Google Fonts が日本語 Web フォントを提供している仕組みに倣い、フォントデータを 120 ファイルに分割して読込みの最適化を行う 試みです。
今回は実装の説明の前に、予備知識として Google Fonts がどのように日本語フォントを提供しているかを確認してみたいと思います。
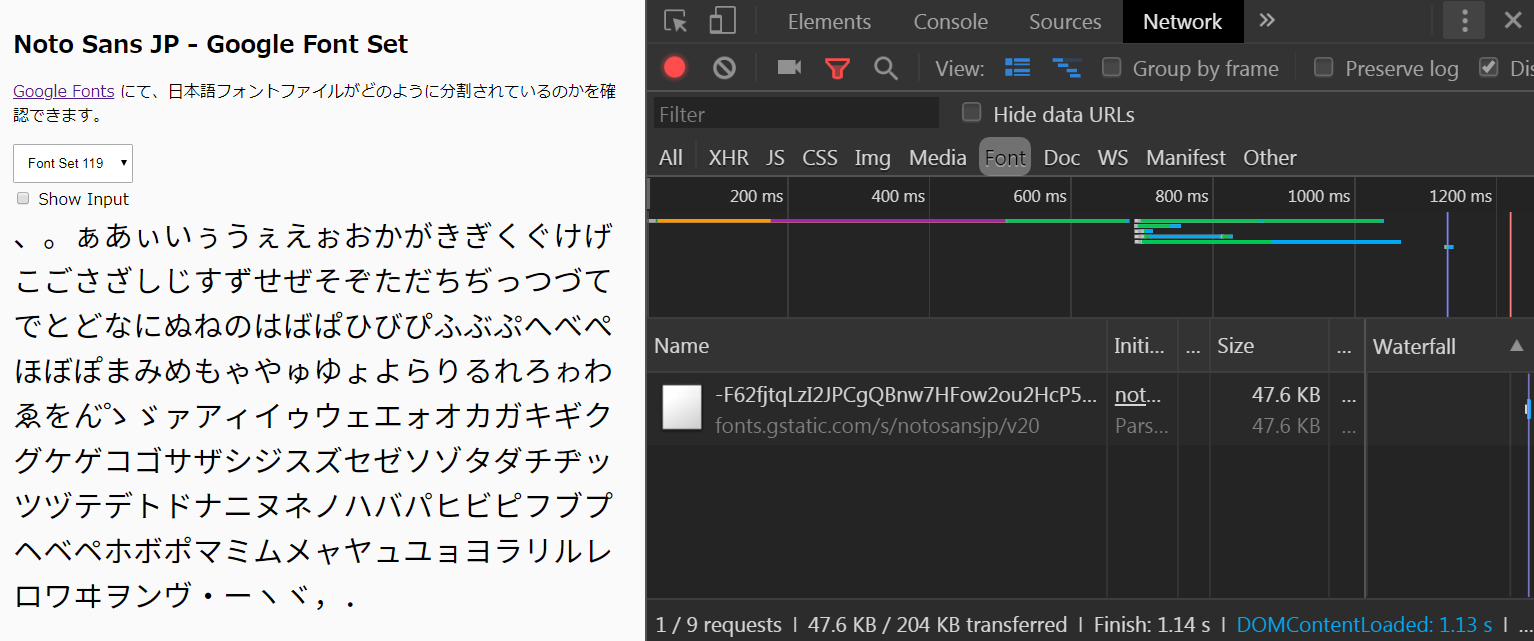
Google Fonts では日本語をどのように分割しているのか?
Google Fonts 提供の Noto Sans JP が、どのようにサブセット化されているかを確認できるページを Vue で作ってみましたので、Chrome でアクセスしてみてください。(Chrome でなくても良いですが、IE はダメです!![]() )
)
https://jp-webfont-subset-example.herokuapp.com/noto-sans#/
-
ページ左上のコンボボックスで Font Set 0 から Font Set 119 までを変更できます。
-
Google Fonts が提供する日本語フォントは、このフォントセットの単位でサブセット化され、それぞれ固有のフォントファイルとして CDN から提供されています。
-
開発者ツールを開き、[Network] → [Font] を表示すると、フォントセットを切替えたり、テキストエリアで適当な文字を入力すると、適宜必要なフォントセットが動的に読み込まれる様子を確認することができます。
-
この動的読込みの仕組みに JavaScript は必要なく、CSS の機能だけで実現されています!

Google Fonts の仕組み
Google Fonts 提供の Noto Sans JP を利用する際に読み込む CSS には、以下のような記述が全部で 120 個定義されています。
/* [0] */
@font-face {
font-family: 'Noto Sans JP';
font-style: normal;
font-weight: 400;
src: local('Noto Sans Japanese Regular'),
local('NotoSansJapanese-Regular'),
url(https://fonts.gstatic.com/s/notosansjp/v20/-F62fjtqLzI2JPCgQBnw7HFow2ou2HcP5pp0erwTqsSCpNtb5_OnUY4AN8I8f2ogPhktlh5UtNFs.0.woff2)
format('woff2');
unicode-range: U+25e56, U+25e62, U+25e65, U+25ec2, U+25ed8, U+25ee8, U+25f23, U+25f5c, U+25fd4, U+25fe0, U+25ffb, U+2600c, U+26017, U+26060, U+260ed, U+26222, U+2626a, U+26270, U+26286, U+2634c, U+26402, U+2667e, U+266b0, U+2671d, U+268dd, U+268ea, U+26951, U+2696f, U+26999, U+269dd, U+26a1e, U+26a58, U+26a8c, U+26ab7, U+26aff, U+26c29, U+26c73, U+26c9e, U+26cdd, U+26e40, U+26e65, U+26f94, U+26ff6-26ff8, U+270f4, U+2710d, U+27139, U+273da-273db, U+273fe, U+27410, U+27449, U+27614-27615, U+27631, U+27684, U+27693, U+2770e, U+27723, U+27752, U+278b2, U+27985, U+279b4, U+27a84, U+27bb3, U+27bbe, U+27bc7, U+27c3c, U+27cb8, U+27d73, U+27da0, U+27e10, U+27fb7, U+2808a, U+280bb, U+28277, U+28282, U+282f3, U+283cd, U+2840c, U+28455, U+2856b, U+285c8-285c9, U+286d7, U+286fa, U+28946, U+28949, U+2896b, U+28987-28988, U+289ba-289bb, U+28a1e, U+28a29, U+28a43, U+28a71, U+28a99, U+28acd, U+28add, U+28ae4, U+28bc1, U+28bef, U+28cdd, U+28d10, U+28d71, U+28dfb, U+28e0f, U+28e17, U+28e1f, U+28e36, U+28e89, U+28eeb, U+28ef6, U+28f32, U+28ff8, U+292a0, U+292b1, U+29490, U+295cf, U+2967f, U+296f0, U+29719, U+29750, U+29810, U+298c6, U+29a72, U+29d4b, U+29ddb, U+29e15, U+29e3d, U+29e49, U+29e8a, U+29ec4, U+29edb, U+29ee9, U+29fce, U+29fd7, U+2a01a, U+2a02f, U+2a082, U+2a0f9, U+2a190, U+2a2b2, U+2a38c, U+2a437, U+2a5f1, U+2a602, U+2a61a, U+2a6b2, U+2a9e6, U+2b746, U+2b751, U+2b753, U+2b75a, U+2b75c, U+2b765, U+2b776-2b777, U+2b77c, U+2b782, U+2b789, U+2b78b, U+2b78e, U+2b794, U+2b7ac, U+2b7af, U+2b7bd, U+2b7c9, U+2b7cf, U+2b7d2, U+2b7d8, U+2b7f0, U+2b80d, U+2b817, U+2b81a, U+2f804, U+2f80f, U+2f815, U+2f818, U+2f81a, U+2f822, U+2f828, U+2f82c, U+2f833, U+2f83f, U+2f846, U+2f852, U+2f862, U+2f86d, U+2f873, U+2f877, U+2f884, U+2f899-2f89a, U+2f8a6, U+2f8ac, U+2f8b2, U+2f8b6, U+2f8d3, U+2f8db-2f8dc, U+2f8e1, U+2f8e5, U+2f8ea, U+2f8ed, U+2f8fc, U+2f903, U+2f90b, U+2f90f, U+2f91a, U+2f920-2f921, U+2f945, U+2f947, U+2f96c, U+2f995, U+2f9d0, U+2f9de-2f9df, U+2f9f4;
}
/** 以下[119] まで [0] と同様のフォーマットが続きます **/
| 項目名 | 説明 |
|---|---|
| src | 参照するフォントデータ。ユーザのローカルにない場合は、url で指定されているフォントデータを利用します。 |
| unicode-range | 「U+」から始まる英数字(文字コード)。例えば最初の U+25e56 は、**「𥹖」**を表します。 |
src の url には unicode-range で指定されているすべての文字だけを埋め込んだ(サブセット化)フォントファイルへの参照が設定されています。
そして、**ブラウザはページ内で使われているテキストの中に unicode-range で指定された文字があれば、紐づけされたフォントファイルを自動的に読み込んでくれるという仕組みになっています。**意外とシンプルですね!![]()
気づいたこと
-
Noto Sans JP 以外の Google 日本語ウェブフォントの
unicode-range指定も同じだった。 -
基本的には、文字タイプ(平仮名/片仮名/漢字/英数字/記号)、漢字の部首をベースにグループ分けされているように見受けられる。使用頻度や画数なども関係あるのかもしれない。
-
何ヶ所か意味不明な範囲指定がある。例えば Font Set 118にはすべての英数字がサブセット化されているように見えるが、実は「N」だけは Font Set 117 の方に含まれている。
-
それぞれのフォントファイルに含まれる文字数と、ファイルサイズは結構マチマチ。ファイルサイズは最大が Font Set 6 の73.0KB、最小が Font Set 115 の 13.5KB だった。
-
表示上は同じ漢字が異なるフォントセットに含まれていたりする。例えば「林」は、Font Set 0 とFont Set 102 の両方に含まれているが、unicode-range による指定は、それぞれU+2f9f4とU+6797で別のコードとなっている。 -
上記に関連して、String.fromCharCode(parseInt('0x2f9f4'))で「林」という漢字をレンダリングした場合でも、Font Set 102 (U+6797) の方が読みこまれる。同様のケースが他にもいくつか有り。 -
文字コード指定されたすべての文字がフォントとして用意されているわけではない。ところどころ文字化け?したり、_sansで表示される文字が有る。 -
<input>要素のplaceholder属性に指定されたテキストについても、ちゃんと認識してくれる。(当たり前?)
Google のサブセット化を模倣する方法..(その 2 へ続く)
Google Fonts が日本語フォントを分割している法則は完全には分からないものの、同じ unicode-range に従って開発者が任意の日本語フォントをサブセット化さえできれば、同様の最適化の恩恵を受けられるはずですね?
次回は実際に Google Fonts と同じ要領で、日本語フォントを 120 個に分割してサブセット化する方法について書こうと思います!