ニフティグループ Advent Calendar 2018の17日目です.
こんばんは.会社ではニコラスとか呼ばれています.日本人です.
はじめに
最近巷ではイ為サイトが話題になっています.年末に魔物が済むといわれていますが,イ為サイトも年末になると元気になるようです.知らんけど.
https://www.fnn.jp/posts/00407155CX
http://news.livedoor.com/article/detail/15691051/
なので,今日は話題の偽サイトを作ってみようとおもいます.
偽サイトの作り方
手順1
サイトにアクセスします.
手順2
次に特殊なコマンドを入力します.
⌘ + s (Macの場合)
手順3
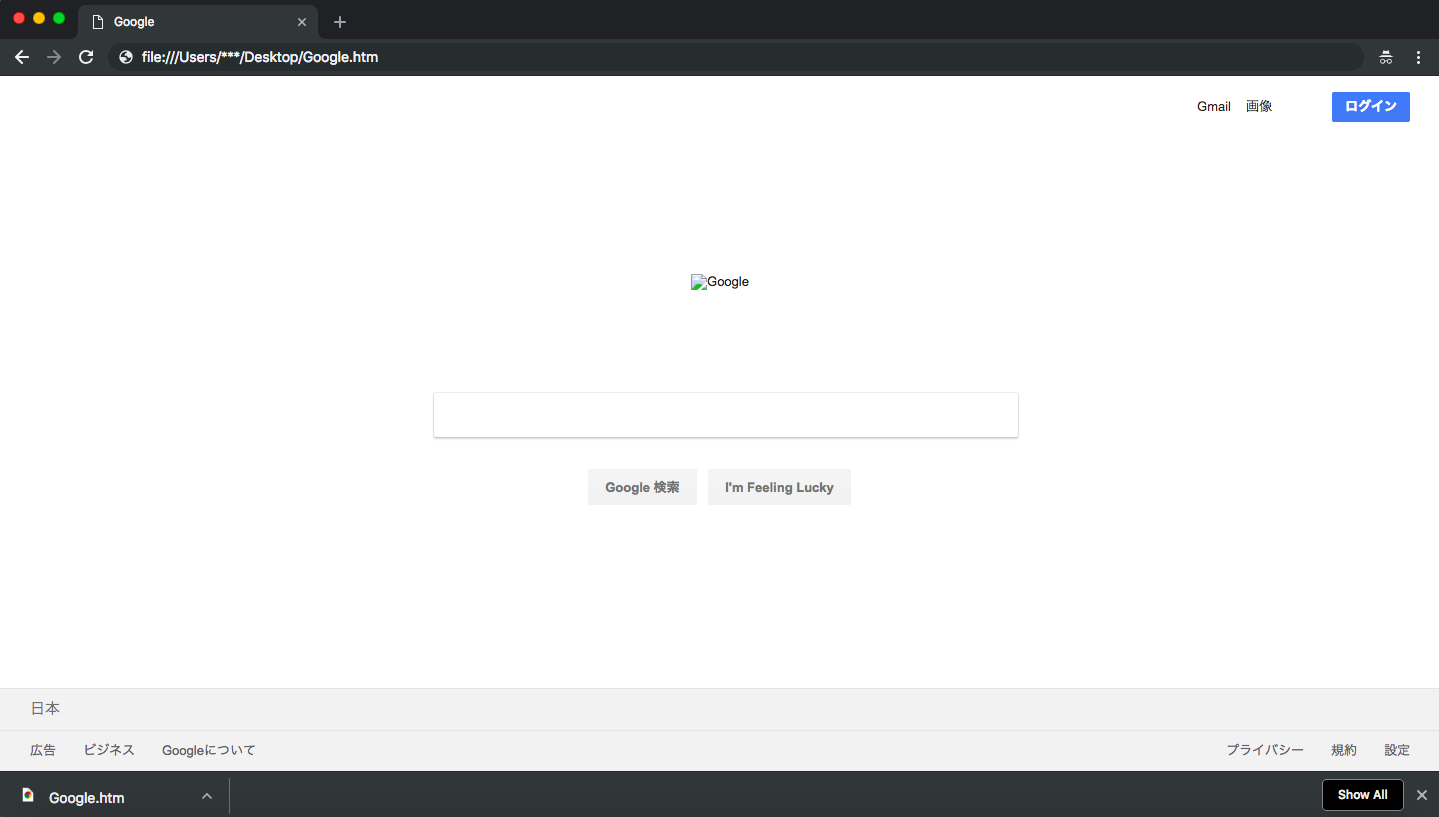
あとはサーバーにアップロードして完成・・・・あれ?
作ってみた.でも出来なかった.おしまい.
解説
googleの場合はchromeのページ保存機能でロゴが保存できませんでした.残念です.ではロゴの部分のソースをみてみましょう,
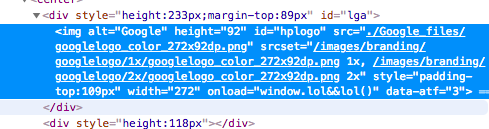
ロゴは画像なので,imgタグで表示しています. src属性でロゴ画像のパスが指定されています.見慣れないsrcset属性がありますが,これはHTML5で新しく定義された属性表示している画面の解像度によって表示する画像を変更できる属性になります.
Chromeの機能でページを完全保存した場合はHTMLから呼び出すリソース(画像とかjsファイル,cssファイル)をローカルに保存して,HTMLのパスを書き換えます.今回の場合ではsrcに指定されているリソースは保存されパスが書き換えられています.実際にGoogle_filesの中にはsrcのロゴ画像が保存されています.
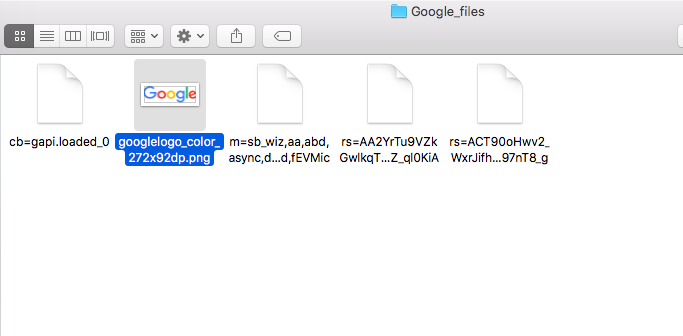
しかしChromeはsrcset属性で指定されている画像を表示しようとします.Chromeの完全ページ保存機能ではsrcset属性の依存関係は解決しないので,画像のダウンロードもHTMLのパスの書き換えも行なわれないため,画像のパスが存在せず画像が表示されません.
googleのトップページは意図している訳ではないですが,chromeの保存機能では完全なページはできません.逆に言うと簡単にはコピーしたページを作ることはできないということです.
さて,最近の問題ですがフィッシング詐欺が巧妙化し,偽サイトを作ることが多くなっています.ひと昔であれば,適当なサイトでフィッシングしていたようですが,最近のは見た目は本物そっくりな事があります.私はフィッシングサイトを作ったことが無いので実際にどうやっているのかはわかりませんが,ブラウザの保存機能を使うと誰でもコピーできるのは事実です.
偽サイトもブラウザの保存機能を使っているのでしょう.知らんけど.
なので,偽サイトを作らせないためにも,ブラウザの保存機能の動作を理解し,「完全」な保存させないサイト作りが偽サイト対策になります.
Chromeで保存できないサイトの作りかた
1 srcset属性を使う
googleが教えてくれた方法.ただしIEではsrcset属性は非対応なので,IEではsrcを読みにいきます.なのでフィッシングサイトがIEが対応しているなら(皮肉),これは無効です.IEのみの対応のフィッシングサイトが登場したら,セキュアなchromeに誘導するつもりなのでしょう.知らんけど.
2 background_img属性を使う
imgタグにcssファイルでbackground_imgを指定すると画像は表示されるますが,保存はされません.どうにもchromeでは再帰的にパスの解決をしないようです.
3 CSSの@import url();を使う
cssはimportが可能なので複数ファイルに分割できます.そのためのimportなのですが,この依存関係もchromeは解決してくれないです.ただし,cssのimportはページのロード時間が伸びる(=レンダリングされるまでに時間がかかる)ので副作用もあります.
4 querySelector("[src$='.ダウンロード']")でダウンロードを検出する.
chromeはjavascriptファイルの拡張子を変更します.リネームせずに保存するとWSH直接実行できるのを防ぐためだと思いますが,jsファイルの拡張子がかわるのを利用して,保存されたのを検出する事ができます.検出が出来るなら,レポートを送るのもありですし,全部dispay:none;にするなりして嫌がらせしたりできます.
結局のところ
いたちごっこです.
でも相対パスが解決されないことを利用して偽サイトを作りにくくできます.ただ,これが通用するのはエンジニアもどき程度が偽サイトを作った場合です.本当にできるエンジニアリングならば,パスを解決もお手の物なので対策が効きません.
ただ,メジャーなサイトを見ていると保存対策をしているところが無く無防備です.偽サイト対策にもある程度でもいいので,簡単に保存できなくすることぐらいしておいてもいいとは思います.画像が表示できなくなるだけの対策なら簡単だと思います.
知らんけど.