この記事は何
世の中でデータサイエンスが持て囃され幾星霜、皆さんいかがお過ごしでしょうか。
「私もキラキラしたデータサイエンティストになりたい ![]() 」なんて思うことはあっても、そこから一歩も踏み出せない。そんなことも多々あるでしょう。
」なんて思うことはあっても、そこから一歩も踏み出せない。そんなことも多々あるでしょう。
この記事はそんな方の背中を押すほど大層なものではございません ![]()
私のような「ちょっと遊びでデータを触ってみたいんだけど ![]() 」ぐらいの方に向けて、少し情報をまとめたものです。気が向いたら適宜追記・編集をしていきたいと思ってはいますが、過度な期待は後禁物
」ぐらいの方に向けて、少し情報をまとめたものです。気が向いたら適宜追記・編集をしていきたいと思ってはいますが、過度な期待は後禁物 ![]()
お品書き
- データの集め方
- データ処理基盤
- データの前処理
- データの可視化
- データの活用
データの集め方
私も含め、趣味データ分析erにとってはここが最初の鬼門ではないでしょうか?何をしたいかにもよりますが、まずデータ分析を試みてみたいのであれば例えば次のような選択肢があるかと思います。
- まとめられたデータを使う
- オープンデータのデータセットを活用
- お試しデータセットの活用
- 自分でデータを集める
- 各種WebサイトやAPIの活用
それぞれ見てみましょうか。
オープンデータの活用
昨今の風潮から様々なオープンデータが公開されていますね。検索してみると例えばこんなものがあります。
- デジタル庁が運営しているデータカタログサイト:
- 東京都オープンデータカタログ:
行政・自治体が公開なさっているものが多い印象です。ただデータの中身は玉石混交で、私が確認してみた中ではデジタル庁データカタログサイト掲載データの中には 人間が読むことを想定しておりデータ分析には不向きな形式のデータ も多く含まれていました。利用が容易な形式か否か、まず中身を確認するのがオススメです。
そして私の一押しのデータセットはこちら…!
- 人文学オープンデータ共同利用センター
紹介のため、利用可能なデータ一覧のページの切り抜きキャプチャを掲載させていただきます。もうこれだけでワクワクが止まらない…!
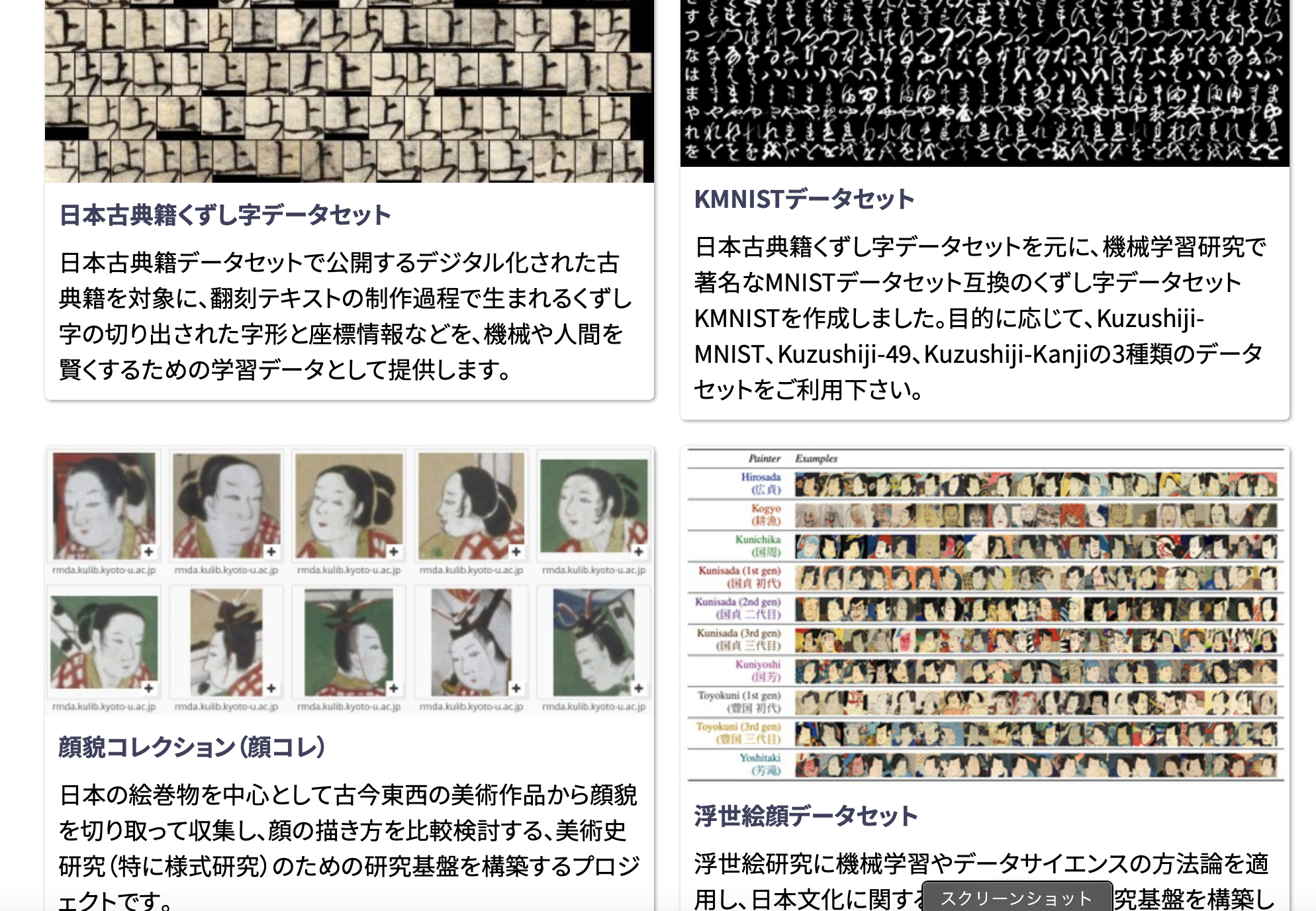
探してみれば、個人で利用可能なデータセットというものもたくさんありますね! ![]()
お試しデータセットの活用
例えば機械学習コンペティションで提供されているトライアル用のデータセットや、各種機械学習ライブラリから呼び出せるデータセットが存在します。
- SIGNATEさんの練習コンペ
時系列データ、テーブルデータ、画像データと、様々な練習問題があり、それぞれのデータセットが公開されています。(要登録)
- Kaggleさんの練習コンペ
こちらも同様に様々なデータセットがありますね。
- その他、あまりにも著名なデータセット
- MNIST: 手書き文字の画像データセット
- Iris: アヤメのテーブルデータセット
各種WebサイトやAPIの活用
興味のあるデータがデータセットという形式で配布されていなくても、WebサイトやAPIを使って頑張ってデータセットを作ることも可能です。同じデータセットを何人も作るのも勿体無いので、そうして作ったデータセットを共有する仕組みも欲しいですね。( delicaさんがトライしているようです)
データ処理基盤
昨今は選択肢が充実しすぎていて目移りしてしまいますね。大きく次の分類で見てみましょうか。 注:データの可視化までだけではなく機械学習等の活用も想定した基盤に限定します。
クラウドは基本的にPython(しかもJupyter Notebook)を使う例に絞っていますが、その辺りはご容赦ください。
- コードを書く
- ローカル
- まあ何でも…(雑)
- クラウド
- Google Colab
- Amazon SageMaker
- Azure ML
- Datalore
- ローカル
- ノーコード
- DataRobot
- RapidMiner
- (以下省略)
特にこだわりがなければローカルのPython環境か、Google Colabあたりの活用がお手軽なのではないかと思います。
(なお、ローカルならR Studioとかもありかもです。エコシステムが成熟しています。)
いかんせんPython勢力が強いので、以下では特にことわりがない限りPythonを前提に話を進めます
データの前処理
扱うデータにもよりますが次のような前処理が一般的には必要です。対応するライブラリをうまく活用して進めていくことになります。
- テーブルデータ
- 欠損値処理
- 標準化(後処理次第では不要)
- カテゴリデータ変換(one hot encodingなど)
- 次元削減
- 新たな特徴量生成
- 画像データ
- 意味のあるデータを際立たせる(輪郭抽出など)
- 意味のないデータを削除する(ノイズ除去など)
- 水増し
(自然言語系はまたの機会に…)
データの可視化
挙げればキリがありませんが、主流な可視化手段は統計量やグラフでしょうか。
グラフについては、一般的なグラフ(折線グラフ、棒グラフ)、ヒストグラム、散布図、相関係数プロットなどがよく使われると思います。それらの描画には次のPythonライブラリを使うのが一般的ですね。
- matplotlib
- plotly
- seaborn
- bokeh
せっかくなので過去に使ったことのあるかわりダネを少し記載しておくと…
- joypy
あるクラスごとのヒストグラムを比較したり、ヒストグラムの経時変化を見せるのに便利
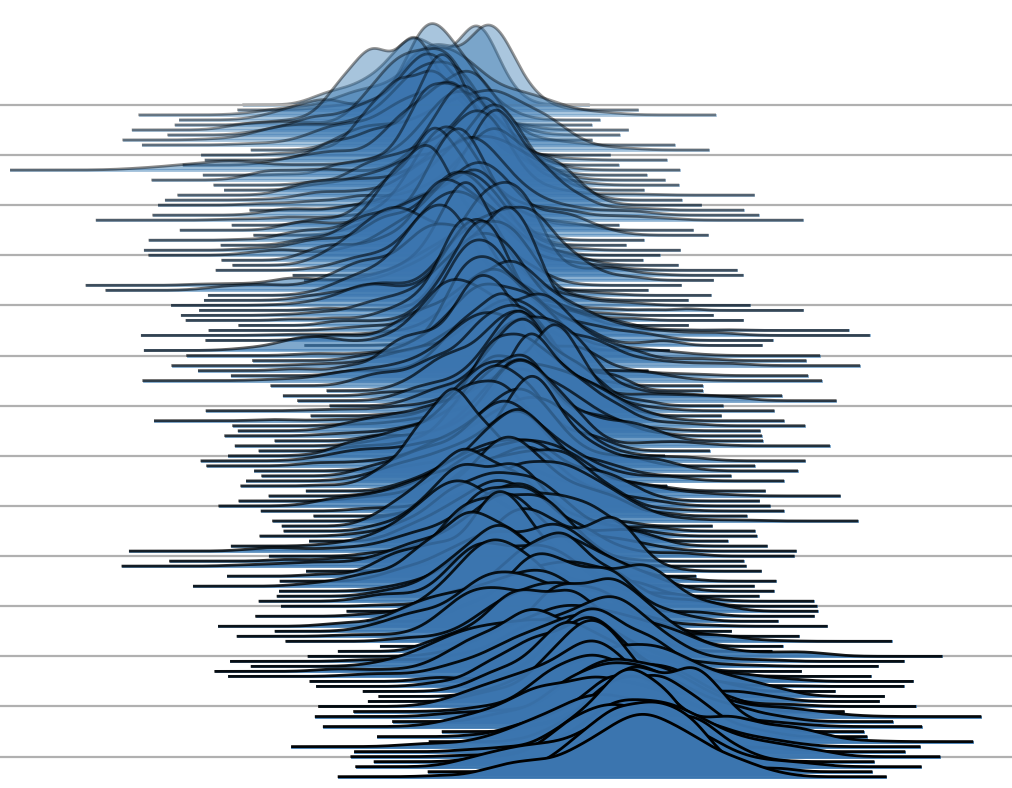
(Githubから引用)
データの活用
活用方法としてはやはり機械学習や深層学習による分類・回帰問題が多いでしょう。(自然言語系については割愛します) 以下、主流のPythonライブラリです。
- 機械学習
- scikit-learn
- LightGBM、XGBoostなどの決定枝系ライブラリ
- 深層学習
- TensorFlow
- kerasも統合されているので、ここではkerasを別途上げることはしません
- PyTorch
- TensorFlow
おわりに
こうして知識を並べていても身につかないので、まずは何かプロジェクトを決めて取り組んでみましょう!(私は浮世絵で何かしてみます笑)