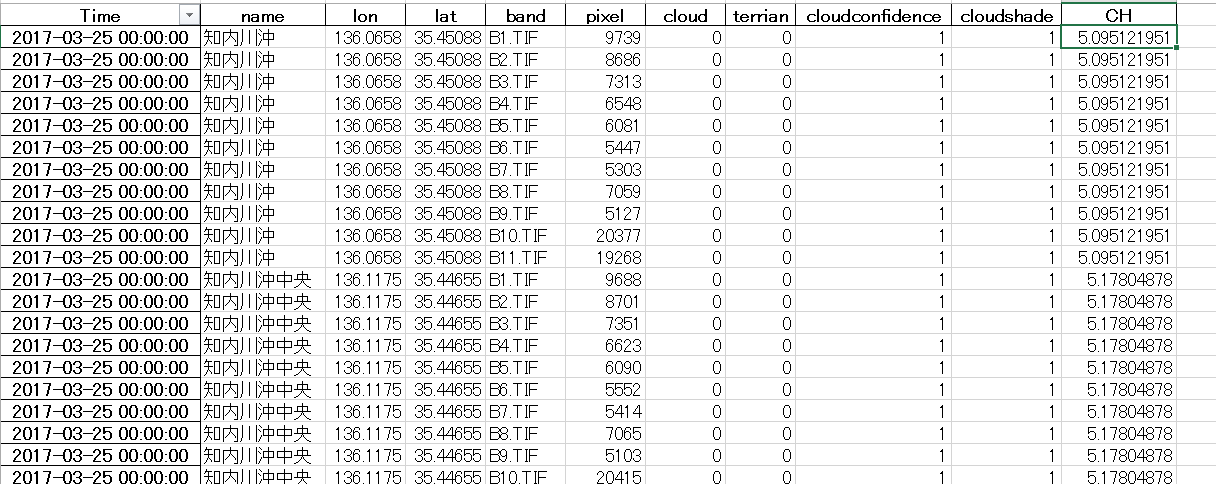
左から、衛星画像データ取得日、水質拠点、水質拠点の緯度経度、衛星画像データのバンドタイプ、抽出したピクセル値(DN値)、cloud 雲情報(0 or 1 雲だったら1、じゃなかったら0)、terrian(陸かどうか),
cloudconfidence(雲である確率。00 不確定 01 雲の可能性低い 10 雲の可能性中 11 雲の可能性大)、cloudshade(雲影の確率)、正解用データのCH(クロロフィル濃度)
これからディープニューラルネットに入力するための形状に変換します。
pandasで条件抽出してから表をArray型に変換
ディープニューラルネットに入力するためには、データをArray型に変換する必要があります。
変換した際のプログラミングはこちら↓
import numpy as np
import pandas as pd
all_data = pd.read_excel("表のPath")
time = []
time = all_data["Time"].unique()
kyoten = []
kyoten = all_data["name"].unique()
list = []
list2 = []
pixel = []
CH = []
Cloud = []
terrian = []
CC = []
CS = []
for t in time:
for n in kyoten:
pixel = all_data["pixel"][(all_data["Time"] == t) & (all_data["name"] == n)].values
CH = all_data["CH"][(all_data["Time"] == t) & (all_data["name"] == n)].values
Cloud = all_data["cloud"][(all_data["Time"] == t) & (all_data["name"] == n)].values
CC = all_data["cloudconfidence"][(all_data["Time"] == t) & (all_data["name"] == n)].values
CS = all_data["cloudshade"][(all_data["Time"] == t) & (all_data["name"] == n)].values
if len(CH2) != 0:
list += [[pixel2, Cloud[0], CC[0], CS[0]]]
list2 += [[CH[0]]]
data_array = np.array(list)
CH_array = np.array(list2)
ここで使用したモジュールはpandasとnumpy
機械学習には必要不可欠な二つですよね。
ここでポイントになるのはpandasの条件を指定して表から値を抽出する方法と、リストからnp.array("list)でarray型に変換してるところぐらいですね。
しかし、こんな感じで3次元以上の不規則なarrayになっています。
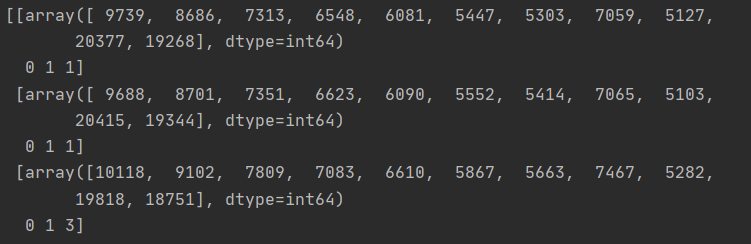
多次元リストを一次元に平坦化し、リストをサブリストに変換する方法
まず多次元リストを一次元に平坦化します。
参考にしたサイトはこちら→多次元リストを一次元に平坦化する方法
for el in l:
if isinstance(el, collections.Iterable) and not isinstance(el, (str, bytes)):
yield from flatten(el)
else:
yield el
list1 = []
for x in data_array:
list1 += flatten(x)
これだけだと全データが平坦化されているので、日付ごとのピクセル値~クロロフィル値のサブセットに分けます。リストをn個のサブリストに分割する方法
def split_list(l, n):
"""
リストをサブリストに分割する
:param l: リスト
:param n: サブリストの要素数
:return:
"""
for idx in range(0, len(l), n):
yield l[idx:idx + n]
# 14個の要素でリストを分割
inputs = np.array(list(split_list(list1, 14)))
これで完成です!これからデータを正規化して、学習用データとテストデータに分けます。
データの正規化と学習用データ・テストデータに分割する方法
学習用データ・テストデータに分割する方法
0~1に正規化する前に、対数をとってますが、これはデータの分布をより正規分布に近づけ機械学習に効果的にするためです。
必要なモジュールのインポート
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
データの対数をとったものを、さらに0~1に正規化
scaler = preprocessing.MinMaxScaler()
pixel_log = scaler.fit_transform(np.log(inputs[:, 0:11]))
cloud = scaler.fit_transform(inputs[:, 11:])
CH_log = scaler.fit_transform(np.log(CH_array))
ピクセル値と雲情報などの結合しさらに衛星データとクロロフィルデータの結合(いったん全部シャッフルするため
input_log = np.concatenate((pixel_log, cloud), axis=1)
衛星データとクロロフィルデータの結合(いったん全部シャッフルするため)
zenbu = np.concatenate((input_log,CH_log),axis=1)
学習用データとテストデータに分割してから衛星データと正解クロロフィル濃度データに分割
zenbu_train, zenbu_test = train_test_split(zenbu, shuffle=True)
inputs_train = zenbu_train[:,0:14]
CH_train = zenbu_train[:,14:]
inputs_test = zenbu_test[:,0:14]
CH_test = zenbu_test[:,14:]
終わり
以上長くなりましたが、データの前処理はこれでおわりです!
次回はいよいよディープニューラルネット構築です!
お読みいただきありがとうございました。