はじめに
料理を行う際の一番頭を使う工程は、「何を作るか?」を考えるときだと思いませんか?
特に冷蔵庫に食材が残っている場合は、その中から作れる料理を考える必要があったり、何かを買い足して作る場合は考える範囲が広がってしまって逆に面倒だったりしたことがあるかと思います。(私だけかもしれませんが。。。)
そこで、冷蔵庫の食材を写真で撮影し、その画像を物体検出を用いて検出することができれば簡単な料理提案アプリが作れるのではないかと思ったことがきっかけで、アプリの作成と本記事の作成に至りました。
※本記事ではアプリ作成まではいかず、モデルの学習と評価までの流れになります。
また、AWSを利用したWEBアプリの作成が目的となることとYOLOv8の論文等を確認できていないことから、モデルの学習や評価に関しては少し簡単なものになっています。
※調べると似たようなことをやられている方がいますね。
特に上のほうは高校1年生のようで、モバイルアプリの実装まで行っていて驚きました。
自分が高校生の時などDeep learningなど全く知らなかったですよ。。。
https://www.ipsj.or.jp/event/taikai/86/86PosterSession/ipsj_poster/pdf/8137.pdf
http://www.rsch.tuis.ac.jp/~nagai/research22/slide4_2.pdf
想定する構成
アプリの作成はあまり行ってなかったため、現在「FLASKによるWEBアプリ開発入門」を用いてWEBアプリの作成を学習しております。こちらの学習が終わり次第、FLASKを利用して
「画像をアップロードしたら、料理を1つ以上提案する」
簡単なアプリをAWSを用いて作成しようと考えております。
使用するモデルについて
YOLOv8を利用します。
YOLOはv3を使用したことはありますが、v4以降は触ったことはありませんでした。
v8に関しては学習や評価は簡単に行うことが可能で、評価に関しては上記gitの"Note books"を利用することで簡単な物体検出を行うことが可能であり、とても使いやすいものと思います。
また、物体検出のみでなく、画像分類やセグメンテーションもカバーしているようです。
モデルのサイズも複数ありパラメータ数が大きいほど精度がいい傾向が見られますが、その分モデルサイズが大きかったり、学習に時間がかかることも考慮して、今回は最も軽量な"YOLOv8n"を使用します。
使用するデータセット
roboflow universeを使用しました。
今回の検出対象は、
1:キャベツ
2:人参
3:きゅうり(そのまま食べつことが主で、あまり火を通すイメージないですが。。。)
4:卵
5:ナス
6:玉ねぎ
7:じゃがいも
8:トマト
9:大根
10:ピーマン
11:肉
12:レタス
13:長ネギ
14:白菜
15:ブロッコリー
上記を検出対象とします。
学習や評価は簡単なものと書きましたが、誤検出しやすい傾向が明らかにみられるものは画像処理(輝度値/RGB値)を利用して補完しようかと考えております。
学習について
下記に、それぞれの項目ごとの学習データ数とバリデーションデータ数を記載します。
学習データ数/バリデーションデータ数
1:キャベツ 5299個/718個
2:人参 6863個/659個
3:きゅうり 4220個/321個
4:卵 4220個/544個
5:ナス 5364個/321個
6:玉ねぎ 5083個/183個
7:じゃがいも 5493個/322個
8:トマト 6585個/416個
9:大根 3076個/170個
10:ピーマン 6325個/398個
11:肉 4358個/41個
12:レタス 1682個/14個
13:長ネギ 61個/14個
14:白菜 716個/34個
15:ブロッコリー 801個/7個
枚数のばらつきが大きいので、WEB作成完了まで完了したのちにうまく均等化して学習と評価をしたいですね。
また、基本的には
pip install ultralytics
でインストールしたものを使用すればいいのですが、データ拡張設定や学習率設定をいじりたいのと、適宜内部を変更して使用したかったこともあって、gitからcloneしたソースコードを使用していました。
(後述しますが、cloneしなくても各種設定を行うことは可能です。)
ディレクトリ構造は下記になります。
YOLO/
├── data.yaml
├── datasets/
│ ├── train/
│ │ ├──images/
│ │ └──labels/
│ ├── test/
│ │ ├──images/
│ │ └──labels/
│ └── valid/
│ ├──images/
│ └──labels/
├── ultralytics/(gitからcloneしたディレクトリ)
└── YOLOv8.py
学習は「YOLOv8.py」を実行すると開始します。
スクリプトの中身は下記です。
from ultralytics.models.yolo.model import YOLO
if __name__ == "__main__":
# ベースとするモデル
model = YOLO('yolov8n.pt') <--事前学習済みのモデルを指定
# cudaのGPUを使ってモデルを学習
results = model.train(
data='./data.yaml',
epochs=400,
imgsz=640,
device='cuda',
optimizer='auto',
freeze=8,
cos_lr=True,
# lr0=0.01,
# lrf=0.01,
# warmup_epochs=10,
)
「data」:ラベル数とtrain,test,validの学習データpathを記載するyamlファイル
「epochs」:学習epoch数
「imgsz」:入力画像サイズ(自動でリサイズされるため、学習データをあらかじめこのサイズにリサイズする必要は無い)
「device」:トレーニング用の計算デバイス指定
「optimizer」:autoの場合はSGDが使用される。Adam等も設定可能
「freeze」:ファインチューニング時に再学習しない層を指定
「cos_lr」:コサイン学習率スケジューラの使用設定(defaultはfalseだが、stable diffusionやtransformerモデル等で頻繁に使用されているのを見たため使用してみた)
上記設定は下記リンクからも確認できます。
(https://docs.ultralytics.com/ja/usage/cfg/#train-settings
因みに、「data.yaml」の中身はこんな感じです
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 16
names: ['cabbage', 'carrot', 'cucumber', 'egg', 'eggplant', 'garlic', 'onion', 'potato', 'radish', 'tomato', 'greenpepper', 'meat', 'lettuce', 'leek', 'hakusai', 'broccoli']
※roboflow universeでDLしたデータセットはラベルの番号を変換したり前処理を行う必要があったため、その時に作成して使用したスクリプトはGitに置いております。https://github.com/megane-9mm/yolov8
結果
学習結果は下記のようになりました。
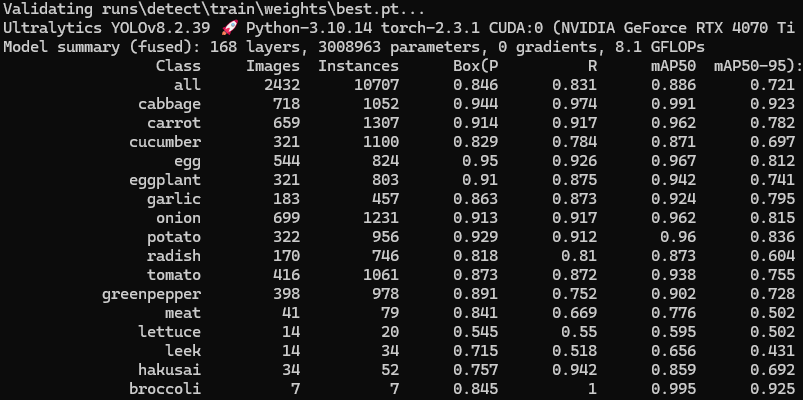
また、学習済みモデルで推論した結果が下記になります。

実は、撮影する角度によって検出できたりできなかったり、誤検出したりしました。特に、トマトは誤検出しにくいかと思っていましたが、思っていたよりも誤検出しています。
トマトの場合は誤検出の対応が可能と考えており、検出した位置を切り出した輝度値(RGB値)を参考にすることで、トマトの誤検出を抑えられる可能性があると考えています。
終わりに
物体検出のモデルの学習は簡単に行えるため、データセットさえ用意できればある程度の物体検出は可能かと思います。ただ、今まであまり物体検出の経験がないこととここまでの多クラス学習の経験が浅い事もあり、検出精度はまだまだです。
そのため、ハイパーパラメータを変更したり、学習データを追加したりしてWEBアプリ作成の裏で学習と評価を行おうと思います。
やはり学習データ数枚をしっかりと自分で作成して、それをうまくデータ拡張することで学習データの平均数を担保する必要があるかもしれませんね。
また、下記疑問点なのですが、
ultralyticsを用いて学習を行っており、初期設定では精度があまり良くなかったことから、ソースコードを見つつハイパーパラメータ等の変更を行っておりました。
そこで、ファインチューニングを行おうと思ったのですが、最終層(ultralytics.nn.modules.head.Detect)が初期設定でfreezeされるようになっておりました。
一般的なファインチューニングは、エッジ等どの画像でも似通った特徴を抽出する上位層をfreezeし、検出対象特有の特徴を抽出することになる下位層を再学習させるものだと思います。しかし、YOLOv8は最終層の重みは固定するようになっており、この理由がいまいちわかりません。(ソースコードの対象箇所 の251行目付近です。)
モデル構造を見ても、YOLO特有の画像サイズが異なる複数の出力を行っている箇所とも思いますが、CNNを利用していることもあって特徴抽出と重みの学習を行っていると思われます。
そのため、何故ここがfreezeされているかいまいち分からず。。。
何か分かる方がいらっしゃれば、ご意見を頂けるとありがたいです。
(物体検出の精度向上に関しても、ご意見やアドバイスがあればいただけると大変ありがたいです。。。)
以上です。
次はWEBアプリ関連の記事を投稿予定になります。