1.目的
本記事は、昨今の製造業の生産ラインにおける省人化・自動化に変革を起こしつつある(と私が勝手に思っている)機械学習を用いた画像認識による外観検査機を、非IT系エンジニアの私でも作ることができるのか、実際にやってみて検証する記事です。
そこで本記事の目的を、「工業部品(O-ring)の外観検査を機械学習を用いて行うことができるか検証する」と設定しました。
なぜO-ringかというと、身近にいっぱい転がっていたからです。深い意味はありません。
2.結論
先に結論を言うと「単純な形状(O-ring)に限って言えば機械学習を用いて外観検査機を作ることは十分可能そうだ」となります。しかもかなり手軽に実現できそうです。
3.実現したい事
外観検査機でやりたいことは、以下のような製品画像を入力として、その製品画像が良品のものなのか、不良品のものなのか判別することです。

入力画像は300x300ピクセルのjpeg画像です。
見ての通り、右の不良品ではゴムが派手に切断されています。
これを検知するプログラムを作ります。
4.実装
環境は
・google colaboratory
・keras
・numpy
・matplot
です。
google colaboratoryではgpuの設定をonにしておくと、学習がとても速く実行されます。
フォルダ構成は、作業フォルダ下のkeras_imageフォルダの中にngフォルダとokフォルダを用意して、その中に上で例を示した良品、不良品の画像をそれぞれ3600枚用意しました。
これら用意した画像を学習用データと妥当性検証データに8:2で分配して使用しました。
下記にソースを示します。
import keras
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
import numpy as np
from sklearn.model_selection import train_test_split
from PIL import Image
import glob
import tensorflow as tf
import matplotlib.pyplot as plt
import os
from google.colab import drive
drive.mount('/content/drive/')
%cd "/content/drive/My Drive/O-ringClassify"
folder = ['ok','ng']
image_size = 300
epo = 100
# 画像の読み込み、リサイズ、ndarrayへの格納
X = []
Y = []
for index, name in enumerate(folder):
dir = 'keras_image/' + name
files = glob.glob(dir + '/*.jpg')
print(files)
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert('L')
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
# RGBデータの正規化
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, 2)
# 訓練データとテストデータの分配(2割をテストデータへ)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20)
X_train = X_train.reshape(X_train.shape[0],image_size,image_size,1)
X_test = X_test.reshape(X_test.shape[0],image_size,image_size,1)
input_shape = (image_size,image_size,1)
model = Sequential()
model.add(Conv2D(32,kernel_size=(3,3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(32,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2,activation='sigmoid'))
model.summary()
# コンパイル
model.compile(optimizer="SGD",
loss=keras.losses.categorical_crossentropy,
metrics=['accuracy'])
# 訓練
result = model.fit(X_train, Y_train,batch_size=20, epochs=epo,validation_data=(X_test,Y_test))
print(result.history.keys())
plt.plot(range(1, epo+1), result.history['accuracy'], label="training")
plt.plot(range(1, epo+1), result.history['val_accuracy'], label="validation")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
model.save('100epochs20batches')
学習過程における正確性と妥当性の推移を以下に示します。
横軸がエポックで縦軸が正確性です。
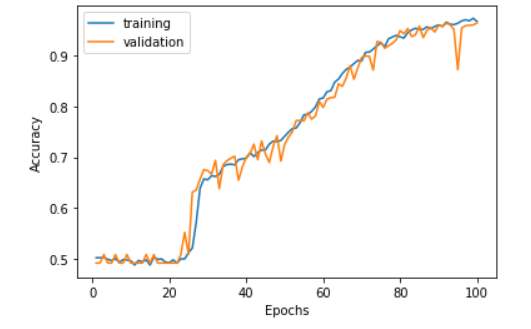
結果として正確性が0.95まで上がっていて、妥当性も同様に上がっていることから、過学習を起こさずに正確性が順調に上がっていったことがわかります。
5.モデルの保存と読み込み
上のソースの最後の行で"100epochs20batches"という名前で保存したモデルを読み込んで実際に予測を行ってみましょう。
(省略)
model = keras.models.load_model('100epochs20batches')
folder = ['randomTestNg']
image_size = 300
X = []
Y = []
for index, name in enumerate(folder):
dir = name
files = glob.glob(dir + '/*.jpg')
print(files)
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert('L')
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
# RGBデータの正規化
X = X.astype('float32')
X = X / 255.0
X = X.reshape(X.shape[0],image_size,image_size,1)
result = model.predict_classes(X)
print(result)
作業フォルダ下のrandomTestNgフォルダに適当に選んだNg画像を保存して実行すると今回はたまたま
[1 1 1 1 1 1 1 1 1 1]
を出力し、0:ok, 1:ngなのですべて正しく識別できていることが確認できました。
6.本記事は以下のサイトを参考にさせていただきました。ありがとうございます。
7.謝辞
本記事は近藤春奈さん、角野卓三さん、マイケルムーアさんの貢献が極めて多きいところとなりました。感謝します。
そして、コードを見て非効率部分を指摘してくれた友人に感謝します。ありがとうございました。