前回までで、Pythonで動くオーディオプレイヤーを自作してみました(ちゃちいです)
これにカラオケ機能をつけたいと思います。
歌詞データの用意
OpenAI社のWhisperという文字起こしモデルを使います。
pip install -U openai-whisper
whisperはtorchで動きます。
下記のコードを実行してGPUで動くかどうか確認しましょう。
import torch
print(torch.__version__, torch.cuda.is_available())
2.3.1+cu118 True
みたいに表示されればOKです。
※torchを入れとかないと、CUDA+CUDNN設定した環境で、Whisperモデル動かしてもCPUで動きます。
※私は上でハマりました。
import whisper
model = whisper.load_model("large")
result = model.transcribe(
file_path,
verbose=True,
word_timestamps=True,
language='ja'
)
import json
with open(file_path + '_result.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False)
word_timestampsのオプションをTrueに指定することで、
おおよそ1文字ずつの文字おこし結果が出力されます。
(jsonで保存しておきます)
きっとカラオケシステムのために用意されているに違いありません...(違う
※このオプション見つけたので、今回のネタをおもいついました。
Whisperの出力
こんなJSONです。
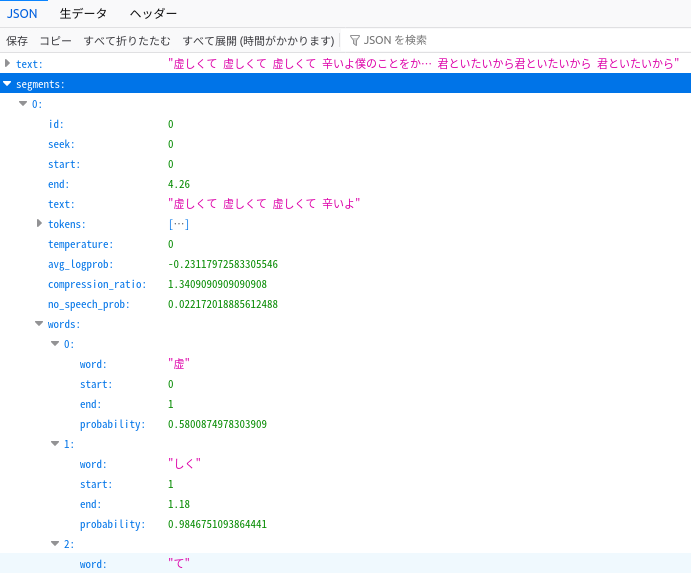
- text ... 文字起こし全テキストが入っています。
- segments ... 分割された文字起こしテキスト(1節)が入っています。
- words ... 文字起こしテキストのおおよそ1文字?が入っています。1文字ずつはいるかとおもっていましたが「しく」みたいに2文字入っているwordsもあるみたいです。
- start ... データの開始秒数
- end ... データの終了秒数
オーディオプレイヤーにカラオケ表示機能を盛り込む
JSONの出力を見ていただけると、だいたいどんな機能を作ればよいか見えてきます。
- 歌詞情報のJSONロード
- segmentsでループ
- segmentsのtextをdisableカラー(灰色とか)で出力
- wordsでループ
- wordのtextをenableカラー(緑とか)で出力
- endの時間がきたら、次のwordやsegmentに移動
実行コード
文字カラーの部分的に色を変えるっていう要件があったので、
tkのテキストウィジェットで実現することとなりました。
tkのテキストウィジェットでつかえるタグを利用して、
segmentタグと、highlightタグを用意しました。
タグによって色を変えます。
self.lyric_text = tk.Text(self.tk_root, font=("Arial", 15, "bold"), wrap="word", height=4, width=45)
self.lyric_text.pack(pady=5)
self.lyric_text.tag_configure("segment", foreground="gray")
self.lyric_text.tag_configure("highlight", foreground="lightgreen")
こんな感じで、tag_add()を使って、タグを付与します。
またtkのindexは
"行数(縦).文字数(横)"
のテキストで指定するようです。
(数字入れようとしてハマった)
tk_start_index = f"1.{start_index}"
tk_end_index = f"1.{end_index}"
self.lyric_text.tag_add("highlight", tk_start_index, tk_end_index)
描画更新処理はゴリッとかいてしまいました。
def start_lyric(self):
def update_lyric():
self.segments_index = 0
self.words_index = 0
self.word_count = 0
while pygame.mixer.music.get_busy():
self.display_lyric(AudioPlayer.LYRIC_UPDATE_SEC)
time.sleep(AudioPlayer.LYRIC_UPDATE_SEC)
self.level_meter_canvas.delete("all")
Thread(target=update_lyric, daemon=True).start()
def display_lyric(self, search_len_sec):
current_sec = pygame.mixer.music.get_pos() / 1000.0 # ミリ秒から秒に変換
current_segment = self.lyric_dict["segments"][self.segments_index]
# segmentのエンドに到達したら次のsegmentへ。
if (float(current_segment["end"]) < current_sec) and (self.segments_index < len(self.lyric_dict["segments"])):
self.segments_index += 1
self.words_index = 0
self.word_count = 0
current_segment = self.lyric_dict["segments"][self.segments_index]
self.lyric_text.delete("1.0", tk.END)
# segmentの表示条件。segmentのstartに到達した初回のみ。
should_show_new_segment = ((float(current_segment["start"]) <= current_sec) and
(float(current_segment["start"]) + search_len_sec > current_sec))
if should_show_new_segment:
self.lyric_text.insert(tk.END, current_segment["text"], "segment")
# wordsテキストを時間経過によって緑色でオーバーラップ
current_word = current_segment["words"][self.words_index]
# wordのエンドに到達したら次のwordへ。
if (float(current_word["end"]) < current_sec) and (self.words_index < len(current_segment["words"])):
self.words_index += 1
current_word = current_segment["words"][self.words_index]
# segmentと同じかんじでwordの表示条件。
should_show_new_word = ((float(current_word["start"]) <= current_sec) and
(float(current_word["start"]) + search_len_sec > current_sec))
if should_show_new_word:
start_index = self.word_count
end_index = start_index + len(current_word["word"])
# tkのテキストウィジェットのindexに変換
tk_start_index = f"1.{start_index}"
tk_end_index = f"1.{end_index}"
# タグを設定して、通過済みの歌詞をハイライト表示
self.lyric_text.tag_add("highlight", tk_start_index, tk_end_index)
self.word_count = end_index
実行結果
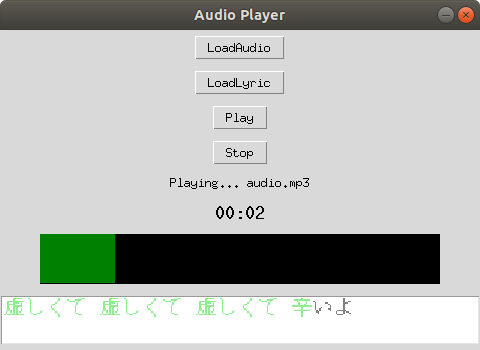
スクショじゃわかりませんが
オーディオデータの進行に沿って、1文字ずつ(たまに2文字)緑色に変わっていきます
これで世の中のあらゆる楽曲を適当にWhisperにぶち込んでカラオケ再生することができそうです、やったね!
最終的にはmp3のメタテキストとして保存できると、ファイルにまとまりがあってよさそうです。